 夜雨聆风
夜雨聆风





从“对话”到“行动”|拆解AI Agent的现实、优势与困境
点击蓝字 关注我们
如果你让ChatGPT帮你订一张明天的机票,它会礼貌地回复:“我不能直接帮你订票,但你可以去携程或飞猪上搜索……”
但如果你向一个成熟的 AI Agent下达同样的指令,它会打开浏览器,读取你的日历,寻找最合适的时间,调用支付API,最后在邮箱里留下一张出票单。
从“只会说话的百科全书”到“能替你干活的数字员工”,AI正在经历一场从 Copilot(副驾驶) 到 Autopilot(自动驾驶) 的范式转移。而驱动这场变革的核心,就是 AI Agent。
本篇将深度刨析当前AI Agent的底层逻辑、优势及它在爆发前夜所面临的现实困境。

什么是AI Agent

OpenAI应用研究主管Lilian Weng曾提出了一个被行业广泛认可的架构公式:
Agent = LLM(大语言模型) + Planning (规划) + Memory(记忆) + Tool Use(工具使用)
其说明了LLM本身不是完整的 Agent,它只是 Agent 的“大脑”。而一个真正可执行任务的 Agent,通常至少包含四个模块:
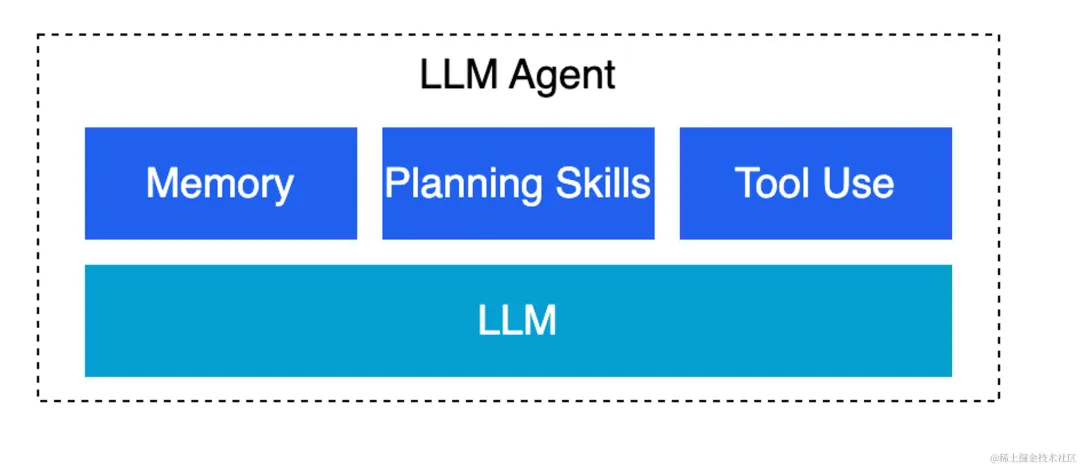
图1 AI Agent架构
1. 大脑(LLM)
Agent的推理引擎,负责理解意图、做推理、生成下一步动作建议,不再是被动回答问题。
2. 规划(Planning)
当面临“开发一个贪吃蛇小游戏”的复杂指令时,它会使用思维链(Chain of Thought, CoT)或任务分解(Task Decomposition)技术,把大目标拆解,再逐步执行。
3. 记忆(Memory)
短期记忆: 当前的“上下文窗口”,记住目前的对话与任务状态。
长期记忆: 通过向量数据库(Vector Database)等技术,可以像翻阅日记一样,回想起用户上个月提到的偏好,沉淀用户偏好、历史经验和外部知识。
4. 工具使用(Tool Use / Action)
Agent可以通过调用API(应用程序接口)来感知和改变世界。它可以搜索网页、运行Python代码、发邮件、操作Excel,甚至控制实体机器人。将Agent从语言系统变成行动系统。

AI Agent能做到什么

为什么硅谷和国内大厂都在疯狂押注AI Agent?因为它打破了AI只能“纸上谈兵”的局限。它的优势不仅在于聪明,更在于自动化与协同。
01
自主工作的超级个体:Devin

Devin 是由AI初创公司 Cognition 开发的全球首个全自主 AI 软件工程师,具备自主学习新技术、端到端构建和部署应用、自主查找和修复代码 Bug、训练和微调 AI 模型的能力。在 SWE-bench 基准测试中,Devin 展现出超越其他 AI 模型的性能,正确解决了实际编程问题。
当你给它一个任务:“帮我写一个爬取纽约时报头条的程序”,Devin会自己打开内置的代码编辑器、命令行和浏览器。它会自己写代码、自己运行、发现报错后自己看Log、然后自己修改代码,直到程序完美运行。这种“闭环解决问题”的能力,是传统LLM无法实现的。
02
多智能体协同:MetaGPT

如果一个Agent能干活,那么一群Agent呢?国内开源项目 MetaGPT 展现了震撼的“数字公司”形态。它将不同的Agent设定为产品经理、架构师、程序员和测试工程师。当你输入一句“我想要一个五子棋游戏”时:
-
PM Agent 负责写需求文档;
-
架构师 Agent 负责设计系统接口;
-
程序员 Agent 根据接口写代码;
-
测试 Agent 负责找Bug。
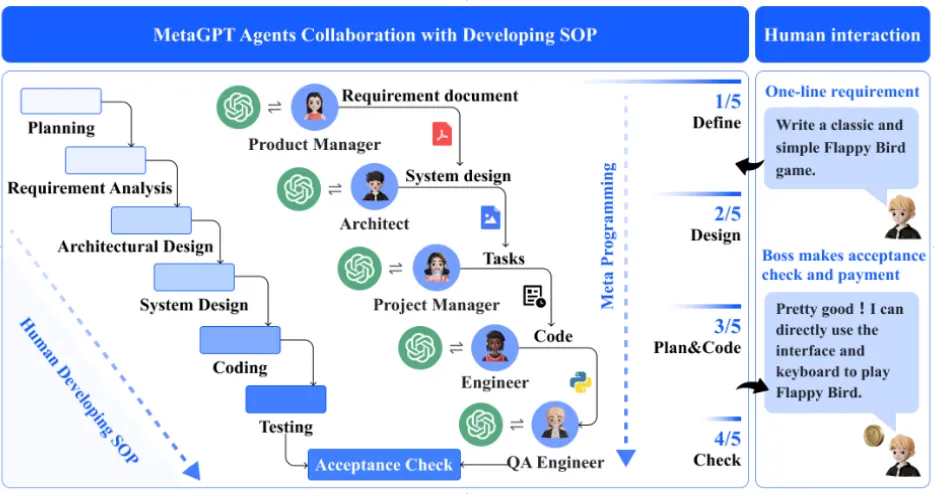
图2 MetaGPT工作流
它们在群聊里互相审核、协作,最终交付一整套软件。这种基于标准操作流程(SOP)的多智能体系统,极大提升了复杂任务的成功率。但值得注意的是,不是Agent数量越多越好,而是当任务本身具有明确分工结构时,角色化、多Agent、流程化确实可能比单一Agent更稳定。
03
斯坦福的“虚拟小镇”

在斯坦福大学的一项研究中,25个带有特定人设、具有记忆、反思与计划机制的 AI Agents被放入一个模拟小镇。它们不仅会自己安排作息,还会互相八卦、交友,甚至自发组织了一场情人节派对,产生了较为可信的个体行为与群体互动。
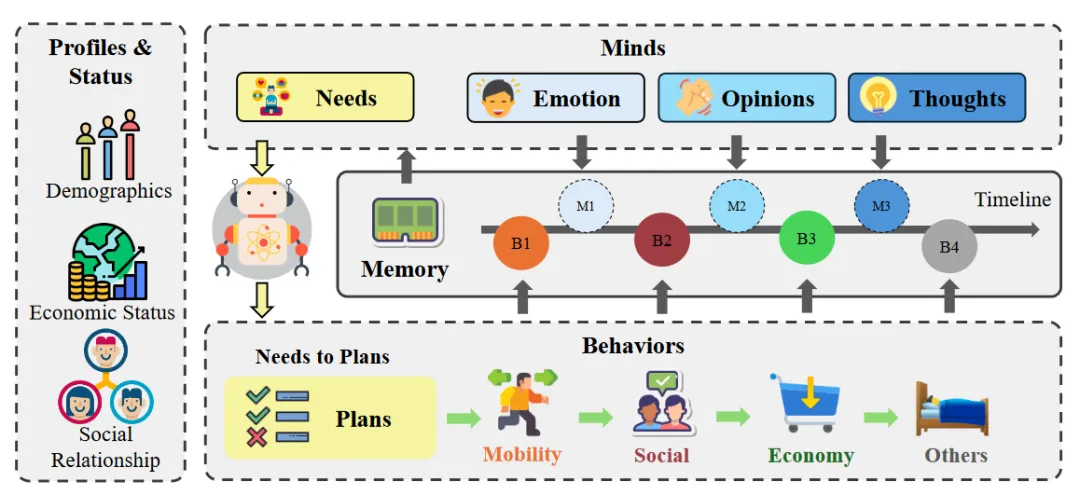
图3 社会模拟架构
其证明了Agent并不只适用于办公自动化或编码,也可能用于教育、训练、社会模拟、游戏 NPC、行为实验等场景。

AI Agent应用的现实困境

看完上面的案例,你可能心潮澎湃:既然这么厉害,为什么我的工作还没被Agent完全接管?现实是骨感的。目前的AI Agent正处于“能用”到“好用”的尴尬跨越期,面临着四大致命困境:
01
误差累积与“蝴蝶效应”

Agent的工作流通常是一步接一步的,并且大多任务是长链条执行。假设一个任务需要5个步骤,LLM每一步的准确率高达90%,那么最终的成功率只有 90%^5 = 59%。
如果Agent在第一步搜集资料时产生了“幻觉”(Hallucination),它会带着这个错误信息继续写代码、发邮件,最终造成南辕北辙的灾难性后果。
02
容易陷入“无限死循环”

很多演示视频里的 Agent 非常惊艳,但一旦进入真实网页、真实 API、真实企业系统,就会遇到权限、页面变化、异常返回、非结构化信息等各种问题。
比如在调用某个天气API时,如果API报错,人类会去查阅文档找原因;而目前的Agent往往会陷入不断重复尝试相同错误代码的死循环中,直到耗尽所有的Token和资金。缺乏有效的“自我反思(Self-Reflection)与纠错机制”,是它的一大软肋。
03
上下文遗忘

尽管现在的模型动辄支持100万Token的上下文,但研究表明,当信息过载时,Agent会出现“中间迷失”(Lost in the Middle)现象。它可能会牢记开头你的叮嘱和结尾的任务,却忽视中间的关键约束条件,而在真实任务中,约束条件、历史决策、工具返回结果往往恰恰散落在长上下文的不同位置,这就导致Agent表现不尽人意。
04
高昂的成本与延迟

让Agent替你工作是需要耐心的。为了完成一个复杂任务,Agent需要反复调用大模型进行“思考-行动-观察”。这会直接带来推理成本、等待时延、系统治理成本这三类成本,也意味着极长的等待时间和高昂的API调用费用。目前,Agent 距“稳定、便宜、可审计、可规模化”仍有一定差距。用其解决某些日常事务的成本,甚至高于雇佣一个真人。

结语

我们该如何看待目前的AI Agent?
如果把AI的发展比作互联网,当前的聊天机器人就像是静态的网页(Web 1.0),而目前的AI Agent正处于“拨号上网”时代的Web 2.0。它经常断线(报错)、速度很慢(延迟)、费用昂贵,甚至时不时给你下载一堆乱码(幻觉)。但这绝不意味着它是一个伪命题。
随着基础大模型推理能力的跃升、Agent专属架构的完善以及API生态的建立,Agent的困境正在被逐一攻破。更准确的判断也许是:Agent 还远没到“全自动接管工作”的阶段,但已经足以重塑很多数字工作的组织方式。
未来几年,真正重要的问题可能不再是“AI 会不会取代人?”,而是“哪些工作会被重新拆分为人类负责定义目标,Agent 负责推进执行?”
参考文献
[1]. Liu N F, Lin K, Hewitt J, et al. Lost in the middle: How language models use long contexts[J]. Transactions of the association for computational linguistics, 2024, 12: 157-173.
[2]. Zhou S, Xu F F, Zhu H, et al. Webarena: A realistic web environment for building autonomous agents[J]. arXiv preprint arXiv:2307.13854, 2023.
[3]. Park J S, O’Brien J, Cai C J, et al. Generative agents: Interactive simulacra of human behavior[C]//Proceedings of the 36th annual acm symposium on user interface software and technology. 2023: 1-22.
[4]. Chen X, Zeng A. A survey on large language model based autonomous agents[C]//CCL 2024–23rd Chinese Natl Conf Comput Linguist. 2024, 2(6): 141-150.
END