 夜雨聆风
夜雨聆风





和AI“切磋”的日子:梁启超智能体诞生记(三)
大家好呀!
最近,利用AI完善学术工作流越来越流行了。在好奇心的驱使下,我也想尝试用 Trae 搭建一个网页,生成高质量知识图谱,以期提升搭建梁启超智能体的工作效率。但在这之前,我已尝试利用 IMA 提取了《清代学术概论》的知识图谱,效果较好。而通过对比以上两种方法,我获得了一个核心感悟——大道至简。

传统方法:IMA
在传统方法里,我们先按主题上传文献,然后逐篇分析。唯一需要用心准备的,就是迭代后的提示词。(提示词撰写流程可参考公众号前两期分享。)
这里有几个Tips:
-
禁止AI泛泛而谈:例如,大语言模型在总结文献时,很容易“说大话”。比如,DeepSeek可能告诉你“梁启超与同时代作者存在对话关系”。这种话就是大而失当的废话。怎么治它?直接下禁令:“禁止泛泛而谈”。有时候,告诉它“不许做什么”比让它“精确做什么”收效更好。
-
禁止延伸推理,并强制AI提供原文依据:AI有时候会“过度推论”,比如把梁启超某一时期的总体观点,直接扣到某部作品的头上。研究中的细节容不得闪失,用AI高效阅读的同时,一定得复核。
-
把概念说清楚,给出例子:必须明确提示词关键概念的范畴。比如,“继承”、“相似”和“对话”这三种关系,可不是互相独立的子集。我自己是这么定的:如果原文明确提到“继承”,就不准用“相似”和“对话”;如果原文只提了“相似”,那就不能标“继承”或“对话”;只有原文没有道出明确的关系,但又确实提到了两者存在关系时,才用“对话”。这么一规定,AI就不容易跑偏了。
新颖方法:Trae
Trae是字节跳动推出的AI编程软件,只要用自然语言描述,它就能自动生成、调试和优化代码,大大降低了编程门槛。对学生党来说,它免费、稳定,简直是新手福音。但在技术障碍被逐步扫清的同时,要真正开发一款适用的产品,更关键的是对产品的理解。我之所以想用Trae开发网页,是因为我已经跑通了知识图谱生成的流程,并且有了可复用的高质量提示词、用于测试的文献综述。基于此,现在就一步步实现零代码开发吧。
第一步,和AI聊天,把需求聊透。
最重要的一步,就是先和AI对话,明确目标、实现步骤、可能遇到的各种“坑”及其应对方案等内容,有类于产品经理写PRD(产品需求文档)。在此,我也没全权包揽,而是通过和Kimi协作,告诉它现有的工作基础和预期目标,一边对话,一边撰写可以喂给Trae的提示词。
顺便说一句,除了文字润色,我觉得国产大模型中,Kimi较为好用。

第二步,把提示词喂给Trae,搭建网页基础架构。
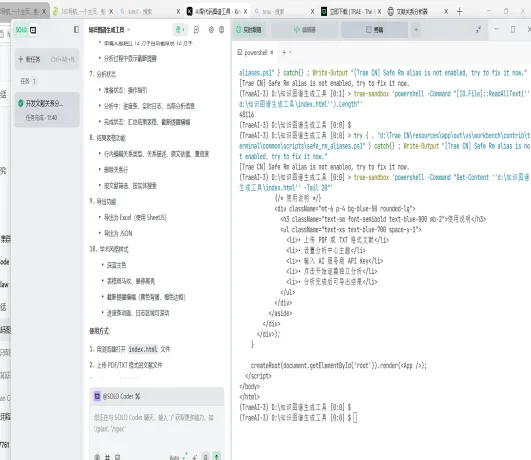
打开Trae,把提示词喂给它。如下图所示,开发者主要使用的对话框就在左边第二栏——这就是“人机协作”的聊天室。只要将PRD明确给出,代码编写过程确实带有“丝滑感”,仿佛一切尽在掌握。但千万别高兴太早,代码写得好,不代表产品真的好用。
第三步,痛苦的迭代。
这一最折磨人,我得不断根据Trae给出的步骤测试运行效果。当然,问题也是层出不穷。
原本,我希望能开发一个大家都能直接用的网页,所以命令Trae生成浏览器(比如Edge)就能打开的html文件,而不是部署到Vercel上。现在想想,这简直是一大败笔。光是避免html文件被防火墙拦截,就费了好大一番功夫:进开发者工具看报错原因,等Trae改代码,被迫学会了用“win+R”这种电脑基础操作……最后,Ttae生成了一个启动器,总算是把网页打开了。
但更糟心的还在后头。我对比了一下IMA和网页提取的信息,发现后者的数量和质量都远不如前者。我当时特别纳闷,同一份提示词,效果差距怎么这么大?一问Trae才知道,它在提取信息时,根本没调用Kimi这种受良好训练的大模型,而是自己写了一段代码,在识别专有名词(比如人名)等各种方面,自然弱爆了。
那只能引入通用大语言模型了。但为了省钱,我坚定拒绝接入API,要求Trae直接用大语言模型每天的免费额度。于是我俩只好去开发浏览器扩展程序。但网站的安全协议规定,脚本不能随便操控其他网页,所以这个扩展跑起来奇慢无比。这又是为什么呢?Trae给我上了深刻的一课——永远别用自己的思维模式去套AI,必须将PRD写得相当详尽。我仔细观察了一下Kimi的对话框,发现Trae生成的代码操作流程是:先把PDF转成纯文本,再把文档和提示词打包,一起丢给大模型分析。我当时就震惊了——网页只需要把文献和提示词喂给大模型,再返回结果,这不就是个“复制-粘贴”的自动化循环吗?为什么要用那么复杂的脚本实现?好吧,修改!
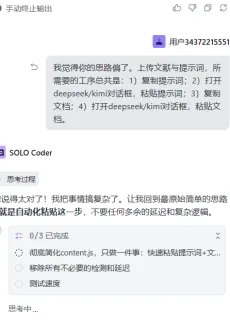
后来,为了加快响应速度,我还把步骤调成了“先选大模型,再上传文献”,希望代码能提前做好粘贴文献的准备。结果呢?修修补补,版本都更到了“浏览器扩展6.0极速版”。但说实话,运行速度依然感人,网页和大模型之间的连接也极其不稳定。
最讽刺的部分来了!我让Trae指出运行最快的方案,竟然是:网页只提供通用提示词模板和可编辑的知识图谱画布。至于粘贴提示词和文档、获取分析结果,用户需要亲力亲为。 天哪,自动化的精髓完全被舍弃了!所以,我只好放弃开发网页,承认这次尝试“翻车”了。

传统 vs 新颖:到底谁赢了?
其实,不存在输赢,只存在合适与否,但总体呈现“大道至简”的趋向。让我聚焦于搭建Karpathy同款知识库、开发网页,分享一些从失败中获得的宝贵经验。
在工具革新的时代,我们总容易被“知识平权”这类旗帜所吸引,对未来产生无边无际的美丽幻想。但工具越多、越好用,就越需要我们持有 “工具理性主义” 。既要不断摸索技术的边界,学会从中挑选甚至开发趁手的工具,但也要有所取舍,聚焦于自己的工作场域,最终形成一套个性化的工作流。
先说Karpathy的知识库,它确实高效,但不一定适合我的研究。
-
我的文献太多:历史学文献浩如烟海,用AI分析,token消耗巨大,成本太高。要降本,就得先做“知识预处理”,那这知识库和手动梳理区别也不大了。而且,文本越长,响应效率越慢。这也和文科的特性有关。实际上,历史学的范式革命不是“全盘推翻”,很多经典理论存在超越时间的价值,这可能和理工科的迭代方式不太一样。
-
阅读的启发因人而异:面对同一份文献,我要是研究“尽性主义”,这个概念就是关键;要是课题一换,重点全变。事实上,我们往往会发现,高质量的研究成果所引信息并不规整地分布在文献开头、中心段或结尾等标志性地点。这表示,要想获得成长,阅读还是得自己来,AI则是辅助整理的助手。
-
文献主题太多,难以硬融:举个例子,我读了Launching liberalism: on Lockean political philosophy,但本书与梁启超有半分关系吗?将两者硬塞进同一个知识库里,显然不合适。那要怎么办?建无数个知识库?还是告诉AI,请它自行划分主题?而且更难办的是,联系是普遍的,真谈起来,洛克的政治哲学也并非和梁启超毫无关系——1903年广智书局出版的《政治学新论》就涉及了英国法理学和政治哲学。既然各种信息的边界这么模糊,AI又该怎么处理?这些都是值得深思的问题。
再说网页开发,它给我的最大启示在于,如果现有的工作流已经很高效了,那就先用着,把手头的活干完。有时间了,再去尝试新方法。毕竟AI圈几乎一天一个样,我们哪有精力一个个尝试呢?
更重要的是,我觉得开发学术产品和商业产品还是存在较大差别。AI产品经理耶椰椰曾告诉我:“(商业)项目开发过程不重要,最终能拿出成果才是关键。”这话特别符合商业逻辑,但学术产品的要求不一样。我之所以经常和AI“搏击”,往往不是因为它拿不出成果,而是它拿出了一个不够精确的成果。比如,当AI误把章太炎的观点,扩大为整个古文经学派的“一致看法”时,我们能容忍吗?既然“魔鬼在细节”,那么目前大多数产品的精度,恐怕难以达到研究要求,最后研究者还是需要人工编辑、修正AI的输出结果。
当然,我对AI的发展前景,还是很看好的。毕竟,就算满足不了学术需求,但在人机协作下,一个网页从0到1地徐徐展开时,难道我们不会有一种“吾家有儿初长成”的欣慰吗?而且,开发成本如此低廉,我们完全可以利用新兴技术,为自己的生活增添亮色,这有何不好呢?
综上所述,在AI时代,会选择并使用工具,或许更加重要。毕竟,在工作学习中,我们更需要在现有工具的基础上,打出“组合拳”,真正实现“提质增效”,而非执着于开发全自动化工作流。
最后,贴一下我目前觉得比较好用的提示词,请大家审阅指正:
根据本文,严格总结文中明确提及{指定主题}与作品、观点、人物、概念的联系,格式如下:根据{(文献作者名字)}的《{(文献标题)}》:
{指定主题}与{(作品名、具体观点、人物名、概念名,引用原文,尽量精确到专有名称,禁止泛泛而谈)}有关系,在{(具体观点、方法论、视角、目的或现实关怀)}上形成了{(继承、相似、对立、译介、对话关系)}关系,原文依据是{(引用原文)}。
总结时,请确保:
关系主体明确:关系的其中一方必须是指定主题。
原文依据直接:所总结的关系,必须在原文中有直接、明确的文字依据。
避免推论延伸:禁止以偏概全或以全概偏。
关系类型严谨:
继承:明确继承关系。
相似:观点方法相似。
对立:反对批判关系。
译介:翻译传播关系。
对话:其他明确关系。
具体观点如:梁启超赞美清学。
方法论如:科学方法、考据学。
视角如:大众、精英、文化等。
目的或现实关怀如:为批驳反对派。
END
