 夜雨聆风
夜雨聆风





一文看懂 LayoutLMv2 文档问答模型:让AI读懂表单和票据


01
前言
在大模型越来越会“聊天”的今天,还有一类模型非常适合解决企业里的真实问题:文档理解模型。
比如合同、发票、报销单、申请表、扫描件、PDF截图、问卷表格……这些内容不是普通文本那么简单。它们既有文字,又有版面结构,还可能包含表格、标题、字段位置和视觉排版。
这时候,普通文本模型往往只能“读字”,但不一定能“看懂文档”。而今天要介绍的
# 这个模型:layoutlmv2-base-uncased_finetuned_docvqa 就是面向 Document Question Answering(文档问答) 场景的模型。它基于微软的 LayoutLMv2-base-uncased 进行微调,核心方向是让模型不仅理解文字内容,还能结合文档中的空间布局信息,回答与文档内容相关的问题。
简单来说,它更像是一个“会看版面的文档问答助手”。
02
这个模型能干啥
传统 NLP 模型处理文本时,通常只关注文字顺序,比如一句话从左到右怎么读。但真实文档往往不是一段纯文本。例如一张报销单中:
1️⃣ 姓名在左上角,金额在右侧;2️⃣ 日期在表格中间;3️⃣ 审批意见可能在底部;4️⃣ 同一个字段旁边还有对应的值。
5️⃣ 如果模型只看文字,很容易把字段和值对应错。
LayoutLMv2 的优势就在于,它会同时考虑:文本内容 + 文档布局 + 视觉信息
因此,它更适合处理扫描文档、表单、票据、合同页、问答型文档理解等任务。当用户提出问题,比如:
✅ “这张发票的金额是多少?”✅ “申请人是谁?”✅ “合同签署日期是哪天?”✅ “表格中的审批结果是什么?”
✅ 模型可以根据文档内容进行回答。
03
模型基础信息
该模型是一个基于microsoft/layoutlmv2-base-uncased微调而来的文档问答模型,任务类型为 Document Question Answering。
从公开信息来看,它使用了Transformers框架,并采用Safetensors格式保存模型文件,底层属于 LayoutLMv2 系列。
训练参数中,学习率为 5e-05,训练批次大小为 4,评估批次大小为 8,训练轮数为 20。这说明它更偏向于在已有 LayoutLMv2 基座能力上进行任务适配,而不是从零训练。
需要注意的是,模型卡中目前对训练数据、具体评估指标和适用限制说明较少,因此在正式生产环境使用前,建议先用自己的业务文档进行测试验证。
04
特色在哪里
1️⃣ 面向文档问答,不只是OCR
它不是单纯把图片转成文字,而是进一步理解文档结构。对于“字段—答案”类问题,它比普通文本模型更适合。
2️⃣ 适合版面复杂的文档
表单、票据、合同、扫描件这类材料,往往不是连续段落。LayoutLMv2 可以结合文字位置关系,对结构化信息更敏感。
3️⃣ 支持企业级信息抽取思路
如果企业有大量 PDF、图片文档、表格文档,需要自动读取关键信息,可以把它作为文档智能处理流程中的核心模型之一。
4️⃣ 基于成熟架构,便于二次开发
LayoutLM 系列在文档理解领域应用较多,适合结合 OCR、后端服务、知识库系统、审核系统进行二次开发。
5️⃣ Safetensors 格式更适合模型分发
Safetensors 在模型加载和安全性方面更友好,适合开发者进行本地实验和部署管理。
05
硬件推荐
1️⃣ 入门测试配置
💻 适合少量样本测试、模型跑通和 Demo 验证。
✨ CPU:Apple M 系列 / Intel i5 以上✨ 内存:16GB 起步✨ 显存:无独显也可尝试 CPU 推理适用:功能验证、接口测试、小规模文档问答
如果是 MacBook Air M3 16GB,也可以做轻量测试,但推理速度不要期待太高。
2️⃣ 推荐开发配置
💻 适合做项目开发、批量测试、接口封装。
✨ CPU:i7 / Ryzen 7 / Apple M3 Pro 及以上✨ 内存:32GB 推荐✨ GPU:NVIDIA 8GB 显存以上更稳✨ 存储:SSD 512GB 以上适用:企业内部工具、文档问答系统原型、批量文档解析
3️⃣ 生产部署配置
💻 适合高并发、批量文档处理。
✨ CPU:多核心服务器 CPU✨ 内存:64GB 以上✨ GPU:NVIDIA 16GB 显存以上部署方式:FastAPI + OCR服务 + 模型推理服务 + 队列任务适用:合同审核、票据识别、档案问答、企业文档智能平台
06
适合领域
1️⃣ 财务票据识别
适合发票、报销单、付款凭证、收据等场景,用于提取金额、日期、单位名称、票据编号等信息。
2️⃣ 合同与法律文档问答
可用于合同关键信息检索,比如甲乙方、签署时间、付款条款、违约条款等。不过法律场景要求较高,建议配合人工复核。
3️⃣ 政务与企业表单处理
适合申请表、审批表、登记表、材料清单等结构化文档,提高录入与审核效率。
4️⃣ 教育与试卷资料处理
可用于试卷、答题卡、成绩表、报名材料等文档问答与信息抽取。
5️⃣ 医疗与科研文档整理
可辅助处理病例表、实验记录表、统计表格等,但医疗场景必须注意合规与人工审核。
6️⃣ 档案数字化管理
对于历史扫描件、纸质档案、企业资料库,可以作为智能检索和问答系统的基础能力之一。
07
使用建议
这个模型更适合做“文档理解流程”的一环,而不是单独使用。比较完整的方案通常是:
文档上传 → OCR识别 → 版面分析 → 模型问答 → 结果校验 → 人工复核
如果文档质量较差,比如图片模糊、扫描倾斜、表格线断裂、OCR识别错误较多,模型效果也会受到影响。
所以在真实项目中,不建议只看模型本身,还要重点关注 OCR质量、图片预处理、字段校验规则和业务数据闭环。
08
模型下载
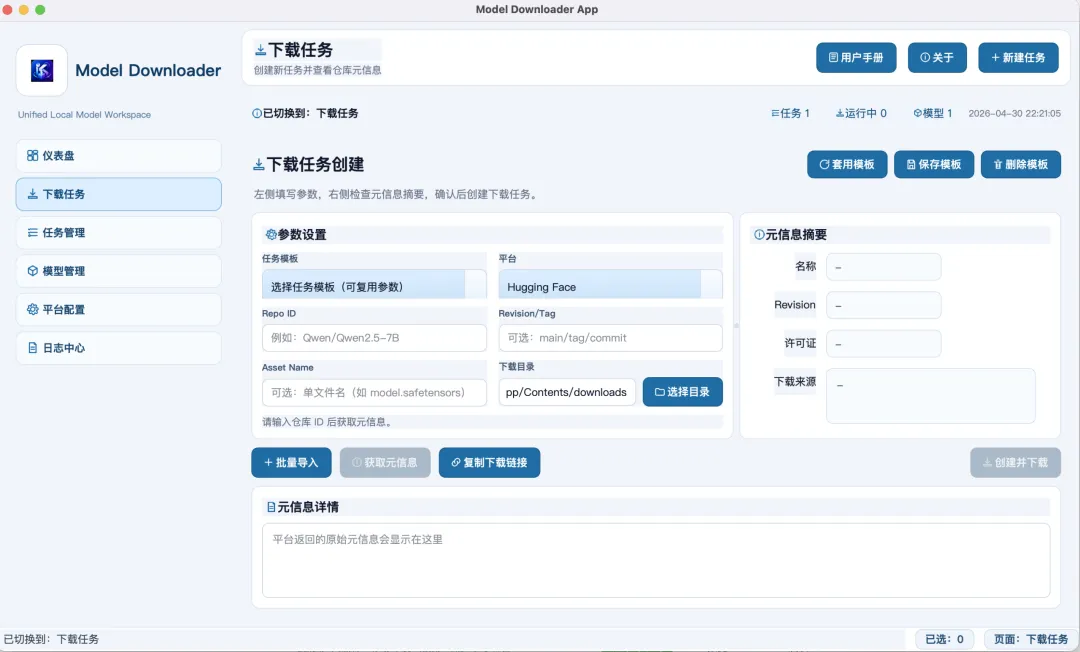
1️⃣ 打开model-downloader-app;
2️⃣ 创建下载任务;
3️⃣ 选择开源模型平台;
4️⃣ 输入repo id




往期推荐
SDPose-Wholebody:让全身姿态估计更稳、更细、更能跨场景
这个中文分词模型,真的更懂电商标题
DeepSeek-V4来了:百万上下文模型,正在把AI拉进新阶段
柯影智绘测试版来了:想让科研绘图更统一、更省心
keying-rembg 节点怎么选模型?这 4 个常用 rembg 模型一次讲清

