 夜雨聆风
夜雨聆风





你的AI助手没有记忆——它只有一本备忘录
最近我用一个AI编程助手写了三个月的代码。它帮我重构过数据库查询,调试过分布式系统的竞态条件,甚至还建议了一个我当时觉得荒谬但后来证明完全正确的架构方案。我很满意。但有一天我打开一个新对话窗口,问它一个我们上周刚一起解决过的问题。它答不上来。
这不是因为它忘了。而是因为它从来就没有”记住”过。
这个区别听起来像语义游戏。但它不是。2026年4月30日,香港中文大学和浙江大学的三位研究者——Binyan Xu、Xilin Dai和Kehuan Zhang——发表了一篇论文,用形式化的数学证明了一件很多人直觉上感觉到但说不清楚的事:当前所有的AI Agent记忆系统,不管叫什么名字——向量存储、检索增强生成(RAG)、记事本、上下文窗口管理——都不是记忆。它们是查找。 把查找叫作记忆,是一个范畴错误,而这个错误正在以可证明的方式限制着AI的能力、学习和安全。
这篇论文值得认真对待。不是因为它的结论新颖——事实上,很多从业者私下里早就怀疑这一点——而是因为它做了一件学术界很少做的事:把一个模糊的哲学直觉变成了一道你可以验证的数学题。
备忘录和记忆之间的区别
要理解这篇论文的核心论点,你首先需要理解一个认知科学中已经被研究了三十年的区分。
想象两个学生准备物理考试。第一个学生有一本笔记,里面记录了老师讲过的所有例题和解法,按章节整理得井井有条。考试时他翻笔记,找到最相似的例题,照猫画虎。第二个学生也做了笔记,但后来他不再翻看了——因为他已经把底层的物理原理内化了。遇到一个全新的题目,他能从未见过这个具体场景,但可以从第一性原理出发推导出答案。
认知科学家把第一种叫做范例式认知(exemplar-based cognition),第二种叫做规则式认知(rule-based cognition)。1981年,Chi等人做了一个经典实验:给物理学新手和专家看同一组物理题,让他们分类。新手按表面特征分类——”这些都是斜面问题”——而专家按深层结构分类——”这些都是能量守恒问题”。关键发现是:这不是因为他们记住的东西不同,而是他们表征知识的方式不同。

这就是备忘录和记忆之间的区别。
备忘录(memo)是一个外部存储:你把信息写进去,需要的时候查出来。它的泛化方式是相似性检索——你只能用好你存过的东西,而且只能在场景足够相似的时候用得好。
记忆(memory)是一种内部重构:你的大脑在睡眠中将海马体的快速情景存储 consolidates 成新皮层的慢速分布式权重表征。它的泛化方式是规则应用——你从未见过这个具体场景,但你可以从已内化的抽象原则出发推导出正确的应对。

备忘录让你找到过去的答案。记忆让你生成新的答案。
现在的问题是:所有的AI Agent都只有备忘录,没有记忆。
两条路的分歧
论文提出了一个简洁的分析框架。任何改变LLM Agent输出的技术都可以归入两条结构上截然不同的路径:
路径一:改变模型的权重(θ)。 通过预训练、微调、强化学习或任何基于梯度的更新,修改模型的先验分布 P(X|θ)。知识被压缩进模型的权重空间,容量随参数量缩放。
路径二:改变上下文内容(Context)。 通过提示词、RAG、工具调用、技能文件、记事本或任何形式的上下文工程,将内容注入上下文窗口,在 P(X|θ,C) 条件下生成。
这两条路的关键区别不是压缩率,而是生成性。权重压缩是生成性的——模型可以重组权重编码的规则来处理从未见过的输入。上下文压缩是检索性的——模型只能使用上下文中明确出现的东西。
MemGPT在做什么?把信息从外部存储调进调出上下文窗口。Generative Agents在做什么?把每次观察写进记忆流。Reflexion在做什么?把口头的自我批评存进情景缓冲区。Voyager在做什么?把技能以代码形式存进向量数据库。
所有的主流Agent框架都在做路径二。没有一个在做路径一。
模型在Agent经历前后,权重是完全相同的。Agent记录了经验,检索了经验,但从未从经验中学习。
论文用一个精妙的类比总结了这个困境:一个Reflexion Agent积累了数千条口头自我批评,但在每次会话中运行的仍然是同一个冻结的模型。它的文件柜在增长,但它的能力没有变。
一个形式化的天花板
如果你是一个工程师,你可能会想:好吧,也许当前的实现有局限,但如果我们把检索做得更好——更大的向量数据库、更聪明的检索算法、更长的上下文窗口——是不是最终可以弥补这个差距?
不能。这就是这篇论文最核心的理论贡献。
研究者定义了一个叫做”组合泛化能力”(Compositional Generalization Capacity, CGC)的指标:给定一个领域中的k个基础概念和一个组合运算符⊕,Agent需要学习如何将这些概念两两组合。目标是衡量系统在从未见过的概念组合上的准确率。
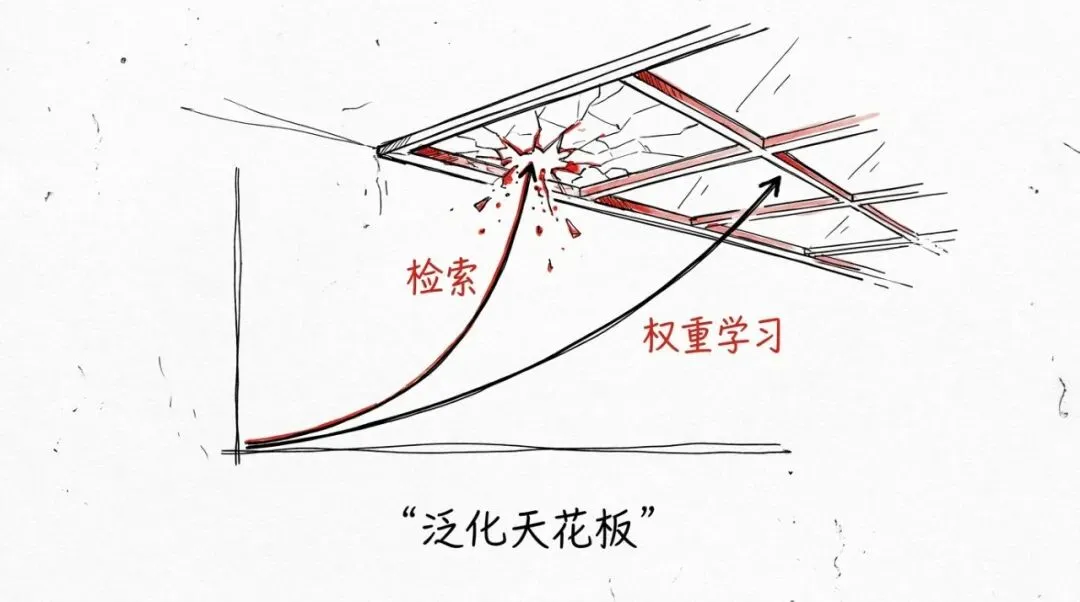
然后他们证明了定理1(Compositional Sample Complexity Separation):
要达到同样的泛化水平,检索系统需要的样本量是Ω(k²)——因为每个存储的例子只能覆盖组合空间中的一个点,而组合空间的大小是k的平方量级。而权重学习系统需要的样本量是O(d)——其中d是组合运算符的内在复杂度,与基础概念的数量k无关。
这个差距是不可弥合的。你无法通过更好的检索算法来弥补它,因为这是一个覆盖问题——检索面对的是”你需要覆盖k²个点中的多少个”,而权重学习面对的是”你需要理解一个复杂度为d的规则”。当k增长时,k²的增长速度远快于d,差距只会越来越大。
论文给出了一个直观的解释:想象一个学生分别学了运动学和热力学。如果考试要求他解决一个同时涉及两者的组合问题,检索系统只能返回他之前见过的单独案例。组合规则必须被穷举存储或者参数化学习。检索面对的是一个覆盖问题;参数学习面对的是一个学习问题。
增加上下文窗口大小(更多的检索结果K)只能轻微提升冻结模型在上下文中的推理能力α,但不能消除结构性的覆盖需求。 只要α小于某个上界,Ω(k²)的样本需求就存在。
这个定理不是在说RAG不好——它是在说RAG在组合泛化上有一个结构性的天花板,这个天花板不是工程问题,是数学问题。
大脑是怎么解决这个问题的
到这里你可能会问:既然检索有天花板,为什么生物智能没有这个问题?
答案在神经科学中一个叫做互补学习系统理论(Complementary Learning Systems, CLS)的框架里。这个理论由McClelland、McNaughton和O’Reilly在1995年提出,核心观点是:
大脑有两套互补的学习系统。海马体提供快速的情景存储——你在一天中经历的事情会被快速编码。但这只是临时存储。在睡眠期间,这些情景记忆会被慢速地重放(replay)并整合(consolidate)进新皮层的分布式权重表征中。
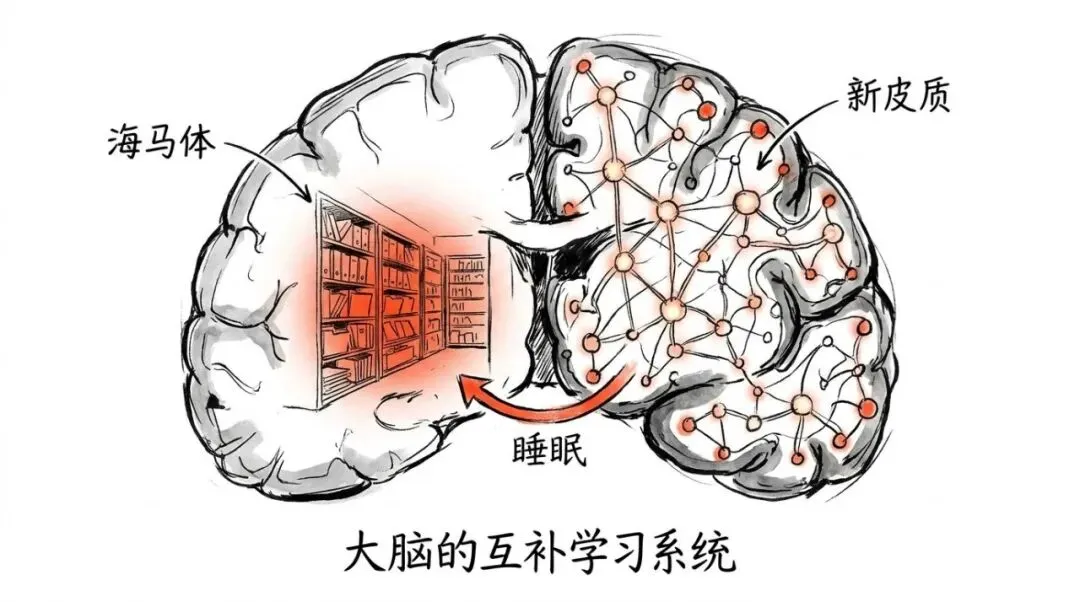
海马体 = 快速的范例存储 = AI当前的检索系统。 新皮层 = 慢速的规则学习 = AI缺失的权重整合。
当前AI Agent只实现了前一半。 没有任何已部署的系统拥有从海马体到新皮层的整合通道。
这个生物学类比不是装饰性的。它精确地描述了当前AI Agent架构的缺失部分:一种将快速的外部经验存储转化为慢速的内部权重更新的机制。不是替代检索,而是在检索之上增加整合。
RAG的倒置
这里有一个讽刺的历史反转。
2021年,Lewis等人在提出RAG时,明确将其定位为用检索索引来增强参数记忆。原始的愿景是:模型本身有知识(在权重里),检索是补充。
但此后的几年里,整个领域逐渐用扩大的非参数存储替代了参数更新。今天的RAG系统与其说是”检索增强的模型”,不如说是”模型辅助的检索系统”。模型变成了一个对检索结果进行后处理的引擎,而不是一个从经验中学习的学习者。
论文把这叫做“RAG倒置”。它不是在批评RAG的工程价值——RAG确实是目前可部署的最佳折中方案。它是在批评一种正在固化的假设:更多的检索等于更多的智能。
这意味着什么
退一步想想这篇论文对AI行业的更广泛含义。
对系统构建者来说:你需要开始构建整合通道。不是放弃检索,而是在检索之上增加一个将外部经验转化为权重更新的慢速整合机制。论文提出了一个”共存架构”——快速检索用于即时的案例匹配,慢速整合用于长期的能力增长。
对基准测试设计者来说:你需要开始测量学习,而不仅仅是回忆。当前的Agent基准测试几乎都在评估”在已见任务上的表现”。你需要开始设计那些真正测试组合泛化能力的基准——那些Agent无法通过找到相似案例来解决的问题。
对持续学习社区来说:你们的方法论才是Agent的真正部署目标。持续学习研究者已经开发了数十种克服灾难性遗忘的方法,但这些方法几乎没有被应用到Agent场景中。论文的论点暗示,Agent场景应该是持续学习最大的应用场景。
对普通用户来说:下次当你发现你的AI助手”忘记”了你们上周一起做过的事时,不要只责怪它的上下文窗口太短。它不是忘了——它从来没有学会过。它只是没有翻到那一页备忘录而已。而即使它翻到了,如果面对的是一个稍微不同的新问题,那份备忘录也帮不了它。
一个更深的哲学问题
当我们说一个系统”记住”了什么,我们到底在说什么?
在日常语言中,”记忆”是一个模糊的词,它同时涵盖了”我有这条信息的记录”和”这个经验改变了我”两层意思。在大多数情况下,这种模糊性不会造成问题——因为对人类来说,这两件事几乎总是同时发生。你记住了昨天晚饭吃了什么(你有这条信息的记录),同时昨天晚饭的经验也可能微妙地改变了你对某种食材的偏好(这个经验改变了你)。
但对AI来说,这两件事已经被技术架构彻底分开了。AI可以有完美的信息记录(外部存储),但没有任何经验改变(权重不变)。而当整个行业用”记忆”这个同时涵盖了两层意思的词来描述只有第一层的系统时,一个概念陷阱就形成了。
我们开始相信Agent在”学习”,因为它们在”记住”。但记住不是学习。记录不是理解。积累不是成长。
这篇论文的价值不在于它发现了一个没人知道的问题——很多工程师早就感觉到了。它的价值在于它把这个直觉变成了一个你可以验证、无法否认的数学命题。定理1不依赖于任何特定的模型架构或任务设计——它只依赖于一个关于冻结模型上下文推理能力上限的合理假设。
这是一个好的理论论证应该有的样子:它让原本可以被忽视的直觉变得无法忽视。
路径
那么出路在哪里?
论文没有说”放弃检索”。事实上,它明确指出检索是”正确的工程选择”——可逆、可审计、安全可部署。问题不是检索本身,而是把检索当作学习的替代品。
出路是一个双系统架构,精确地模仿互补学习系统理论所描述的大脑结构:
- 快速系统(海马体/检索):用于即时的案例匹配和经验记录。这是当前的RAG、MemGPT、向量数据库等系统。保持不变。
- 慢速系统(新皮层/整合):用于将积累的经验转化为权重更新。这是当前缺失的部分。需要新的研究。
中间的桥梁是一种”整合机制”——定期地将外部存储中的经验蒸馏、提炼、编码进模型权重。ParamMem已经证明了这种方法的可行性。但如何规模化、如何保证安全性、如何在不破坏已有能力的前提下进行——这些都是开放问题。
这篇论文的副标题是”一个备忘录,不是真正的记忆”。但它的最终信息更积极:备忘录是有用的,真正的记忆也是需要的。两者应该共存,而不是互相替代。
也许最重要的启示是:在AI领域,我们经常犯一种错误——把当前最好的工程折中方案当作足够好的终极方案。检索是2024年最好的折中方案。但2026年的Agent需要的不只是更好的检索——它们需要真正的学习。而真正的学习意味着改变自己,而不仅仅是积累记录。
一个不会因为经验而改变的AI,不管它积累了多少备忘录,永远只是一个拥有大文件柜的新手。