AI做游戏、网站最佳搭配:Codex + Image 2 ,从出图到落地全流程
最近一段时间,一些开发者在社交平台上分享了用 GPT Image 2 和 Codex 协同工作的经验。
GPT Image 2 是 OpenAI 今年推出的图像生成模型,支持复杂构图和非拉丁文字渲染;
Codex 则是同一个生态下的开发环境,可以对话式生成代码、调用工具,现在也内置了 Image 2 的生图接口,不需要单独配置 API Key。
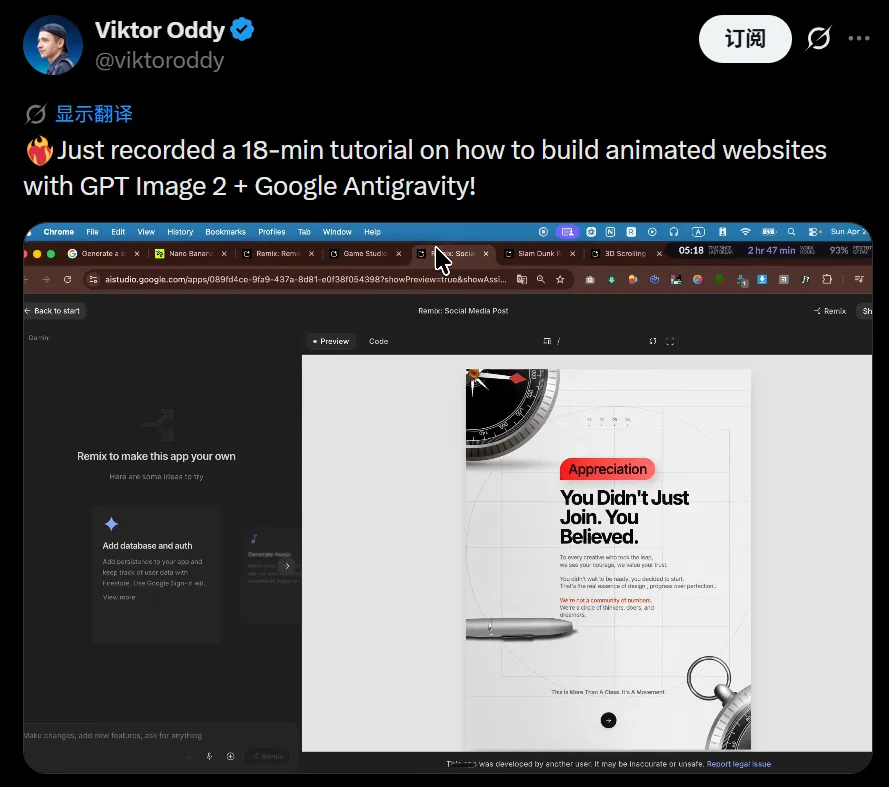
除了此前收集的游戏开发案例,最近一位设计师 Viktor Oddy 也录制了一段完整的建站实操视频,展示了如何用类似的工具链从零搭建一个品牌网站。
把这两类案例放在一起,这套工具链目前的能力边界和使用方法已经比较清晰了。
独立开发者 VibeCreAI 提到他在一次 Game Jam 中,把整个游戏的场景、道具和天空背景全部替换了一遍,总共 106 个素材,用时一天。之前他因为不喜欢手动处理美术资产,所有视觉都用代码生成的占位符凑合。这次他让 Codex 调用 Image 2 生成这批资产,然后直接在游戏里加载。没有导出文件、拖拽素材和手动资产管理的过程。他把这叫做“vibe art”——类似于此前大家说的 vibe coding,只不过换到了美术环节。
另一个开发者 givros 的流程也很接近:先用 Image 2 生成画面,然后让 Codex 把画面切割成精灵图并生成动画,最后由 GPT-5.5 搭建出可玩的浏览器游戏原型。整个过程从一张图到一个可以在网页上操作的游戏,没有离开同一个工具链。
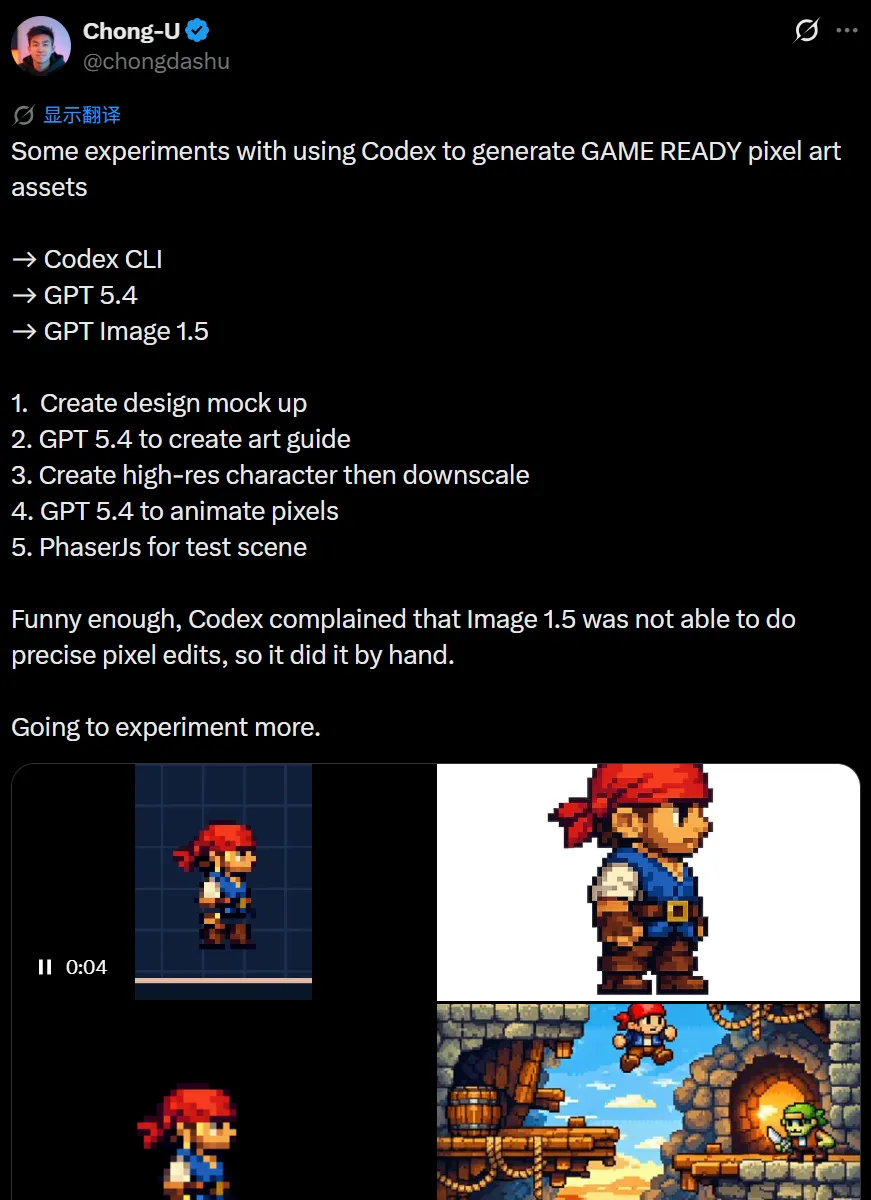
如果想用这套工具做像素风格的游戏,chongdashu 的测试提供了一个细节。他让 Codex 调用 Image 1.5 处理像素画精准编辑时,模型反馈说自己不擅长,结果它选择了自行通过代码去调整像素。也就是说,遇到自身工具的局限时,模型会转而用其他方式完成目标。
规模更大一点的尝试来自 Peter Gostev。他让 GPT-5.5 在 Codex 里规划并生成了 1500 张 2:1 比例的图像,拼合成一个可以在各个方向环顾的“巴比伦空中花园”,效果类似街景地图的行走体验。他在复盘时提到,移动时画面衔接还有跳跃,如果能更精细地规划图像序列,效果应该会更好。
Codex 直接凭空设计网页界面时,生成的结果往往功能没问题但视觉平庸。Peter Gostev 给出的方法分三步:第一步,在对话里用 Image 2 反复调整出一张满意的 UI 设计图;第二步,把这张图交给 Codex 去实现前端代码;第三步,让 Codex 一直对照参考图进行修改,直到界面和设计图尽量对齐。这样就把审美决策留给人,Codex 只负责落地。
Viktor Oddy 录制的完整建站过程,则把这个思路从头到尾演示了一遍。他搭建的是一个游戏风格的品牌展示页,全程没有手动写过一行代码,具体步骤是这样的:
第一步,去 Pinterest 找视觉灵感,确定网站的风格走向。他找了一张合适的场景图作为起点。
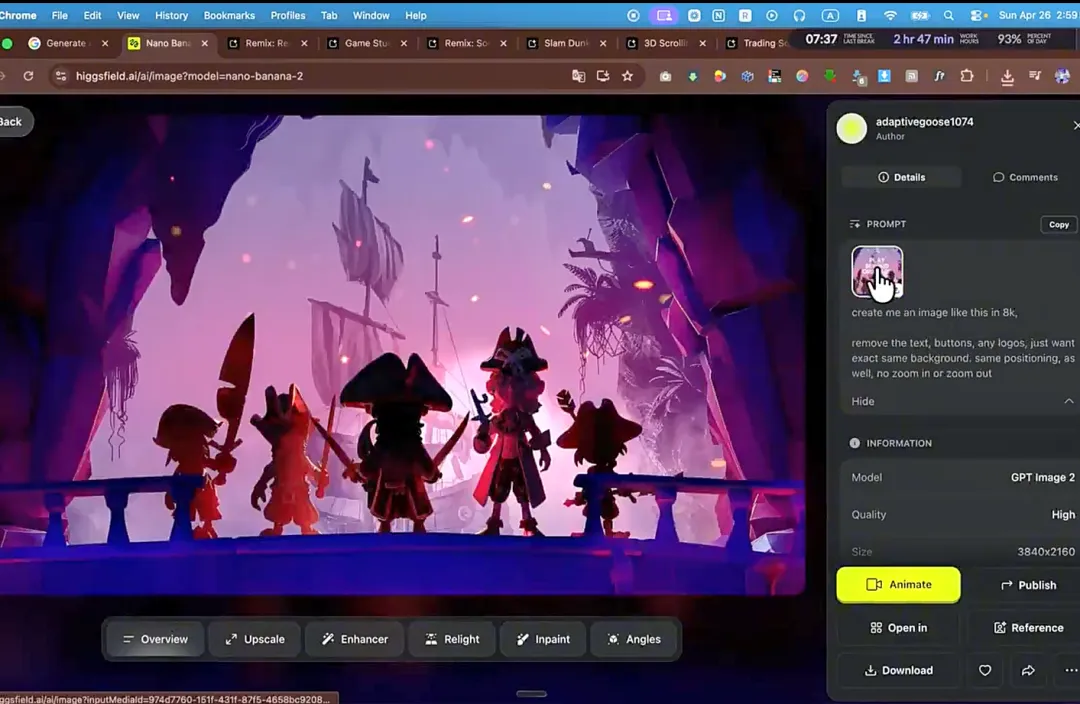
第二步,用 AI 生图工具把这张图拆成前景和背景两个图层。前景保留角色和场景元素,背景换成纯黑色,这样做的目的是为后续做视差滚动效果做准备。如果不用付费工具,直接搜“在线免费去背景”也能完成这一步。
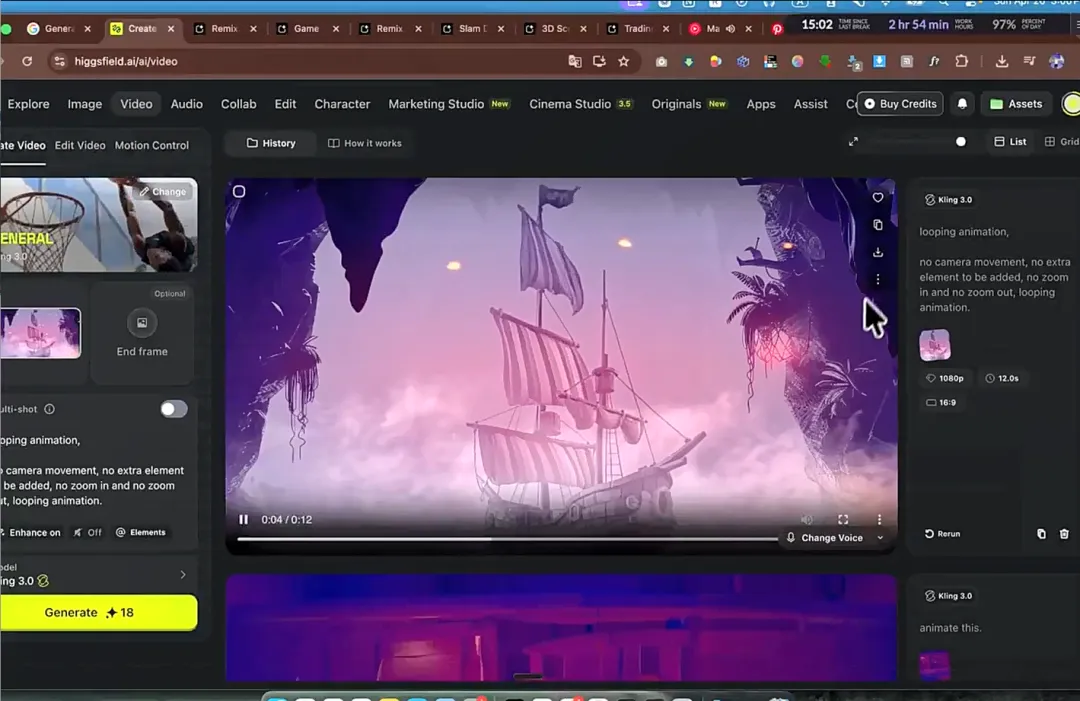
第三步,把前景图导入视频生成工具(他用的 Kling),让画面生成一段循环动画,镜头不动,只是画面内有细微动态。这个动画视频将作为网站 hero 区域的背景。
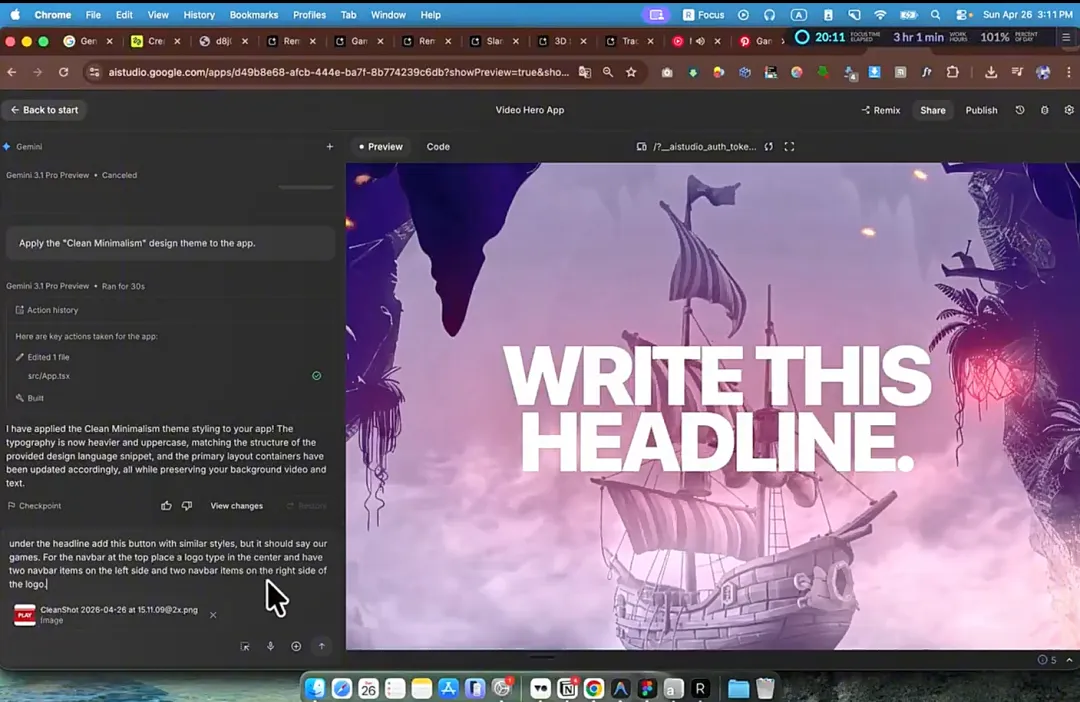
第四步,打开 Google AI Studio,用对话的方式描述页面结构。
他给出的指令大致是:“创建一个 hero 区域,用这个视频做背景,写上标题”。AI 生成了一个包含导航栏和按钮的初始页面。他对自动生成的按钮样式不满意,就去 Pinterest 截了一张游戏风格按钮的参考图,发给 AI 让它参照这个风格重新生成按钮。这一步本质上就是在用参考图纠偏。
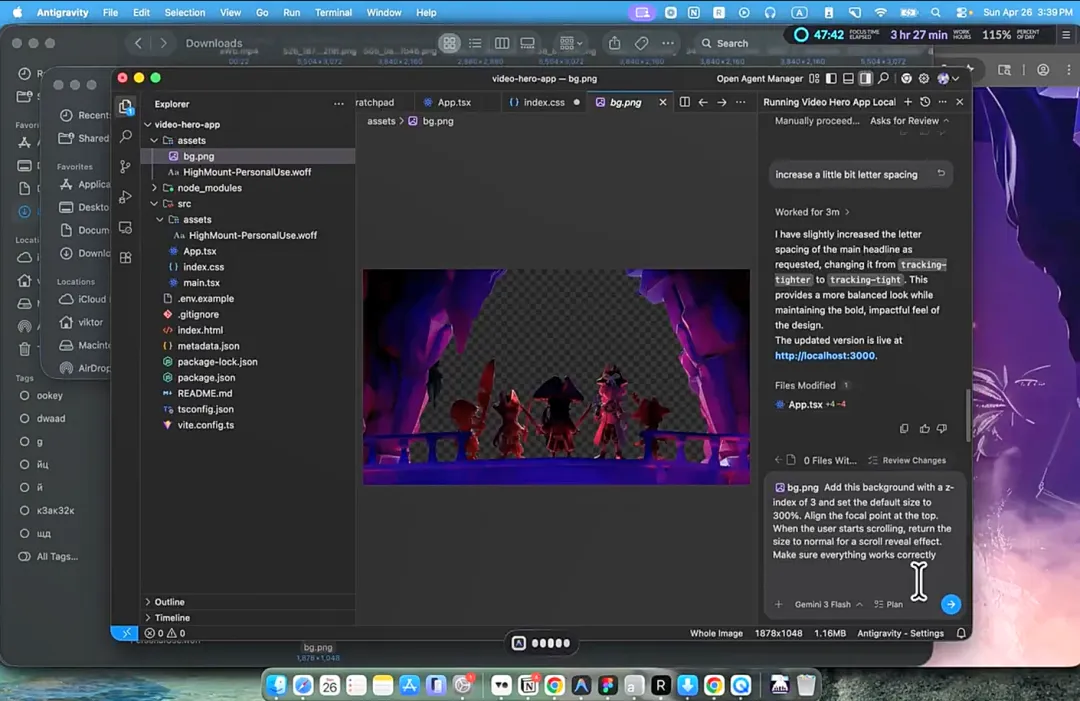
在 Antigravity 里,他把之前准备好的字体文件直接拖进素材库,用对话指令让 AI 把页面字体替换成他选的那一款,同时调整字号和标题文案。然后,他把第二步拆出来的前景图上传,用自然语言描述视差滚动效果——初始尺寸放大到 300%,视点对齐顶部,用户滚动时尺寸恢复正常,并指定了各元素的层级顺序,让前景盖住文字但不会挡住按钮。
他参考了 Landbook 上游戏行业网站的布局,用一段较长的指令同时让 AI 生成“关于我们”板块、数据统计板块、视频背景板块和页脚。对应位置先用占位图,后续替换。
第七步,把剩余的视觉素材上传,同样用对话让 AI 把占位图替换成实际图片,整个页面就完成了。
他的整个操作验证了一个关键点:在这个流程里,AI 不擅长做精准的审美决策,比如颜色搭配和字体选择。人去 Pinterest 或字体库找参考,然后把参考图丢给 AI 去复现,目前是效率最高的分工方式。
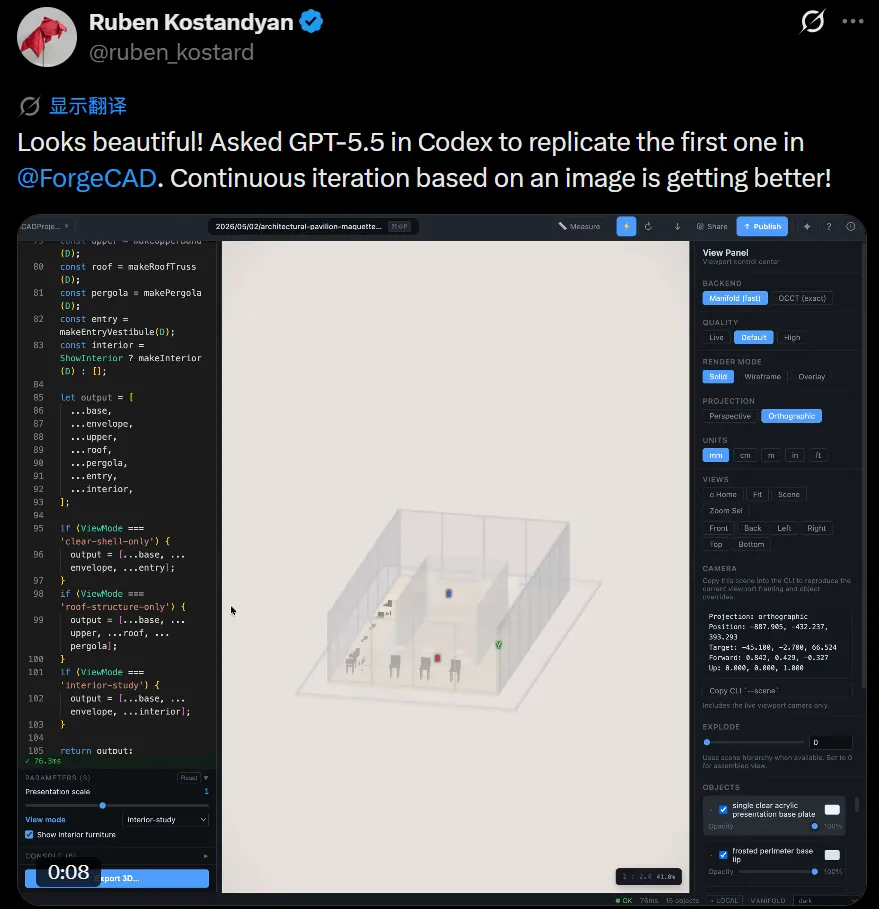
另外,CAD 工具领域也有类似尝试。Ruben Kostandyan 让 Codex 参照 Image 2 生成的建筑造型图,在 ForgeCAD 中复现了模型的结构参数。这说明以图像驱动工程参数生成,不局限于游戏和网页。
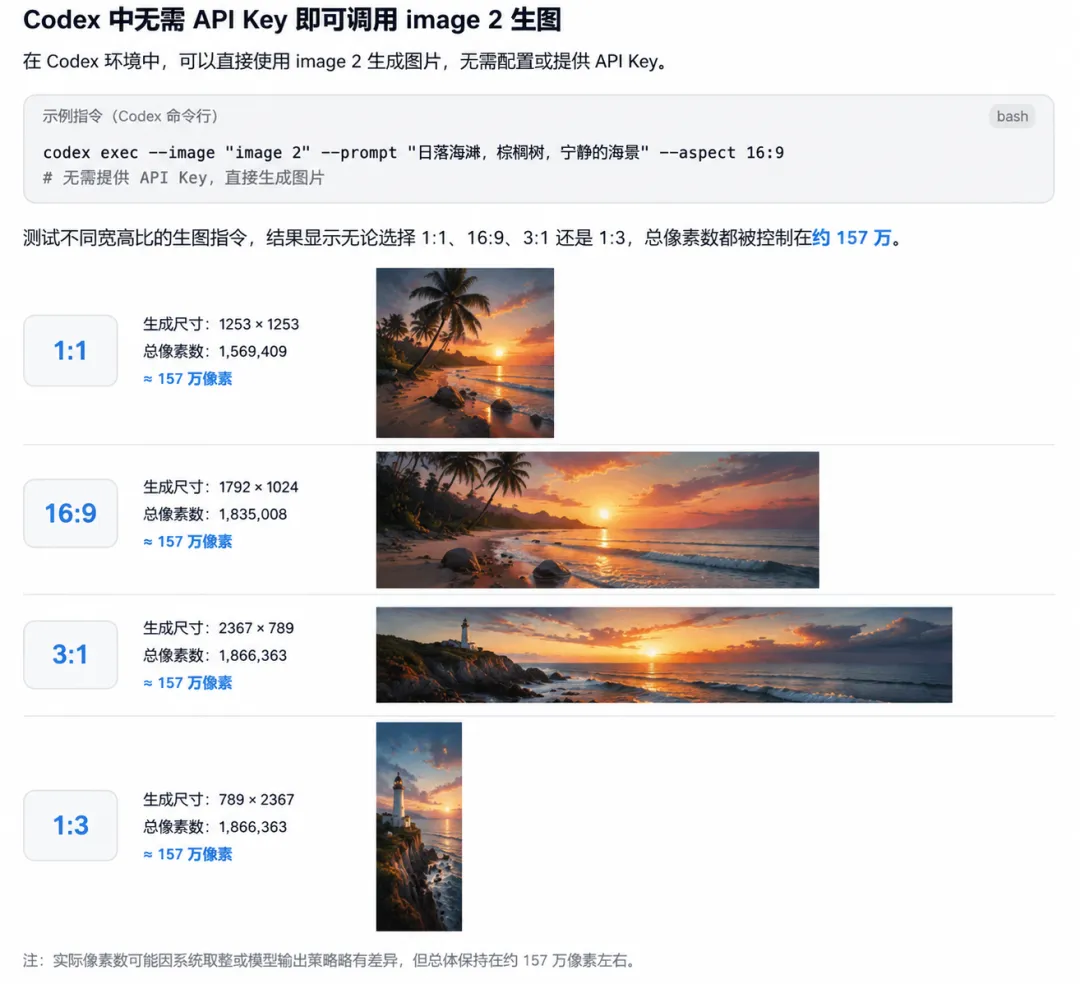
在 Codex 中直接使用 Image 2 时,有开发者发现一个容易被忽略的限制。
Tz_2022 测试了不同宽高比的生图指令,结果显示无论选择 1:1、16:9、3:1 还是 1:3,总像素数都被控制在约 157 万。
对于屏幕显示来说已经够用,但如果有更高分辨率的印刷需求,目前这个限制还绕不过去。
另外,OpenAI 目前正在用 DevDay 门票奖励社区中基于 GPT-5.5 和 Image Gen 的优质作品,说明这条工具链已经是他们现阶段着重推动的方向之一。
这些案例放在一起,指向一个比较清晰的变化:美术资产的制作和 UI 的实现门槛被拉得很低,个人开发者可以把更多时间花在方向和创意上,而不是被实现细节卡住。工具负责做出来,人负责判断好不好看,目前看下来,这是这套工具链最能发挥效率的协作模式。
如果你有类似的使用经验,或者遇到了其他限制,可以在评论区补充。
 夜雨聆风
夜雨聆风