 夜雨聆风
夜雨聆风





AI是怎么来的,为什么到2023年才"爆炸"?
1950年,图灵(Alan Turing)提出了一个问题:“机器能思考吗?”
这就是后来著名的”图灵测试”。如果一台机器和人的对话,让人分不清谁是机器,那就算它会”思考”。这一年被认为是AI的思想原点。

1956年,麦卡锡(John McCarthy)正式造了“人工智能”这个词。
在美国达特茅斯学院,一群年轻人开了个暑期研讨会,参会的有:麦卡锡(后来发明了Lisp语言)、明斯基(后来MIT AI实验室创始人)、香农(信息论之父)。他们预言”再过一代人,AI问题就能解决”——这个预言错了,但会议本身成了AI的诞生地。

1950-1980年代:符号AI时代
这个阶段的AI思路是”把人类知识写成规则”,叫”专家系统”。比如一个诊断疾病的AI,就是医生把”如果发烧+咳嗽=感冒”这种规则写进去。
这条路后来走到了瓶颈,因为世界太复杂,规则根本写不完。这就是第一次”AI寒冬”。投资撤了,预设太高,现实跟不上。
直到1986年,辛顿(Geoffrey Hinton,现在被称为”AI教父”之一)和一帮人重新把”神经网络”这条路捡起来。神经网络不是写规则,而是让机器自己从数据里找规律——这个思路,就是今天所有AI的根源。

但当时算力和数据都不够,神经网络只能解决小问题,没能大火。
1990-2010年代,这个阶段的关键转变是:从”写规则”变成”从数据里学”。这个范式转变,ML(机器学习)正式成为一个学科。
关键人物:
- 弗拉基米尔·万普尼克(Vladimir Vapnik):支持向量机(SVM)之父,统计学习理论的奠基人
- 莱奥·布雷曼(Leo Breiman):随机森林算法,让决策树方法大放异彩
- 汤姆·米切尔(Tom Mitchell):写了第一本机器学习教科书,定义了”机器学习”是什么

这期间还发生了几件大事:
- 1997年,IBM的深蓝超级计算机击败国际象棋世界冠军卡斯帕罗夫,这是AI第一次在智力游戏上打败人类顶尖选手。
- 2006年,辛顿发表论文,提出”深度信念网络”,”深度学习”这个词正式出现。但当时还没引爆,因为数据和算力还不够。
2012年,真正的引爆点。
辛顿的两个学生:亚历克斯·克里切夫斯基(Alex Krizhevsky)和伊利亚·苏茨克维(Ilya Sutskever,后来成了OpenAI的首席科学家),用深度学习模型参加ImageNet图像识别竞赛,错误率比第二名低了整整10个百分点。

这一次,整个学术界和产业界都醒了:深度学习真的能行。
从2012年到2017年,深度学习一路狂奔:
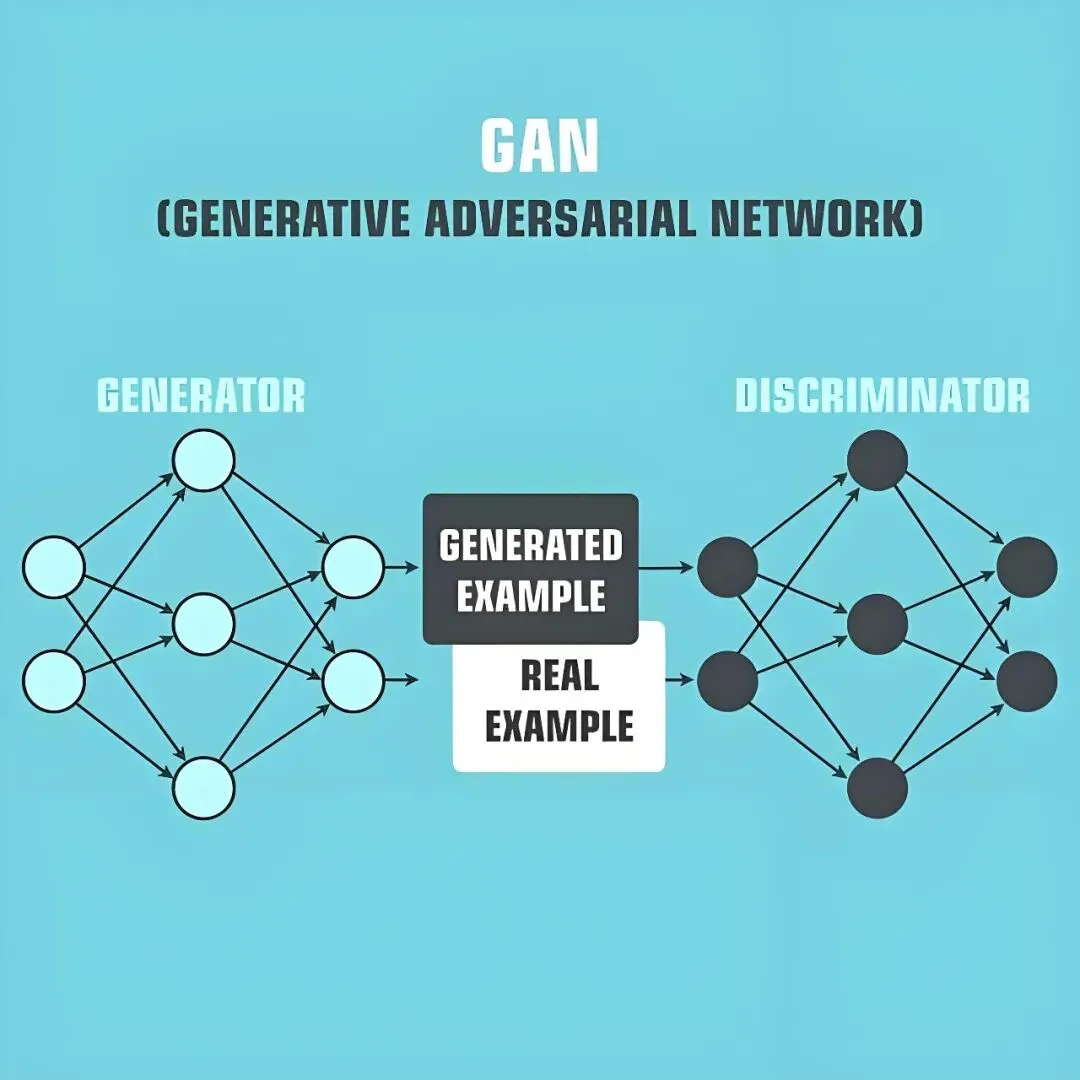
- 2014年,GAN(生成对抗网络)问世,AI开始能”生成”东西,不只是”识别”
- 2015年,ResNet,图像识别准确率超过人类
- 2017年,Google发表论文《Attention is All You Need》,Transformer架构诞生——这是GPT的技术基础,也是今天所有大语言模型的祖先
2012年,今日头条上线,它的核心是一个叫”协同过滤”(Collaborative Filtering)的算法。这个技术不是2012年才发明的。最早可追溯到1990年代,Amazon用它来做”买了这个商品的人还买了什么”。
这是机器学习,但不是大语言模型。它不需要”理解”内容,只需要”发现行为模式”。抖音2016年上线,算法更进了一步。这些技术,全部都是传统机器学习+推荐系统的技术栈,和大语言模型(LLM)的技术栈是两条路。
2017年是分水岭。
Google的《Attention is All You Need》论文发表了Transformer架构。这个架构的特点是:能处理很长的文本、能”记住”上下文、能并行训练(以前的模型只能一个词一个词地算)这个架构出来之后,OpenAI和Google几乎同时意识到:
如果能用一个超级大的Transformer,喂进去整个互联网的文本,会怎么样?
2018年,GPT-1出来了(OpenAI)
- 参数量:1.17亿
- 效果:能写一段还算通顺的文字,但不算惊艳
2019年,GPT-2出来了
- 参数量:15亿
- 效果:开始让人惊讶,但OpenAI当时觉得”这个模型太危险,不公开发布了”——这件事反而让全世界意识到”GPT-2可能已经比大家想象的强很多”
2020年,GPT-3出来了
- 参数量:1750亿
- 效果:这次真的震惊了——GPT-3能写代码、能答题、能做翻译、能写文章,而且只需要给它几个例子就能学会新任务
这时,全世界(包括中国)才真正意识到:这条路能走通,而且会改变一切。
但是为什么中国在大模型上起步晚了。
核心原因不是”技术不行”,是”没人信这件事能成”。
2017-2020年间,中国科技公司的AI投入主要放在两个方向:推荐算法(字节、阿里、腾讯都在做,而且做到了世界顶级),计算机视觉(商汤、旷视、依图、云从,这四家拿到了巨额融资)。这两个方向都是”能快速商业化”的方向。推荐算法直接带来用户时长和广告收入;视觉AI能做人脸识别、安防、支付验证,全是立刻能卖钱的东西。
大语言模型在2020年之前,看起来是”烧钱没回报”的事:
训练一次GPT-3,据估计要花OpenAI约1200万美元的算力成本。训练出来的模型,商业化路径不清晰——2020年的时候,大家还不知道”聊天机器人”能变成什么产品。国内的科技公司都是上市公司或者追求盈利,很难justify”烧几亿人民币做一个不知道能干嘛的模型”
那么,OpenAI为什么能做到?
因为OpenAI从2015年成立开始,就拿了微软等资本的钱,而且它的定位是”做AGI(通用人工智能)”,不是”做能卖钱的产品”。这种”长期主义+不计成本”的打法,国内企业在2020年之前是做不到的。
另外,人才集中度很高。Transformer论文是Google的人写的,GPT系列的核心人物伊利亚·苏茨克维、安德烈·卡帕斯(Andrej Karpathy)都是在美国学术体系里培养出来的。2020年之前,顶尖AI人才基本上都在美国(Google Brain、OpenAI、DeepMind、FAIR)。
中国不是在技术上差,是在“相信这件事能成”上晚了一步。
2022年11月30日,ChatGPT发布。这件事改变了一切。
一周之内,全中国的科技公司都意识到了:
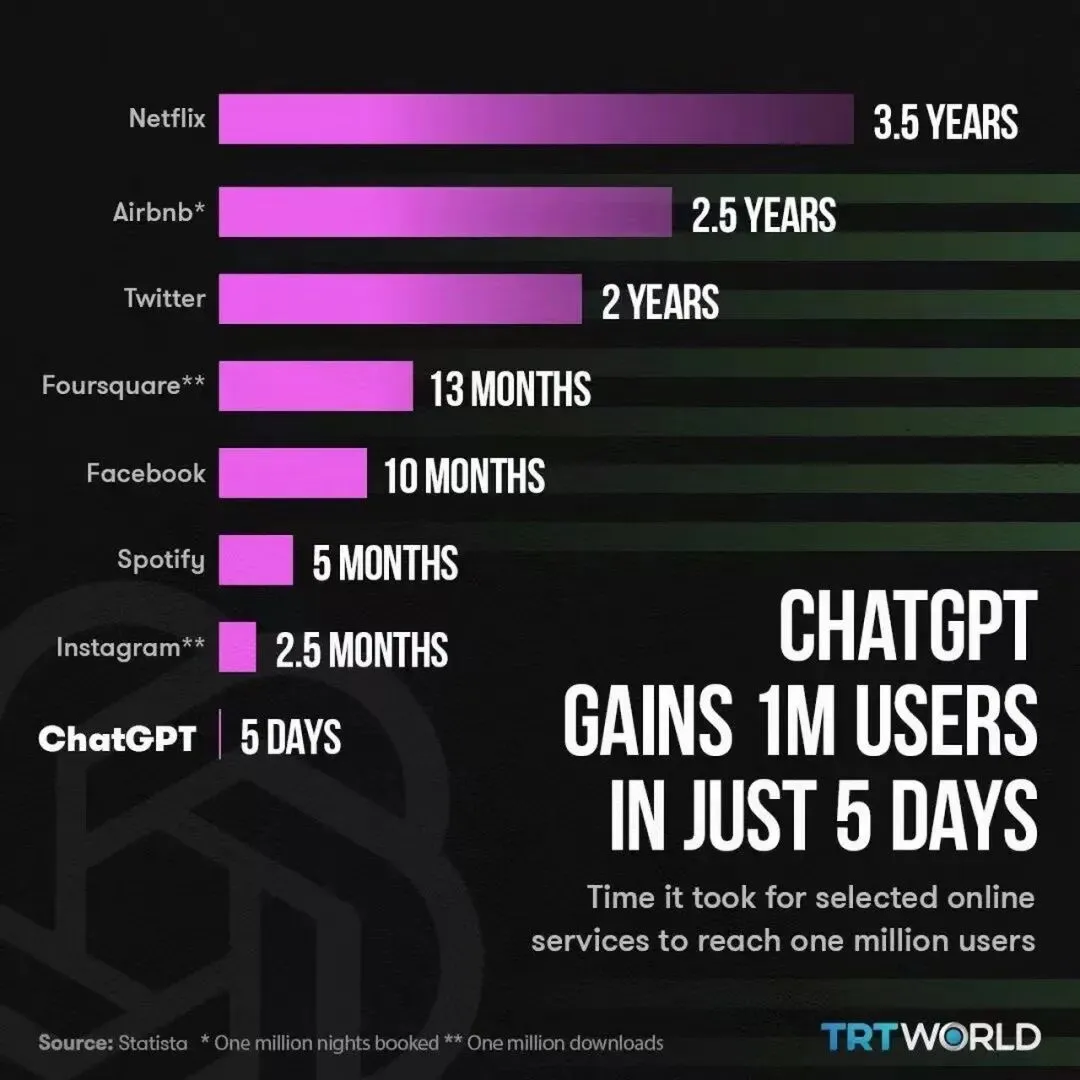
这件事不是”遥远的科研”,是”现在就能用的产品”,而且用户增长速度快到吓人(ChatGPT上线2个月,用户破1亿,人类历史上最快)
这个冲击波带来了几个变化:
第一,国家层面把AI提到了战略高度。2023年开始,国内AI相关政策密集出台,算力建设、大模型备案、数据要素市场,全都在加速。
第二,人才开始回流。在OpenAI、Google、Meta工作过的华人研究员,看到了国内的机会,开始回国创业或者被国内大厂挖走。
第三,开源救了所有人。2023年3月,Meta的LLaMA模型被泄露到网上,全世界的开发者都能拿到一个还算不错的预训练模型,在这个基础上做自己的事。国内的大模型(包括百川、智谱、清华大学ChatGLM)都是在LLaMA的开源基础上快速迭代出来的。
第四,DeepSeek打破了”只有美国能做大模型”的迷信。2024-2025年,DeepSeek连续发布DeepSeek-V3和R1,效果追平GPT-4o,但训练成本只有对手的零头。这件事证明:算法创新可以部分弥补算力差距,中国团队在这方面的能力被低估了。

ChatGPT证明了这件事”能成、能卖钱、能改变格局”。国家、资本、人才、开源社区,四件事同时到位,国内大模型从2023年开始井喷。