 夜雨聆风
夜雨聆风





从源码看 RAG:一次请求到底发生了什么?
很多人以为,RAG(检索增强)只是:
“查点资料 + 丢给大模型”
但在真实系统中,一次请求远比这复杂。
这篇文章不讲概念,而是回答一个更具体的问题:
当用户发出一个问题时,系统内部到底发生了什么?
一、从一个请求开始
假设用户输入:
“公司的报销流程是什么?”
在一个典型 RAG 系统中,这个请求不会直接进入模型,而是会经历一整条处理链路:
Query↓Embedding↓检索(向量 / 关键词)↓候选结果(Top-K)↓Rerank(精排)↓Prompt 构造↓LLM 生成↓返回结果
关键认知:
这不是“一次模型调用”,而是:
一条完整的数据处理流水线(Pipeline)
二、Embedding:不是编码,而是“信息压缩”
第一步:
把 Query 转成向量
很多人把它当作“编码”,但更准确的理解是:
Embedding = 有损语义压缩
会发生什么?
-
原始文本 → 高维向量(768 / 1024 维) -
语义被“映射”,而不是完整保留 -
细节信息会丢失
一个典型现象:
-
“报销流程” -
“费用审批”
在不同模型中:
-
可能很接近 -
也可能偏离
工程结论:
Embedding 决定了召回的“天花板”
如果这一步错了,后面全错。
三、检索:为什么只用向量一定不够
最常见实现:
Top-K 向量相似度搜索
但它有天然缺陷:
向量检索的问题
-
无法精确匹配关键词 -
对结构化字段无感(如时间 / ID) -
对长尾问题极其不稳定
工程真实做法
Hybrid Retrieval = 向量检索 + 关键词检索 + 规则过滤示例架构
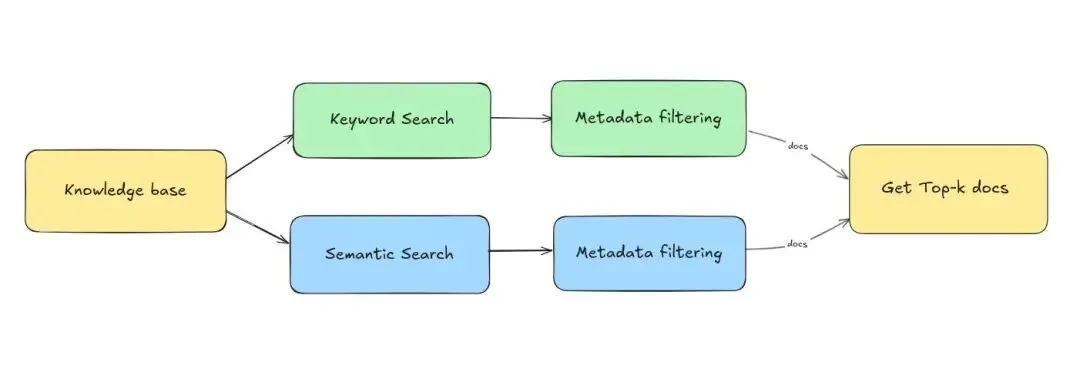
关键认知:
向量解决“语义相似” 关键词解决“精确命中”
四、Rerank:被低估的一步
很多 Demo 没有这一步,但在真实系统中,它是:
效果分水岭
Rerank 在做什么?
输入:
-
Query -
Top-K 文档
输出:
-
排序更准确的 Top-N
为什么必须要?
因为:
-
Embedding 是“粗筛” -
Rerank 是“精排”
常见问题(没有 Rerank):
-
看起来相关,但其实没用 -
噪声进入 Prompt -
模型被误导
一句话总结:
检索决定“有没有”,Rerank 决定“准不准”
五、Prompt 构造:真正的输入设计
这一阶段,本质是:
构造模型的上下文输入
做的事情:
-
拼接检索结果 -
控制 token 数量 -
加入系统指令
但核心问题不是 Prompt 技巧,而是:
信息选择策略
常见坑:
-
上下文太多 → 模型抓不到重点 -
上下文不准 → 幻觉 -
顺序混乱 → 理解错误
更本质的理解:
Prompt ≠ 文本Prompt = 信息压缩后的结构
六、LLM:只是系统中的一个组件
很多人以为:
模型输出 = 结束
但在工程系统中,通常还有:
后处理阶段:
-
格式化(JSON / Markdown) -
截断 / 清洗 -
敏感内容过滤 -
置信度判断
甚至包括:
-
fallback(降级到规则 / FAQ) -
retry(换模型 / 换参数) -
多模型投票(Ensemble)
关键认知:
LLM 不是系统本身,而是系统中的一个模块
七、为什么你的 RAG 效果不稳定?
我们可以把整个流程抽象为:
常见问题定位:
-
Embedding 不匹配 → 语义偏差 -
检索策略单一 → 召回不足 -
缺少 Rerank → 排序错误 -
Prompt 构造问题 → 上下文污染
很少是因为:
“模型不够强”
这是一个典型误区
八、一个更重要的结论
如果你把 RAG 看成:
“给模型加点资料”
那它大概率做不好。
但如果你把它看成:
一个完整的信息检索 + 生成系统
你才会开始真正关注:
-
数据结构设计 -
检索策略组合 -
系统可控性 -
可观测性(日志 / tracing)
这也是从 Demo 到生产系统的分水岭。
九、下一篇
下一篇我们继续往下拆:
为什么 Chunk(分块)策略,决定 RAG 的效果上限?
会重点讲:
-
chunk 大小 vs 召回质量 -
overlap 是否真的必要 -
如何针对业务做分块设计
结尾
很多人以为,RAG 是:
RAG 的本质,不是“增强模型”,而是“约束模型”。
当你开始从“系统”而不是“模型”去理解它时, 你才真正进入了 AI 工程的核心区。