 夜雨聆风
夜雨聆风





我用 AI 给自己写了个亚马逊广告调价软件
好久不见。
最近我用 Claude 和 Codex 的最顶尖的大模型,给自己开发了一款亚马逊广告优化软件——我负责当「产品经理」,模型负责写代码。现在它已经接管了我自己账户的日常广告优化。
这篇就聊三件事:我为什么自己动手、它怎么工作、以及最有意思的——我是怎么和 AI 一步步把调价算法磨出来的。
只关心「能不能用、效果怎样」的朋友,看完第一部分就够了;想看硬核算法的,往后翻。
一、它长什么样,能干什么
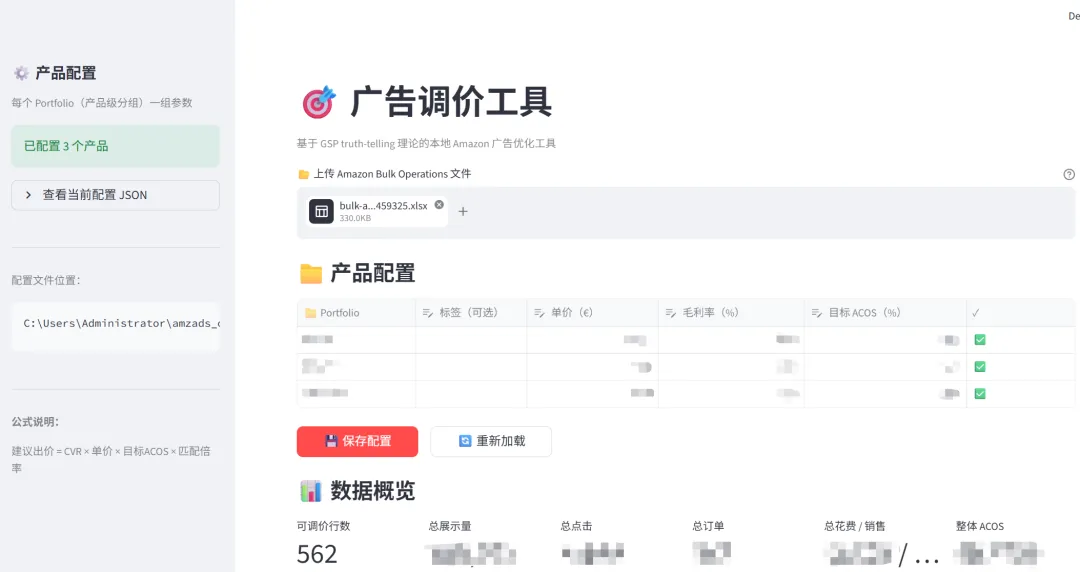
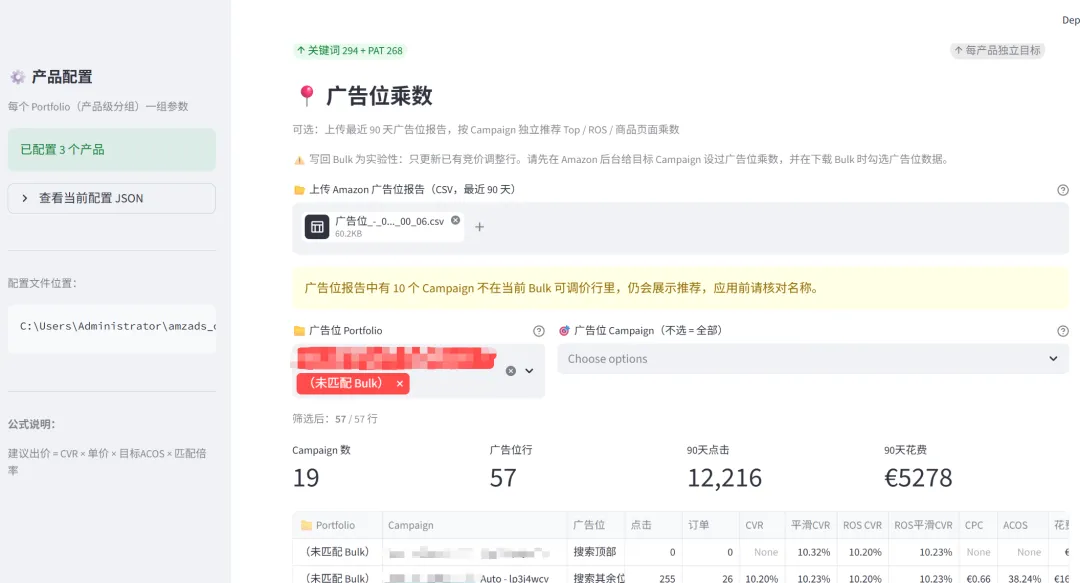
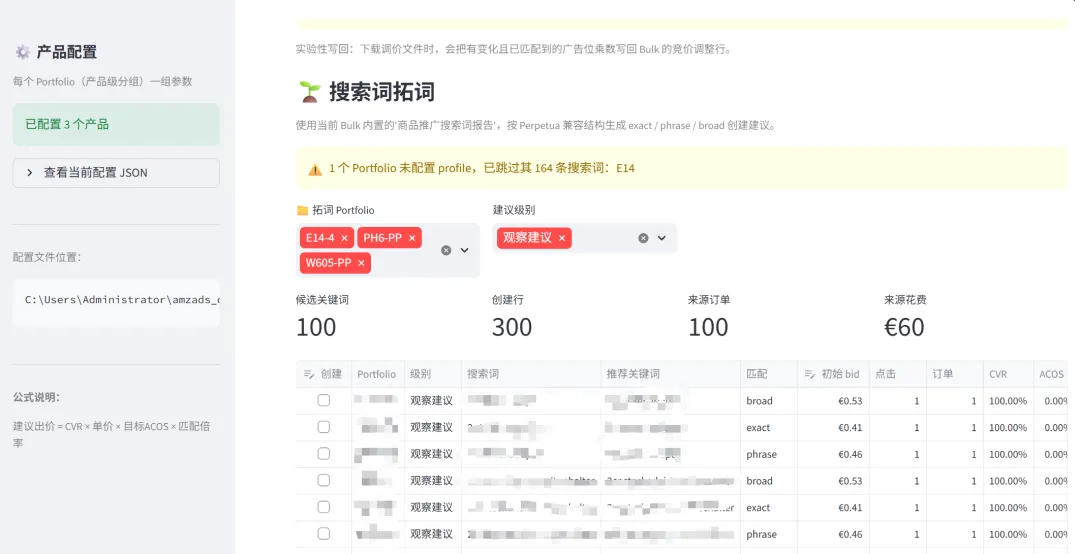
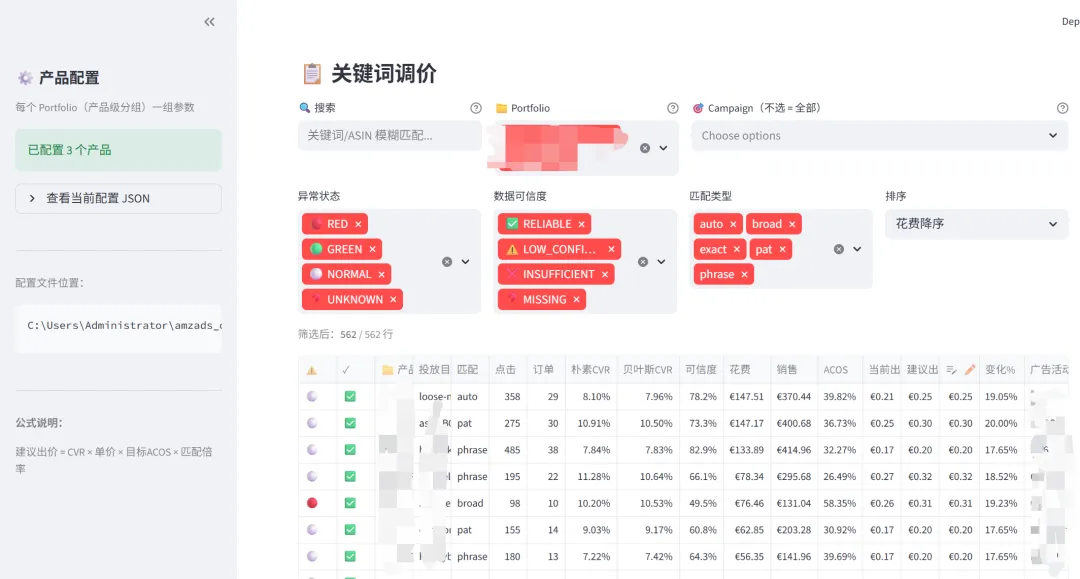
软件大概分 3 个模块:调竞价、调广告位乘数、拓词(拓词还带「同步否定」)。我想着,广告优化的主要活儿,基本都覆盖了。
我为什么想自己开发这个软件?
其实在这之前,我也用过市面上的一些广告托管软件,也学过一些课程,主要是出于学习目的。到最近,我觉得学得差不多了,加上自己店铺规模不大、本身又有点程序员背景——于是萌生了一个念头:干脆自己写一个,帮自己调广告。
和 Claude 多轮讨论之后,这个软件慢慢成型了。它算是个半自动化工具,操作很简单:
从 Amazon 广告后台下载 bulk 表格 → 上传到软件分析 → 下载结果 → 再上传回 Amazon 后台。
目前实测下来功能没什么问题,已经投入使用。
二、和 AI 一起,把调价算法磨了三遍
软件主要参考了 Perpetua 和 SciAds 这两家广告服务商的设计。整个开发过程里,最有意思的就是和 Claude 反复讨论调价算法,一步步升级。
下面这部分稍微硬核,但我尽量讲人话。
先说理论:广告竞价的底层逻辑
亚马逊广告竞价用的是 GSP 拍卖机制(广义第二价格拍卖),规则其实很简单:
-
多个广告主对同一个关键词出价; -
系统按 Ad Rank 排序: Ad Rank = Bid × Quality Score; -
排名第一的广告中标; -
中标者实际付费 = 第二名的 Ad Rank ÷ 自己的 Quality Score + €0.01。
如果假设大家的 Quality Score 都一样,可以简化成一句话:
赢家付的是「第二高出价 + €0.01」,而不是自己出的价。
这个机制有个被数学证明过的结论(Vickrey 等人的二价拍卖理论):老老实实按真实价值出价,是最优策略。
直觉上也好理解:
-
出价高于真实价值 → 可能赢,但赢的时候付的比东西值的还多 → 亏; -
出价低于真实价值 → 可能白白错过本来能赚的机会; -
出价等于真实价值 → 只赢那些「赢了就划算」的拍卖。
那么问题来了:对一次点击来说,我的「真实价值」到底是多少?
答案是:这次点击给我带来的期望毛利润。
点击的期望毛利 = P(转化) × 每单毛利
= CVR × 单价 × 毛利率
举个例子:
单价 = €14.99
毛利率 = 30%
每单毛利 = €14.99 × 30% = €4.50
某关键词 CVR = 8%
→ 真实点击价值 = 8% × €4.50 = €0.36
于是核心出价公式就出来了:
对一个产品来说,单价和毛利率都是固定的。所以调价的全部难点,就浓缩成一件事:预测 CVR。CVR 预测得越准,最终广告的 ACOS 就越接近你设定的目标。
一句话总结:调价公式全行业都差不多,几乎是公开的「业界公式」,没什么神秘的。真正的难点,是 CVR 怎么估准。
难点一:点击太少时,CVR 根本不能信
CVR 的算法很朴素:CVR = 订单数 ÷ 点击数。
问题是:点击数很少的时候,这个数字极不可信。
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
三个关键词的朴素 CVR 看着差不多,但 C 的真实 CVR 可能在 0.3% 到 44.5% 之间——这种数据,直接拿来算出价就是灾难。
那怎么办?我和 Claude 把处理办法迭代了三个版本。
第 0 版(MVP):朴素 + 门控(已废弃)
简单粗暴:
-
点击数 < 10 → 干脆不给建议; -
点击数 ≥ 30 → 用朴素 CVR 算。
缺点也很致命:我账户实测,79% 的关键词被「弃疗」了,啥建议都没有。
第 1 版:经验贝叶斯平滑(已实现)
引入 Beta-Binomial 共轭先验,给 CVR 加一个「全店平均」的底子:
其中:
-
(先验里的「虚拟订单」) -
(先验里的「虚拟非订单」) -
= 全店平均 CVR -
= 先验强度(默认 100)
直觉:数据少的时候,往全店平均靠;数据多的时候,相信它自己的真实表现。 这样小样本关键词也能给出一个靠谱的估计,不用再「弃疗」。
第 2 版:分层贝叶斯先验(当前方案)
再进一步,把「全店平均」这个底子,细化到 (Portfolio, 匹配类型) 这个维度:
数据不够,就一层层往上兜底:
-
(Portfolio, 匹配类型) —— 数据够(≥30 点击)就用这个; -
(Portfolio, 任意匹配类型) —— 不够就回退到 Portfolio 层; -
全店 —— 再不够就用全店兜底。
这套思路不是我拍脑袋的,背后有成熟理论撑着:经验贝叶斯(Robbins, 1956)、分层贝叶斯(Gelman《BDA》第 5 章)、以及 James-Stein 估计量——「向群体均值收缩能严格降低误差」是被证明过的。
难点二:匹配类型的「经验倍率」,对我的店铺错得离谱
这一段我觉得最值得卖家看,因为它直接推翻了一个流行做法。
早期方案(已弃用):硬编码倍率
一开始我参考行业经验值,给不同匹配类型设了「衰减系数」:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
看着挺合理对吧?但拿我自己店铺的真实数据一比,错得离谱:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
1.11 |
|
|
|
1.42 |
|
|
|
|
|
|
|
|
我的 Broad 实际比 Exact 还强 42%,可「经验倍率」却把 Broad 的出价打到六折——严重低估! 按这套倍率调价,等于亲手掐死自己最能转化的流量。
当前方案:让数据自己说话
现在我不再硬编码倍率,而是把匹配类型的差异,直接交给上面那套分层贝叶斯去学。比如我店铺实测:
-
(W 产品线, broad) 群体 CVR = 10.84% -
(W 产品线, exact) 群体 CVR = 7.92%
这个差异会自动进入每个关键词的 CVR 估计里。所以公式里的倍率,我现在全部设成 1.0:
MATCH_TYPE_MULTIPLIERS = {
"exact": 1.00,
"phrase": 1.00,
"broad": 1.00,
"auto": 1.00,
"pat": 1.00,
}
🔔 划重点:网上那些「匹配类型出价倍率」的经验值,请务必用你自己的历史数据校准,别照抄。每个店铺的真实情况,可能跟「经验」完全相反。
接口我还留着——以后想给某些「噪声大」的匹配类型加个风险折扣,可以再调;但它不再用来校准 CVR 差异了。
调价的算法,目前就是这样,效果如何还得交给时间验证。
但我想说:大多数广告运营调价用的公式其实都一样,这几乎是公开的业界共识,没什么神秘的,难点永远在 CVR 的预估上。再往上,就是结合你自己的运营策略去调目标 ACOS——想冲销量,那就牺牲点利润,反之亦然。
三、它离 Perpetua 这种成熟软件,还差多远?
软件投入使用后,我回过头问了 Codex 一个问题:这玩意儿离市面上的成熟产品,到底差多少? 下面是它给我的回答(我做了点整理):
坦白说:现在已经从「玩具工具」进入「可用的本地半自动广告工作台」了,但距离 Perpetua / SciAds 这种成熟 SaaS,还有一段明显距离。
已经比较接近的部分:
-
关键词 / PAT 调价:bulk 解析、Portfolio 配置、贝叶斯 CVR、分层先验、导出写回,都有了; -
广告位乘数:能给经验贝叶斯推荐,也能写回; -
搜索词拓词:能从搜索词报告里发现好词,自动生成 exact / phrase / broad; -
Auto 收割配对否定:已经开始接近 Perpetua 的 harvesting 逻辑; -
本地透明:每一条建议背后的公式、阈值、原因都看得见,不像黑盒 SaaS。
还差比较多的部分:
-
自动化频率:人家是 API 每天自动拉数、调价、建词、否词;我还是手动下载 / 上传 bulk; -
状态记忆:成熟软件有历史数据库,知道某个词之前建过没、否过没、传成功没;我目前主要靠当前这张 bulk 快照; -
安全机制:SaaS 有预算保护、异常回滚、失败重试;我现在还得靠自己人工小批量验证; -
语义与结构识别:Perpetua 可能还会结合账户结构、商品、历史表现做语义聚类;我目前只做保守规则; -
报表与监控:成熟工具有趋势、归因、A/B、预算 pacing;我这个偏「操作工具」,还不是经营看板; -
API 闭环:我没直接接 Amazon Ads API,所以没有真正的无人值守闭环。
Codex 还给各模块打了个分(满分 10):
关键词 / PAT 日常调价: 6.5 / 10
广告位乘数: 5.5 / 10
搜索词拓词 + 配对否定: 5.5 / 10
透明可解释性: 8.5 / 10
自动化闭环: 2.5 / 10
商业 SaaS 完整度: 4.5 / 10
但它也点了一句很关键的话:
你的使用场景,不一定需要一个完整的 Perpetua。 你不是在管几百个 ASIN、几千个 campaign 的团队账户。你需要的只是:每隔几天把 bulk 下下来,工具给出稳定、可解释、可复核的调价 / 拓词 / 否定建议,然后你小批量上传。这件事,它已经越来越能替代了。
至于下一步怎么拉近差距,Codex 的建议是——别再堆复杂算法了,做好这三件事就够:
-
历史数据库:记录每次导入、建议、导出、上传后的结果,让工具知道「自己以前做过什么」; -
上传后校验:下次 bulk 进来时,自动检查上次建的词 / 否定是否真的生效了; -
拓词 / 否词闭环:不只发现好词,也能识别坏词、重复流量、auto / manual 内部竞争。
做完这三块,它就能从「强力 bulk 助手」进化成「本地版小 Perpetua」。用它的话说:核心发动机已经有了,仪表盘和自动驾驶还没装全。
写在最后
对我自己来说,我觉得它已经满足了我 99% 的需求。
我现在的广告工作流,简化成了:从 Amazon 导出 bulk → 过一遍软件 → 导回 Amazon。 大部分调价、拓词的活儿就干完了。我甚至可以主动避开像 Prime Day 这种大促活动日的异常数据,不让它们污染算法。
既省下了每月几百刀的订阅费,又把我从重复劳动里解放出来。我觉得挺棒的。
接下来,就是观察它长期跑下来的实际效果了。
欢迎做亚马逊的朋友一起交流。👋