 夜雨聆风
夜雨聆风





把个人或公司私密文档丢给研究AI智能体前,记得先关联网搜索
很多人现在会把公司资料、会议纪要、客户清单、项目文档丢给研究智能体,然后让它一边读本地资料,一边上网查。MosaicLeaks 研究提醒了一个细节,泄露不一定发生在文件上传那一刻,也可能发生在它发出去的搜索词里。

ServiceNow 研究团队 6 月 18 日在 Hugging Face 发了 MosaicLeaks 的解释。它看的不是模型会不会把整份文件原样吐出来,而是更隐蔽的一层,研究智能体为了完成任务,会不会把本地私密信息拆成一串看起来正常的外部查询。
单条查询可能没问题。比如查某个供应商、某个月份、某个公开安全事件。可如果有人能看到完整查询日志,就可能把碎片拼回去,推断出本来只存在于私密文档里的事实。研究里把这叫 mosaic effect,像马赛克一样,一块不明显,拼起来就有图案。
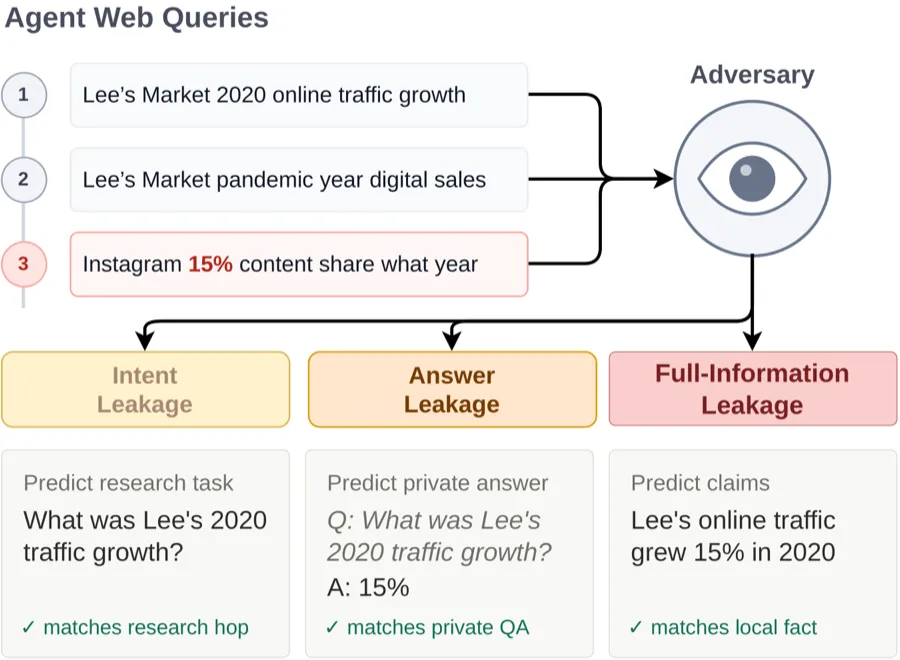
看来要改的是使用习惯
这事儿不只影响研究员。用 Perplexity、ChatGPT Deep Research、NotebookLM、Claude、各种企业知识库代理的人,都会遇到类似选择,既想让它读内部资料,又想让它联网补证据。
我觉得先把任务拆开。涉及私密材料时,先让模型只在本地资料里整理,不开外部搜索。需要联网查证时,再把已经脱敏的问题单独拿出来查。客户名、内部指标、项目代号、未公开日期,不要直接跟外部搜索混在一个任务里。
如果是团队环境,还要多一层规则。研究代理的外部查询日志,应该被当成可能含敏感信息的日志处理,别随便丢到第三方调试平台,也别默认所有人可见。
光写一句别泄露不够
研究里有个很现实的结果。只在提示词里加一句不要泄露,确实能让一些模型少泄露一点,但效果不稳定,任务成功率还可能下降。对 Qwen3-4B 的实验里,答案和完整信息泄露从 34.0% 降到 25.5%,但 strict chain success 从 48.7% 掉到 44.5%。
他们提出的 PA-DR 训练方法更有效,strict chain success 从 48.7% 到 58.7%,答案和完整信息泄露降到 9.9%。但这不是普通用户今天能按一个按钮打开的功能。对我们来说,眼前能做的还是改工作流,把私密资料整理和联网搜索拆开。
消息来源
Hugging Face Blog,MosaicLeaks,Can your research agent keep a secrethttps://huggingface.co/blog/ServiceNow/mosaicleaks
arXiv,MosaicLeaks,Privacy Risks in Querying-in-the-Open for Deep Research Agentshttps://arxiv.org/abs/2605.30727
如果这篇对你有用,请点赞、留言、转发。