 夜雨聆风
夜雨聆风





千万文档级 RAG 如何逼近零幻觉
文章拆解一个面向千万级文档的 RAG 流水线,重点是如何通过检索、约束、验证和弃答,把幻觉压到接近零。
向 RAG 系统中塞入的文档越多,它“编造答案”的空间也就越大;当语料规模增长到数百万、逼近 10M 乃至更高时,幻觉问题只会进一步恶化。想要在这种规模下依然让答案可信,就必须构建一条这样的流水线:让 agent 自行核查证据,并为每一条结论附上引用。这与 Claude 使用引用的核心思路一致。
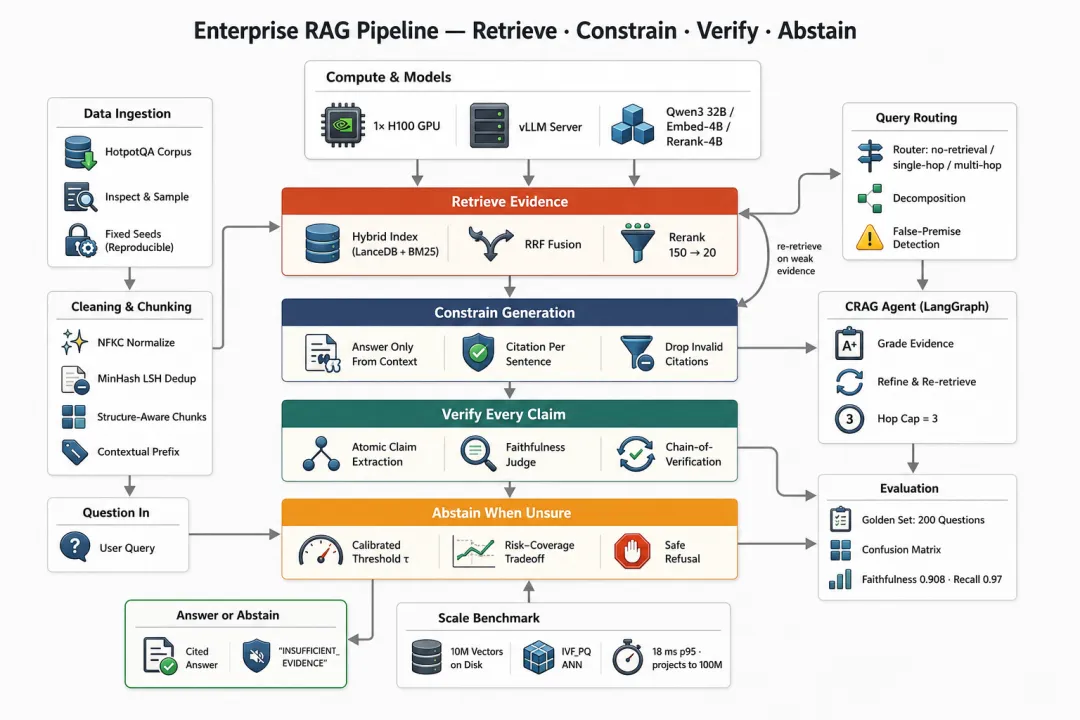
这条流水线包含的全部组件如下。我们会自上而下逐步搭建,每次只完成一个组件:
-
搭建环境并准备数据:下载语料库,检查其规模并查看真实样本,同时固定所有随机种子,确保整个流程可复现。 -
清洗与切块:规范化文本,使用 MinHash LSH 去除近重复内容,再按文档结构切分为 chunk,并为每个 chunk 添加一行上下文前缀。 -
构建混合索引:将每个 chunk 同时保存为 LanceDB 中的稠密向量和稀疏 BM25 posting,并落盘存储,以支持 10M+ 向量规模。 -
检索与重排:用 reciprocal rank fusion 融合稠密检索与稀疏检索的排序结果,再将 150 个候选重排为 20 个。 -
路由与分解:先对问题分类,再在检索前把多跳问题拆解为多个子问题。 -
带引用生成:答案必须严格基于上下文生成,每句话都带引用;如果证据不足,则输出 abstain token。 -
核验每一条 claim:将答案拆分为原子级 claim,并用 faithfulness judge 对照其引用文本逐条检查。 -
不确定时拒答:将各类信号汇总为一个经过校准的决策;当支持证据不足时,直接拒绝回答。 -
接入 agent:把上述组件串联成一个可自我纠错的 CRAG 循环,在证据较弱时触发重新检索。 -
评估与扩展:先在一个包含 200 个问题的 golden set 上评估幻觉率,再将索引基准测试扩展到真实的 10M 向量规模,并推算到 100M。
全部代码都已发布在我的 GitHub 仓库中(Theory + Code):
GitHub – FareedKhan-dev/rag-zero-hallucinations: Handling 10M+ docs using RAG with zero…[1]Handling 10M+ docs using RAG with zero hallucinatons – GitHub – FareedKhan-dev/rag-zero-hallucinations: Handling 10M+…
千万文档级 RAG 如何逼近零幻觉
-
接近零,而非绝对零 -
项目初始化 -
获取数据 -
清洗语料 -
切块与上下文 -
加载检索模型 -
构建混合索引 -
检索:融合与重排 ∘ Reciprocal rank fusion ∘ 重排 -
路由与分解 -
带引用生成 -
验证闸门 -
何时应当拒答 -
Agent -
它真的有效吗? ∘ Golden set ∘ 幻觉集中在一个单元格里 ∘ 安全性的代价 ∘ 这个 judge 靠谱吗? -
扩展到 10M+ 向量 ∘ 真实的 10M 向量索引 ∘ 千万规模下 18 ms,以及对 100M 的推算 ∘ 时间都花在哪 -
适用范围与下一步
接近零,而非绝对零
我们要解决的问题,不是“让模型更聪明”。即便换成更大的模型,只要检索没有返回有效结果,它依然会猜;因为“猜”本来就是生成模型的默认行为。
所以,与其追求一个完美模型,不如把一个普通模型包裹进一套系统里,并且让它只有一种安全的失败方式:当证据缺失时,正确输出不该是流畅却未经证实的猜测,而应该是拒答。

这就形成了四层控制机制,后文每一节都对应其中一层。
-
检索到正确证据:混合稠密检索与 BM25 检索、上下文化 chunk,以及重排。 -
约束生成:只能基于上下文作答;每句话都必须引用 passage id;否则就拒答。 -
核验每一条原子级 claim:使用 faithfulness judge,将每条 claim 与其引用文本逐一比对。 -
拒答:当 claim 支持度或检索置信度低于校准阈值时,拒绝回答。
我们的目标有两个,而且必须同时达成。第一个是 可信性:对于我们选择回答的问题,幻觉率要接近于零。
第二个是 规模化:检索底座必须能够承载 10M+ 向量,并且仍然在毫秒级返回结果。前者依赖验证逻辑,后者依赖索引能力。
这两者我们都会构建。
项目初始化
在实现任何逻辑之前,先把项目本身搭起来。整体计划是:导入所需库,固定所有随机种子以保证可复现性,检查我们可用的那一块 GPU,把一个轻量客户端指向生成模型,并冻结配置,使无头运行在每次执行时都保持一致。

首先是导入依赖,以及一个统一设置所有随机数生成器种子的函数。
import json, os, random, subprocess, timefrom dataclasses import dataclass, asdict, fieldimport numpy as npdefset_determinism(seed: int) -> None:"""Seed every RNG we touch so runs are reproducible.""" random.seed(seed) np.random.seed(seed) os.environ["PYTHONHASHSEED"] = str(seed)try:import torch torch.manual_seed(seed) torch.cuda.manual_seed_all(seed)except Exception:passset_determinism(42)我会在最开始固定随机种子,因为不可复现的 RAG 评测根本不能算评测;而这篇博客的核心目的,就是让读者能够信任最终给出的那些数字。这个 notebook 也做了参数化处理,因此只需一个单元格就能解析本次运行配置,并打印接下来将采用的构建环境。
#### OUTPUT ####profile=FULL slice=20000 eval=100+100 artifacts=/mnt/data/artifacts这次跑的是完整配置:20,000 个 passages,以及 100+100 道评测题;不是我最开始用来低成本排查代码错误的那个微型 smoke profile。我们只使用单张 GPU,所以 VRAM 是一项刚性预算,而不是运行到一半才发现的意外限制。为此,我们先用 nvidia-smi 读取显卡信息,并通过断言确认当前硬件确实符合预期。
defgpu_report() -> dict:"""Return GPU name / memory / driver and assert we are on an 80GB H100.""" name = _smi("name")[0] total = float(_smi("memory.total")[0]) / 1024.0# GiB rep = {"name": name,"total_gb": round(total, 1),"free_gb": round(float(_smi("memory.free")[0]) / 1024.0, 1),"driver": _smi("driver_version")[0] }print(json.dumps(rep, indent=2))assert"H100"in name and total >= 79# one 80GB H100, nothing smallerreturn rep#### OUTPUT ####{"name": "NVIDIA H100 PCIe","total_gb": 79.6,"free_gb": 32.8,"driver": "570.195.03"}我们运行在一张 80 GB 的 NVIDIA H100 上;配套主机还有 180 GB 内存和 750 GB NVMe 磁盘。随着索引规模增大,这些资源在后文会变得很关键。32B 生成模型并不直接运行在这个 notebook 里。
它部署在独立的 vLLM server 中,我们通过一个小型的 OpenAI-compatible client 与之通信。把它常驻在独立进程里并保持热启动状态,意味着我们可以反复重跑这个 notebook,而不必每次都重新加载模型。
classLocalLLM:"""面向预热完成的 vLLM OpenAI-compatible server 的轻量客户端。"""def__init__(self, endpoint: str, model: str, thinking: bool = False):self.endpoint, self.model, self.thinking = endpoint.rstrip("/"), model, thinkingdefchat(self, system: str, user: str, temperature: float = 0.0, max_tokens: int = 512) -> str: body = {"model": self.model,"temperature": temperature,"max_tokens": max_tokens,"messages": [ {"role": "system", "content": system}, {"role": "user", "content": user} ] }ifnotself.thinking:# Qwen3:关闭 <think> trace,以获得更低延迟 body["chat_template_kwargs"] = {"enable_thinking": False} r = requests.post(f"{self.endpoint}/chat/completions", json=body, timeout=120) r.raise_for_status()return r.json()["choices"][0]["message"]["content"]llm = LocalLLM("http://localhost:8000/v1", "Qwen/Qwen3-32B")print(f"[llm] up={llm.is_up()}")#### OUTPUT ####[llm] up=True服务已经启动。最后一步配置工作,是把所有可调参数固定到一个配置对象里并打印出来,这样后文所有实验数字都集中在同一个地方。
#### OUTPUT ####{"gen_model":"Qwen/Qwen3-32B","embed_offline":"Qwen/Qwen3-Embedding-4B","rerank_model":"Qwen/Qwen3-Reranker-4B","chunk_tokens":256,"chunk_overlap":32,"retrieve_k":150,"rerank_top_n":20,"rrf_k":60,"max_hops":3,"crag_ok":0.7,"crag_bad":0.4,"tau_claim":0.3,"tau_abstain":0.3,"seed":42}这里的设置是:先召回 150 个候选,再重排压缩到 20 个;允许 agent 最多进行 3 次纠错跳转;并把两个支持度阈值都先设为 0.3,后面再做校准。生成模型使用 Qwen3–32B,Embedding 和 Reranker 使用 Qwen3 的 4B 模型,而负责判断忠实性的也是同一个 32B 模型。
我把生成器固定在 temperature 0,同时关闭 thinking trace,因为我需要结果可复现、延迟尽可能低;另外,采样本身也是模型偏离已提供证据的一个额外入口。这里所有模型都采用本地部署的开放权重 Qwen3,这也是整套方案成立的前提:文档和查询都不离开这台机器。正因如此,这样的 pipeline 才真正适用于私有语料库。
工具准备好之后,就可以开始取数据了。
获取数据
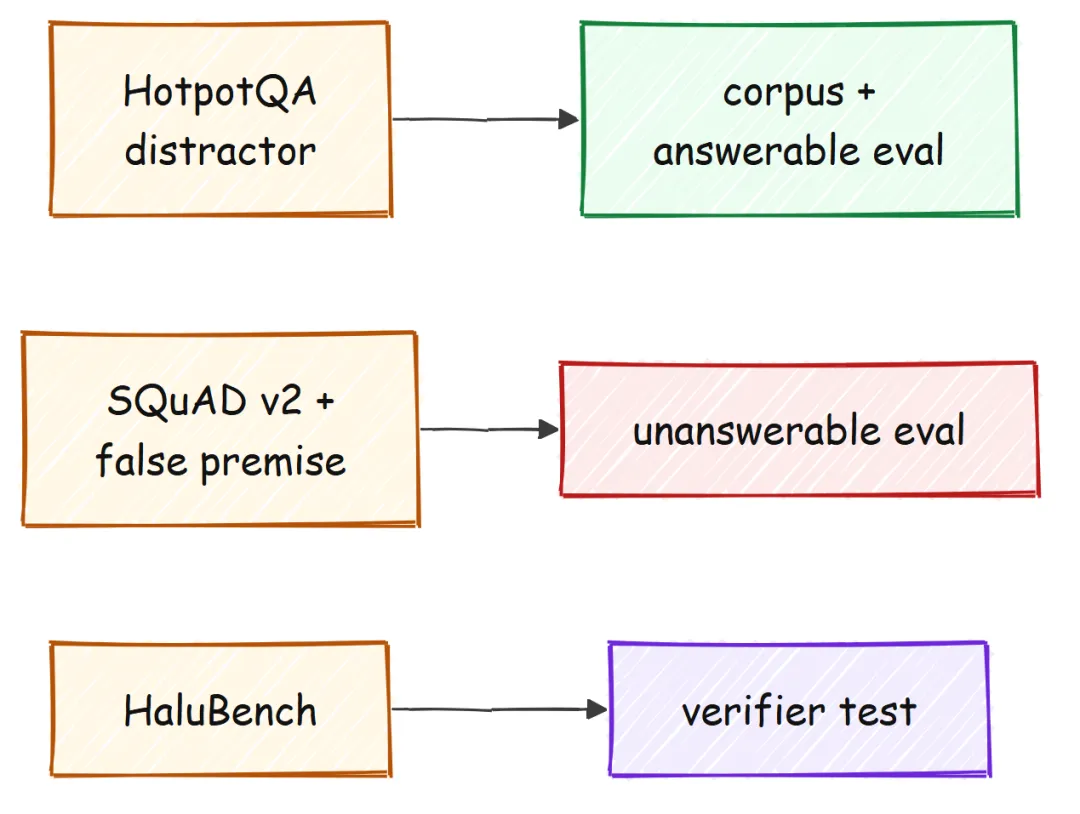
一个 pipeline 的上限,取决于它下面那层 corpus 的质量。因此第一步真正要做的事,是先下载数据集并实际看一遍。我选择 HotpotQA 的 distractor 设置,主要有两个原因。
首先,它的每个问题都附带句子级别的 gold supporting facts,这为后续评估检索召回率提供了最干净的打分依据;其次,它自带的 Wikipedia 段落天然就是一套可直接使用的真实 corpus。为了测试另一面,我又引入了 SQuAD v2 中的 impossible questions,并手工写了少量 false-premise questions,因为要衡量幻觉,唯一可靠的方法就是故意提出 corpus 无法回答的问题,再检查系统是否真的保持沉默。
第三组数据 HaluBench 会在接近结尾时出现,它唯一的用途是验证 verifier 本身。真正用来构建和检索的 corpus,还是 HotpotQA。
from datasets import load_datasetdefload_hotpotqa(split: str = "validation"):# datasets 3.x wants the namespaced repo idreturn load_dataset("hotpotqa/hotpot_qa", "distractor", split=split, cache_dir=DS_CACHE)hotpot = load_hotpotqa()print(f"[data] hotpotqa(validation) = {len(hotpot)} questions")#### OUTPUT ####[data] hotpotqa(validation) = 7405 questions也就是说,这里一共有 7,405 个问题,并且每个问题都附带了其对应的 Wikipedia 段落来源。接下来,我们先定义 passage 和 question 的数据结构,再实现一个构建器:把所有问题的上下文段落合并成一个统一语料库,同时记录哪些 passage 是对应问题的 gold evidence。
@dataclassclassPassage:id: str title: str text: str is_gold_for: list[str] = field(default_factory=list)@dataclassclassQAItem: qid: str question: str answer: str answerable: bool gold_titles: list[str] = field(default_factory=list) gold_sentences: list[str] = field(default_factory=list) qtype: str = ""classCorpusBuilder:"""Build a passage corpus + QA items from HotpotQA distractor contexts."""defbuild(self, qa, n_passages: int): passages, qa_items = {}, []for ex in qa: gold = list(dict.fromkeys(ex["supporting_facts"]["title"]))for t, ss inzip(ex["context"]["title"], ex["context"]["sentences"]): para = " ".join(s.strip() for s in ss).strip()iflen(para) < 40:continue p = passages.setdefault(_pid(t, 0), Passage(_pid(t, 0), t, para))if t in gold: p.is_gold_for.append(ex["id"]) qa_items.append(QAItem(ex["id"], ex["question"], ex["answer"], True, gold_titles=gold, qtype=ex.get("type", "")))iflen(passages) >= n_passages:breakreturnlist(passages.values()), qa_itemscorpus, qa_items = CorpusBuilder().build(hotpot, SLICE_SIZE)print(f"[corpus] passages={len(corpus)} qa_items={len(qa_items)} gold-bearing passages={sum(1for p in corpus if p.is_gold_for)}")#### OUTPUT ####[corpus] passages=20007 qa_items=2073 gold-bearing passages=4072现在,我们手里有 20,007 个 passages 和 2,073 个问题,其中 4,072 个 passages 被标记为某些问题的 gold evidence。在基于这些数据继续构建系统之前,应该先真正看一眼数据本身:既要看规模分布,也要看一个真实样本。
import pandas as pdtok_lens = [len(p.text.split()) for p in corpus]print(pd.Series(tok_lens, name="passage_word_count").describe().round(1).to_string())ex = qa_items[0]print(f"\nSample question:\n Q: {ex.question}\n A: {ex.answer} (type={ex.qtype})")print(f" gold titles: {ex.gold_titles}")for s in ex.gold_sentences:print(f" - {s}")#### OUTPUT ####count 20007.0mean 89.2std 53.4min7.025% 54.050% 80.075% 113.0max1378.0Sample question:Q: Were Scott Derrickson and Ed Wood of the same nationality?A: yes (type=comparison)gold titles: ['Scott Derrickson', 'Ed Wood']- Scott Derrickson (born July 16, 1966) is an American director, screenwriter and producer.- Edward Davis Wood Jr. was an American filmmaker, actor, writer, producer, and director.这些 passage 的平均长度约为 89 个词:既足够短,能在一个 prompt 中容纳几段;又足够长,能够承载完整事实。上面的示例是一个比较型问题:“Were Scott Derrickson and Ed Wood of the same nationality?” 它对应的两条 gold sentence 已经直接给出答案:两人都是 American。
在这篇博客里,我会一路跟踪这个问题贯穿整个流程。因为让一个真实问题走完整条 pipeline,最能把每个组件讲清楚、讲具体。这里其实已经能看出两个层次。
像这个例子这样“可回答”的问题,可以用来衡量系统是否找回了正确证据;而我后面加入的“不可回答”问题,则用来衡量幻觉。因为如果系统会对语料库中根本没有支持证据的问题作答,那它本质上就是在编造答案。
清洗语料库
垃圾输入,往往就会产出幻觉。所以在建立索引之前,必须先把文本清洗干净。这里有两个成本很低、但收益极高的步骤。其一是标准化,它能让 tokenizer 在所有 passage 上都表现一致;其二是近重复去重,它可以避免被复制或转发的段落挤占检索结果前列,造成“看似召回变高、实则没有新增证据”的假象。

import re, unicodedatadefnormalize_text(s: str) -> str: s = unicodedata.normalize("NFKC", s) # canonical unicode form s = s.replace("", "") # drop soft hyphens s = re.sub(r"[ \t]+", " ", s) # collapse runs of spacesreturn s.strip()我首先做 NFKC 标准化,因为 BM25 是基于原始字符做分词的:一个连字,或者一串意外空白,都可能把一个词拆成两个,或者把两个词粘成一个,从而在不知不觉中损害召回率。对于脏文本,这个函数的效果正是我们想要的。
#### OUTPUT ####>>> normalize_text("the final report\twas ready")'the final report was ready'连字 "fi" 会被还原成普通的 "fi",制表符和连续空格也会折叠成单个空格。这样一来,那些仅仅因为不可见字符不同而有差异的 passage,就会得到完全一致的分词结果。
更有意思的是去重部分。这里我必须选择像 MinHash LSH 这样的近似方法,而不能做两两精确比较。因为精确的 pairwise comparison 是二次复杂度,在语料库规模上根本跑不完;而带有 LSH 索引的 MinHash 则能以近似线性的时间找出近重复内容。
删除这些近重复内容,可以同时服务两个目标。一方面,当我们朝着 10M vectors 的规模推进时,它能让索引更小;另一方面,它还能防止同一段文字的三份拷贝挤满检索结果前列。后者是一种很隐蔽的问题:retriever 会把冗余上下文喂给模型,让模型对单一来源产生过度信任。
classDeduper:"""通过基于词 shingles 的 MinHash LSH 去除近重复段落。"""def__init__(self, threshold: float = 0.9, num_perm: int = 64):self.threshold, self.num_perm = threshold, num_permdeffit_transform(self, passages: list[Passage]): lsh = MinHashLSH(threshold=self.threshold, num_perm=self.num_perm) kept, dropped = [], 0for p in passages: m = self._mh(p.text)if lsh.query(m): dropped += 1continue lsh.insert(p.id, m) kept.append(p)return kept, {"kept": len(kept), "dropped_near_dup": dropped}#### OUTPUT ####{ "kept": 19987, "dropped_near_dup": 19, "input": 20007, "after_quality": 20006, "after_dedup": 19987}去掉 19 个近重复段落和 1 个过短片段后,我们最终保留了 19,987 个 passages。这份语料只是经过筛选的一部分,但清洗流程本身无需改动——无论输入规模是两万个 passages,还是两千万个,跑的都是同一套步骤。
切块与上下文
接下来要把 passages 切成 chunks。最省事的做法是固定长度切块,但这往往也是错误的做法,因为它会把承载实体信息的句子,从用于消歧的上下文里硬生生切开;对多跳问题来说,这几乎是致命的。
因此,我们采用按句子打包的方式:在 token 预算内尽量放入完整句子,并保留少量重叠。同时,token 计数直接使用生成模型自己的 tokenizer,这样预算才与模型实际看到的内容一致。看似只是切块细节,实则是幻觉问题的一个隐藏来源。
如果某个 chunk 超出预算后被悄悄截断,恰好包含答案的那一句就可能直接消失。这样一来,问题会在没有任何真实理由的情况下,看起来像是“无法回答”。所以我宁可遵守句子边界,多付出几个 chunks 的代价,也不愿承担这种风险。

classStructureAwareChunker:def__init__(self, tokenizer, target_tokens: int = 256, overlap: int = 32):self.tok, self.target, self.overlap = tokenizer, target_tokens, overlapdefchunk(self, passage: Passage) -> list[Chunk]: sents = split_sentences(passage.text) or [passage.text] chunks, cur, cur_tok = [], [], 0for s in sents: st = self._ntok(s)if cur and cur_tok + st > self.target: chunks.append(self._make(passage, cur)) cur, cur_tok = ([cur[-1]], self._ntok(cur[-1])) ifself.overlap else ([], 0) cur.append(s) cur_tok += stif cur: chunks.append(self._make(passage, cur))return chunks#### OUTPUT ####[chunk] 19987 passages -> 21259 chunks (tokens: mean=125 p95=236)最终我们得到 21,259 个 chunks,平均长度 125 tokens,距离 256 的预算上限还有充足余量。不过,在建立索引之前,还有一个问题必须先解决。
像 “revenue grew 3 percent that quarter” 这样的 chunk,单独拿出来其实是不可检索的,因为“谁的 revenue”以及“哪个 quarter”都丢了。为了解决这个问题,我们在建立索引前,先给每个 chunk 前面补上一句用于定位语境的单行说明。这就是 contextual retrieval 的思路,只不过这句话不是由托管模型生成,而是由我们本地部署的 Qwen3 来写。
CONTEXTUALIZE_PROMPT = ("下面是一篇标题为 '{title}' 的文档:\n<document>\n{doc}\n</document>\n\n""下面是其中的一个分块:\n<chunk>\n{chunk}\n</chunk>\n\n""请用一句简短的单句上下文(<=25 words)说明这个分块在整篇文档中的位置,""让它即使脱离原文也能被单独检索。只返回这句话。")这种做法会把每个 chunk 的调用分发到线程池中并行执行,因为这些调用彼此独立,而且 vLLM 会在服务端自动做 batch,所以速度远快于逐个 chunk 串行处理。我们还会把结果做 checkpoint,因此重新运行时可以直接跳过这一步。
classContextualizer:defcontextualize(self, chunks, doc_lookup, workers: int = 32):def_one(c): user = CONTEXTUALIZE_PROMPT.format( title=c.title, doc=doc_lookup.get(c.passage_id, c.text)[:4000], chunk=c.text, ) ctx = self.llm.chat("You write concise retrieval context.", user, max_tokens=64).strip() c.contextual_text = (ctx + "\n" + c.text) if ctx else c.textwith ThreadPoolExecutor(max_workers=workers) as ex:list(ex.map(_one, chunks))return chunks#### OUTPUT ####Before: Ed Wood is a 1994 American biographical period comedy-drama film directed and produced by Tim Burton, and starring Johnny Depp as cult filmmaker Ed Wood...After (context-prefixed): This chunk introduces the 1994 film *Ed Wood*, directed by Tim Burton, and outlines its main subject and cast. Ed Wood is a 1994 American biographical period comedy-drama film...多出来的只是一个额外句子:每个 chunk 只需一次很短的生成,成本很低,却能在 chunk 本身语义不够明确时,直接告诉 retriever 这段内容到底在讲什么。召回率之所以能做到这么高,主要就靠这一步。
而召回率,正是整个“幻觉问题”的根基。因为下游的 verifier 只能基于检索阶段真正找到的证据来约束答案;如果证据没被召回,它就无从判断、无从落地。所以,我在这里多买到的每一点 recall,最终都会转化成一个“可以回答”的问题,而不是一个“只能拒答”的问题。
加载检索模型
chunk 准备好之后,就该加载那些把它们变成“可搜索证据”的模型,以及后续用于答案校验的模型了。这里一共有 3 个模型与 generator 共享同一块 GPU,所以每加载一个模型,我们都会记录一次 VRAM 快照,确保始终不超预算。此处先加载 reranker 和 faithfulness judge;embedder 会稍后在构建索引时再加载。
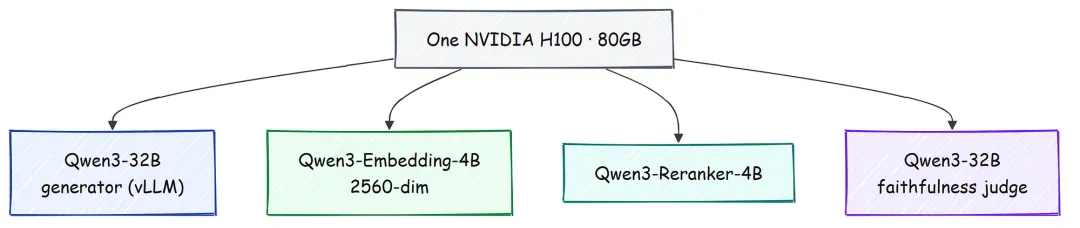
我们不希望在 3 个步骤之后,才以 out-of-memory crash 的形式发现显存超限。因此,每次加载都会同时记录 nvidia-smi 给出的整卡显存占用,以及 torch 给出的当前 kernel 进程显存占用。
defvram_snapshot(tag: str) -> dict:"""在每个加载步骤后记录整块 GPU 和当前 kernel 的 VRAM 使用情况。""" kernel = round(torch.cuda.memory_allocated() / 1024**3, 2) used = round(float(_smi("memory.used")[0]) / 1024.0, 2)print(f"[vram] {tag:22} gpu_used={used}GB kernel={kernel}GB")return {"tag": tag, "gpu_used_gb": used, "kernel_gb": kernel}重排器(reranker)是一个小型因果模型,作为“是 / 否”裁判使用。对每个 query 与 document 配对,我们都会套进固定模板,再直接从下一 token 的 logits 里读取分数,因此对每个候选文档的重排只需要一次 forward pass。之所以加载专用的 cross-encoder reranker,而不是直接相信 embedding 分数,是因为 embedder 会把整段文本压缩成单个向量:这样做扫描整个语料库足够快,但会模糊两类内容之间的差别——一种只是顺带提到了相关实体,另一种则是真正回答了问题。而恰恰是这种区分,决定了错误证据能否被挡在 prompt 之外,最终也挡在答案之外。
classQwen3Reranker:"""根据模型赋给 'yes' token 的概率,为 (query, doc) 对打分。""" @torch.no_grad()defscore(self, query: str, docs: list[str], batch_size: int = 16) -> list[float]: out = []for i inrange(0, len(docs), batch_size): batch = [self._fmt(query, d) for d in docs[i:i + batch_size]] enc = self.tok( batch, return_tensors="pt", padding=True, truncation=True, max_length=1024 ).to(self.model.device) logits = self.model(**enc).logits[:, -1, :] # last-token logits yn = logits[:, [self.no_id, self.yes_id]] # compare 'no' against 'yes' probs = torch.softmax(yn.float(), dim=-1)[:, 1] # keep P('yes') out.extend(probs.cpu().tolist())return outclassQwen3Reranker:"""根据模型赋给 'yes' token 的概率,为 (query, doc) 对打分。""" @torch.no_grad()defscore(self, query: str, docs: list[str], batch_size: int = 16) -> list[float]: out = []for i inrange(0, len(docs), batch_size): batch = [self._fmt(query, d) for d in docs[i:i + batch_size]] enc = self.tok( batch, return_tensors="pt", padding=True, truncation=True, max_length=1024 ).to(self.model.device) logits = self.model(**enc).logits[:, -1, :] # last-token logits yn = logits[:, [self.no_id, self.yes_id]] # compare 'no' against 'yes' probs = torch.softmax(yn.float(), dim=-1)[:, 1] # keep P('yes') out.extend(probs.cpu().tolist())return outfaithfulness judge 直接使用 32B 生成模型本身,并通过 prompt 要求它针对某条 claim 与给定 context 返回一个单一的支持分数。我把本地 32B 设为 judge,是因为 RAG 里的 faithfulness 检查,本质上是在多段长文本上下文中核对一条 claim;而这正是小型 sentence-pair NLI 模型最容易变得脆弱的场景。更重要的是,这个 judge 是整个系统里唯一一个能把“听起来很自信但实际上错误”的回答,硬生生拦成 abstention 的组件。
它是“近乎零幻觉”这一结论的核心,因此我宁愿把手头最强的模型优先用在这里。NLI cross-encoder 和 MiniCheck 仍然接入了系统,作为更轻量的备选方案,但这次运行实际使用的是 LLM judge。
JUDGE_PROMPT = ("You are a strict fact-checker. Decide whether the CONTEXT supports the CLAIM.\n\n""CONTEXT:\n{context}\n\nCLAIM: {claim}\n\n""Output ONLY a number: 1.0 if the context clearly states or entails the claim, ""0.0 if it contradicts or does not mention it, or a value in between.")classJudgeVerifier:def_score(self, claim: str, context: str) -> float: out = self.llm.chat("You are a strict faithfulness grader.", JUDGE_PROMPT.format(context=context[:6000], claim=claim), max_tokens=8 ) m = re.search(r"01?", out)returnmin(1.0, float(m.group())) if m else0.0#### OUTPUT ####[vram] reranker gpu_used=54.3GB kernel=7.49GB[verifier] using the local LLM as faithfulness judge[vram] whole-GPU used=54.3GB / 80.0GB (need >= 3.0GB headroom)JUDGE_PROMPT = ("You are a strict fact-checker. Decide whether the CONTEXT supports the CLAIM.\n\n""CONTEXT:\n{context}\n\nCLAIM: {claim}\n\n""Output ONLY a number: 1.0 if the context clearly states or entails the claim, ""0.0 if it contradicts or does not mention it, or a value in between.")classJudgeVerifier:def_score(self, claim: str, context: str) -> float: out = self.llm.chat("You are a strict faithfulness grader.", JUDGE_PROMPT.format(context=context[:6000], claim=claim), max_tokens=8 ) m = re.search(r"01?", out)returnmin(1.0, float(m.group())) if m else0.0#### OUTPUT ####[vram] reranker gpu_used=54.3GB kernel=7.49GB[verifier] using the local LLM as faithfulness judge[vram] whole-GPU used=54.3GB / 80.0GB (need >= 3.0GB headroom)整套系统总共占用了 H100 提供的 80 GB 中的 54.3 GB,因此后续构建索引时仍然留有余量。judge 不需要额外的 VRAM,因为它复用了已经运行在 vLLM server 中的 generator。整个流程始终都在同一台机器上完成,没有任何一步调用外部 API。
构建混合索引
接下来进入索引阶段。这里的关键问题是:任何单一 retriever 都不够用。Dense embeddings 擅长捕捉语义改写,这正适用于“问题和答案使用了不同措辞”的场景。
BM25 擅长命中精确 token,例如名称、ID 和数字,而这恰恰是 dense 模型最容易“抹平”的信息。因此,我们同时建立两套索引,并以 chunk id 作为键,索引对象都是加入上下文后的文本。
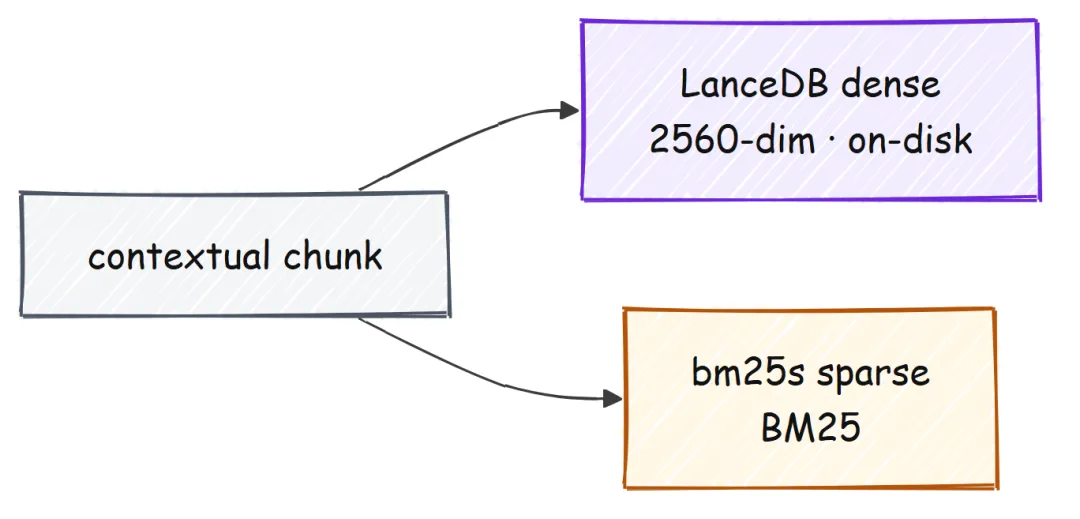
Embedding 模型只在建立索引时加载:先为每个 chunk 生成向量,完成后立即释放;真正处理查询时,则换用更小的在线 embedder。所有向量都会做归一化,因此 cosine similarity 可以直接退化为普通点积。
defembed_texts(embedder, texts, is_query: bool = False) -> np.ndarray: kw = {"normalize_embeddings": True, "convert_to_numpy": True, "batch_size": 64}if is_query: kw["prompt_name"] = "query"return embedder.encode(texts, **kw).astype("float32")把查询用的 embedder 加载进来,是最后一个会继续推高 VRAM 占用的步骤;下面这份快照展示了最终落点。
#### OUTPUT ####[vram] embedder(online) gpu_used=61.85GB kernel=15.04GB峰值大约是 80 GB 中的 62 GB,仍在预算之内。索引构建完成后,我会立刻释放更重的离线 embedder,这样常驻内存、负责查询的就只剩下小型在线模型。dense 检索这一侧我必须选 LanceDB,因为它是嵌入式、可直接落盘到 NVMe,而且不需要额外运行服务器。这意味着同一套代码路径就能承载一个远大于 RAM 的索引;正是这一点,让这套设计在后续扩展到 10M+ 向量时,无需改动一行代码。
dense 检索层本身只是对它做了一层很薄的封装。唯一需要注意的细节,是要把 cosine distance 再换算回 0 到 1 区间内的相似度。
classLanceVectorStore:defsearch(self, qvec: np.ndarray, k: int) -> list[tuple[str, float]]: res = self.tbl.search(qvec).metric("cosine").limit(k).to_list()return [(r["id"], 1.0 - r["_distance"] / 2.0) for r in res]除了向量索引,我还会并行保留一份 lexical bm25s 索引。原因很直接:dense embedding 最容易把稀有名称、ID 或数字与它们的“邻居”混在一起,而事实性问题往往恰好依赖这些 token。换句话说,sparse 检索就是一道保险,防止系统基于“差一点对上”的段落,给出一个看似自信、实则错误的答案。sparse 侧会先用与文档相同的 stemming 方式处理查询,再按 BM25 分数返回最匹配的结果。
classBM25Index:defsearch(self, query: str, k: int) -> list[tuple[str, float]]: q = bm25s.tokenize(query, stemmer=self.stemmer) idx, scores = self.retriever.retrieve(q, k=min(k, len(self.ids)))return [(self.ids[int(i)], float(s)) for i, s inzip(idx[0], scores[0])]#### OUTPUT ####[index] LanceDB on-disk: /mnt/data/artifacts/lancedb | bm25 over 21259 chunks针对这 21,259 个 chunk,整套索引落盘后大约只有 11.1 MB,体积很小;但这里真正重要的不是大小,而是架构形态。LanceDB 把向量存放在 NVMe 上,而不是压进 RAM,因此同一套代码路径可以容纳一个远超内存容量的索引。这正是我们在文章最后把设计推进到千万级向量时所依赖的关键特性。
检索:融合与重排
倒数排名融合
现在我们手上有两份排序结果:一份来自 dense 检索,一份来自 sparse 检索,接下来必须把它们合并起来。这里最容易踩的坑是,二者的分数根本不可直接比较,因为 BM25 分数和 cosine similarity 本来就处在不同量纲和尺度上。
Reciprocal rank fusion 完全绕开了这个问题。它不看分数,只看名次:给每个结果分配一个权重,计算方式是 1 / (k + rank),然后把它在两份列表中的权重累加起来。
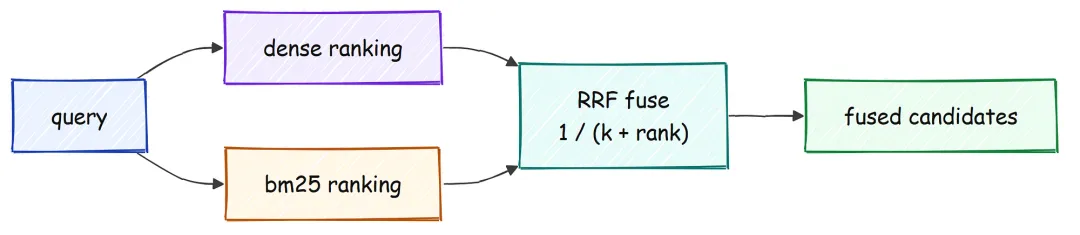
defrrf_fuse(rankings: list[list[str]], k: int = 60) -> list[tuple[str, float]]: scores: dict[str, float] = {}for ranking in rankings:for rank, cid inenumerate(ranking):# 排名越靠后,贡献越小,而且不需要做分数归一化 scores[cid] = scores.get(cid, 0.0) + 1.0 / (k + rank + 1)returnsorted(scores.items(), key=lambda x: -x[1])这个机制看代码比用文字解释更直观。来看两个很短的排序结果:dense 列表和 sparse 列表彼此不一致,观察融合之后会发生什么。
#### OUTPUT ####>>> rrf_fuse([["a", "b", "c"], ["b", "c", "a"]])[('b', 0.03252), ('a', 0.03227), ('c', 0.03200)]尽管 b 在两个列表里都不是第 1,但它最终胜出,因为它在两边都排得足够靠前。这正是这种方法的核心。
当两个不同的 retriever 都倾向于同一个结果时,它会压过那些只被其中一个 retriever 强烈偏好的结果。之所以要做融合,就是因为这两类 retriever 的失败模式并不相同。
Dense search 往往会漏掉罕见的专有名词:如果某个词在 embedding 空间里附近没有它“见过”的相似内容,就可能检不出来;而 sparse search 则容易漏掉改写表达:如果文本与查询语义一致、但几乎不共享词面,它就很难命中。把两者融合起来,就能找回原本会被任一单独检索器丢掉的文档。整个 retriever 的做法是:对查询只做一次 embedding,然后以相同的宽度分别执行两路搜索,最后把两组 id 排名融合为一个结果列表。
classHybridRetriever:defretrieve(self, query: str, k: int) -> list[RetrievedChunk]: qvec = embed_texts(self.embedder, [query], is_query=True)[0] dense = self.vec.search(qvec, k) # dense 擅长捕捉改写和语义 sparse = self.bm25.search(query, k) # sparse 擅长命中精确名称、id、数字 fused = rrf_fuse([[i for i, _ in dense], [i for i, _ in sparse]], self.rrf_k)[:k]return [c for c in (self._mk(cid, s, "hybrid") for cid, s in fused) if c]这个融合后的列表就是我们的召回阶段。这里会刻意放宽到 150 个候选,因为下一阶段才是把高召回换成高精度的地方。
Reranking
召回便宜,精排昂贵,所以顺序必须先召回、后精排。前面加载的 reranker 会把 query 和每个候选一起读入,并判断两者的匹配程度。它的准确性远高于 bi-encoder embeddings,但速度太慢,不可能直接在整个语料库上跑。
只对融合后的 150 个候选做 reranking,通常就是效果和成本之间的最佳平衡点。把这个昂贵模型限制在 150 个候选上,而不是整个语料库,也是一个扩展性决策:无论索引里是两万个 chunk,还是一千万个 chunk,这一步的成本都固定为 150 对 query-candidate 配对。
实现上只需要一个很薄的封装层:给所有候选打分,然后保留前 20 个。

classRerankerStage:defrerank(self, query, cands, top_n): scores = self.reranker.score(query, [c.text for c in cands]) ranked = sorted(zip(cands, scores), key=lambda x: -x[1])[:top_n] out = []for c, s in ranked: c.score, c.source = float(s), "reranked" out.append(c)return out这种提升是可以直接测出来的。以当前这个例子为例,我们可以用 HotpotQA 的 gold titles 来衡量 passage recall,分别比较仅用 dense、使用 hybrid,以及再经过 reranked 之后的结果。
路由与拆解
#### OUTPUT ####Q: Were Scott Derrickson and Ed Wood of the same nationality?gold titles: ['Scott Derrickson', 'Ed Wood']recall@20: dense=1.00 hybrid=1.00 reranked=1.00top-3 reranked:[a9ec406223bd] (0.999) Scott Derrickson[2d2201c92ac5] (0.996) Ed Wood[b7dbb0e190b4] (0.796) Ed Wood (film)两个 gold passage 都进入了前三,reranker 分数分别是 0.999 和 0.996,而相关性较低的电影条目排在后面,分数为 0.796。在完整评测中,这套 retrieval stack 达到了 0.97 context recall,这意味着:只要问题本身可回答,证据几乎总能被找出来。
Retrieval 已经基本解决。接下来要做的,就是别把它用坏。
路由与拆解
并不是每个查询都值得走完整 pipeline。打招呼不需要检索,简单事实查询只需一次跳转,比较类问题则往往需要多步推理。因此,agent 的第一步是先把问题路由到三种标签之一,只在真正有收益的地方消耗算力。
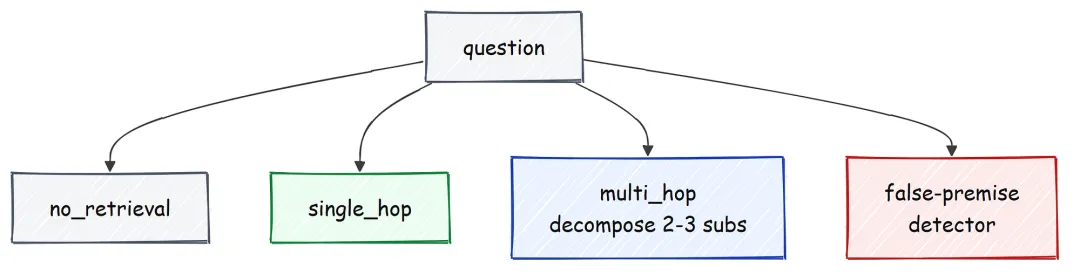
ROUTER_PROMPT = ("Classify the question into exactly one label:\n""- no_retrieval: greetings/opinions or questions no document corpus could answer\n""- single_hop: answerable by finding one fact\n""- multi_hop: needs combining facts from multiple documents\n""Question: {q}\nReply with only the label.")classQueryRouter: LABELS = {"no_retrieval", "single_hop", "multi_hop"}defroute(self, query: str) -> str: out = self.llm.chat("You are a precise query classifier.", ROUTER_PROMPT.format(q=query), max_tokens=8).strip().lower()for lbl inself.LABELS:if lbl in out:return lblreturn"single_hop"decomposer 和 false-premise check 也同样很轻量。前者要求模型把问题拆成 2 到 3 个自包含、可独立理解的子问题;后者则直接判断:这个查询是否预设了某个可能并不成立的前提。
DECOMPOSE_PROMPT = ("Break this multi-hop question into 2-3 ordered, self-contained sub-questions, ""one per line, no numbering. If it is already simple, return it unchanged.\nQuestion: {q}")defdetect_false_premise(query: str, llm: LocalLLM) -> bool: out = llm.chat("You detect false presuppositions.", FALSE_PREMISE_PROMPT.format(q=query), max_tokens=4)return out.strip().lower().startswith("y")#### OUTPUT ####route('Were Scott Derrickson and Ed Wood of the same nationality?...') -> single_hopdecompose ->• What is the nationality of Scott Derrickson?• What is the nationality of Ed Wood?再看同一个 router 对另外两类问题的判断,就能看到其余两个分支的行为。
#### OUTPUT ####route('What is the best programming language?') -> no_retrievalroute('Who directed Ed Wood, and what is that director also known for?') -> multi_hop观点类问题会被归到 no_retrieval。这本身就是一种 abstention path:系统不会去检索一个文档库中根本不存在的答案,而是选择拒答。真正需要两条事实拼接的问题则会被归到 multi_hop,后续 agent 也会因此进入它的纠错循环。
路由器之所以把我们这个运行中的示例判定为 single-hop,是因为重排后的段落已经足以直接回答问题;而分解器也展示了另一种处理方式:如果第一轮召回信息不足,它会如何把这个比较问题拆成两次清晰的检索。路由的成本很低,本质上只是一轮简短的分类调用,但它依然很有价值:它能把昂贵的检索与验证留给真正需要的问题。在大规模场景下,这一点尤其重要,因为每省掉一次检索,就等于少花一份延迟成本。
带引用生成
这是第一道防幻觉防线。系统提示词明确禁止使用外部知识,要求每一句话都附带行内引用,并为“上下文中没有答案”的情况指定了一个显式输出 token。仅仅要求模型“给出引用”还不够,因此我们还会对引用做校验,凡是模型虚构出来的引用,一律丢弃。

ABSTAIN_TOKEN = "INSUFFICIENT_EVIDENCE"GENERATION_SYSTEM_PROMPT = ("You answer strictly from the numbered context passages. Rules:\n""1. Use ONLY facts in the passages, never outside knowledge.\n"f"2. If the passages do not contain the answer, reply with exactly: {ABSTAIN_TOKEN}\n""3. Every sentence MUST end with a citation to the passage id(s) it uses, like [abc123def456].\n""4. Be concise and factual.")生成完成后,我们会解析其中的引用标记,只保留那些与真实 chunk id 匹配的引用。因此,任何伪造的引用都不可能原样保留并展示给用户。
defparse_citations(text: str, valid_ids: set[str]) -> tuple[list[str], str]: found = _CITE_RE.findall(text) valid = [c for c indict.fromkeys(found) if c in valid_ids] invalid = [c for c indict.fromkeys(found) if c notin valid_ids] cleaned = textfor bad in invalid:# 去掉模型虚构的引用 cleaned = cleaned.replace(f"[{bad}]", "")return valid, cleaned把它运行在一个句子上:这个句子同时引用了一个真实段落和一个模型捏造的段落,那么假引用就会被直接移除。
#### OUTPUT ####>>> text = "Paris is the capital of France [a1b2c3d4e5f6]. The Louvre opened in 1793 [deadbeef0000].">>> parse_citations(text, valid_ids={"a1b2c3d4e5f6"})(['a1b2c3d4e5f6'], 'Paris is the capital of France [a1b2c3d4e5f6]. The Louvre opened in 1793 .')真实 id 会被保留,而虚构的 [deadbeef0000] 会被剥离,因此进入下一阶段的只会是真实引用。这一点至关重要,因为最危险的幻觉形式,恰恰是那种语气笃定、却套着一个并不属于它的“引用”的句子;而在这里,这种伪装会在任何人看到之前就被清除掉。生成器会先把召回得到的段落连同它们的 id 一起格式化,再调用模型一次,最后要么返回 abstain 信号,要么返回经过解析并完成引用校验的答案。
classCitedGenerator:defgenerate(self, question, chunks) -> CitedAnswer: user = f"Context passages:\n{format_context(chunks)}\n\nQuestion: {question}\n\nAnswer:" raw = self.llm.chat(GENERATION_SYSTEM_PROMPT, user, max_tokens=400).strip()if ABSTAIN_TOKEN in raw:return CitedAnswer(text="", cited_ids=[], abstained=True, raw=raw) cited, cleaned = parse_citations(raw, {c.idfor c in chunks})return CitedAnswer(text=cleaned.strip(), cited_ids=cited, abstained=False, raw=raw)#### OUTPUT ####Q: Scott Derrickson 和 Ed Wood 的国籍是否相同?abstained=Falsecitations=['a9ec406223bd', '2d2201c92ac5']A: 是的,Scott Derrickson 和 Ed Wood 的国籍相同;两人都是 American。 [a9ec406223bd] [2d2201c92ac5]这个回答引用了我们检索到的两段内容,而且两个 id 都是真实存在的,因此不会有任何内容被剔除。到这里,我们已经得到了一个语言流畅、带引用的答案;但“带引用”只能证明模型指向了某段文本,并不能证明那段文本真的支持它给出的结论。
模型完全可能引用了一段真实文本,却依然误读了它。因此,引用是必要条件,但不是充分条件。下一道防火墙要解决的,正是这个缺口。
验证闸门
这是整个系统里最关键的一道防火墙。我们会先把生成的答案拆成若干原子级 claim,再用前面加载好的 faithfulness judge,把每条 claim 与其引用的上下文逐一核验。只要某条 claim 的分数低于阈值,就视为证据不足;而一旦有任何一条未通过,整个答案都会被降级为 abstention。

claim 提取器会先去掉答案中的引用标记,再把内容切分为一条条原子级、可独立验证的事实陈述,这样得到的 claim 都是干净文本。
classClaimExtractor:defextract(self, answer: str) -> list[str]: clean = _CITE_RE.sub("", answer).strip() out = self.llm.chat("You extract atomic factual claims.", CLAIM_DECOMP_PROMPT.format(a=clean), max_tokens=300) claims = [re.sub(r"^\s*\d+[.)]\s*", "", ln).strip(" -\t") for ln in out.splitlines() if ln.strip()]return [c for c in claims iflen(c) > 3]这道闸门会先抽取 claim,再把每条 claim 与其引用的段落逐一打分;只有当所有 claim 都高于阈值时,答案才会被放行。
classVerificationGate:defcheck(self, cited: CitedAnswer, chunks: list[RetrievedChunk]) -> GateResult: claims = self.extractor.extract(cited.text) used = [c for c in chunks if c.idinset(cited.cited_ids)] or chunks context = "\n\n".join(c.text for c in used) verdicts = []for cl in claims: s = self.verifier.support(cl, context) verdicts.append(ClaimVerdict(cl, s["score"], s["score"] >= self.tau, s["nli"], s["minicheck"])) min_support = min((v.score for v in verdicts), default=0.0) passed = len(verdicts) > 0andall(v.supported for v in verdicts)return GateResult(passed, verdicts, min_support, len(verdicts))#### OUTPUT ####claims=3 passed=True min_support=1.00[OK 1.00] Scott Derrickson is American.[OK 1.00] Ed Wood is American.[OK 1.00] Scott Derrickson and Ed Wood share the same nationality.这句单句回答会被拆成 3 条可核验的断言,而每一条与所引用段落比对后的得分都是满分 1.00,因此 gate 最终通过,min_support 也是 1.00。之所以能做到如此严格,关键就在于它检查的是 claim 级别,而不是整段答案。
一段长答案即使有 80% 内容都能落地到证据,仍可能夹带 1 个凭空捏造的事实;如果只看答案整体得分,这种情况很容易被放行。claim-level gate 则会把那一句单独拎出来核验,并在该句上直接判失败。这里最关键的设计选择是:gate 报告的是最弱的一条 claim,而不是平均分,因为一段答案是否可信,取决于其中证据支持最薄弱的那一句。
要理解这条“最弱 claim”规则,最好的方式就是看它真正触发失败时的样子。下面是同一个 gate 在一道“错误前提”问题上的表现:模型试图顺着问题作答,但被拦了下来。
#### OUTPUT ####claims=2 passed=False min_support=0.20[OK 0.95] Marie Curie was a physicist.[XX 0.20] Marie Curie traveled to the Moon.第一条 claim 有充分证据支持,但第二条只有 0.20,远低于 0.3 的阈值,因为没有任何段落提到这件事。只要有 1 条 claim 失败,passed 就会被置为 False,整段答案会被直接丢弃,问题也会从“自信但错误的陈述”转为 abstention。也正是在这一刻,幻觉被捕获,并被转化为一次安全的拒答。
对于处在边缘的答案,我们不会直接丢掉。系统会先执行一轮 chain-of-verification,给它 1 次自我修复机会:把上下文无法支持的句子改写掉,保留 citations,然后再对修订后的文本重新运行一次 gate。
COVE_PROMPT = ("Revise the answer so EVERY sentence is directly supported by the context. ""Remove or soften any claim not supported. Keep citations [id].\n\n""Context:\n{ctx}\n\nAnswer:\n{ans}\n\nRevised answer:")defcove_revise(answer: str, chunks, llm: LocalLLM) -> str: ctx = format_context(chunks)return llm.chat("You make answers strictly faithful to context.", COVE_PROMPT.format(ctx=ctx, ans=answer), max_tokens=400).strip()何时该选择 Abstain
Abstention 不是失败,而是一种正确答案,因此我们把它设计成一等输出。这一步本身,就是让“近乎零幻觉”成为可能的关键。
对于语料库中根本没有答案的问题,我无法保证模型绝不出错;但我可以让系统拒绝回答这类问题。这样一来,原本无界的失败——一本正经地胡说——就变成了有界的失败:一次可见、可测量、可调优的 abstention。整个策略的核心,就是把这些信号折叠进一次统一决策。
如果路由器判定无需检索,或者模型输出了弃答 token,或者验证关卡未通过,我们就选择弃答;只有在这些条件都满足时,才返回经过验证的答案文本。
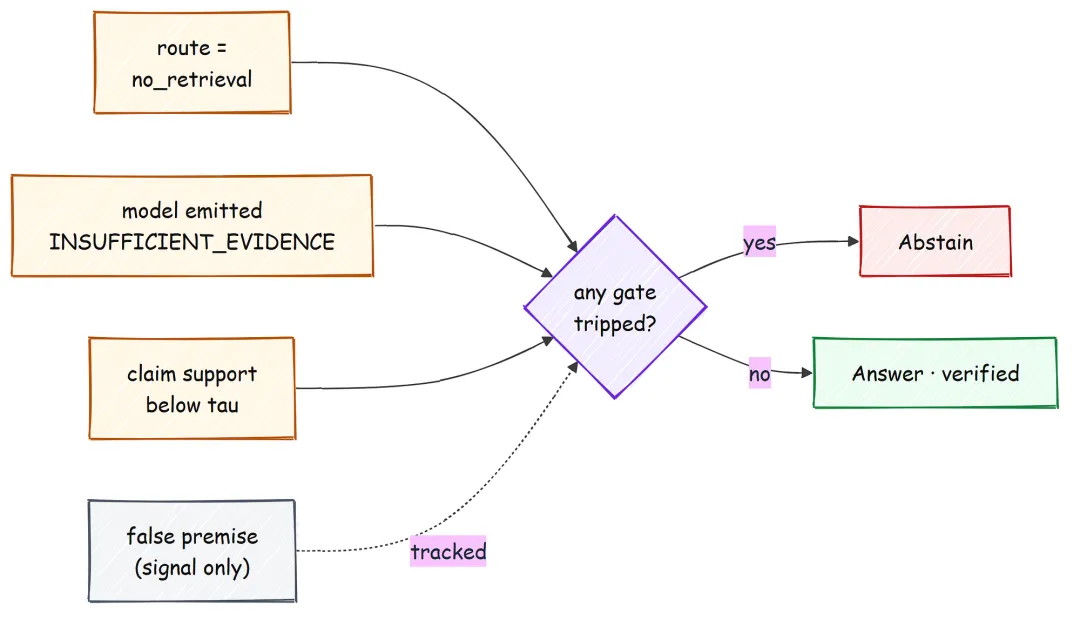
每一种结果都会落成一条严格、可审计的记录,因此在评估时,可以明确区分“已作答”和“已弃答”,不需要任何猜测或推断。
@dataclassclassFinalAnswer: status: str answer: str citations: list[str] min_support: float reason: strclassAbstentionPolicy:defdecide(self, route, false_premise, cited, gate) -> FinalAnswer:if route == "no_retrieval":returnself._abstain("routed_no_retrieval", gate)if cited.abstained:returnself._abstain("model_abstained", gate)if gate isNoneornot gate.passed or gate.min_support < self.tau:returnself._abstain("unsupported_claims", gate)return FinalAnswer("answered", cited.text, cited.cited_ids, gate.min_support, "verified", {})#### OUTPUT ####AbstentionPolicy ready; reasons = {routed_no_retrieval, false_premise, model_abstained, unsupported_claims, verified}这里有一个容易被忽略、但值得特别指出的细节:false-premise 标记会作为一个信号被记录下来,但它不是硬性关卡,因为一个小型的 yes-or-no 检测器噪声太大,单独依赖它并不可靠。
真正的决策由“证据评分 + claim verification”这条证据链来完成;当没有任何段落能够支持问题前提时,这套机制同样会把 false-premise 问题拦下来。系统一旦决定弃答,返回的将是一条直接明了的信息——“I do not have enough supporting evidence in the available sources to answer this confidently,”——而不是基于猜测作答。
Agent
至此,所有组件都已经搭建完成。最后一步,是把它们接成一个能够自我纠错的图结构,因为幻觉最常见、也最核心的成因,就是模型基于错误上下文进行生成。这个循环由 LangGraph 构建而成;我之所以选择它,是因为这里的控制流本质上就是一个图,而不是一条直线:route 可以跳过检索,grade 可以回环到 refine,verify 还可以把一个答案降级为弃答。与其把这些逻辑埋进层层嵌套的条件分支里,我更愿意直接把这些边声明出来。
整个流程是:先路由,再检索,然后对证据打分。如果证据足够强,就进入生成;如果证据偏弱,就改写查询并重新检索,直到达到 hop 上限;如果判断已经无望,就直接弃答,完全不进入生成阶段。

这个 agent 在各个节点之间传递同一个状态对象。它是一个带类型的字典,用来持续累积 route、证据、评分、草稿答案、关卡结果,以及累计延迟统计。
classAgentState(TypedDict, total=False): question: str route: str query: str evidence: list grade: float draft: Any gate: Any final: Any hops: int latencies: dict每个节点只负责一项工作。grader 负责评估当前 passages 对问题的回答程度;而 refine 节点则承担纠错职责:它会增加 hop 计数、拆解问题,并在再次检索前扩展查询范围。
千万文档级 RAG 如何逼近零幻觉
defgrade_evidence(query: str, chunks, llm: LocalLLM) -> float: ctx = "\n".join(f"- {c.text[:200]}"for c in chunks[:8]) out = llm.chat("You grade retrieval sufficiency.", GRADE_PROMPT.format(q=query, ctx=ctx), max_tokens=8 ) m = re.search(r"01?", out)returnfloat(m.group()) if m else0.5defn_refine(state: AgentState) -> AgentState: state["hops"] = state.get("hops", 0) + 1 subs = decomposer.decompose(state["question"]) state["query"] = " ".join(subs) # 用拆分出的子问题扩展查询return state一个很小的路由函数,就能把评分映射成下一步动作;而整个 graph 则把各个节点串起来,其中 refine 会回环到 retrieve,形成纠偏流程。
def_after_grade(state: AgentState) -> str: g = state.get("grade", 0.0)if g >= CRAG_OK: # 0.7+,证据足够强,可以直接回答return"generate"if g < CRAG_BAD or state.get("hops", 0) >= MAX_HOPS:return"generate"if g >= CRAG_BAD else"finalize"# 证据太弱,放弃作答return"refine"# 处于边界区间,改写查询后重试defbuild_agent_graph(): g = StateGraph(AgentState)for name, fn in [ ("route", n_route), ("retrieve", n_retrieve), ("grade", n_grade), ("refine", n_refine), ("generate", n_generate), ("verify", n_verify), ("finalize", n_finalize) ]: g.add_node(name, fn) g.set_entry_point("route") g.add_conditional_edges("grade", _after_grade, {"generate": "generate", "refine": "refine", "finalize": "finalize"} ) g.add_edge("refine", "retrieve") # corrective loop g.add_edge("generate", "verify") g.add_edge("verify", "finalize")return g.compile()把完整 agent 跑在前面的示例问题上,可以看到每个阶段以及对应耗时。
#### OUTPUT ####Q: Were Scott Derrickson and Ed Wood of the same nationality?route=single_hophops=0grade=1.00status=answeredreason=verifiedA: Yes, Scott Derrickson and Ed Wood were of the same nationality; both were American.latencies(s): {'route': 0.16, 'retrieve': 2.4, 'grade': 0.13, 'generate': 0.94, 'verify': 0.97, 'total': 4.6}这次 grade 返回 1.00,因此 agent 直接进入 generate。最终状态是 answered,原因是 verified,说明它通过了我们设计的所有关卡。
这里的 hops 计数保持为 0;但如果检索结果比较单薄,它会一路增加到 3,然后才放弃。这个有界循环的意义就在于:既把延迟控制在预算内,又保留了第二次、第三次纠错重试的机会。
这种对比,正是整个设计的核心,而且两行就能说明白:如果给 agent 一个在语料库中根本没有答案的问题,同一张 graph 会走向相反但正确的结论。
当检索结果里完全找不到 Newton 发明某种编程语言的证据时,评分会回落到 0.15,低于 crag_bad 设定的 0.4 下限。于是,agent 会在生成答案之前直接进入弃答流程,不再继续生成。
这也是为什么弃答路径更快:这里总耗时只有 3.3 秒,而有答案输出的情形是 4.6 秒。原因很简单,一旦系统判断证据不存在,就不会再为生成或验证投入额外开销。这正是那 100 个不可回答问题中 98 次弃答的实际表现——逐题如此。
这套方法有效吗?
Golden Set
要衡量这一切,首先需要一个包含两个层次的测试集。可回答部分来自 HotpotQA,不可回答部分来自 SQuAD v2 的 impossible questions,再加上一小部分手工构造的错误前提问题。
真正关键的是不可回答这一半,因为普通 RAG 系统最容易在这里不动声色地“编”。我们设计的所有机制——citation rule、claim gate、abstention policy——本质上都是为了让这部分保持安静。因此,是否接近“零幻觉”,真正看的就是这一层;而可回答部分则主要用于衡量检索是否完成了任务。
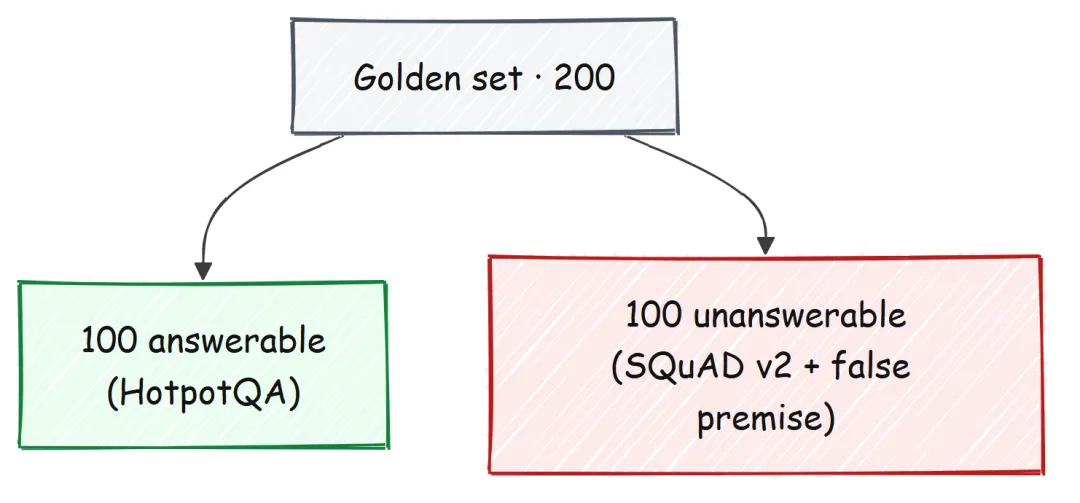
defbuild_false_premise_set() -> list[EvalItem]: qs = ["In what year did Albert Einstein win his second Nobel Prize in Physics?","What was the name of the spaceship Marie Curie flew to the Moon?","How many gold medals did William Shakespeare win at the Olympics?","Which programming language did Isaac Newton invent in 1700?", ]return [EvalItem(f"fp_{i}", q, "", [], False, "false_premise") for i, q inenumerate(qs)]#### OUTPUT ####[golden] 200 items (answerable=100, unanswerable=100)最终,我们得到的是一个平衡的 200 题 测试集,其中一半可回答,一半不可回答。错误前提问题都刻意设计得很荒谬,比如“Newton 在 1700 年发明了哪种编程语言?”。如果一个系统会认真回答这种问题,那它面对任何听起来像模像样的问题时,都可能凭空捏造事实。
之所以必须保持两半平衡,是因为如果测试集大多数题目都可回答,系统即便在困难场景下持续胡编,也依然可能拿到不错的总分。而这个测试集有一半题目存在的唯一目的,就是衡量系统是否足够克制。
幻觉只存在于一个格子里
接下来,我们让 agent 跑完全部 200 道题,并用一个二乘二表来打分。行表示题目是可回答还是不可回答,列表示系统是作答还是弃答。唯一真正危险的那个格子,是“不可回答但仍然作答”,因为按定义,这就是幻觉。
defconfusion_2x2(results, items) -> np.ndarray: cm = np.zeros((2, 2), dtype=int)# rows: answerable/unanswerable, cols: answered/abstainedfor r, it inzip(results, items): i = 0if it.answerable else1 j = 0if r.final.status == "answered"else1 cm[i, j] += 1return cm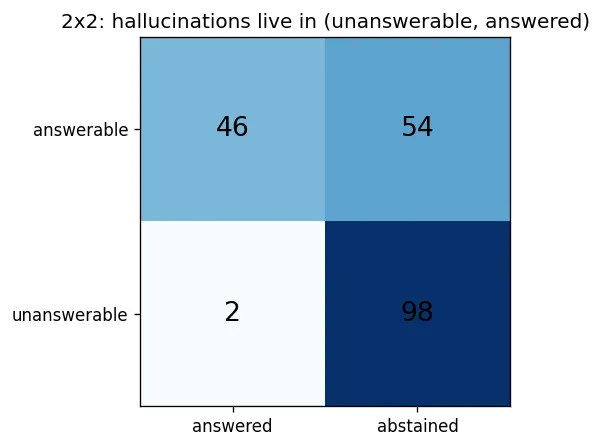
#### OUTPUT ####confusion (rows ans/unans, cols answered/abstained):[[46 54] [ 2 98]]hallucinations (unanswerable answered): 2 / 100 unanswerable读最下面一行,因为那才是核心结论。在 100 个不可回答的问题中,系统对其中 98 个选择了弃答,只回答了 2 个;也就是说,在这些专门用于“诱导犯错”的问题上,幻觉率只有 2 percent。
如果只是一个没有验证闸门的普通 RAG 系统,这个单元格的数字通常会亮得多,因为它没有机制阻止自己去回答那些语料库根本无法支持的问题。这个安全机制的代价,则体现在矩阵的最上面一行,下面我们就来看这一点。
安全性的代价
前面的二乘二矩阵只用了一个固定阈值,但阈值本质上是一个可调旋钮。阈值调得越高,系统越倾向于弃答;这样可以进一步降低幻觉,但同时也会压低覆盖率。为了有意识地选择这个阈值,我们会扫描一系列阈值并绘制风险-覆盖率曲线,然后选出这样一个点:在把幻觉控制在预算内的前提下,尽可能多地回答问题。
defpick_tau(df, max_halluc: float = 0.05) -> float: ok = df[df["hallucination_rate"] <= max_halluc]returnfloat(ok.sort_values("coverage", ascending=False).iloc[0]["tau"]) iflen(ok) else1.0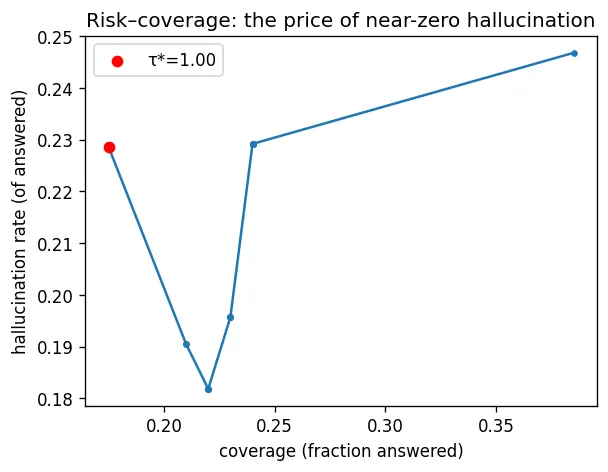
#### OUTPUT ####chosen τ* (halluc<=5%): 1.0metrics: { "faithfulness": 0.908, "answer_relevancy": 0.817, "context_recall@k": 0.97, "answerable_accuracy": 0.58}在那些最终被回答的问题上,我们得到 0.908 faithfulness 和 0.97 context recall。这说明证据确实被找到了,而且回答也始终锚定在这些证据之上。代价,则正是矩阵最上面一行所体现的部分。
在 100 个可回答的问题中,我们只回答了 46 个,其余全部弃答,对应覆盖率为 0.46。这是一个有意为之的取舍。
相比于冒着高置信度却答错的风险,我们更愿意对一个其实“本来能答”的问题保持沉默。至于在这条曲线上具体落在哪个位置,本质上是产品决策,而不是模型决策;并且可以按语料库分别设定,因为不同领域里“答错一次”的代价并不一样。
这个裁判真的靠谱吗?
这里还有一个必须补上的缺口。整个闸门机制都建立在 verifier 之上;如果 verifier 自己没有经过验证,那就只是把幻觉从答案里转移到了评分卡里。为此,我们单独测试 verifier:使用 HaluBench 这组由人工标注的 faithful 与 hallucinated 答案样本,并报告 ROC 曲线下面积。
defeval_verifier(verifier, n: int = 300) -> dict: hb = load_halubench().shuffle(seed=SEED).select(range(n)) scores, labels = [], []for ex in hb: scores.append(verifier.nli_score(ex["answer"], ex["passage"])) labels.append(1ifstr(ex["label"]).upper().startswith("PASS") else0)from sklearn.metrics import roc_auc_scorereturn {"auroc": round(float(roc_auc_score(labels, scores)), 3), "n": len(labels)}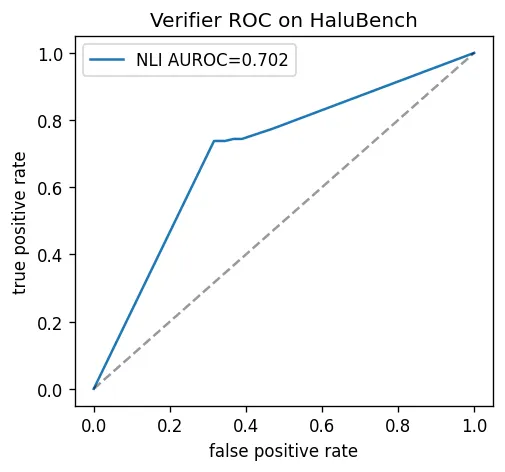
#### OUTPUT ####[verifier] AUROC=0.702 over n=300 HaluBench items在 300 条 HaluBench 样本上,这个 verifier 的得分是 AUROC 0.702。它显然优于随机猜测,但距离“完美”还有相当长的路。我想把这一点说得非常明确,因为这正是整个闸门机制当前的真实性能上限。
如果只做一项改动,最能把前面那些指标继续往上推的,就是换一个更强的 verifier。好在这个架构从一开始就是这样设计的:我们可以直接替换 verifier,而不需要动其余部分。闸门机制并不要求 verifier 必须完美;它只需要足够经常地把“有证据支持的陈述”排在“没有证据支持的陈述”前面,从而推动整体工作点向更优的位置移动。以这个标准看,0.702 已经跨过了可用门槛,但依然留有很大的提升空间。
扩展到 10M+ 向量
一个真实的 10M 向量索引
这套质量评估流程已经在一个精心整理过的样本切片上得到了验证。接下来,我们必须从字面意义上证明“规模”这件事,因为标题写的是 10M+ documents,而能真正说明问题的,只有基准测试。
因此,我们分别在 100k、1M 和 10M 向量规模下构建 LanceDB 索引,使用真实的近似最近邻索引,并在每个规模点测量建索引时间、磁盘占用和查询延迟。
这里必须使用近似的 IVF_PQ 索引,而不是精确搜索。因为精确扫描需要把查询与每一个向量逐一比较,其复杂度随 n 线性增长;一旦到 10M 规模,这部分成本就会明显失控。相比之下,近似索引只访问少量分区,并把每个向量量化到几个字节,用少量召回率损失换取几乎不随语料规模增长而变化的延迟。
为了让这个基准测试保持为纯粹的向量搜索评测,这里的向量都是合成数据:1024 维单位向量;数据通过 Arrow 导入,以确保这条数据通路可以承载数千万行。测试机器配有 180 GB 内存和 750 GB NVMe 磁盘,因此 1000 万向量索引可以很从容地放在单机上——这正是磁盘型存储的意义所在。

classScaleBench:defrun(self, sizes: list[int]) -> "pd.DataFrame": rows = []for n in sizes: vecs = make_synthetic_vectors(n, self.dim) db = lancedb.connect(str(SCRATCH_DIR / f"scale_{n}")) t0 = time.time() tbl = db.create_table("v", data=self._arrow(vecs), mode="overwrite")if n >= 100_000: tbl.create_index(metric="cosine", num_partitions=int(min(4096, max(256, n ** 0.5))), num_sub_vectors=64) build_s = time.time() - t0 rows.append(self._measure(tbl, vecs, build_s))return pd.DataFrame(rows)#### OUTPUT ####[scale] building n=100,000 with IVF_PQ ANN index ... -> {'n': 100000, 'build_s': 41.82, 'disk_gb': 0.39, 'p50_ms': 8.5, 'p95_ms': 10.59, 'recall@10': 0.135}[scale] building n=1,000,000 with IVF_PQ ANN index ... -> {'n': 1000000, 'build_s': 81.22, 'disk_gb': 3.884, 'p50_ms': 11.34, 'p95_ms': 14.46, 'recall@10': 0.105}[scale] building n=10,000,000 with IVF_PQ ANN index ... -> {'n': 10000000, 'build_s': 347.04, 'disk_gb': 38.825, 'p50_ms': 16.91, 'p95_ms': 18.48, 'recall@10': 0.105}最关键的信息就在最后一行:一个 10M-vector 索引的 p95 响应时间是 18.48 ms,而向量数量少 100 倍的索引,响应时间是 10.59 ms。
数据规模增长了 100 倍,延迟代价却还不到翻倍。磁盘占用则按线性增长,从 0.39 GB 增加到 38.8 GB——这正是我们想要的结果,因为磁盘便宜,而这种规模下的内存索引并不便宜。
建索引时间也以同样温和的方式增长:从 10 万向量时的 42 秒,到 1000 万向量时不足 6 分钟,而且全部数据都保留在单机的 NVMe 磁盘上。
1000 万规模下 18 ms,以及对 100M 的外推
延迟几乎不变,原因就在于近似索引的工作方式。IVF_PQ 索引搜索的是少量分区,而不是整个向量空间,因此查询成本增长主要取决于分区数量,而不是向量总数;与此同时,磁盘占用仍然线性增长,因为每个向量终究都需要存储下来。基于这一趋势,我们做拟合并外推到 100M。
deffit_and_extrapolate(df, target: int = 100_000_000) -> dict: n = df["n"].values.astype(float) out = {"target": target}for col in ["build_s", "disk_gb", "p95_ms"]: a, b = np.polyfit(n, df[col].values, 1) out[col] = round(float(a * target + b), 2)return out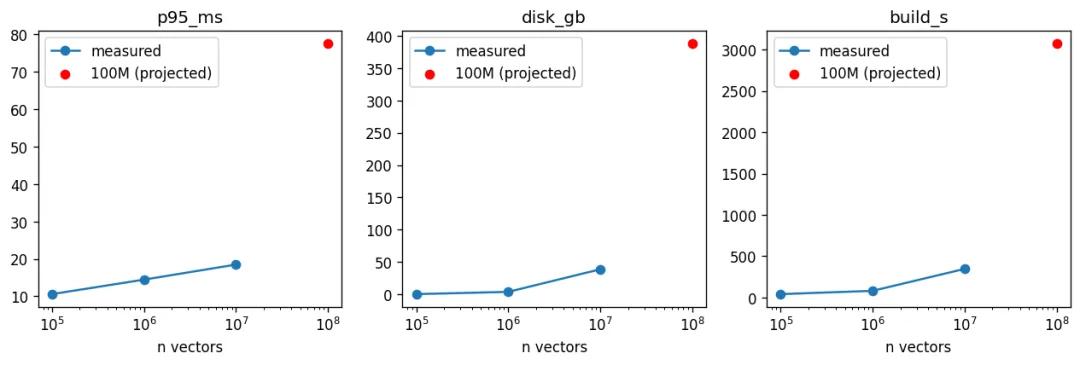
#### OUTPUT ####projection to 100M: { "build_s": 3075.1, "disk_gb": 388.23, "p95_ms": 77.58}在 100M vectors 的规模下,投影结果显示 p95 延迟为 77.58 ms,索引大小约 388 GB,仍然可以放进单机的 NVMe 磁盘。这里需要明确说明一个前提。
这里 Recall@10 接近 0.1,并不是因为索引效果差,而是因为这些向量是随机生成的。对于近似索引来说,随机向量几乎没有真实结构可供检索,因此这次实验衡量的是延迟与吞吐,而不是检索质量。换成真实语料后,同一套索引仍能保持较高召回,而真正随规模增长仍然成立的,是这里测得的延迟数据。
时间都花在哪里
扩展规模本身并不难,真正昂贵的是单次查询背后的 agent 流程。因此,我们按阶段拆分延迟,看看时间预算究竟消耗在哪些环节。
defaggregate_latencies(results) -> "pd.DataFrame": stages = {}for r in results:for k, v in r.latencies.items(): stages.setdefault(k, []).append(v) rows = [{"stage": k, "p50_s": round(np.percentile(v, 50), 3), "p95_s": round(np.percentile(v, 95), 3), "mean_s": round(np.mean(v), 3)} for k, v in stages.items()]return pd.DataFrame(rows).sort_values("mean_s", ascending=False)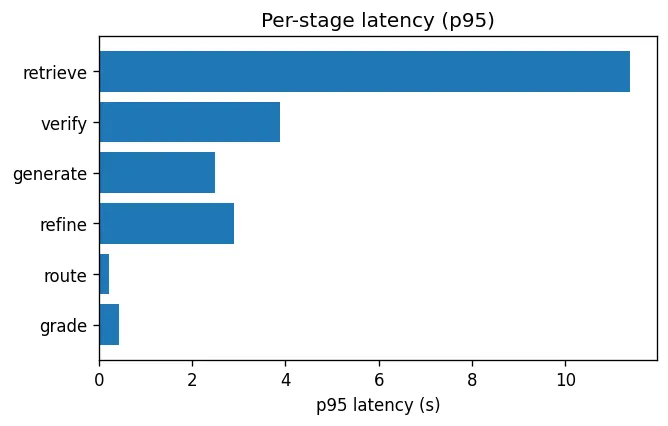
#### OUTPUT ####stage p50_s p95_s mean_stotal 4.001 17.668 5.823retrieve 3.074 11.393 4.166verify 1.534 3.878 1.758generate 1.451 2.484 1.619refine 1.471 2.888 1.575route 0.168 0.206 0.170grade 0.127 0.431 0.161一条典型问题在中位数情况下会在 4 秒 内完成,而在长尾情况下,p95 会达到 17.7 秒。其中 retrieve 是绝对主耗时,因为这一阶段需要运行 embedder、两路检索,以及对 150 个候选结果执行 cross-encoder reranker;遇到复杂问题时,它还会在纠错循环中重复执行多次。
真正便宜的其实是向量检索本身,这与前面的规模实验给出的结论一致。瓶颈并不在索引,而是在围绕索引展开的语言模型调用。
这也是优化前必须先认清的一点:真正值得投入的方向,是减少模型调用次数、对 reranker 做批处理,或者缓存 grade 结果,而不是去替换一个更快的 vector store。
适用范围与下一步
最后,我想明确说明这套方法解决了什么、又没有解决什么。它在不可回答问题集合上的幻觉率是 2 percent,而不是 zero,因为对生成式模型来说,字面意义上的零幻觉并不可达。
在可回答问题上的 coverage 为 0.46。这是我们为安全性刻意付出的代价,而风险—覆盖曲线就是用来在两者之间调节权衡的旋钮。10M 那次实验本质上是基于合成向量的向量检索基准测试,因此它证明的是索引在延迟和磁盘占用上的可扩展性;至于在同样速度下维持高召回,仍然要依赖真实语料来验证。
verifier 当前的表现是 AUROC 0.702,这已经不错,但还谈不上优秀;它也是下一步最值得优先改进的部分。
接下来有几个方向值得投入。
-
更强的 verifier:gate 的上限取决于 judge 的质量,因此只要 faithfulness model 更好,所有下游指标都会一起提升。 -
在大规模下使用真实 embeddings:用真实文档向量重新跑一次规模实验,确认在 18 ms 延迟维持不变的同时,召回率也能保持住。 -
分片与量化:一旦超出单机容量,索引可以拆分到多个 shards 上,而上面的正确性逻辑完全不需要改变。 -
校准 coverage:根据不同领域分别调阈值,让高风险语料更倾向于 abstain,让低风险场景回答更多。
这些后续工作都不会改变这套设计的主干。索引可以继续增长,verifier 可以继续增强,阈值也可以继续调整,但系统契约始终不变:凡是最终呈现给用户的每一句话,系统都必须能在检索到的文本中指出依据;做不到的内容,一律转为 abstention。
这套方案从头到尾都围绕着同一个核心思路展开:我们并不试图让模型“永远不会出错”,而是构建一个系统,让它只输出自己能够证明的内容;凡是无法证实的,就明确选择不回答。该索引可在 18 ms 内扩展到 1000 万 向量规模,回答的事实忠实度稳定在 0.908,而对于证据不足、无法支撑的问题,系统会直接返回一句朴素的“我没有足够的证据”,而不是自信地猜一个答案。
包含完整代码单元和真实运行输出的 notebook 已发布在 GitHub:
GitHub – FareedKhan-dev/rag-zero-hallucinations: 通过 RAG 处理 1000 万+ 文档并实现零幻觉…[2]Handling 10M+ docs using RAG with zero hallucinatons – GitHub – FareedKhan-dev/rag-zero-hallucinations: Handling 10M+…
引用链接
[1]GitHub – FareedKhan-dev/rag-zero-hallucinations: Handling 10M+ docs using RAG with zero…: https://github.com/FareedKhan-dev/rag-zero-hallucinations
[2]GitHub – FareedKhan-dev/rag-zero-hallucinations: 通过 RAG 处理 1000 万+ 文档并实现零幻觉…: https://github.com/FareedKhan-dev/rag-zero-hallucinations