 夜雨聆风
夜雨聆风追求高吞吐量的计算,却在每日海量任务的管理中疲于奔命。理想中的高通量计算变为现实里的低效率和高维护率,研究节奏被打乱,时间被浪费,团队无法专注核心科学问题,这似乎是所有高通量材料计算团队的困局。
并行科技凭借强大的资源调度和专业性能优化能力,正在改写这个局面。

跑不动的高通量:
“我们陷入了一个怪圈”
在某双一流高校前沿材料计算课题组,某DFT计算软件是他们的核心研究工具。不同于传统的单个体系研究,他们的工作涉及海量参数组合的系统性计算,对计算资源的效率和稳定性要求极高。然而,大规模计算也带来了前所未有的挑战。
“我们不是算一个两个体系,而是成百上千个参数组合同时推进。”课题组负责人坦言。曾经的日常就是面对海量计算任务的队列拥堵、资源调度僵化,以及频繁的任务失败——有时计算到最后阶段,内存占用会突然飙升,作业因“内存溢出”而崩溃,研发人员不得不投入大量精力进行人工排查与重提计算。这种模式不仅效率低下,更对科研项目的推进周期构成了巨大威胁。
破局关键:
并行科技M9集群的“性能调优组合拳”
为了突破计算瓶颈,该课题组将目光投向了并行科技自建的M9集群,一个采用AMD都灵架构的大规模高性能计算平台。然而,当他们开始在M9上运行计算任务时,问题似乎并没有立刻消失。
并行科技的工程师团队第一时间介入,借助公司自研的应用性能特征分析工具,对任务运行状况进行了全面诊断。

作业异常信息摘要
问题的根源很快被锁定:课题组使用的软件版本无法充分利用新集群的并行规模。在任务运行后期,特别是面对包含超过40个原子的复杂结构算例时,内存占用会出现急剧增长,频繁触发集群的“内存溢出”保护机制,导致作业崩溃。
面对这个棘手的问题,并行科技工程师团队没有选择“头痛医头”,而是实施了一系列深度系统化的性能调优措施:
编译器深度调优:对比了oneAPI、不同版本的intelmpi、openmpi+aocc等多种组合,最终锁定intelmpi 17版本编译的软件——内存使用量最低,稳定性最好,完美适配M9的大规模并行架构。
动态调整作业配比:将单作业从64核调整到96核,在不显著增加预算的前提下,为每个任务争取到更充裕的计算资源。
海量资源弹性协调:依托M9的18万核心池,根据课题组的任务进度,按需灵活调配3~5万核资源,既满足峰值需求,又节约总体成本。
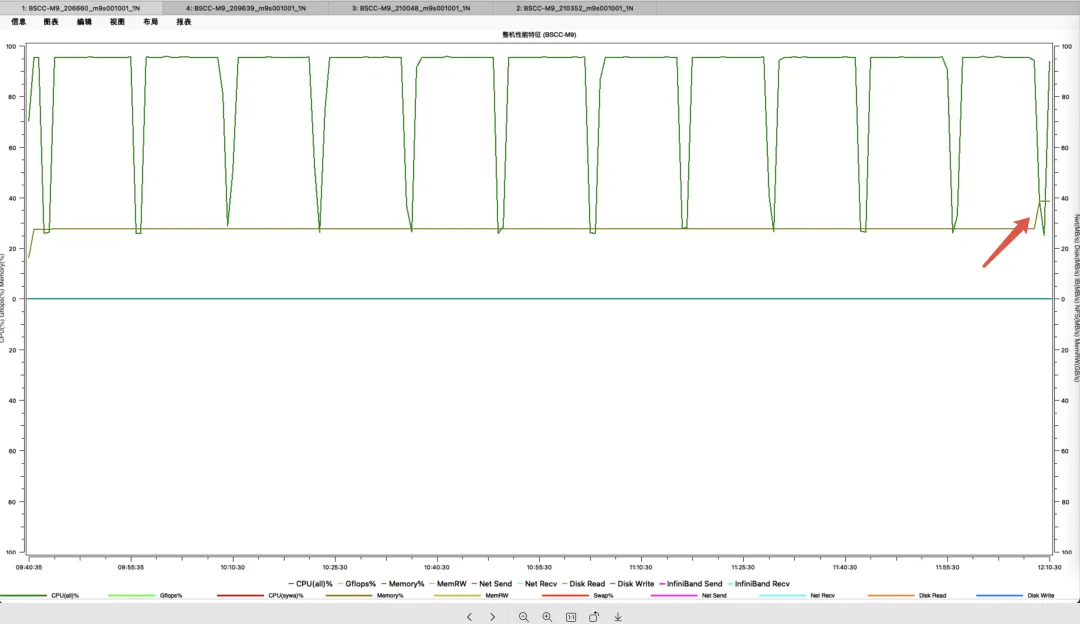
采集作业性能特征监控内存调用
从“救火”到专注研究:
科研节奏的回归
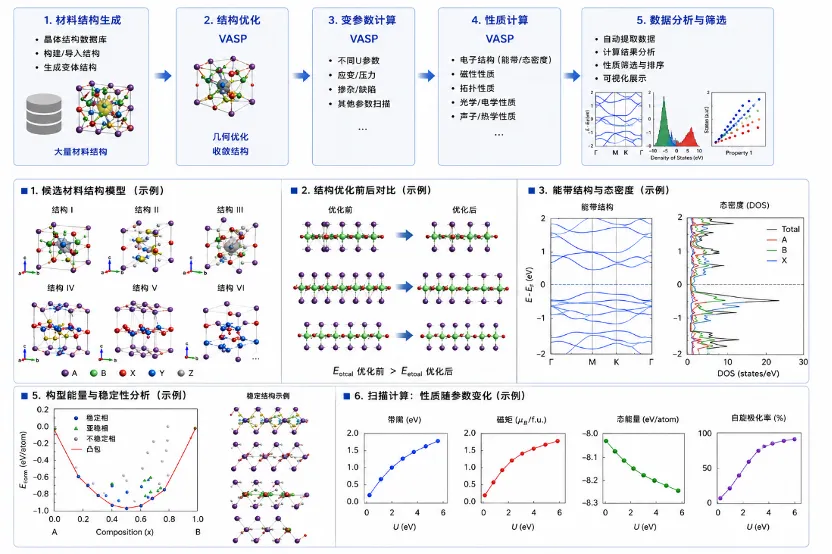
材料计算全流程示意图
并行科技核心竞争力:
不仅是算力,更是专家服务
如同此次与某双一流高校课题组的深度合作,并行科技提供的不仅仅是计算资源。无论是针对前沿材料计算场景,还是在人工智能、智能制造等多样化行业,并行科技都致力于为科研用户提供真正“拿得起来、跑得起来、稳定可靠”的一站式HPC云平台。
稳定,比什么都重要。作为国内领先的算力服务提供商,并行科技正通过其深厚的应用性能优化积累与弹性的算力调度能力,让高通量计算从“能不能跑”,变成“跑得稳、跑得快、跑得省心”。

来源自并行科技
如有侵权请联系删除
来源自并行科技
如有侵权请联系删除

协会宗旨:智能经济使能可持续发展
愿景:成为国际一流的智能经济专业服务平台
使命:AI产业化 产业AI化
提供服务 反映诉求 规范行为 促进发展
企业所急 协会所能 精准服务 价值创造
不与企业争利,不与机构争权;
不与学者争名,不与个人争资;
社会产业治理的事
企业降本增效的事
政府委托交办的事
个人解决不了的事
带你见见不到的甲方、带你见见不到的领导
带你见见不到的大咖、带你拿拿不到的荣誉
服务交费企业、服务关键人的KPI、服务关键人交办的事、服务关键人个人的事
有价值、有未来、有快乐
一群人、一辈子、一件事,干成!

| 联系我们 | ||
| 序号 | 负责内容 | 负责人及手机号 |
| 01 | 副会长、理事服务 | 范会长13392892809 |
| 02 | 政府关系&党建&工会 | 罗莹18820990700 |
| 03 | 市场活动&品牌活动&展会咨询 | 俞永豪13380316965 |
| 04 | 创业空间 | 党军峰13480138058 |
| 05 | 公益培训 | 何月岚19820812325 |
| 06 | 创业孵化 | 王慧君13392892806 |
| 非诚勿扰,请根据实际需求咨询相关工作人员 |




