 夜雨聆风
夜雨聆风





大厂都在用的大数据工具,原来小白也能轻松上手?
哈喽各位数据小白和想入门数据分析的朋友👋
今天我们接着聊数据分析工具,这次要讲的是大数据处理框架和云平台数据分析服务——听起来很高深?其实用大白话+生活例子,你马上就能get!
一、大数据处理框架:处理海量数据的「超级流水线」
想象一下:你开了一家连锁奶茶店,全国1000家门店,每天产生100万条订单数据,要算「哪个城市最爱喝三分糖」「周末销量比工作日高多少」。
如果用普通电脑算,可能要跑好几天;但用大数据处理框架,就像把数据拆成小块,让几百台电脑同时算,几小时就能出结果。
目前最主流的两个框架是:Apache Hadoop 和 Apache Spark。
1. Apache Hadoop:稳扎稳打的「老大哥」
Hadoop就像一个成熟稳重的仓库管理员,擅长处理「超超超大量」的离线数据,比如过去一年的销售记录、历史用户行为。
– 核心能力:把数据分散存在多台电脑上(分布式存储HDFS),再用MapReduce把计算任务拆成小任务,分头搞定。
– 生态组件(就像仓库里的不同工具):
– Hive:给不会写复杂代码的人用,输入类似SQL的简单语句,就能查大数据(比如「查2025年北京门店的奶茶销量」)。
– Pig:用脚本语言处理复杂数据流程,适合做「清洗-统计-导出」一条龙。
– HBase:实时读写海量数据,比如用户点单时立刻查询会员余额。
– Sqoop:把传统数据库(比如MySQL)和Hadoop之间的数据「搬来搬去」。
💡举个例子:
某奶茶品牌要分析2024全年的订单数据,用Hadoop把1000万条数据存在10台服务器上,再用Hive写一句简单查询,就能快速算出「哪个口味销量最高」,完全不用怕数据太大跑不动。

2. Apache Spark:快到飞起的「闪电侠」
Spark就像一个急性子的外卖小哥,擅长处理「高速、实时」的数据,比如直播弹幕、实时订单、用户实时行为。
– 核心优势:把数据放在内存里计算,比Hadoop快10-100倍,适合需要「秒出结果」的场景。
– 生态组件(就像外卖小哥的不同装备):
– Spark Core:基础能力,负责分布式计算,是整个Spark的「发动机」。
– Spark SQL:处理结构化数据,支持用SQL查询,和Hive用法很像,小白更容易上手。
– Spark Streaming:处理实时数据流,比如监控奶茶店实时订单,一旦某门店订单暴增就立刻预警。
– Mllib:自带机器学习算法,比如给用户推荐「你可能喜欢的奶茶口味」。
– GraphX:处理图形数据,比如分析用户之间的社交关系、商品关联。
💡举个例子:
电商平台要做「实时推荐」,用户刚浏览了一款耳机,Spark Streaming立刻捕捉这个行为,用Mllib算相似商品,1秒内就给用户推「搭配的耳机壳」,这就是Spark的速度优势。

二、云平台和数据分析服务:不用买电脑也能玩转大数据
以前企业要做大数据,得自己买几十台服务器、搭环境、雇人维护,成本超高。
现在有了云平台,就像租「共享办公室」——不用买电脑,直接在网上租算力、存数据,按使用量付钱,小白也能轻松用。
三大主流云平台(就像三家不同风格的共享办公)
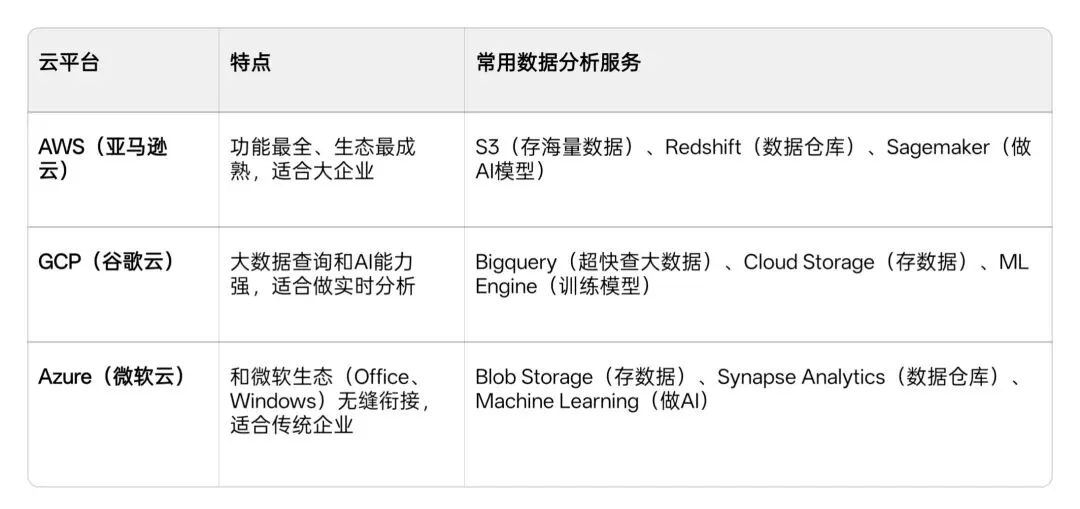
💡举个例子:
你是一个小博主,想分析自己小红书的10万条评论数据:
1. 不用买电脑,直接在AWS上开个S3存储桶,把评论数据传上去;
2. 用Redshift建一个数据仓库,写几句SQL就能算出「大家最常吐槽的点是什么」;
3. 再用Sagemaker训练一个模型,自动给新评论打「正面/负面」标签,完全不用懂复杂运维。
云计算在数据分析里的优势(为什么大家都爱用?)
– 低成本:不用一次性买服务器,用多少付多少钱,小团队也能负担。
– 弹性伸缩:双11时数据暴增,就临时多租点算力;平时数据少,就少租点,不浪费钱。
– 高可用性:云平台会自动备份数据,不用担心电脑坏了数据丢了。
– 全球访问:不管你在国内还是国外,都能随时登录处理数据。
三、写给小白的总结📌
– 大数据处理框架:帮你搞定「海量数据」,Hadoop适合离线算历史数据,Spark适合实时算高速数据。
– 云平台:帮你「低成本用大数据」,不用自己搭环境,租算力、租存储就能干活。
– 对初学者来说:不用一开始就啃底层原理,先知道「什么时候用什么工具」——比如算历史数据用Hadoop,做实时推荐用Spark,想省钱就上云平台。