 夜雨聆风
夜雨聆风





1000个工具喂给OpenClaw,效果反而更差?

“我把1000多个tool和200多个skill全塞给AI,结果它反而变笨了。”
你可能也有类似的想法:既然AI这么强大,那当然要给它最全的装备。搜索工具多装几个,翻译工具来一打,文件处理、数据分析、能想到的都配上。
但现实会给你一记响亮的反常识。
01 越多≠越强

先看数据。
这位网友的1M上下文窗口,愣是被工具描述占用了21万token。你以为这是小事?评论区一位从业者直接点破:
“1M上下文真正可用的可能就50%多,再多大模型会产生幻觉。也就是除去工具以外,你实际可用的上下文只剩30%了。”
有图有真相,有人贴出了大模型上下文长度与性能下降的关系曲线——断崖式下滑。
还有更扎心的:
“别说是1M了,上下文超过20K就能感到性能明显下降。”
这就像让你同时管理100个人,你以为是“人越多力量越大”,实际上是“谁也管不过来”。
02 核心问题:注意力稀释
为什么工具越多,AI越笨?
一位开发者的比喻特别到位:
“让你写个命题作文,然后从康熙词典到故事会都给你来参考,还是只给你一本和命题相关的书,哪个更容易?”
前者,光挑选参考文献就已经懵了。
这就是大模型的“注意力稀释”问题。LLM的注意力机制就像人的专注力——当信息过载时,它不知道该重点处理什么。工具描述占满上下文,真正需要AI干活的空间反而没了。
有经验的开发者总结:
“1000个tool塞进去,上下文直接废掉大半。模型光是理解’我有哪些工具可以用’就烧掉一堆token,真正留给干活的空间反而少了。”
03 正确的打开方式
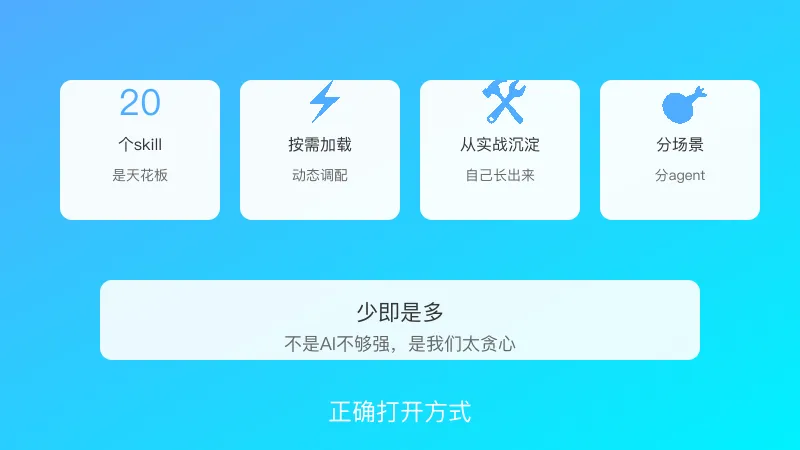
那到底该怎么玩?
1. 够用就行,20个是天花板
多位开发者给出的一致建议是:20个skill顶天了,而且是明确要用的时候才加载。
“你也不想你的模型注意力被分散吧?”
2. 按需加载,动态调配
平时只挂十几个核心技能,需要特定能力时再动态拉进来。这就像瑞士军刀——刀刃不少,但每次只弹出用得着的那一个。
3. 从实战中沉淀
好的skill不是从外面搜罗的,是从自己项目里长出来的。每完成一个任务,如果发现这个方法以后还会用到——再把它沉淀为skill。
4. 分场景、分agent
不同业务场景用不同的agent。前面放一个LLM做“调度员”,判断问题该交给哪个agent处理。各管一摊,效率最高。
04 一个反直觉的真相
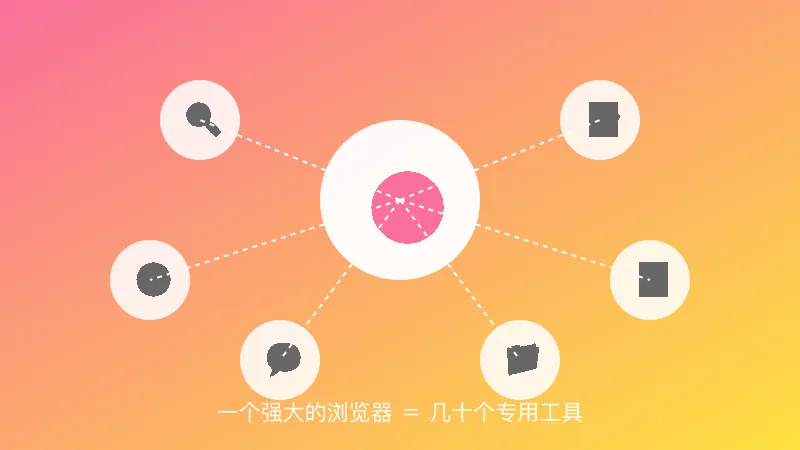
有意思的是,评论区还提到了另一个趋势:
“我之前也搞了很多skill,后来发现CDP(Chrome DevTools Protocol)弄好,就没skill啥事了。只要一个agent-browser就可以。有了Chrome,就有了整个世界。”
什么意思?
工具的数量不重要,关键是工具的“通用性”。
一个强大的浏览器自动化工具,能顶得上几十个专用工具。因为它可以做“任何”事情,而不是只能做“某一类”事情。
这才是真正的效率杠杆。
写在最后
回到那位网友的困惑:“为什么塞了1000多个tool,AI反而没变强?”
答案很简单:不是你给的不够多,而是AI根本用不过来。
这让我想起一句话——
“少即是多。”
不是AI不够强,而是我们太贪心。
你觉得AI工具是越多越好,还是够用就行?
