 夜雨聆风
夜雨聆风





文档解析大模型最新进展:基于扩散思路做OCR之MinerU-Diffusion及网页解析工具MinerU-HTML更新
今天是2026年3月25日,星期三,北京,天气晴
继续看技术,回到文档解析领域,看两个有意思的点。
一个是基于扩散模型做文档OCR思路MinerU-Diffusion,用来做加速的,思路很看,很有趣
另一个是HTML解析工具进展之MinerU-HTML,偏向工程,解析网页的轮子。
一、基于扩散模型做文档OCR思路MinerU-Diffusion
先看文档多模态大模型进展,基于扩散解码的文档OCR统一框架,核心是将文档OCR重新定义为视觉条件下的逆渲染问题【就是搞成文本恢复】,以并行扩散去噪替代自回归顺序解码,目的是解决传统自回归OCR在长文档解析中的延迟【一个一个输出,很慢】、误差传播【多阶段都有损失】及过度依赖语言先验【就是对不清晰的图片会乱猜】的问题。【注意,这个是用来做加速的,不是为了性能提升】
工作在《MinerU-Diffusion: Rethinking Document OCR as Inverse Rendering via Diffusion Decoding》,https://arxiv.org/pdf/2603.22458,Code: https://github.com/opendatalab/MinerU-Diffusion,Model: https://huggingface.co/opendatalab/MinerU-Diffusion-V1-0320-2.5B,【注意,目前还没上传】
先说说效果上,2.5B模型与自回归MinerU2.5相当的性能【也就是顶天了的,作为baseline】,解码效率提升最高3.2×【用来验证速度上的事,维持差不多的性能的情况下,速度提升】,如下面这个图:
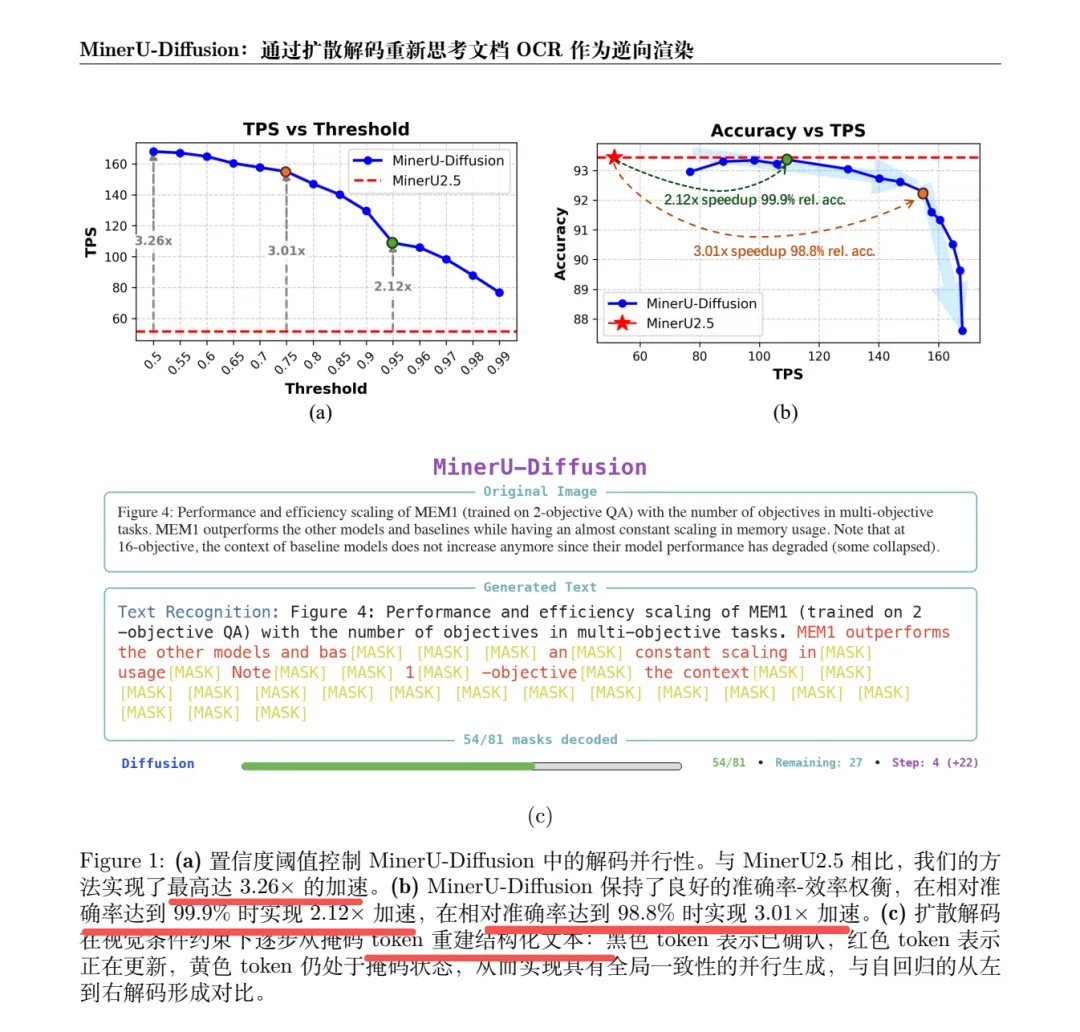
置信度阈值(0.5~0.99),阈值越低,速度越快。
1、自回归模型和扩散模型的解码方式
先看下两种不同的建模方式,自回归模型和扩散模型。
左边传统自回归(AR)解码,右边扩散(Diffusion)解码,如下:
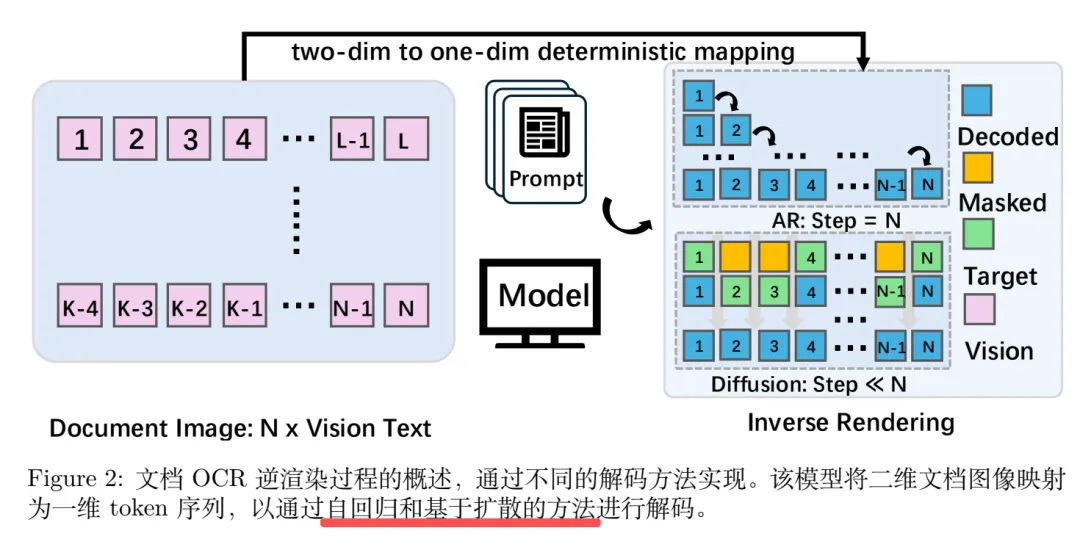
先说自回归(AR)解码,实现过程上,把2D文档图先转成视觉特征,然后按固定顺序(1→2→3→…→L)挨个生成1D文字令牌,一步只能生成1个,总共要走N步(N=文字总数)。
这种的核心问题是每一步都依赖前一步的结果,还会靠语言先验“补内容”——比如前一步认成“苹”,后一步不管图片是啥,大概率会补成“果”,这就是脑补;
再说扩散(Diffusion)解码,同样把2D文档图转视觉特征,但没有固定顺序,而是先生成一个带大量MASK的1D token序列,然后通过少数几步(Step≪N)全局还原,一步能更更新多个token;这类每一步都依赖整张图的视觉特征,不是前一步的文字,模型只看图片,不看自己之前认的字,所以想着从根上避免脑补。
所以,看到这,其实也是OCR这块的任务,之前deepseek-ocr等也在聚焦一个点:OCR的本质是从2D图片还原1D文字,自回归其实并不自然。
2、MinerU-Dizusion的训练
用比较直白的话来理解就是不把文档识别当成“按顺序生文字”的语言任务,而是当成“从图片里还原结构化文字”的视觉任务。
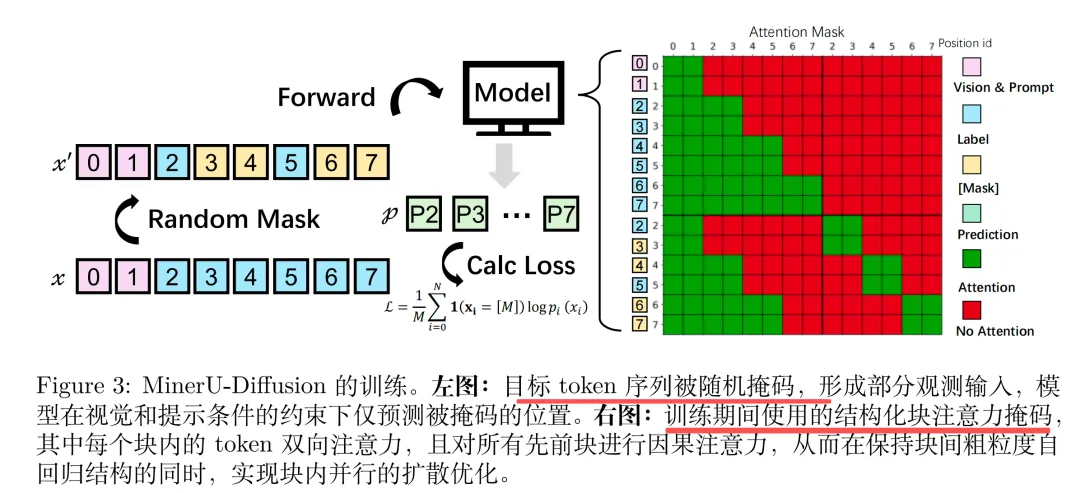
首先,训练上,训练时就不让模型 “按顺序猜”,而是 “根据图片补全打码的字”。
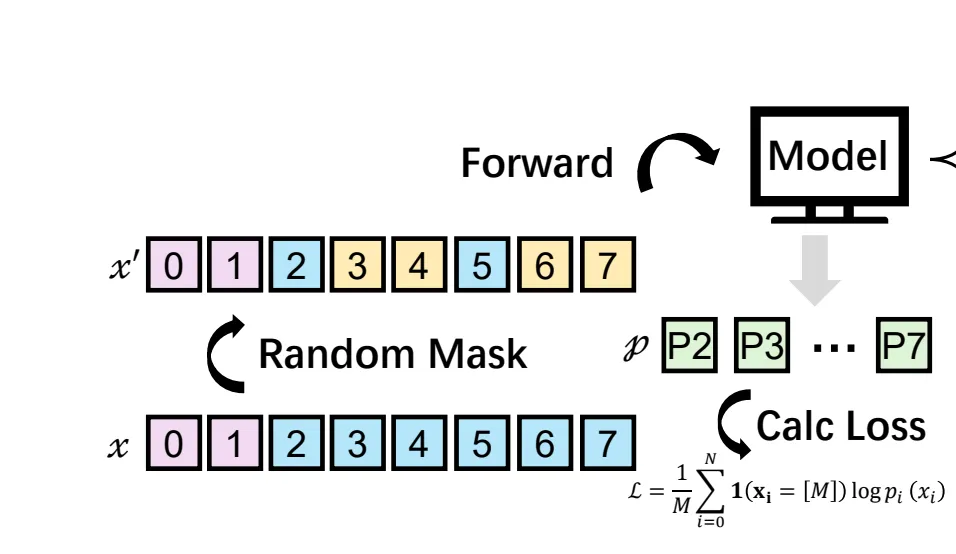
具体实现上,步骤如下:输入两个东西文档图片(Vision)+提示词(Prompt,比如“识别这段文字”)->打码(RandomMask)【把要识别的目标文字序列(Label)随机遮罩一部分,变成带MASK的不完整序列】->模型预测【模型根据图片+提示词,预测被MASK的位置应该是什么字】;->算损失(CalcLoss)【对比“模型预测的字”和“真实的Label”,算出误差(哪里猜错了)】;->模型更新【根据误差调整模型参数,让下次预测更准】;
然后,就是注意力上的变化,右半部分:块注意力掩码(Block-Attn Mask),替代传统的全注意力(Full-Attn),如图里的格子。
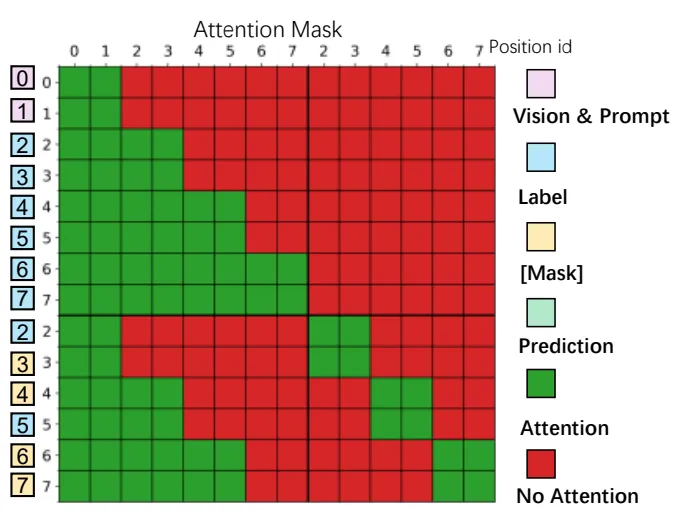
这里的核心在于,怎么去控制彼此看不到。几个步骤:
先分块:把文字序列切成一个个连续的小块(比如每32个token1块),图里能看到明显的“块边界”,随后执行两个规则:
一个是块内规则:同一小块里的token,互相能全关注,比如第一块的1/2/3/4号token,彼此都能看到,能并行更新,这就是块内并行【解决速度问题,不用全序列挨个算,计算复杂度从O(L^2)降到O(BL’^2)(L是总长度,B是块数,L’是每块长度)】
一个是块间规则:后一块能看到前一块,前一块看不到后一块(因果关注),比如第二块能看到第一块的所有token,第三块能看到第一、二块,但第一块看不到第二、三块【这就是块间因果关注,解决稳定性问题,避免长文档的 “全局漂移”(比如识别到最后,把前面的内容忘光了),块间的衔接能让模型记住上下文】
3、置信度的机制
这个也是一个很有趣的点,给解码加了置信度阈值的可控开关,用于平衡解码并行度和精度,阈值越低,并行解码范围越大,TPS 越高,速度越快;阈值越高,并行度越低,越接近逐字生成,速度越慢。
这里的机制很有意思,因为传统扩散模型是固定迭代步数(比如不管认的咋样,都迭代10轮),哪怕第1 轮就认对了,也得硬走后续步骤,纯浪费时间;这里的置信度机制是动态停步,只要所有字的置信度≥阈值,立刻停止迭代,认对了就不瞎忙活,这是速度提升的关键。
就如下图中的step数:

但是具体怎么算?文中没有讲。
但是可以做个猜想,OCR识别中,模型对某个位置会预测所有候选字的概率(比如 “中” 0.99、“申” 0.005、“仲” 0.005),取目标字的概率值,就是该结果的置信度。比如,给模型划一条 “确认线”,线以上的直接定版,线以下的继续优化,也就是识别后,置信度≥阈值τ→直接确认(黑色字,不再改);置信度<阈值τ→暂不确认。
举个例子:
第一轮识别后,“高效模型”四个字的token概率是高(0.96)、效(0.97)、模(0.95)、型(0.96):
如果阈值设得更低(比如τ=0.8),第1轮扩散后,所有字置信度都≥0.8,一轮全部确认,速度很快;
如果阈值设得更高(比如τ=0.98),第2轮后可能“模0.95”仍<0.98,会进入第3轮扩散,专门细化这个字,直到置信度达标。
所以,综上,这个工作还是很有趣的,目标是更快,技术上的创新,蛮好。
二、HTML解析工具进展之MinerU-HTML
MinerU-HTML(https://arxiv.org/pdf/2511.16397,基于Qwen3进行微调,https://huggingface.co/opendatalab/MinerU-HTML),可以从复杂的网页HTML中准确识别和提取主要内容,自动过滤导航栏、广告和元数据等辅助元素。

回顾下实现思路:
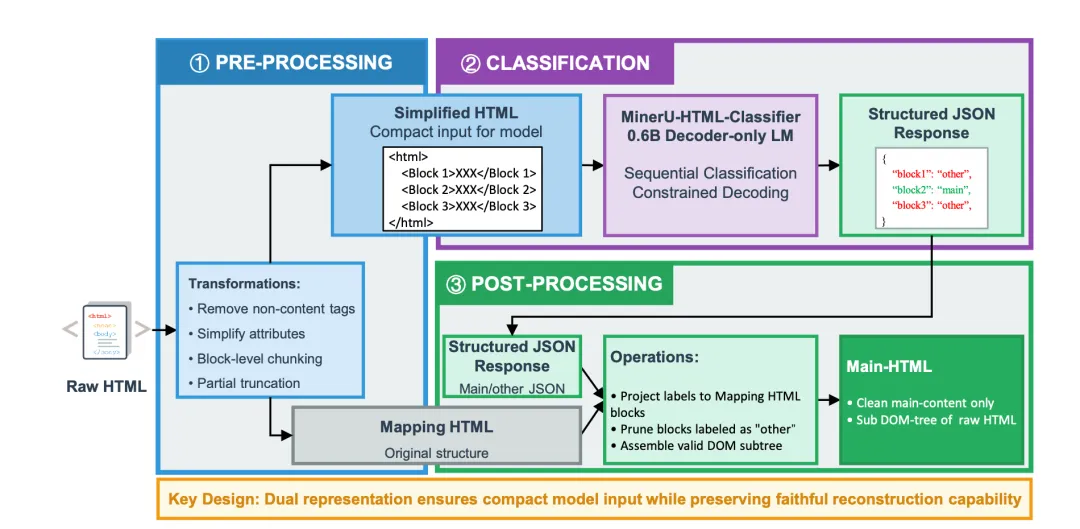
step1.HTML简化(simplify_html)【将原始 HTML 简化为结构化格式,并为每个元素分配唯一的 _item_id 属性】;
->step2.提示词构建(build_prompt)【基于简化后的 HTML 构建大语言模型提示词,引导模型对内容进行分类】;
->step3.大模型推理(inference)【使用大模型对每个元素进行分类,标记为 “正文”(主要内容)或 “其他”(辅助内容)】;
->step4.结果解析(parse_result)【对大语言模型返回的分类结果进行解析】;
->step5.正文内容提取(extract_main_html)【根据分类结果从原始 HTML 中提取主要内容】;
->step6.格式转换(convert2content):将提取的 HTML 转换为 Markdown、JSON 或 Txt 格式。
->step6.回退处理【若上述流程执行失败,将启用降级机制(trafilatura 提取、直接跳过或返回空内容)完成内容提取】
最近版本更新,MinerU-HTML-v1.1-hunyuan0.5B-compact,https://huggingface.co/opendatalab/MinerU-HTML-v1.1-hunyuan0.5B-compact,支持256k长度【这个是特点】。
并且现已集成新发布的MinerU-Webkit网页内容转换工具包(https://github.com/opendatalab/MinerU-Webkit),利用Python和lxml进行快速处理和低内存占用,支持Markdown、JSON、Txt和其他结构化格式输出,这个也是新发布。
参考文献
1、https://arxiv.org/pdf/2603.22458
关于我们
老刘,NLP开源爱好者与践行者,主页:https://liuhuanyong.github.io。
对大模型&知识图谱&RAG&文档理解感兴趣,并对每日早报、老刘说NLP历史线上分享、心得交流等感兴趣的,欢迎加入社区,社区持续纳新。
加入社区方式:关注公众号,在后台菜单栏中点击会员社区加入。