 夜雨聆风
夜雨聆风





拆完 MemPalace 源码,我终于搞清 Agent 记忆该怎么存

用 Claude Code、Cursor 做复杂项目,最让人崩溃的往往不是模型写不出代码。
而是刚给它说的东西,一转头它就忘了。
昨天定好的目录结构、已经排掉的坑、临时补的兼容方案、某个模块为什么不能那么改……只要会话一长、窗口一关、上下文一压,整个项目很容易退回”半失忆”状态。模型确实还在输出,但最后往往只剩不停返工。
这也是大家最近盯着 MemPalace 看的原因。
传播光环当然有。milla-jovovich 这个账号名本身就吸睛——和《生化危机》女主角同名,自带破圈效应。GitHub 首页那套”跑分高、免费、本地跑、接 Claude Code”的组合拳也足够抓人。但光靠这些,顶多热闹一阵。真正让它站稳脚跟的,是它正面处理的问题够实:原始语境怎么留、中途决策怎么不丢、海量记忆怎么组织、需要时怎么找回,以及这整套机制怎么真正融入 Claude Code 和 MCP 这类现有工作流。
这几件事,之前没有人一起打通过。
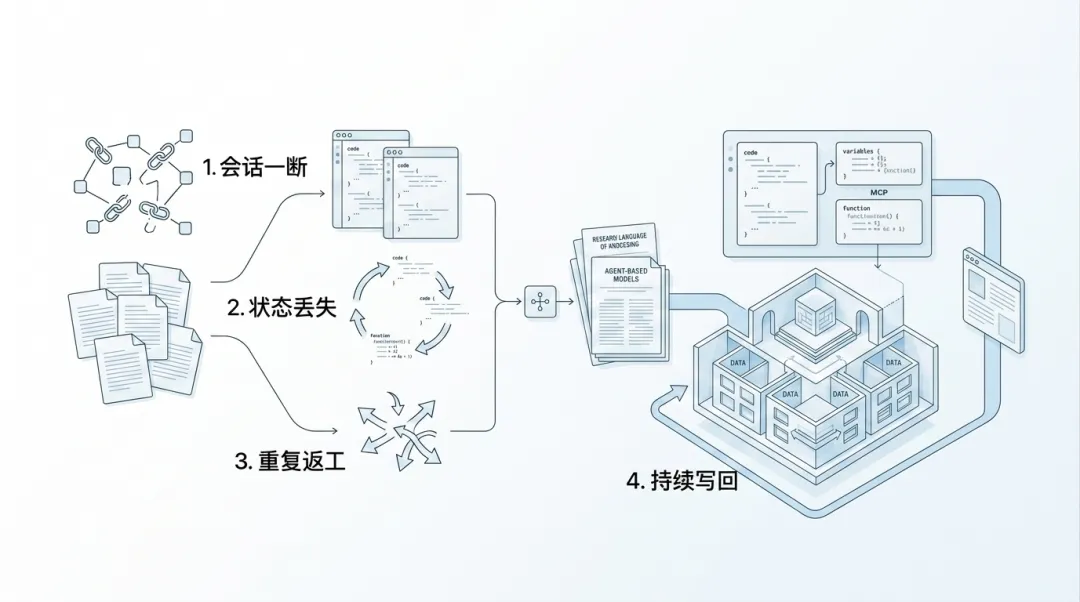
之前我们是怎么解决记忆问题的
普通 RAG 擅长检索静态资料。
把文档切块、向量化、检索,再把命中的内容塞回上下文。这套流程做知识库问答或项目文档搜索确实好使。但它本质上是被动等触发的——只有问题提出来,才会去找;没有触发,之前的开发过程依然是一盘散沙。”项目目前进展到哪了””昨天为什么做那个技术折中””这个 bug 之前试过哪条路不通”,这类正在运行的动态决策,普通 RAG 根本接不上。
摘要式记忆(Summary)更省事,但有个硬伤:它把对话里的偏好、事实、里程碑单独抽出来,压成一份长期记忆。省上下文空间、适合做用户画像(Profile),看着挺好。但压缩得太早,原始语境很容易丢。一旦抽错了或者抽得太薄,后面再想还原真实上下文,成本极高。
真正卡脖子的地方就在这:该留的原文没留住,留下的片段没结构,就算有了结构,也缺少持续自动写回工作流的机制。
MemPalace 选择把这几件事一起做——原文存储、结构组织、分层检索、自动写回、工作流接入,试图串成一条闭环。
记忆怎么接进工作流
对这个项目来说,最关键的一层不是”宫殿”这套比喻有多精巧,而是它有没有把记忆真正接入干活的流程里。
mcp_server.py 直接暴露了一整组运行时工具。除了基础搜索,它把状态查看、结构遍历、记忆的增删改、知识图谱查询、甚至日记写入,都做成了标准 MCP 动作。这让它不再是个死库,而是一层能读、能写、还能顺着结构漫游的”记忆运行时”。
翻 hooks/README.md 能看得更清楚。它专门给 Claude Code 等工具做了自动保存的 Hook:对话积累到一定轮次,或者上下文压缩(Context Compaction)触发前,会自动把当前状态强制写回记忆库。在真实的长线工作流里,最怕的从来不是搜不到,而是压根没记下来。任务一旦跨了会话、跨了窗口、跨了几天,记忆系统最先出问题的往往就是写入这条链路(Write Path)。
Hook 的配置很直白。在项目根目录的 .claude/settings.local.json 里加两条:
{ "hooks": { "Stop": [ { "matcher": "", "hooks": [ { "type": "command", "command": "python -m mempalace.hooks.save_hook" } ] } ], "PreCompact": [ { "matcher": "", "hooks": [ { "type": "command", "command": "python -m mempalace.hooks.precompact_hook" } ] } ] }}Stop Hook 对应每次 AI 输出结束,累积到 15 条人类消息触发一次强制写回;PreCompact Hook 是上下文压缩前的必执行项,确保内容在被压缩前已经落地。
接入 MCP 的命令也很简单:
claude mcp add mempalace -- python -m mempalace.mcp_server接入之后,MCP 工具分两类:读取类用于查询和遍历,写入类负责把当前状态持续写进 palace:
# 读取类(查状态、搜内容、遍历结构)mempalace_status # 当前 palace 概览mempalace_search # 语义搜索mempalace_get_taxonomy # 查 Wing / Room 结构mempalace_kg_query # 知识图谱查询mempalace_traverse # 按结构遍历记忆mempalace_find_tunnels # 找跨翼关联# 写入类(存内容、更新图谱、写日记)mempalace_add_drawer # 新增原文块mempalace_delete_drawer # 删除抽屉mempalace_diary_write # 写当前会话日记mempalace_kg_add # 添加知识图谱节点mempalace_kg_invalidate # 标记失效的旧事实每次写入都会先记一条 WAL(Write-Ahead Log)到 ~/.mempalace/wal/write_log.jsonl,支持后续审计和回滚。
许多开源项目做到”能搜资料”就止步了。MemPalace 多走的那一步,是让记忆在 Agent 干活时跟着自动积累——把正在经历的决策、事实和上下文持续存下来,而不是等事后再翻。
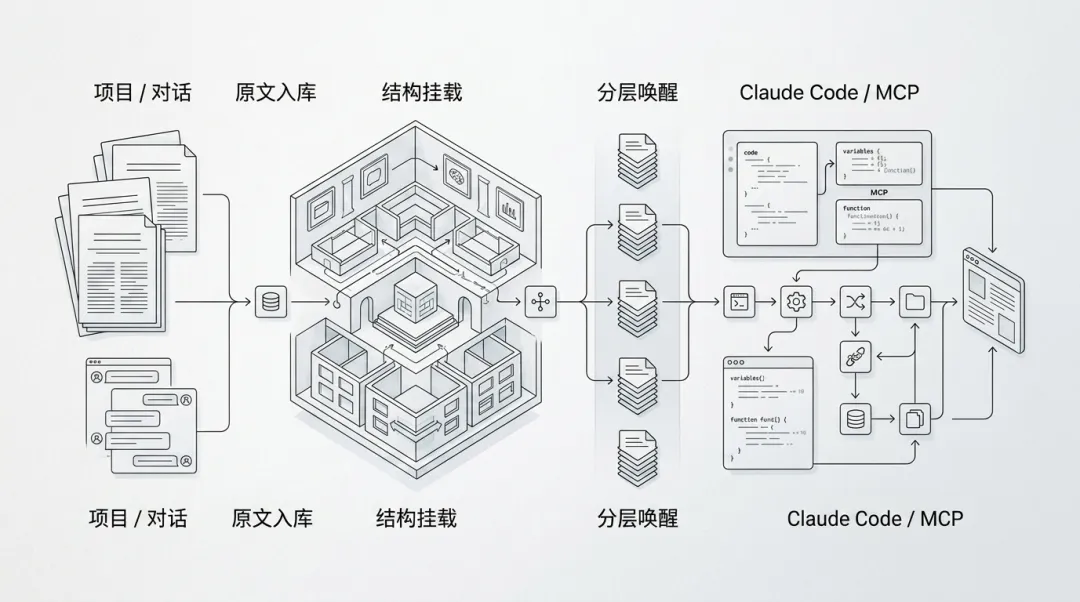
记忆在底层是怎么组织的
把原文保存下来
看代码就能发现,读取项目文件主要靠 miner.py 这条线:
-
1. 扫描目录、过滤掉构建产物和缓存 -
2. 读取文本、按段落切块(Chunk) -
3. 塞进 ChromaDB 的集合里
对话内容的存储则归 convo_miner.py 管。它按问答对切块;如果开了 general 模式,还会调用提取器,把内容细分为决策(Decision)、偏好(Preference)、里程碑(Milestone)、问题(Problem)等类别。
对话还会按内容属性自动分到五个房间:
TOPIC_KEYWORDS = { "technical": [ "implement", "function", "class", "method", "error", "bug", "code", "refactor", "debug", "test", "api", "database" ], "architecture": [ "structure", "design", "pattern", "layer", "module", "system", "component", "interface", "schema", "pipeline", "workflow" ], "planning": [ "plan", "roadmap", "milestone", "priority", "timeline", "goal", "objective", "sprint", "backlog", "scope" ], "decisions": [ "decide", "choose", "option", "tradeoff", "approach", "strategy", "consider", "reason", "because", "therefore" ], "problems": [ "issue", "problem", "fail", "broken", "wrong", "stuck", "blocker", "conflict", "limitation", "constraint" ],}detect_convo_room() 会对内容前 3000 字符做关键词评分,得分最高的房间就是它的归属。同一段对话里,关于技术实现的内容和关于架构设计的讨论,会分别存进不同的房间和序列里单独管理。
写进 drawer 时,不会先压成摘要,而是把原文和结构 metadata 一起存下去:
metadata = { "wing": wing, "room": room, "source_file": source_file, "chunk_index": chunk_index, "filed_at": datetime.now().isoformat(),}collection.upsert( documents=[content], ids=[drawer_id], metadatas=[metadata],)市面上太多系统喜欢在入口处”先做个摘要再存”。MemPalace 的思路是不急着压缩——原始文件、原始问答先原汁原味地留底,怎么检索、怎么抽提是后话。这种看似有点”笨”的做法,反而最能保住那些一旦丢了就很难找回来的原始语境。
给记忆加一层空间结构
只存原文还不够。所有数据平铺在向量空间里,规模稍微增加,检索就会沦为全库大海捞针。MemPalace 给记忆强制加上了 Wing(翼) / Room(房间) / Drawer(抽屉) 三级结构:
-
• Wing是大的业务归属域 -
• Room是归属域下的具体技术议题 -
• Drawer是实际装着原文碎片的抽屉
有了这层结构,召回记忆就不再是”算出相似度最高的那几段”,而是”处理这个问题,去哪个域、哪个房间的抽屉里翻”。检索从扁平的向量匹配,变成了带结构的定点回忆。
README 里放出的召回率提升数据,本质上也是这个逻辑:结构化的元数据(Metadata)过滤确实能让召回更准。官方后来的更正说明直接承认了,所谓 +34% Palace Boost,靠的就是 Metadata 过滤的功劳,没有神秘的黑魔法。这种坦诚反而让人踏实——它是个脚踏实地的工程实现,不是过度包装的学术神话。
把检索拆成分层加载
普通 RAG 的节奏是遇到问题才去搜。layers.py 里做的是另一件事:把上下文拆成 L0 / L1 / L2 / L3 四层,最浅层常驻身份设定和核心事实,中间层按翼和房间按需加载,只有到最深层才触发全局搜索。
# Layer 0: Identity (~50 tokens) - Always loaded# Layer 1: Critical facts (~120 tokens, AAAK) - Always loaded# Layer 2: On-Demand - Loaded when topic comes up# Layer 3: Deep Search (unlimited) - Full ChromaDB semantic search哪些信息需要一直常驻?哪些细节等需要时再翻?前者维系工作状态,后者才是传统意义上的资料检索。MemPalace 没把所有记忆揉进同一个搜索框,而是给 Agent 搭了一个有轻重缓急的常驻大脑。
MemoryStack 类把这四层封装成统一接口:
stack = MemoryStack()# 唤醒时加载 L0+L1,常驻约 600–900 tokensprint(stack.wake_up())# 按副翼按需加载 L2print(stack.recall(wing="my_project"))# L3 全库语义搜索print(stack.search("why did we drop the redis cache"))实际 token 占用:L0 简明身份设定约 100 tokens,L1 自动抽取重要度最高的 15 条记忆约 500–800 tokens,两者合并大概 600–900 tokens。L2 和 L3 按需展开,不会默认塞满初始层。
把事实单独存进一条轨道
代码里还并行跑着一套知识图谱(knowledge_graph.py),走本地 SQLite 存储,记录实体与关系、时间边界(valid_from / valid_to)、以及失效信息。
这条轨道专门处理”在某个时间点,什么事实是真的”以及”某个逻辑关系是何时变化的”——不同类型的信息进不同的位置,而不是全塞进向量库。
CREATE TABLE IF NOT EXISTS triples ( id TEXT PRIMARY KEY, subject TEXT NOT NULL, predicate TEXT NOT NULL, object TEXT NOT NULL, valid_from TEXT, valid_to TEXT, source_file TEXT);很多记忆系统最后都退化成一张干瘪的人设卡或偏好表。MemPalace 想把原文、事实、时间线和空间结构彻底拆开安放,最后再统一收回工作流。
这套系统现在能做什么、做不到什么
再分析完代码后,有几条边界值得说清楚。
现阶段最稳定的记忆路径还是是原文存储:把项目文件和对话按原文切块入库,挂上 Wing / Room 结构标签,需要的时候再语义检索找回来,配合 Hooks 持续自动写回。这套链路代码落地扎实,是 MemPalace 目前真正可以依赖的部分。
README 里还提到一套叫 AAAK 的压缩模式——它会把记忆内容压缩成一种高度缩写的格式,目的是用更少的 token 塞进更多信息。但官方自己在 4 月 7 日的更正说明里承认,AAAK 是有损的,压缩过程会丢信息。在 LongMemEval(一个专门测试长文本记忆召回的基准)上,AAAK 模式的召回准确率是 84.2%,原文模式是 96.6%。也就是说,压得越狠,找回来的东西越不准。现阶段更可靠的还是直接存原文。
README 里还描述了一些更高级的结构,比如跨翼的关联通道、更细的记忆分类层级。从代码成熟度看,这些在当前版本里还没有全量落地,不能当成开箱即用的功能。至于 +34% Palace Boost 这个数字,官方自己说了,靠的是结构化标签(Metadata)过滤,不是什么神秘算法——老实承认这点反而更可信。
总体来说,它是一套思路扎实的记忆架构,但还不是开箱即用、经得起长期大项目验证的成品。
它真正做到的那一步
MemPalace 推进的,是 Agent 记忆里几件之前没人一起做完过的事:原文怎么留住、结构怎么挂上去、检索怎么分层找回、写回怎么自动持续,最后怎么真正接进 Claude Code 和 MCP 这类日常工作流。这条链路它做到了。
做到这一步,不代表问题全解决了。但它至少把问题本身说清楚了——Agent 在长期项目里需要的,不只是一个能搜文档的知识库,而是一套能跟着工作流一起跑的动态记忆系统。