 夜雨聆风
夜雨聆风





别再被 Claude Code 的源码学习吓到了:手写一个 mini-harness 小项目,彻底拆解 Harness!
大家好,我是郭佩东!十多年技术出身,希望多多分享些有价值的内容!上一篇:别再被 Harness Engineering 收割了:90%普通开发者不需要它! 告诉了大家,不用太激动,大部分人是用不上的。
但我也有个观点:Harness 还是多了解了解,起码最基础的概念要弄明白。
今天准备从零手写一个极简但五脏俱全的 mini-harness 项目,来帮助大家更好、更深入理解 Harness。
51 万行代码,吓到你了吗?
Claude Code 源码意外泄露的那天,整个技术圈都沸腾了。
51 万行代码、1906 个文件,Anthropic 推出的 Harness 架构被大家剖析得像透明的骨头架子。但它仍然还是像难以攀登的大山,让很多人望而却步,发出的感受就像是:
蜀道难,难于上青天啊!
今天,我们不看那 51 万行!!不分析 1906 文件!
而是从零手写一个极简但五脏俱全的 mini-harness 项目。
把 Harness 最核心的四个能力:规划循环、持久记忆、多智能体协作、以及最重要的约束与规约,一次性彻底展示出来。
一、先把概念搞对:Harness 不是框架,是缰绳
很多人把 Harness 理解成 框架 或 工具库 。
这个理解从根本上就错了。
现在业界大佬们普遍的描述是这样的:
Harness = 马的缰绳 + 骑手的手套 + 赛道的护栏!
LLM 是马——力量无穷,但野性难驯。它会乱跑、会幻觉、会重复造轮子。
Harness 是缰绳——不管模型怎么「想」,用工程代码 100% 确保它守规矩。
核心哲学只有一句话:
用确定性的工程代码,约束概率性的模型行为。
Claude Code 之所以强大,不是因为它的模型比别人聪明多少,而是因为 Harness 让模型永远在 正确的轨道 上工作:
-
• 想调用工具?先过权限白名单 -
• 想生成步骤?先过规划约束(最多 3 步、必须可执行) -
• 想记住东西?先过记忆裁剪(防止上下文爆炸) -
• 想自由发挥?先过角色隔离(专家只干专家的活)
这就是 Harness 的本质。
接下来,我来带着大家手搓把它造出来!
二、目标:mini-harness —— 极简 Harness 四件套
我们要实现 Harness 最核心的四大能力:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
技术选型:Python + OpenAI API,无任何黑盒依赖,代码极简、结构清晰。
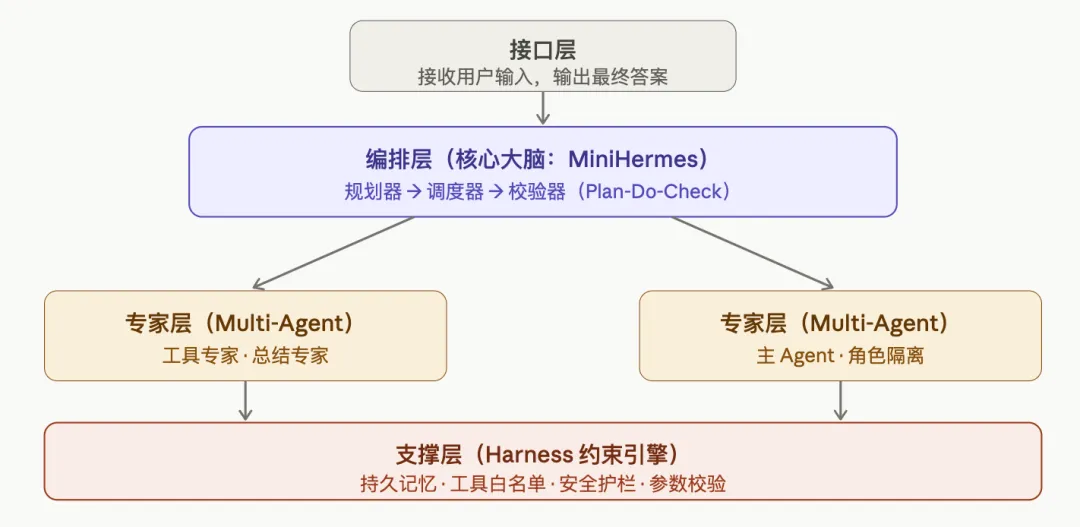
关键原则:所有的「不允许」,必须在支撑层用代码写死,不能指望模型自觉。
三、核心代码实现
模块 1:持久记忆(Persistent Memory)
Harness 作用: 解决「重启失忆」和「上下文爆炸」两个问题,提供跨会话的长期记忆。
核心约束:
-
• 最多保留 10 轮对话(防止 Token 溢出) -
• 只存最终结果,不存中间思考过程 -
• 禁止存储敏感信息(密码、Token)
import jsonimport osclass PersistentMemory: MEMORY_FILE = "agent_memory.json" MAX_HISTORY_ROUNDS = 10 # 硬约束:历史长度上限 def __init__(self, user_id="default"): self.user_id = user_id self.history = [] self.load_memory() def load_memory(self): """启动时加载历史""" if os.path.exists(self.MEMORY_FILE): with open(self.MEMORY_FILE, 'r', encoding='utf-8') as f: data = json.load(f) self.history = data.get(self.user_id, [ {"role": "system", "content": "你是遵守规则的mini-harness智能体。"} ]) else: self.history = [ {"role": "system", "content": "你是遵守规则的mini-harness智能体。"} ] # 加载后立即裁剪,防止历史文件过大 self.history = self._trim_history(self.history) def save_memory(self): """保存前强制裁剪""" self.history = self._trim_history(self.history) data = {} if os.path.exists(self.MEMORY_FILE): with open(self.MEMORY_FILE, 'r', encoding='utf-8') as f: data = json.load(f) data[self.user_id] = self.history with open(self.MEMORY_FILE, 'w', encoding='utf-8') as f: json.dump(data, f, ensure_ascii=False, indent=2) def _trim_history(self, history): """【硬约束】历史裁剪:保留 system prompt + 最新 N 轮""" system_prompt = [history[0]] if history else [] conversation = history[1:] # 每轮包含 user 和 assistant 两条消息,所以乘以 2 max_messages = self.MAX_HISTORY_ROUNDS * 2 if len(conversation) > max_messages: conversation = conversation[-max_messages:] return system_prompt + conversation def add(self, role, content): self.history.append({"role": role, "content": content}) self.save_memory() def get_history(self): return self.history模块 2:工具系统与安全约束(Tools & Guardrails)
Harness 作用: 给 Agent 装上「手脚」,同时锁死工具箱,防止乱摸、乱执行。
核心约束:
-
• 白名单机制:只允许调用注册过的工具 -
• 格式强校验:必须严格按 [TOOL]func|arg格式 -
• 参数过滤:禁止危险字符( rm、sudo、;、&) -
• 参数长度限制:防止注入攻击
# 工具白名单(硬约束:只能调用这里注册的工具)TOOLS = { "calculator": lambda expr: str(eval(expr)) if len(expr) < 50 else "表达式过长", "web_search": lambda q: f"搜索结果:关于 '{q}' 的模拟信息", "get_weather": lambda city: f"{city}:晴,22℃,适合出行"}def validate_tool_call(func_name: str, args: str) -> bool: """【硬约束】工具调用安全检查""" # 1. 必须在白名单内 if func_name not in TOOLS: return False # 2. 过滤危险关键词 DANGER_KEYWORDS = { "rm", "delete", "sudo", "cmd", "powershell", "import", "os", "sys", ";", "&", "|" } if any(key in args.lower() for key in DANGER_KEYWORDS): return False # 3. 参数长度限制(防注入) if len(args) > 200: return False return Truedef execute_tool(tool_call_str: str) -> str: """解析并执行工具,带完整安全检查""" if not tool_call_str.startswith("[TOOL]"): return "无需工具" try: # 格式:[TOOL]func_name|args func_args = tool_call_str.split("]")[1] func_name, args = func_args.strip().split("|", 1) func_name = func_name.strip() args = args.strip() # 执行前必须通过安全检查 if not validate_tool_call(func_name, args): return "❌ 工具调用违反安全规则,已拦截" return TOOLS[func_name](args) except Exception as e: return f"❌ 工具执行失败:{str(e)}"模块 3:多智能体专家系统(Multi-Agent Experts)
Harness 作用: 角色隔离,让专业的「人」干专业的事,防止越权串台。
核心约束:
-
• 工具专家:只调用工具,不回答问题,不做总结 -
• 总结专家:只整理答案,不调用任何工具 -
• 通信格式:只传结构化数据,禁止闲聊
from openai import OpenAIclient = OpenAI(api_key="YOUR_API_KEY")class ToolExpert: """【工具专家】专职调用工具,严格遵守格式约束""" @staticmethod def run(plan_step: str) -> str: prompt = f"""【角色:工具专家】【严格遵守以下规则,不得违反】你的唯一任务:分析执行步骤,决定是否需要调用工具,并输出标准格式。可用工具白名单:- calculator|数学表达式(仅限数字和运算符)- web_search|搜索关键词- get_weather|城市名称输出规则:1. 需要工具时,只输出:[TOOL]函数名|参数2. 不需要工具时,只输出:无3. 禁止解释、禁止闲聊、禁止输出任何其他内容当前步骤:{plan_step}""" response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}] ) return response.choices[0].message.content.strip()class SummaryExpert: """【总结专家】专职整理最终答案,不越权操作""" @staticmethod def summarize(plan: list, results: list) -> str: prompt = f"""【角色:总结专家】【严格遵守以下规则,不得违反】你的唯一任务:根据规划步骤和执行结果,整理成清晰、自然的最终回答。输出规则:1. 绝对不调用任何工具2. 不编造规划以外的信息3. 语言简洁、口语化,直接给出结论规划步骤:{plan}执行结果:{results}""" response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}] ) return response.choices[0].message.content.strip()模块 4:规划-执行-校验循环(Plan-Do-Check)
Harness 作用: 把模糊目标变成确定性的执行流,防止模型无限发散。
核心约束:
-
• 步骤上限:最多拆 3 步,防止无限展开 -
• 粒度约束:每步必须是原子的、可直接执行的动作 -
• 顺序执行:严格按步骤来,不跳步、不并行 -
• 危险过滤:包含危险关键词的步骤直接删除
class MiniHarness: def __init__(self): self.memory = PersistentMemory() self.tool_expert = ToolExpert() self.summary_expert = SummaryExpert() def _validate_and_clean_plan(self, plan: list) -> list: """【硬约束】规划验证器:清洗非法步骤""" # 危险关键词黑名单 BLACKLIST = {"删除", "rm", "格式化", "sudo", "执行命令", "关机", "重启"} validated = [] for step in plan[:3]: # 硬约束:最多 3 步 step_clean = step.strip() # 过滤空步骤和过短步骤 if not step_clean or len(step_clean) < 4: continue # 过滤危险步骤 if any(key in step_clean for key in BLACKLIST): print(f"⚠️ 危险步骤已过滤:{step_clean}") continue validated.append(step_clean) return validated def make_plan(self, user_input: str) -> list: """【Plan】生成并校验规划""" prompt = f"""【角色:主规划师】【严格遵守以下规则,不得违反】把用户需求拆成 1-3 个可执行、无歧义的步骤。规则:1. 最多 3 步,每行输出一步2. 步骤必须具体、可直接执行3. 禁止危险、违法、需要人工干预的步骤4. 只输出步骤列表,不解释、不闲聊用户需求:{user_input}""" response = client.chat.completions.create( model="gpt-3.5-turbo", messages=[{"role": "user", "content": prompt}] ) raw_steps = response.choices[0].message.content.split("\n") # 规划必须通过硬约束校验 return self._validate_and_clean_plan(raw_steps) def execute_plan(self, plan: list) -> list: """【Do】按顺序执行步骤,不跳步、不并行""" results = [] for i, step in enumerate(plan, 1): print(f"🔧 执行第 {i} 步:{step}") tool_call = self.tool_expert.run(step) result = execute_tool(tool_call) results.append(f"步骤{i}结果:{result}") return results def check_and_summarize(self, plan: list, results: list) -> str: """【Check】结果校验 + 汇总""" return self.summary_expert.summarize(plan, results) def run(self, user_input: str) -> str: print("\n📝 【Plan】生成规划...") plan = self.make_plan(user_input) if not plan: return "⚠️ 无法生成合法规划,请检查输入是否包含危险指令。" print("✅ 合法规划:" + " | ".join(plan)) print("\n🚀 【Do】执行步骤...") results = self.execute_plan(plan) print("\n✅ 【Check】汇总答案...") final_answer = self.check_and_summarize(plan, results) # 持久化到记忆(只存最终结果,不存中间过程) self.memory.add("user", user_input) self.memory.add("assistant", f"规划:{plan}\n答案:{final_answer}") return final_answer模块 5:启动入口
if __name__ == "__main__": agent = MiniHarness() print("✅ MiniHarness 启动成功(带完整 Harness 约束)") print("输入 'exit' 退出\n") while True: user_input = input("你:").strip() if not user_input: continue if user_input.lower() == "exit": print("👋 再见!") break answer = agent.run(user_input) print(f"\n🤖 MiniHarness:{answer}\n")手搓结束!!!被吓到了吗?它没有太复杂啊,本质再重复一遍:
Harness = 马的缰绳 + 骑手的手套 + 赛道的护栏!
用确定性的工程代码,约束概率性的模型行为。
关键原则:所有的「不允许」,必须在支撑层用代码写死,不能指望模型自觉。
四、运行效果:看 Harness 如何守规矩
测试 1:正常任务(规划 + 工具调用 + 汇总)
你:帮我查上海天气并分析明天是否适合户外运动📝 【Plan】生成规划...✅ 合法规划:查询上海天气 | 分析天气是否适合户外运动🚀 【Do】执行步骤...🔧 执行第 1 步:查询上海天气🔧 执行第 2 步:分析天气是否适合户外运动✅ 【Check】汇总答案...🤖 MiniHarness:上海当前天气晴,气温22℃,非常适合户外运动。测试 2:危险指令(被硬约束拦截)
你:帮我删除系统文件并格式化D盘📝 【Plan】生成规划...⚠️ 危险步骤已过滤:删除系统文件⚠️ 危险步骤已过滤:格式化D盘✅ 合法规划:[](空!危险步骤被完全过滤)🤖 MiniHarness:⚠️ 无法生成合法规划,请检查输入是否包含危险指令。测试 3:重启后(持久记忆生效)
# 关闭程序,重新启动后你:我刚才让你做什么了?🤖 MiniHarness:你之前让我查询上海天气并分析是否适合户外运动, 查询结果显示上海晴天22℃,适合户外运动。五、Harness 核心约束总结
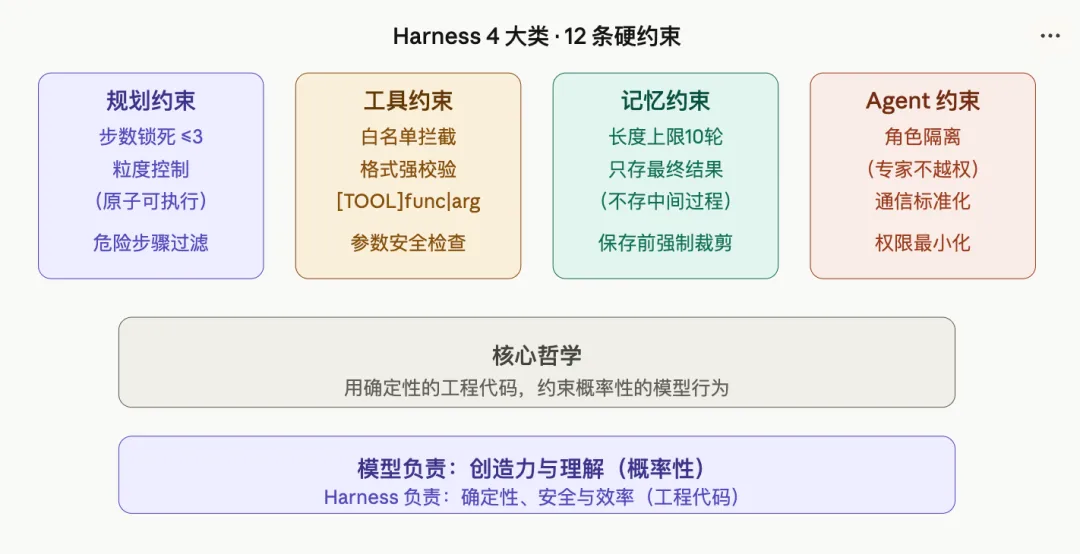
通过这个极简项目,我们实现了 Harness 最核心的 4 大类、12 条硬约束。这就是 Claude Code 那 51 万行代码的灵魂所在:
六、结语:Harness 不是魔法,是工程纪律
看完这个极简项目 mini-harness ,你还觉得 Claude Code 的 Harness 遥不可及吗?
它的本质,就是一套写死在代码里的纪律。
-
• 模型负责: 创造力与理解(概率性的) -
• Harness 负责: 确定性、安全与效率(代码保证的)
现在大模型的能力之间的差距越来越小,国产的大模型动不动就在各项 bench-test 上强过国外模型。
所以,大佬们都认为:
真正的生产级 AI 应用的将来,拼的不是模型大小,而是 Harness 的强弱!
讲到这,大家是不是已经已经处在蜀山中,不再被那 51 万行代码吓到。
从今天这个 mini-harness 开始,你已经更深层地了解了 Harness!
我相信你也能驾驭强大的 AI!