 夜雨聆风
夜雨聆风





Excel双文件透视对比工具
Excel双文件透视对比工具
下载地址在最后
一、项目概述
本项目是一款纯前端实现的 Excel 双文件透视对比工具,用户可以在浏览器中加载两个 Excel 文件,分别配置透视表的行、列、值字段和聚合方式,生成透视表后进行数据对比,并将对比结果以颜色标记的方式可视化呈现。工具支持导出对比结果为 Excel 和 PDF 格式,同时内置测试数据生成功能,方便快速验证。
该工具的核心设计理念是”零服务端依赖、纯离线运行”。所有第三方库(Bootstrap、jQuery、SheetJS、html2canvas、jsPDF)均以本地文件形式存放在 libs/ 目录下,无需连接外网即可在企业内网环境中正常使用。这一特性使其特别适合对网络安全有严格要求的政企、金融等行业场景。
项目的技术栈选型非常精简:HTML5 + CSS3 + 原生 JavaScript,配合 Bootstrap 5 做 UI 框架,SheetJS(xlsx.js)处理 Excel 读写,html2canvas + jsPDF 实现 PDF 导出。没有使用任何前端构建工具(Webpack、Vite 等),也没有引入 React、Vue 等框架,做到了”双击 index.html 即可运行”的极致简洁。
二、项目文件结构
├── index.html # 主页面,UI 布局与结构
├── app.js # 核心业务逻辑
├── style.css # 样式表
└── libs/ # 本地第三方库
├── bootstrap.min.css # Bootstrap 5 样式
├── bootstrap.bundle.min.js # Bootstrap 5 JS(含 Popper)
├── jquery.min.js # jQuery(兼容性辅助)
├── xlsx.full.min.js # SheetJS,Excel 读写核心
├── html2canvas.min.js # DOM 截图为 Canvas
├── jspdf.umd.min.js # PDF 生成
├── jspdf.plugin.autotable.min.js # jsPDF 表格插件(备用)
└── xlsx.full.min.js # SheetJS 完整版
这种扁平化的文件结构有几个好处:第一,部署极其简单,整个目录复制到任意 HTTP 服务器或直接本地打开即可;第二,维护成本低,所有业务逻辑集中在一个 app.js 文件中;第三,离线友好,所有依赖都是本地文件,不存在 CDN 不可达的问题。
三、核心技术点详解
3.1 Excel 文件读取与解析
文件读取采用 HTML5 的 FileReader API,以 ArrayBuffer 格式读取文件内容,然后交给 SheetJS 解析:
functionreadFile(e, n) {
var f = e.target.files[0];
if (!f) return;
var reader = new FileReader();
reader.onload = function (ev) {
var buf = ev.target.result;
if (n == 1) wb1 = XLSX.read(buf, { type: 'array' });
else wb2 = XLSX.read(buf, { type: 'array' });
// 填充工作表选择器...
loadSheet(n);
};
reader.readAsArrayBuffer(f);
}
这里有几个关键设计决策:
-
使用 readAsArrayBuffer而非readAsBinaryString,前者在现代浏览器中性能更好,且对大文件的内存管理更友好。 -
SheetJS 的 XLSX.read()配合type: 'array'参数,可以直接消费 ArrayBuffer,避免了额外的编码转换。 -
工作簿对象( wb1、wb2)保存为全局变量,这样切换工作表时无需重新读取文件。
工作表加载时,使用 sheet_to_json 的 header: 1 模式将数据转为二维数组,再根据用户指定的标题行位置提取列名和数据行:
var arr = XLSX.utils.sheet_to_json(ws, { header: 1, raw: false });
var cols = arr[header] || [];
var rows = arr.slice(header + 1);
raw: false 参数确保所有单元格值都以字符串形式返回,这对于后续的中文内容处理至关重要——避免了 SheetJS 自动将某些中文内容误判为日期或数字的问题。
3.2 拖拽系统的双层架构
拖拽功能是本项目交互设计的核心,采用了”双层拖拽”架构:
第一层:字段区 → 目标区(跨容器拖拽)
用户从”可用字段”区域将字段拖入”行”、”列”、”值”目标区域。这一层使用 HTML5 原生 Drag and Drop API 实现:
functiononFieldDragStart(e) {
dragType = 'field';
dragSource = null;
e.dataTransfer.setData('text/plain', e.target.getAttribute('data-field'));
e.dataTransfer.effectAllowed = 'copy';
}
字段源使用 data-field 属性标识字段名,拖拽时通过 dataTransfer 传递。目标区通过 drop 事件接收,并检查是否已存在同名字段以防重复添加。
第二层:目标区内排序(同容器拖拽)
已拖入目标区的字段可以通过上下拖动来调整顺序,这直接影响透视表的行/列层级。排序逻辑的核心是根据鼠标位置判断插入点:
if (target && target !== dragSource && box.contains(target)) {
var rect = target.getBoundingClientRect();
if (e.clientY < rect.top + rect.height / 2) {
box.insertBefore(dragSource, target); // 插入到目标上方
} else {
box.insertBefore(dragSource, target.nextSibling); // 插入到目标下方
}
}
通过 getBoundingClientRect() 获取目标元素的位置,将其垂直中线作为分界:鼠标在上半部分则插入到目标前面,在下半部分则插入到目标后面。同时配合 CSS 类 drag-over-top 和 drag-over-bottom 提供蓝色边框的视觉指示,让用户清楚地知道放下后字段会出现在哪个位置。
两层拖拽通过全局变量 dragType 区分:'field' 表示从字段区拖入,'reorder' 表示区内排序。dragSource 保存被拖动的 DOM 元素引用,用于排序时的 DOM 操作。
每个目标区内的字段项还带有一个红色的 × 删除按钮,点击即可移除该字段,无需拖回字段区:
var rm = document.createElement('span');
rm.className = 'remove-btn';
rm.innerHTML = '×';
rm.onclick = function () { div.remove(); };
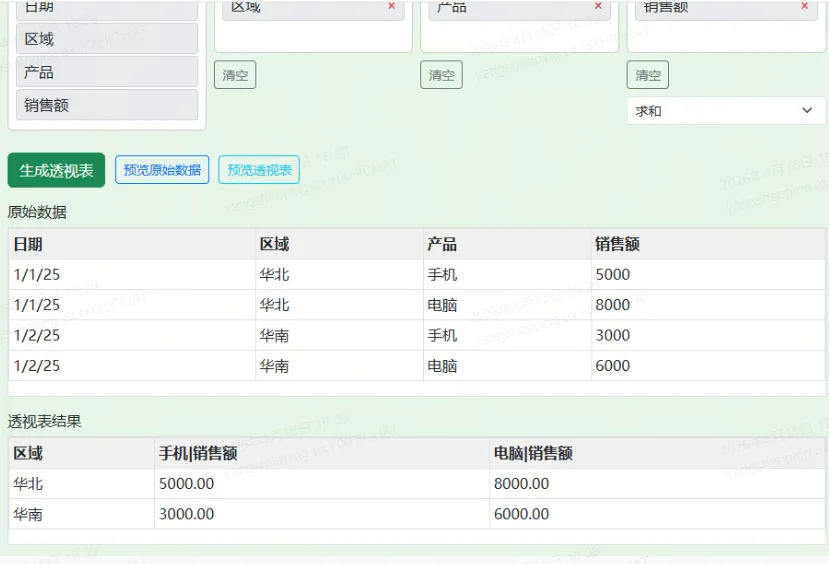
3.3 透视表引擎
透视表的生成是整个工具的计算核心。算法分为三个阶段:
阶段一:数据聚合
遍历源数据,以”行键 + 列键 + 值字段名”的组合作为唯一键,累积计算各项统计量:
var key = rk + "~~" + ck + "~~" + v;
if (!map[key]) map[key] = { sum: 0, count: 0, min: null, max: null, sum2: 0 };
map[key].sum += num;
map[key].count += 1;
map[key].min = map[key].min === null ? num : Math.min(map[key].min, num);
map[key].max = map[key].max === null ? num : Math.max(map[key].max, num);
map[key].sum2 += num * num;
这里的设计巧妙之处在于:一次遍历同时收集了 sum、count、min、max、sum2(平方和)五个统计量,使得后续无论用户选择哪种聚合方式(求和、平均、计数、最大、最小、标准差),都可以直接从已有数据中计算,无需重新遍历。
标准差的计算使用了 Welford 的在线算法变体:
case"std":
val = o.count > 1
? Math.sqrt((o.sum2 - o.sum * o.sum / o.count) / (o.count - 1))
: 0;
break;
公式 sqrt((Σx² - (Σx)²/n) / (n-1)) 是样本标准差的计算公式,分母使用 n-1(贝塞尔校正)而非 n,这在统计学上更为准确。
阶段二:矩阵构建
将聚合结果组织为行键 × 列键的二维矩阵:
var mat = {};
rowKeys.forEach(function (r) { mat[r] = {}; });
colKeys.forEach(function (c) {
vals.forEach(function (v) {
rowKeys.forEach(function (r) {
mat[r][c + "|" + v] = val; // 计算后的聚合值
});
});
});
列键和值字段名用 | 连接作为矩阵的列标识,这样当有多个值字段时,每个列键会展开为多列。
阶段三:输出构建
将矩阵转换为表格友好的对象数组格式,行字段作为前导列,后跟所有数据列:
var out = rowKeys.map(function (r) {
var o = {};
rows.forEach(function (k, i) { o[k] = r.split("|")[i]; });
Object.keys(mat[r]).forEach(function (mk) { o[mk] = mat[r][mk]; });
return o;
});
3.4 中文汇总数据兼容
这是本项目的一个重要特性。实际业务中的 Excel 文件经常包含中文汇总行,如”合计”、”小计”、”汇总说明”等。这些行的数值列可能包含非数字内容(如”总计”),如果简单地用 parseFloat 转换会得到 NaN,导致对比结果异常。
解决方案体现在两个层面:
透视表渲染层面:区分行字段和值字段的渲染逻辑:
if (rowFields && rowFields.indexOf(c) >= 0) {
td.innerText = v != null ? v : ''; // 行字段:保持原始文本
} else {
var num = parseFloat(v);
td.innerText = isNaN(num) ? (v != null ? v : '') : num.toFixed(2); // 值字段:尝试数字化
}
对比逻辑层面:采用行键匹配而非索引匹配,并对非数字值做优雅降级:
functionmakeRowKey(row) {
return rowFields.map(function (k) { returnString(row[k] || '').trim(); }).join('||');
}
// 对比时检查数值有效性
var avIsNum = !isNaN(av);
var bvIsNum = !isNaN(bv);
if (!avIsNum && !bvIsNum) {
row['文件1_' + k] = a[k] || '';
row['文件2_' + k] = b[k] || '';
row['差异_' + k] = ''; // 非数字值不计算差异
return;
}
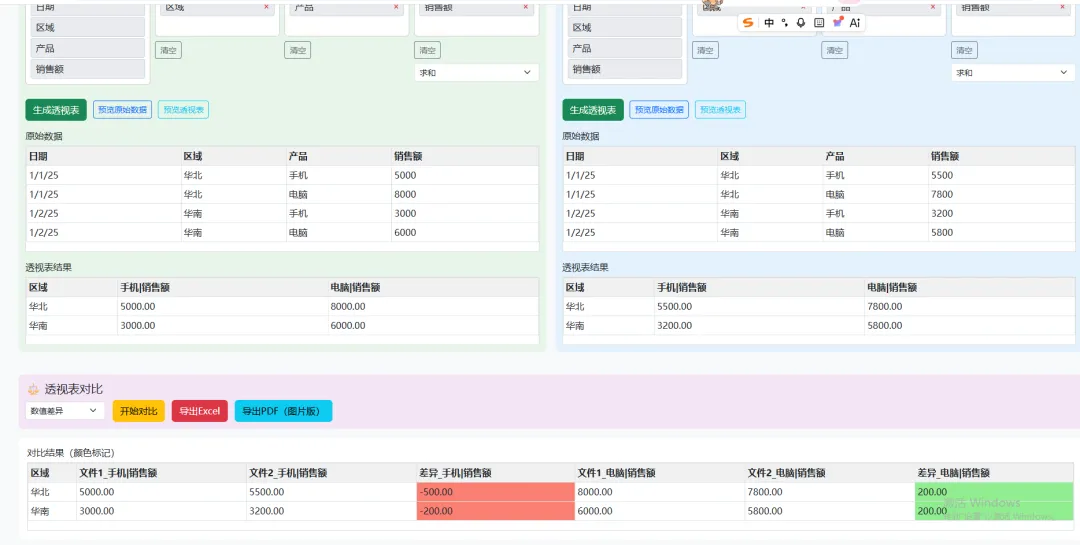
行键匹配(而非按数组索引匹配)的好处是:即使两个文件的行顺序不同,只要行字段值相同就能正确配对。同时,文件2中存在但文件1中不存在的行也会被单独处理,确保不遗漏数据。
3.5 预览系统的折叠/展开机制
原始数据和透视表结果默认隐藏,通过按钮切换显示状态。实现方式非常轻量:
CSS 层面:
.preview-section { display: none; }
.preview-section.show { display: block; }
JS 层面:
functiontogglePreview(id) {
var el = document.getElementById(id);
el.classList.toggle('show');
}
生成透视表后自动展开预览:
var sec = document.getElementById('pivot' + n + 'sec');
if (!sec.classList.contains('show')) sec.classList.add('show');
这种设计避免了页面初始加载时显示大量空表格,保持界面整洁。用户可以按需查看原始数据或透视结果,也可以同时展开两者进行对照。
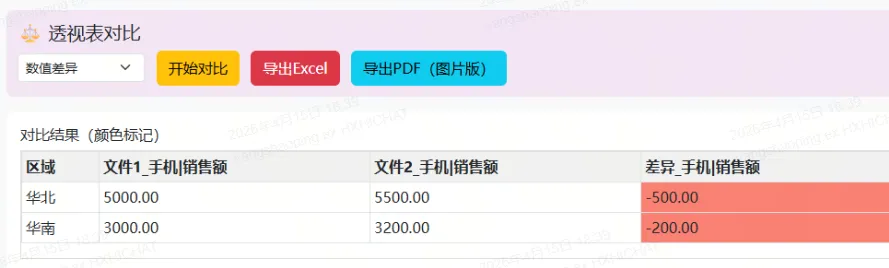
3.6 对比结果的可视化
对比结果使用颜色编码直观展示差异:
if (c.indexOf('差异_') === 0 && typeof v === 'number') {
if (v > 0) td.className = 'diff-positive';
elseif (v < 0) td.className = 'diff-negative';
else td.className = 'diff-zero';
}
颜色判断仅应用于差异列(列名以”差异_”开头),且只对数字类型的值着色,中文文本列不会被错误着色。
对比支持两种模式:
-
数值差异:直接计算 文件1值 - 文件2值 -
百分比差异:计算 (文件1值 - 文件2值) / 文件2值 × 100%
百分比模式下对除零做了保护:bv ? ((av - bv) / bv * 100) : 0。
四、导出功能实现
4.1 Excel 导出
Excel 导出使用 SheetJS 的写入功能,将对比结果转换为 AOA(Array of Arrays)格式后生成工作簿:
var aoa = [headerRow];
compareResult.forEach(function (row) {
aoa.push(headerRow.map(function (h) {
var v = row[h];
returntypeof v === 'number' ? parseFloat(v.toFixed(2)) : (v || '');
}));
});
var newWb = XLSX.utils.book_new();
var ws = XLSX.utils.aoa_to_sheet(aoa);
ws['!cols'] = headerRow.map(function () { return { wch: 18 }; });
XLSX.utils.book_append_sheet(newWb, ws, "对比结果");
XLSX.writeFile(newWb, '对比结果_' + newDate().getTime() + '.xlsx');
几个技术细节值得注意:
-
数字值保留两位小数后再写入,确保精度一致。 -
非数字值(中文汇总文本)以字符串形式写入,不会被强制转为数字。 -
列宽统一设置为 18 个字符宽度,保证中文列名完整显示。 -
文件名使用时间戳后缀,避免重复下载时的命名冲突。 -
XLSX.writeFile内部使用 Blob + URL.createObjectURL 触发下载,兼容所有现代浏览器。
4.2 PDF 导出(图片版)
PDF 导出采用”DOM → Canvas → PNG → PDF”的技术路线:
var canvas = await html2canvas(container, {
scale: 2, // 2倍分辨率,保证清晰度
useCORS: true, // 允许跨域资源
logging: false, // 关闭调试日志
backgroundColor: '#ffffff'// 白色背景
});
html2canvas 将对比结果的 DOM 区域截图为 Canvas,然后转为 PNG 数据 URL。jsPDF 以横向 A4 尺寸创建文档,将图片按比例缩放后嵌入。对于超长表格,通过循环分页处理:
while (heightLeft >= 0) {
position = heightLeft - imgHeight;
doc.addPage();
doc.addImage(imgData, 'PNG', 10, position, imgWidth, imgHeight);
heightLeft -= pageHeight;
}
这种方案的优势是完美保留了表格的颜色标记和样式,劣势是 PDF 中的文字不可选中(因为是图片)。对于需要文字可选的场景,可以考虑使用 jspdf.plugin.autotable(项目中已预留了该库)。
五、测试数据生成
项目内置了测试数据生成功能,点击按钮即可在浏览器中直接生成并下载 Excel 测试文件:
functiongenerateTestFile(n) {
var testData1 = [
["部门", "产品", "区域", "销售额", "数量"],
["技术部", "产品A", "华东", 15000, 120],
// ... 更多数据行
["合计", "", "", 198000, 1611], // 中文汇总行
["汇总说明", "全部产品", "所有区域", "总计", ""] // 中文描述行
];
// ...
}
测试数据的设计经过精心考虑:
-
多维度数据:包含部门、产品、区域三个维度,可以灵活组合行/列字段测试不同的透视配置。 -
中文汇总行:末尾包含”合计”和”汇总说明”行,专门用于验证中文兼容性。 -
两组差异数据:文件1和文件2的数值有差异(如技术部产品A华东区:15000 vs 16500),确保对比时能看到正差异、负差异和零差异。 -
数值合理性:销售额和数量的数值在合理范围内,汇总行的合计值与明细行一致,方便人工验证。
六、离线运行架构
项目的离线运行能力是通过以下策略保证的:
6.1 依赖本地化
所有第三方库都存放在 libs/ 目录下,HTML 中通过相对路径引用:
<linkrel="stylesheet"href="libs/bootstrap.min.css">
<scriptsrc="libs/jquery.min.js"></script>
<scriptsrc="libs/xlsx.full.min.js"></script>
<scriptsrc="libs/html2canvas.min.js"></script>
<scriptsrc="libs/jspdf.umd.min.js"></script>
没有任何 CDN 链接、Google Fonts 引用或外部 API 调用。
6.2 字体策略
CSS 中指定了 "Microsoft YaHei" 作为首选字体:
body { font-family: "Microsoft YaHei", sans-serif; }
微软雅黑是 Windows 系统自带字体,无需额外下载。对于非 Windows 系统,回退到系统默认的 sans-serif 字体。这确保了中文内容在任何环境下都能正常渲染。
6.3 无构建依赖
项目不使用任何构建工具,不需要 npm install、npm run build 等步骤。所有 JavaScript 代码使用 ES5 兼容语法(var 声明、function 关键字、forEach 回调),唯一的例外是 PDF 导出函数使用了 async/await,这在所有现代浏览器中都已原生支持。
七、UI 设计与交互细节
7.1 双面板布局
页面采用 Bootstrap 的 row + col-md-6 实现左右双面板布局。文件1面板使用绿色背景(#e8f5e9),文件2面板使用蓝色背景(#e3f2fd),对比区域使用紫色背景(#f3e5f5)。颜色编码让用户一眼就能区分不同区域的功能。
7.2 表格的粘性表头
数据表格使用 CSS position: sticky 实现表头固定:
.table-boxth {
background: #f1f1f1;
position: sticky;
top: 0;
z-index: 10;
}
当表格内容超出容器高度(最大 400px)时,滚动数据区域而表头保持可见,这对于查看大量数据时的用户体验至关重要。
7.3 拖拽视觉反馈
拖拽过程中提供了多层视觉反馈:
-
字段项使用 cursor: grab光标提示可拖拽,拖动时切换为cursor: grabbing -
从字段区拖入目标区时,目标区背景变为黄色( #fff3cd)提示可放置 -
区内排序时,目标位置显示蓝色边框指示插入点 -
每个已放置的字段右侧有红色 ×按钮,hover 时颜色加深
八、潜在优化方向
8.1 性能优化
当前的透视表算法对于万行级别的数据完全够用,但如果需要处理十万行以上的大数据集,可以考虑:
-
使用 Web Worker 将计算移到后台线程,避免阻塞 UI -
对表格渲染采用虚拟滚动(Virtual Scrolling),只渲染可视区域的行 -
使用 requestAnimationFrame分批渲染大表格
8.2 功能扩展
-
支持多值字段的不同聚合方式(当前所有值字段共用一个聚合函数) -
增加数据筛选/过滤功能 -
支持透视表的行/列小计和总计 -
增加图表可视化(柱状图、折线图对比)
8.3 数据持久化
可以使用 localStorage 保存用户的字段配置(行、列、值的选择和顺序),下次打开同结构的文件时自动恢复配置,减少重复操作。
九、总结
本项目以极简的技术栈实现了一个功能完整的 Excel 透视对比工具。核心技术点包括:基于 HTML5 Drag and Drop API 的双层拖拽排序系统、支持六种聚合方式的透视表引擎、兼容中文汇总数据的智能对比算法、基于行键匹配的跨文件数据配对机制、以及完全离线运行的架构设计。
项目的代码组织清晰,单文件 app.js 约 350 行,涵盖了文件读取、数据处理、UI 交互、导出功能的全部逻辑。没有过度工程化,没有不必要的抽象层,每一行代码都直接服务于业务需求。这种”够用就好”的工程哲学,在工具类项目中往往是最务实的选择。
对于需要在内网环境中快速部署数据对比工具的团队来说,本项目提供了一个开箱即用的解决方案,同时其清晰的代码结构也为后续的定制化开发提供了良好的基础。
通过网盘分享的文件:Excel透视图-弹框.rar
链接: https://pan.baidu.com/s/1_4Ku_vkVg4vL1EE5rhi94g?pwd=zecj 提取码: zecj
通过网盘分享的文件:Excel透视图-预览.rar
链接: https://pan.baidu.com/s/1zzWDLSW6oAJ7ZnRxePuSwg?pwd=6pm2 提取码: 6pm2
通过网盘分享的文件:Excel透视图-弹框.rar
链接: https://pan.baidu.com/s/1_4Ku_vkVg4vL1EE5rhi94g?pwd=zecj 提取码: zecj