 夜雨聆风
夜雨聆风





告别模糊扫描件!用这个小软件 AI 一键高清修复 PDF

旺丁旺财杂货铺
生活/旅行/效率/电器/装修
🎯 Intro 前记
两年前,由于铺主经常到网上图书馆借书,网上图书馆借出的PDF实在太差,只有96dpi上下现在的屏幕上显示效果实在太渣,这就为强迫症的铺主开了新坑,当年就过程中发现的东西写成了这篇【赛博炼丹——AI实现低清晰度渣画质扫描PDF电子档案转高清 Chapter1】。文章下面有位小伙伴留了言。
对啊,一键处理多好,于是这个原有的Todo在铺主心里由生根发芽长成了亭亭如盖 。这两年铺主经历了由寄望能简单整合资源柒就,到放弃幻想借AI手搓。最近终于解决了卡壳多时的问题,又写了这篇PNNY实战:Python驱动的PyTorch to NCNN转换指南。最终获得NCNN模型的铺主,终于把那个一键AI一键高清修复的软件弄出来了!!!之前留言的小伙伴可以去可以狠狠点赞了
。这两年铺主经历了由寄望能简单整合资源柒就,到放弃幻想借AI手搓。最近终于解决了卡壳多时的问题,又写了这篇PNNY实战:Python驱动的PyTorch to NCNN转换指南。最终获得NCNN模型的铺主,终于把那个一键AI一键高清修复的软件弄出来了!!!之前留言的小伙伴可以去可以狠狠点赞了 。
。
🐌 要解决的问题
你是否遇到过这样的尴尬:收到的合同、论文或旧档案是低分辨率的扫描件,文字模糊不清,放大后全是马赛克?今天,我们分享一个基于 Python 的自动化解决方案,结合 PyMuPDF 和 Upscayl AI 引擎,实现从“提取”到“超分放大”再到“智能重组”的全流程自动化,让老旧 PDF 焕然一新!

💡 核心亮点
-
全自动流水线:无需手动提取图像,一键处理整个 PDF 文件。 -
AI 超级分辨率:调用本地 Upscayl 引擎,利用 ESRGAN 模型进行 2倍 无损放大。 -
智能色彩识别:自动区分灰度文档与彩色图片,优化存储体积。 -
标准 A4 重构:无论原图尺寸如何,统一调整为标准 A4 画布,排版更整洁。
🛠️ 技术实现深度解析
1. 精准提取:拆解 PDF 骨架
代码使用 fitz (PyMuPDF) 库深入 PDF内部结构。
# 核心提取逻辑简述pdf_document = fitz.open(pdf_path)for page_num in range(total_pages): image_list = page.get_images(full=True) # ...提取并保存为 image_p{page}_i{index}.jpg-
逻辑:遍历每一页,提取嵌入的图片对象。 -
兼容性强:支持 JPG, PNG 等多种格式,对于非标准格式图片,自动通过 PIL 转换为 JPEG,确保后续处理兼容性。 -
命名规范:根据页码和图片索引生成唯一文件名,防止覆盖。
2. AI 赋能:Upscayl 引擎驱动
这是项目的“心脏”。代码通过 subprocess 调用本地编译好的 upscayl-bin.exe。
-
模型选择:使用 4xNomosWebPhoto_esrgan_225000 模型。 -
异步监控:实时反馈放大进度,让用户知晓处理状态。 -
异常处理:若放大失败,程序会捕获错误并停止后续步骤,避免生成损坏文件。
3. 智能后处理:不仅仅是放大
放大后的图片往往尺寸巨大且杂乱,代码进行了三步精细化处理:
✅ A. 大尺寸压缩
防止显存爆炸或文件过大,将超过 3508px(A4 300DPI 高度)的图片按比例缩小,保持清晰度同时控制体积。
✅ B. 智能灰度检测
这是代码的一个精巧之处!很多扫描件看似黑白,实则包含噪点或轻微色偏。
-
算法:不依赖沉重的 NumPy,而是通过采样像素,计算 RGB 通道的最大差值。 -
容错机制:设置容忍度 tolerance=15.0,忽略微小噪点;只有当彩色像素比例超过阈值时,才判定为彩色。 -
价值:将纯文本页面强制转为灰度模式(L模式),大幅减小最终 PDF 体积。
✅ C. 标准化 A4 画布 (resize_to_a4_canvas)
-
自适应方向:自动识别横版/竖版图片。 -
居中填充:将图片按比例缩放至 A4 尺寸(2480×3508 pts @300DPI),多余部分留白。这解决了不同尺寸图片合并时版面混乱的问题。
4. 完美重生:合并为高清 PDF
最后,使用 PIL 的图片保存功能,将所有处理好的图片流式写入一个新的 PDF 文件。
-
命名规则:原文件名(模型名).pdf,便于追溯。 -
分辨率锁定:强制设定 resolution=300.0,确保打印级清晰度。
📊 效果对比
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
💻 如何使用?
🎮 Python环境
-
环境准备: • 安装 Python 依赖:pip install PyMuPDF Pillow • 下载 Upscayl 并将 upscayl-bin.exe 放在脚本同目录下。 -
运行命令: python AI-PDF_Upscaler.py “你的文件路径.pdf” -
等待完成:程序会自动创建临时文件夹,处理完成后自动清理,并在原目录生成高清 PDF。
🚀 Windows下的懒人包
由于时间关系,铺主已经将一个基于aardio构建GUI的PDF-SuperRes,连同用Nuitka打包好可独立运行CLI、upscayl-bin和可用的4xNomosWebPhoto_esrgan_225000 NCNN模型整合成懒人包。小伙们只要解压后,运行PDF-SuperRes.exe,将要处理的文件拖相应的位置▼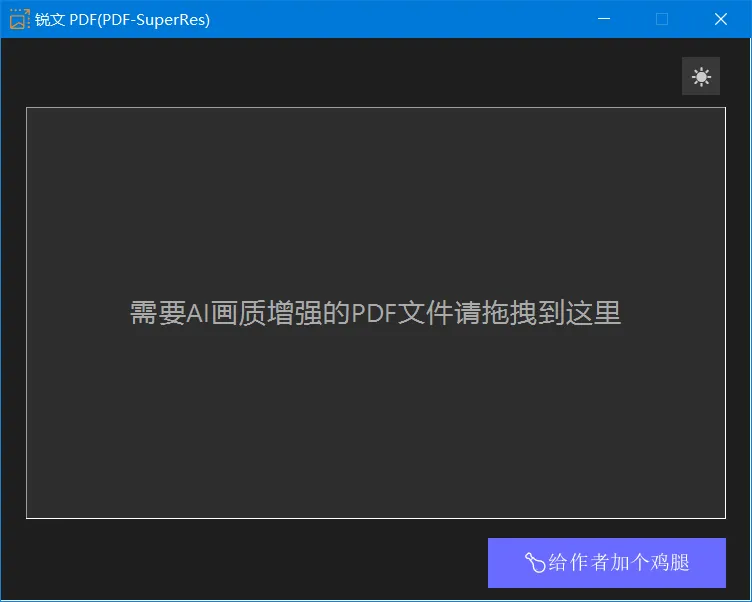 其实,这个懒人包更重要的是给作者加个鸡腿,哈哈
其实,这个懒人包更重要的是给作者加个鸡腿,哈哈
📌 WQ: 后记
终于把这个历时两年的Todo给彻底解决了,这过程是真TM累啊。写到最末,原先还想把PDF压缩流程给弄上去,后来想了一下,这次写的灰度算法已经把自己介绍过神器的PDF reducer的颜色检测也比下去了,开源组件不全又要折腾编码库,所以把图像编码转成JPEG 2000的最后一步就留给各位吧(这样铺主能弄另外一个开源项目,哈哈哈 )。目前,这个项目我已经开源,有需要的在评论区留言索取地址。好了,这次就写这么多,若然觉得这篇文章能帮到你,希望大家点赞和评论留言,这能帮到我不少,感谢感谢!!!!
)。目前,这个项目我已经开源,有需要的在评论区留言索取地址。好了,这次就写这么多,若然觉得这篇文章能帮到你,希望大家点赞和评论留言,这能帮到我不少,感谢感谢!!!!
