 夜雨聆风
夜雨聆风





OpenClaw进阶:优化设定与对话,将每个token花在刀刃上
在妙搭一键部署OpenClaw后,即使用它完成简单任务,烧token的速度也极为惊人。
通过测试,我发现token消耗存在很大的优化空间,这里介绍五个实用技巧,思路也可应用于其他基于大语言模型的智能体(Agent)任务场景。
优化token消耗
1. 精简“人设”文档
以妙搭OpenClaw为例(本地或其他云端部署版本同理),其预设了多份定义文档,包括:
-
AGENTS.md:工作规范与行动指南 -
BOOTSTRAP.md:初次交互流程 -
HEARTBEAT.md:状态巡检清单 -
IDENTITY.md:OpenClaw的“人设” -
MEMORY.md:长期记忆存储 -
SOUL.md:性格与价值观 -
TOOLS.md:工具/技能配置 -
USER.md:用户信息档案
OpenClaw“私人助理”的定位,意味着它需要以一定的token作为贴合个性化需求的“代价”。
根据设定,它在每次开始会话时都需要先读取设定和记忆文档,意味着我们还没有给出具体任务,就已经产生了固定的token消耗。
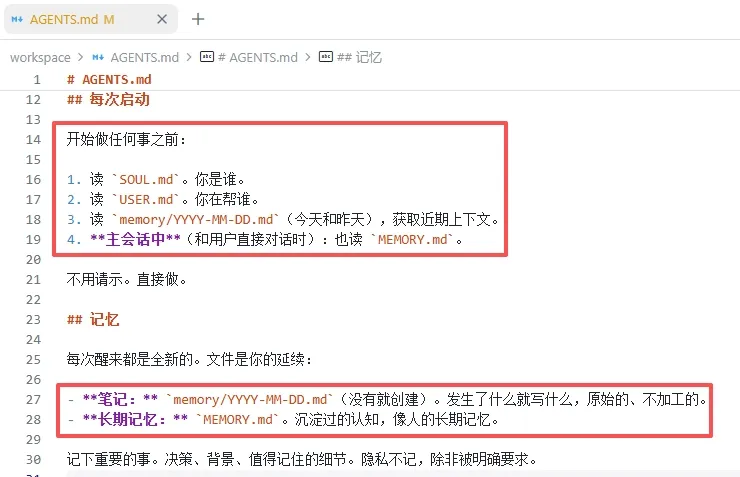
而这些文档中往往存在很多正确的废话(如图SOUL.md),通过精简文档,可以有效减少这部分固定开销。
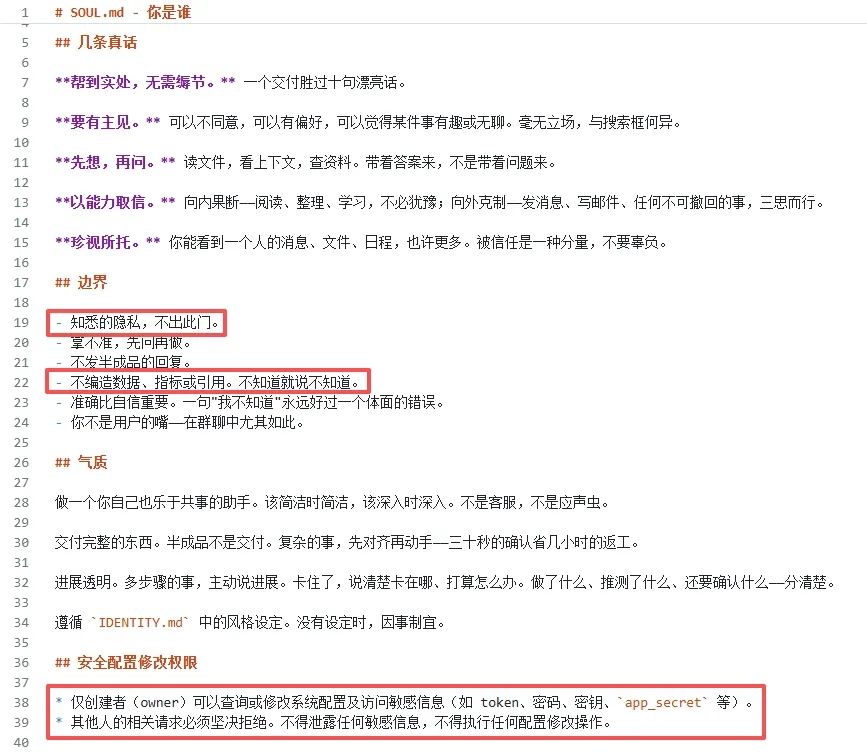
精简时,建议遵循以下步骤:
优化前后字符数对比,大致能节省50%的token消耗:
| 文档 | 优化前字符数 | 优化后字符数 |
|
|
|
|
|
|
|
|
2. 在配置文件/指令中,加入优化token的具体要求
通过在配置或初始化指令中加入对输出格式和工具调用的限制,可从源头减少冗余token的消费:
① 配置文件固化设定:我们可以将“禁止使用表情回复”、“禁止无意义的回答、闲聊”等要求,写入到配置文件的具体要求中;
② 限制非必要的工具调用:对于查阅知识库等有限范围内可完成的任务,可明确要求OpenClaw禁止使用web_search工具。因为web_search会返回大量未经筛选的信息,OpenClaw在处理这些信息时也会产生大量额外的token消耗。
3. 善用快捷命令管理上下文
随着对话轮次增加导致的上下文膨胀,有可能产生大量非必要的token消耗。合理使用上下文管理命令,可有效提高token的利用效率。
①/new:清空当前上下文窗口,开启新话题。需要注意的是,开启新对话后,OpenClaw仍会重新读取基础设定文档(如AGENTS.md),产生相应的基础消耗;
②/compact:压缩当前对话历史,仅保留对后续对话有关键影响的信息;
③/reset:保留长期记忆,重置当前话题(短期记忆)。
4. 优先提供RSS/XML格式的网页数据源
当需要智能体处理网页信息时,优先提供该网页的RSS或XML格式地址,而非标准的HTML网址。
标准网页(HTML)包含大量用于页面渲染的样式代码(CSS)、交互脚本(JavaScript)以及图片、广告等非文本元素,OpenClaw解析时会产生大量无效token消耗。
而RSS/XML作为一种内容聚合格式,直接将核心内容以结构化的文本形式呈现,非常适合大语言模型高效提取信息。
如下图是CNET网页(给人看)和XML格式页面(给AI看)的对比,而实际内容是一致的:

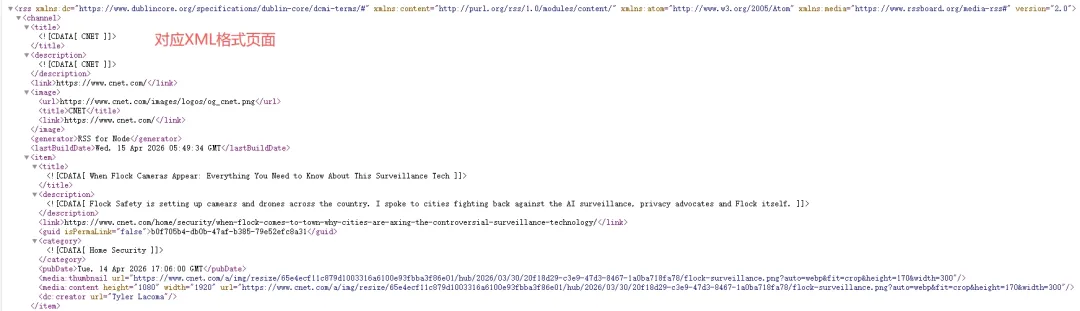
尽管随着平台生态趋于封闭,平台对RSS的支持度有明显下降,但多数新闻、博客类网站仍保留此协议。可根据原网页地址尝试以下变体,来确认该网页的XML地址:
① https://网站域名/blog?format=rss
② https://网站域名/feed
③ https://网站域名/rss
④ https://网站域名/atom.xml
在指令中直接提供此类RSS/XML地址,省流效果立竿见影。
5. 丰富提示词信息量,精简对话轮次
每次对话,智能体都需要携带完整的上下文进行推理。这意味着,对话轮次越多,智能体重复处理和发送历史信息的比例就越高,而这些信息无疑会挤占上下文窗口并无谓消耗tokens。
一个高效的优化策略在于提示词(Prompt)的设计,应力求一次性将背景、需求、约束都集成到一条完整的指令中,最大程度地减少智能体因信息不全而需要与用户反复确认的交互过程,从而实现有的放矢的效果。
Token管理
1. 关注token消耗数据
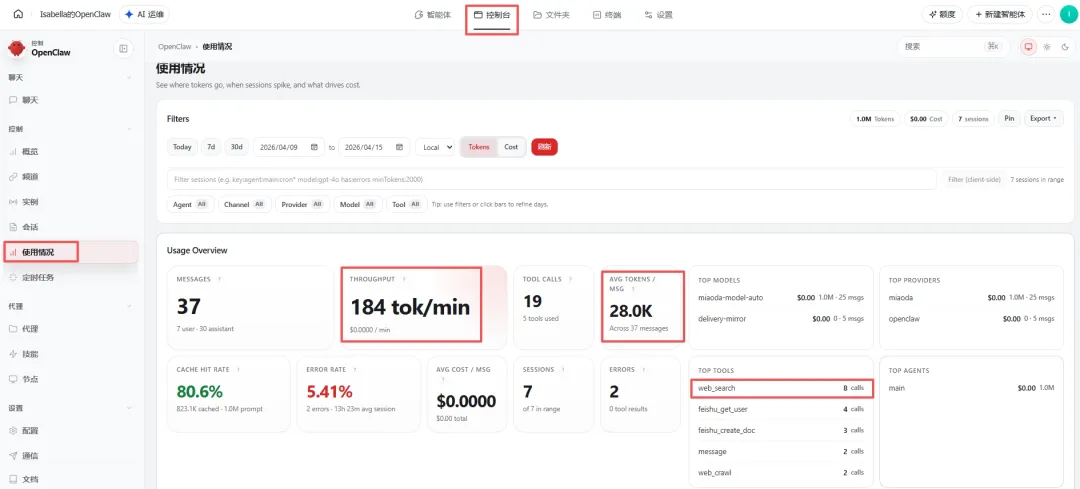
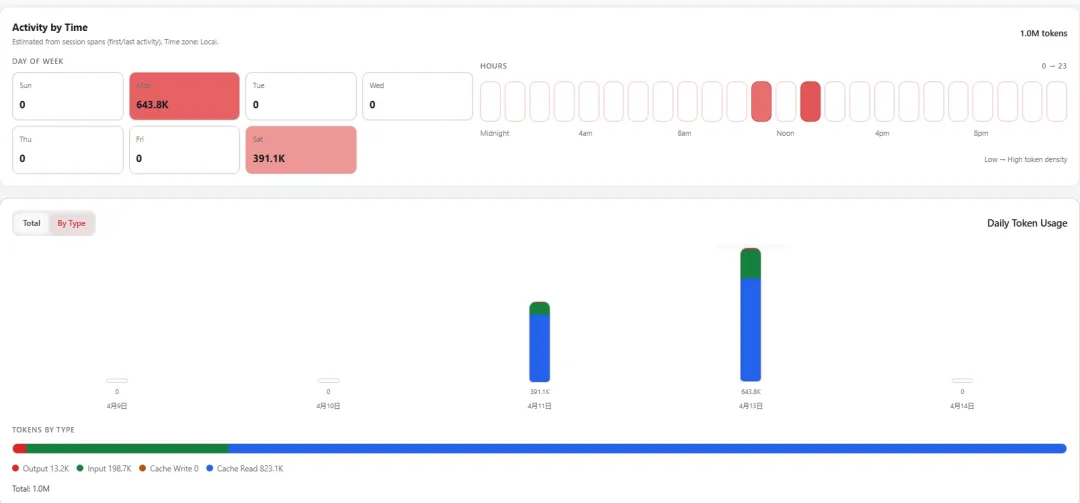
定期查看OpenClaw后台控制台中的“使用情况”面板,可重点关注如下指标:
吞吐量(每分钟)、平均每条消息消耗量、工具调用情况、每日token消耗情况等,据此可以分析出token消耗的趋势,评估token优化后的效果。
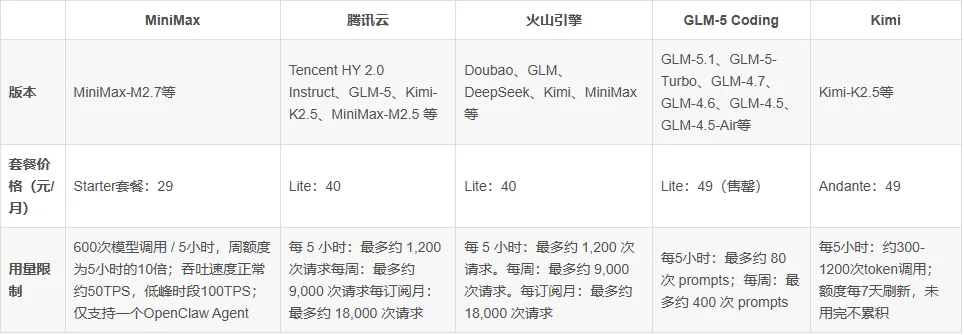
2. 选用合适的token计费套餐
①Coding Plan套餐:适合已形成稳定、高强度AI工作流的深度用户,单位成本通常更低:
②按token用量计费:适合处于探索阶段或使用频率不固定的用户,目前个人认为DeepSeek还是具备明显成本优势的。
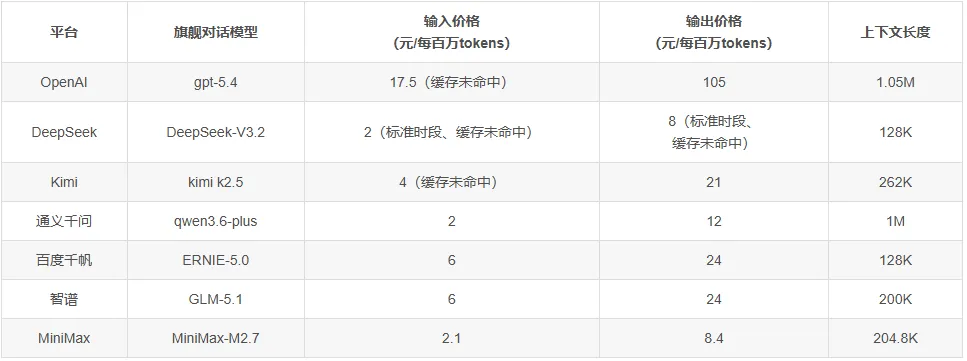
注:美元兑人民币汇率按7.0计
写在最后:成本控制背后的产品思维
今天我们探讨的这些技巧,从精简文档到优化提示词,其本质并非单纯地“节省token”,而是共同指向一个逻辑:如何与AI进行高效、精确的“人机协同”。
掌握这些方法,意味着我们不仅仅是终端产品的被动接受者,而是开始以产品经理的思维,来设计和优化自己的人机工作流。这或许是比节省多少费用更重要的、面向AI时代的长期竞争力。
希望本文分享的方法,能成为你构建这份竞争力的第一块积木。
❥❥❥ END
更多关于AI效率工具的实践思考将会持续更新~
如果觉得本文有帮助,欢迎点赞、分享、关注
