 夜雨聆风
夜雨聆风





文档解析类Skill可以怎么做?TextIn xParse Skill的设计思路解析
我们在之前的文章《力荐RAG、Agent的基建实力选手TextIn xParse:几点思考及亮点实测》中给大家推荐一个比较靠谱的工具——TextIn xParse智能文档解析【LLM与Agent的文档智能基础设施】,地址在:https://cc.co/16YSdX,这是一个老牌文档智能领域公司合合信息的产品,综合使用下来很不错,尤其是在复杂表格解析方面。
伴随着Openclaw的热潮,Skill技能化也逐步成为企业Agent应用的重要形式,因此,TextIn xParse Skill也顺势上架ClawHub(https://clawhub.ai/intsig-textin/xparse-parser):
进一步提供免费使用的skill,延续之前的商业稳定性、可用性及效果优势,帮助企业更快速地把文档接入Agent。作为文档解析方向的一个Skill,我们可以借着几个问题,来看看它的一些细节,会有收获。
一、TextIn xParse Skill是怎么设计的?
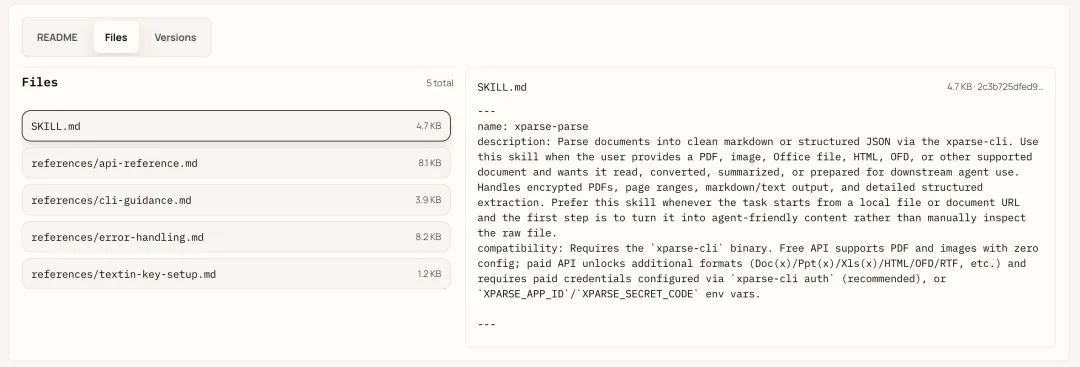
整体Skill由5个markdown文件构成,是个标准的写法,规定了API接口、命令行使用、错误处理、密钥安装等细节,比较完整。
其中:
SKILL.md,xparse-parse智能技能的核心使用规范,定义了该工具的适用场景、调用优先级、安装启动、基础命令、执行流程和终止规则,是Agent调用xparse-cli解析文档的总纲领;
references/api-reference.md,TextInParseAPIv1的完整接口参考,详细定义了xparse-cli的命令参数、JSON/Markdown响应结构、返回字段、全量错误码及对应处理方式,是工具解析文档的底层接口规范说明;
references/cli-guidance.md,xparse-cli使用手册,清晰说明付费API配置方式、免费与付费版的功能限制、各类解析命令用法、输出格式选择,同时关联错误处理文档完成全流程使用指引;
references/error-handling.md,针对TextInAPI各类错误码制定的Agent决策指南,核心是按错误类别精准判定重试一次、停止提示或调整配置的处理策略,明确不同错误的用户提示话术、重试禁忌与恢复流程,并配套诊断逻辑与配置指引。
references/textin-key-setup.md,TextInAPI密钥配置指南 ,说明在免费额度用尽、文件超10MB等场景下,通过交互式命令或环境变量配置APP_ID与SECRET_CODE,解除文件大小与配额限制,并给出验证方法、凭证优先级及排错指引。
二、TextIn xParse Skill是用来干啥的?
重点来看其功能,从xparse-parser/SKILL.md这个文件中,可以看到其功能说明:
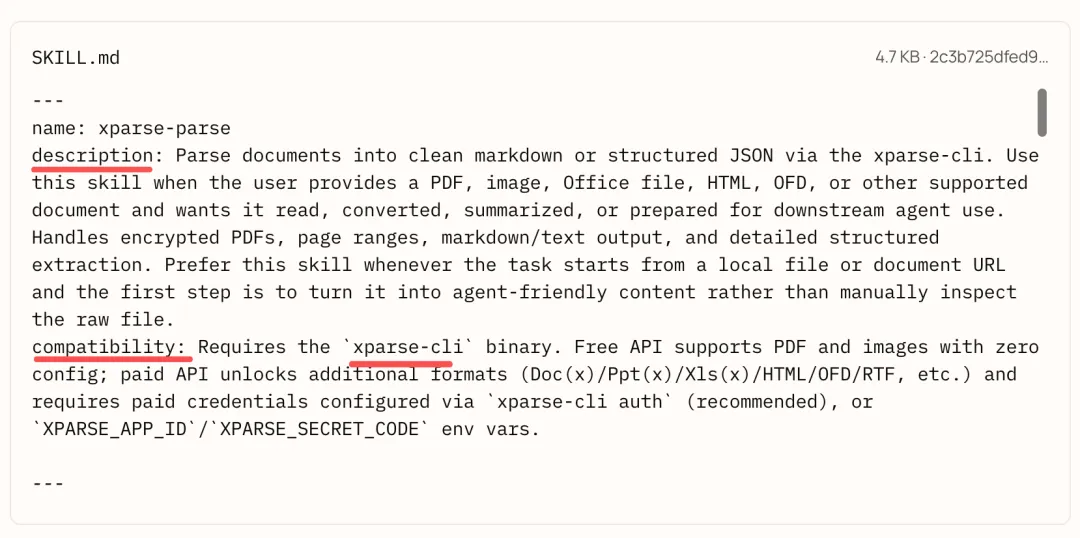
xparse-parse,基于xparse-cli的文档解析技能,用于把PDF、图片、Office、HTML、OFD等文件转成干净Markdown或结构化JSON,供智能体读取、转换、摘要使用。
从场景上看,xparse-cli可以直接命令行调用完成输出Markdown/JSON至控制台、保存为Markdown/JSON文件、指定解析页码范围、解析加密文档、输出字符级详情(包围盒、置信度、候选字符)的那个场景。
一般场景:

高级场景:


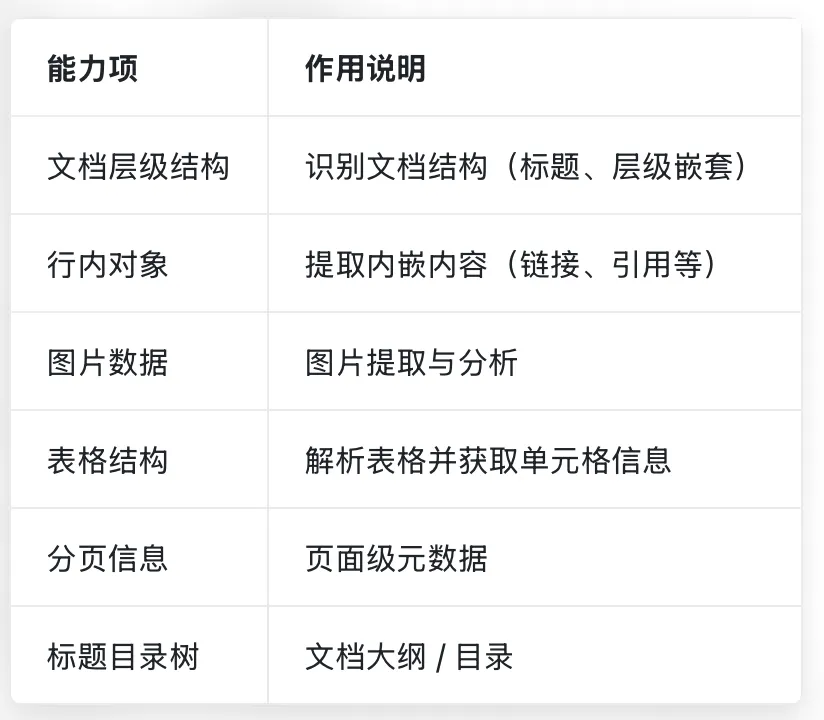
为了实现以上场景功能,会自动启用功能,包括文档层级结构、行内对象、图片数据、表格结构、分页信息、标题树等。
其中,它分成两个版本:

免费版零配置,仅支持PDF+图片,付费版解锁全格式,需配置密钥,优先级上处理本地文档优先用它,失败后再换OCR/Python库等工具。
那么,又是如何执行的?可以看下默认执行流程:
step1. 确认文档适合使用xparse-parse解析
step2. 执行xparse-cliparse<文件路径>
step3. 读取Markdown格式解析结果;
step4. 仅当任务需要更结构化的数据时,再切换为JSON格式;
step5. 若缺少必要输入,暂停并询问用户;
step6. 若xparse-parse明显无法完成任务,说明原因后再切换工具
二、如何安装TextIn xParse Skill?
安装方式很简单,有两种方式,指引如下:
方式一:通过各类Agent或Claw安装在Agent对话框安装
直接输入:
帮我从技能市场安装 intsig-textin/xparse-parser
如果技能市场里没有,则通过npx安装:npx skills add intsig-textin/xparse-skills –yes
如果npx也没有,则可以从以下仓库里任选一个手动安装:https://github.com/intsig-textin/xparse-skills;https://gitee.com/intsig-textin/xparse-skills
方式二:手动安装
从以下任一地址下载 zip 文件,解压后,放到 agent 对话框,让模型使用解压里面的 skill.md 文件即可:
GitHub:https://github.com/intsig-textin/xparse-skills
Gitee:https://gitee.com/intsig-textin/xparse-skills
ClawHub:https://clawhub.ai/intsig-textin/xparse-parser
三、TextIn xParse的其他问题?
TextIn xParse其实在使用过程中还是会有一些疑惑,所以,也特意向官方咨询,找到了一些回复:
Q1:TextIn是一款什么工具,为什么之前不太知道?
A:TextIn是合合信息智能文本处理企业级AI产品线。合合信息面向C端的热门产品如扫描全能王、名片全能王等相信很多人都有在使用。
Q2:为什么要现在用这个Skill?
A:每天1000页的免费额度,不用登陆,不用API KEY,用户可免费体验商业级精度产品。
Q3:付费疑虑?
A:1000页/天是实打实免费,个人开发者一般用不完;如果并发数多想要解析得更快一点,可以选择付费凭证,但也是丰俭由人,Skill里面写了怎么设置账号信息和调用免费接口或付费接口;如果是企业,每天1000页也足够用来做一些测试和POC。
Q4:数据安全问题,处理的过程是需要把文档上传给api的,是不是会有风险?
A:不会的。合合信息作为上市公司,深耕金融级文档智能处理领域,始终将数据安全与合规经营作为业务底线,拿客户的样本来做数据集和测试机优化模型本来就是不合规的,合合信息作为上市公司,核心业务包含金融级文档处理,合规是生命线。
One More thing
针对这次skill,也有对应的线上公开课,时间在2026年4月27号(下周一),感兴趣的可以关注👇的直播海报。
