 夜雨聆风
夜雨聆风





从"会说话"到"能干活":AI Agent 落地生产需要什么?

(好久没发咪子……)
在真正干 Agent 之前,我有过一种错觉:接上模型 API,写几个工具函数让 Agent 自动调用串联,ReAct 一套,loop 一上,Demo 跑通了就觉得大功告成。
这个错觉在真正落地之前几乎人人都有过。
从受控的演示环境到真实的生产系统,中间横着的不是模型能力的问题,而是一系列工程化问题。
现在发展下,各种组件其实也已经在稳定发展,好用的框架、组件层出不穷;
在 harness 的思想下,A 社出了 managed-agent, openai 的 sdk 也在发展,前不久也发布了新版本集成了沙箱,虽然现在最好用的 agent 还得说是 claude code,但是我们要搭出可商用的 agent,应该怎么做呢?
我根据自己的理解 也做了一个图

(gpt-image2模型生成 确实强)
这是我认为的 agent 工程化所需要的组件和架构,最近也一直在工作中使用一些开源框架进行二开,未来也会随着 ai 发展逐渐调整;
而本篇文章所写的,是 AI Agent 平台落地过程中最常见、也最容易被低估的 5 道坎。
第一道坎:模型输出不稳定,比”模型不够聪明”更难搞
很多团队在早期把精力都放在调提示词、换更强的模型上,却忽略了一个更基础的问题:同样的输入,不同时间的输出可能长得完全不一样。

同一段提示词,今天返回标准 JSON,明天在 JSON 前面多了一句解释性文字,导致下游解析逻辑直接崩掉。这种问题在测试环境几乎不会复现,偏偏在流量高、并发多、触发限速重试的时候集中爆发。
根本原因:LLM 是概率模型,不是确定性函数。相同输入在不同温度、不同系统负载下输出存在漂移,这是模型本身的特性,无法通过调提示词彻底消除。
工程解法:在每个 LLM 调用出口加”输出校验层”——
-
• 校验结构是否符合预期格式 -
• 不符合则自动重试,最多 3 次 -
• 超过重试次数降级为简化版输出,而非直接报错让任务失败
这一层改造上线后,因模型输出格式问题导致的任务失败率可以从两位数降至个位数。
关键认知:模型的不确定性是前提条件,而不是需要消灭的 Bug。工程代码的职责是为这种不确定性托底。
第二道坎:工具越多,调用链路越脆
一个成熟的 Agent 平台往往会积累大量可调用工具:内部 API、数据库查询、搜索引擎、命令行接口,再加上技能市场(Skill Marketplace)里动态注册的几十个业务技能。
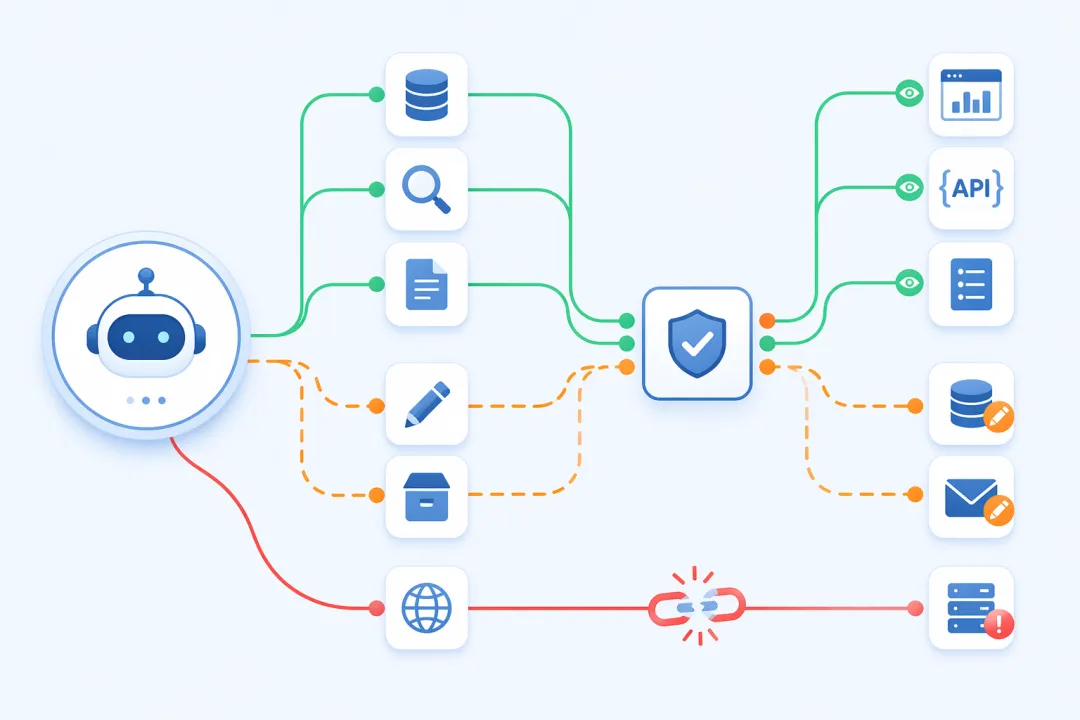
理想状态是 Agent 根据任务自动选工具、串联调用、完成复杂任务。
现实状态是:工具一多,选错工具、传错参数、循环调用、中途失败不知道如何恢复——这些问题会集中出现。
根本原因:工具描述模糊、权限边界不清晰,Agent 在选工具时实质上是在”猜”,而不是在”匹配”。
工程解法:对工具做分级管理——
轻工具(查询类、只读类):Agent 可自由调用,失败自动重试,不需要人工介入。
重工具(写入类、执行类):Agent 提出调用意图后,经由规则引擎审批或人工确认,通过后才真正执行。
同时,技能市场里的每个技能需要做结构化描述:明确输入格式、输出格式、适用场景、限制条件。Agent 选工具时基于结构化描述匹配,而非依赖模型对工具名称的”理解”。
关键认知:工具数量不是 Agent 能力的衡量标准。清晰的工具边界 + 合理的调用权限,比堆砌工具数量更重要。
第三道坎:Agent “失忆”,是最难复现的生产 Bug
支持多轮对话的 Agent,以及需要跨越较长时间才能完成的复杂任务,都依赖一件事:Agent 能记住之前发生了什么。
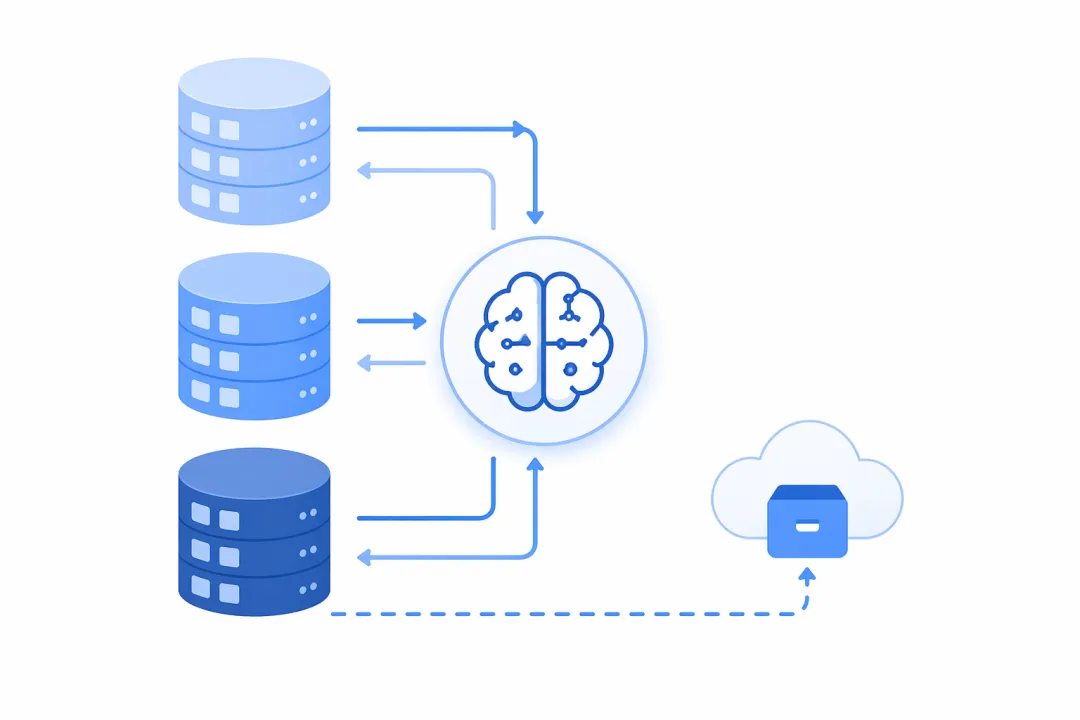
早期架构里,对话历史和任务状态往往只存在内存中。服务一重启,状态全无。用户看到的是:昨天谈好的需求,今天 Agent 完全不记得。
更危险的问题是状态隔离失效:多个用户的会话状态混存,偶发出现 A 用户的上下文被带入 B 用户对话的情况。这类问题极难复现,出现时用户体验直接崩塌,且排查成本极高。
根本原因:把”记忆”寄托在内存或上下文窗口上,本质上是把工程问题交给了不可靠的载体。
工程解法:引入外置记忆系统(如 Memos),将状态存储从进程内存移至持久化存储,并分三层管理——
-
• 短期记忆:当前对话上下文,存于会话 Session -
• 工作记忆:任务执行进度和中间结果,存于任务状态表 -
• 长期记忆:用户偏好、历史交互摘要,持久化存储,按需检索注入上下文
状态外置后,服务重启不丢失,多租户状态天然隔离。
关键认知:记忆管理是工程问题,不是模型问题。把状态交给可靠的存储,而非依赖上下文窗口。
第四道坎:多租户”互相打架”,比单个 Bug 更难定位
Agent 平台服务多个业务线时,本质上是一个多租户系统。共用工具池、共用模型调用配额、共用 Prompt 模板仓库——任何一处共享,都是潜在的故障传导路径。
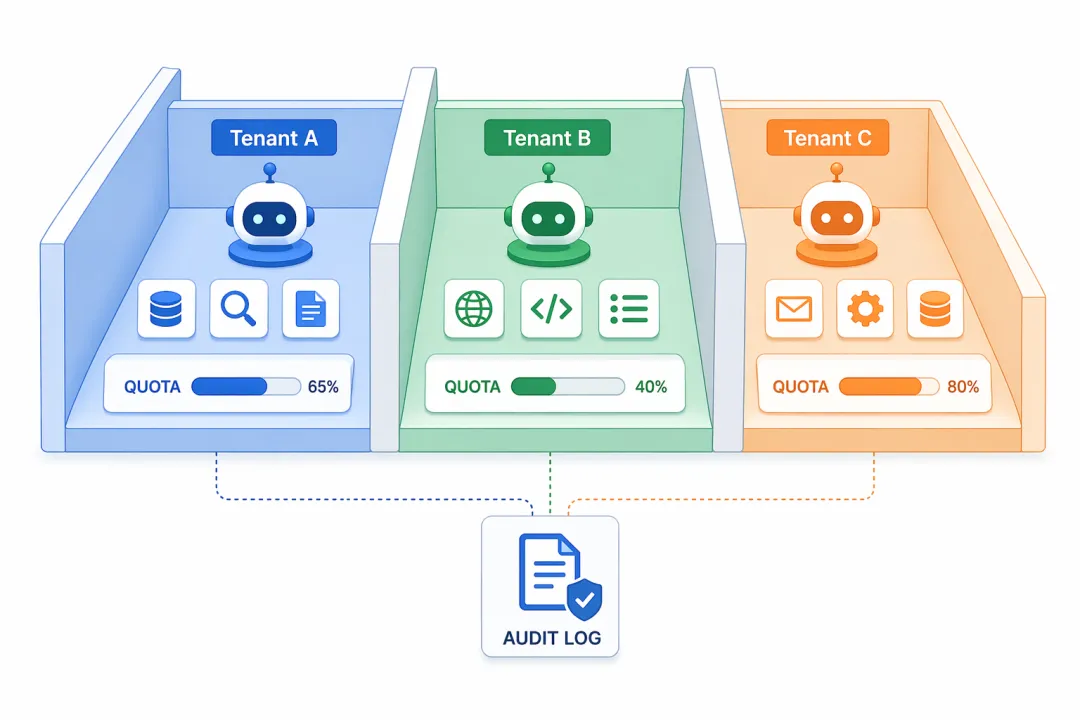
典型场景:某个租户的高并发任务打满了模型 API 速率限制,导致其他租户的任务全部超时报错,彼此之间毫无关联,却互相影响。更隐蔽的情况是某个租户修改了公共 Prompt 模板,悄悄降低了其他租户的输出质量,排查数天才找到根因。
根本原因:共享资源在高负载或配置变更时,故障会以非预期的方式在租户间传导。
工程解法:做两层隔离——
资源隔离:每个租户有独立的模型调用配额和工具调用频率限制,互不影响。
配置隔离:Prompt 模板、工具权限、技能市场的可见范围,全部按租户维度管理,不同租户看到的工具集是独立的子集。
在此基础上,通过命令行接口层(OpenCLI)做租户级操作审计——每次工具调用携带租户 ID 和操作者身份,出现问题时可以精确追溯到是谁、在什么时间、做了什么操作。
关键认知:多租户隔离不只是数据隔离,而是资源、配置、审计的全面隔离。缺少任何一层,都会在某个时间点集中爆发。
第五道坎:Agent 越自主,越需要”刹车机制”
随着 Agent 能力增强,可调用的工具越来越多,执行的任务越来越复杂,一个新的风险开始浮现:Agent 在没有明确边界约束的情况下,会做出超出预期的操作。
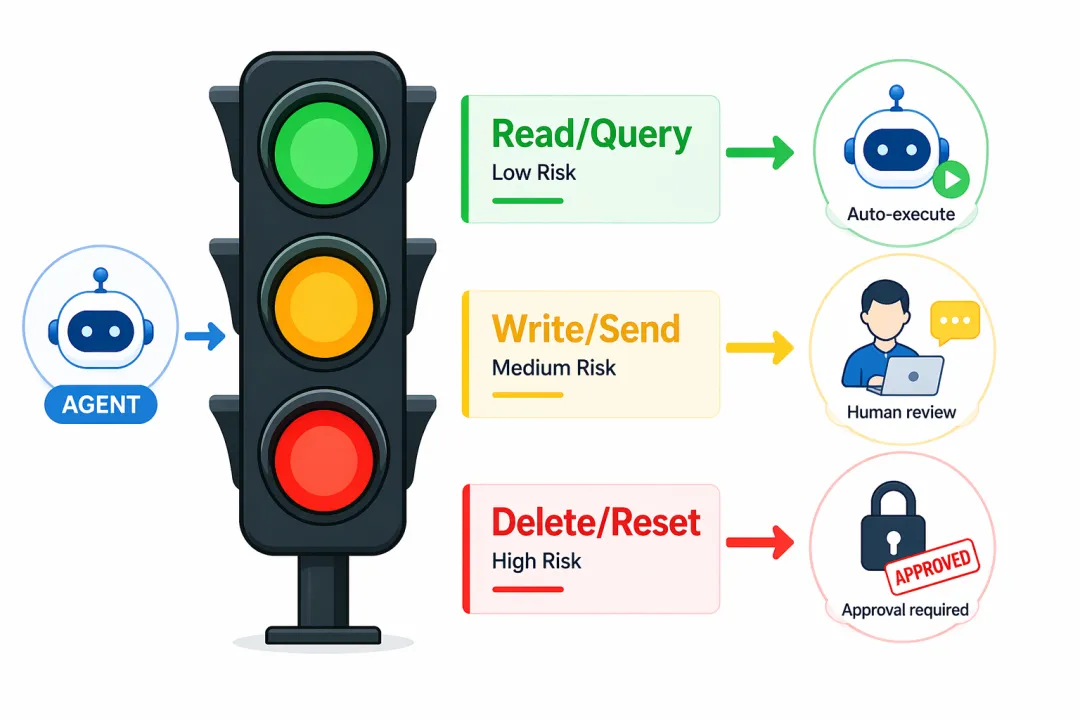
典型案例:Agent 执行”清理过期数据”任务时,因 Prompt 中对”过期”的定义不够严格,将范围理解得过于宽泛,差点误删不该删除的数据。此类问题的根源不在于模型理解错误,而在于执行边界由 Prompt 定义,而 Prompt 无法提供真正可靠的约束。
根本原因:Agent 的行为边界不应该由 Prompt 来保证,而应该由架构来保证。
工程解法:按操作风险等级建立三档执行机制——
-
• 绿色操作(读取、查询、生成):自动执行,记录日志 -
• 黄色操作(写入、修改、发送):执行前展示操作摘要,等待确认 -
• 红色操作(删除、清空、权限变更):强制人工审批,审批记录永久留存
在此之上,沙箱执行环境是下一阶段的演进方向:将代码执行和文件操作限定在隔离容器内,从基础设施层面切断误操作的可能。
关键认知:给 Agent 装刹车,不是不信任 AI,而是在信任尚未建立时的必要工程保障。自主能力越强,约束机制越要清晰。
结语
从 Demo 到生产,核心变化不是模型版本更新了,也不是框架功能更丰富了,而是开发者开始认真面对那些”不该发生但一定会发生”的工程问题。
模型输出会漂移,工具调用会断链,状态会丢失,租户会互相干扰,Agent 会做出边界之外的操作——这些不是极端情况,而是生产环境的日常。
Agent 工程化的本质,是把这些”万一”提前设计进系统,而不是等到它们在生产环境爆发后再补救。