 夜雨聆风
夜雨聆风





谷歌 AI 智能体平台暂居领先,但仍有大量工作待完成
企业正快速从 “能回答问题、生成内容的AI”,转向能执行任务、采取行动的 AI。谷歌云 CEO 托马斯・库里安表示,这一转变需要一套完全不同的基础设施与软件架构。谷歌认为,只有从芯片到应用全程紧密集成的技术体系,才能有效支撑这场转型。

这场转型的核心是数据与 AI 平台——我们称之为 “智能体系”,谷歌最初以知识目录(Knowledge Catalog) 的形式对外呈现。这一能力最终会将分析型应用与运营型应用抽象化、统一化。在此之上,正在形成一套智能体体系(谷歌称之为 “行动体系”),由知识目录与智能体平台共同构成。
我们认为,可量化的商业价值将建立在这套基础设施之上,这也是未来真正的竞争焦点。包括谷歌在内的头部大模型厂商,正快速构建将成为软件行业未来基石的能力 —— 我们预测,这将是软件行业史上最大规模的变革。
开篇:TPU 8、数据底座,以及从对话到行动的跃迁
本周谷歌重磅发布TPU 8(8t / 8i),作为其芯片路线图的关键一步,也向外界传递明确信号:谷歌是唯一同时拥有前沿大模型、差异化数据栈、可规模化落地智能体的超大规模云厂商。谷歌特意强调,张量处理单元(TPU)不是专用集成电路(ASIC),而是更通用的芯片。
无论如何定义,TPU 都是为高效运行现代 AI 而设计的专用芯片,是谷歌论证 “性价比与性能至关重要” 的核心。值得注意的是,尽管谷歌宣称了多项性能倍数提升,但几乎未提及每瓦性能—— 这对能源受限的运营方而言是最关键指标。
TPU 是谷歌战略的核心,但我们认为,英伟达仍将是谷歌(及其他云厂商)的关键合作伙伴。TPU 并非直接与英伟达竞争,而是通过软硬深度整合为谷歌带来差异化优势,同时让谷歌更好地平衡加速器供需。对开发者而言,英伟达 CUDA 生态依然是必不可少的选择。
更重要的是,谷歌在数据平台层已深耕多年。不只是 BigQuery,还包括上层元数据层,以及与 Spanner 运营数据库的整合。我们认为,谷歌是唯一能在数据平台领域真正与Snowflake、Databricks 抗衡的云厂商,而这一切积累,正是如今智能体平台的基础。
过去几十年,行业一直处于数据孤岛、应用孤岛状态。能感知、推理、决策、执行、学习的商业智能体,如果被隔离在孤岛中,无法释放真正价值 —— 只能实现单点自动化,却无法改变业务运行方式。
这正是库里安本周提出的核心前提:行业已超越基于检索增强生成(RAG)的对话机器人,进入智能体与智能体团队代表人类执行行动的时代。这一转变对基础设施提出全新要求:必须全面整合。
谷歌的定位是:自己是唯一提供全栈能力的云厂商,将芯片、基础设施、数据、模型、应用与服务整合为一套连贯系统,支撑智能体工作负载。与此同时,多数头部大模型厂商并不拥有云平台,这为谷歌将模型能力转化为企业级部署提供了结构性优势。
核心结论:TPU 8 是头条新闻,但更重要的是,谷歌正试图将芯片、数据平台与前沿模型整合为一套一体化智能体平台叙事。
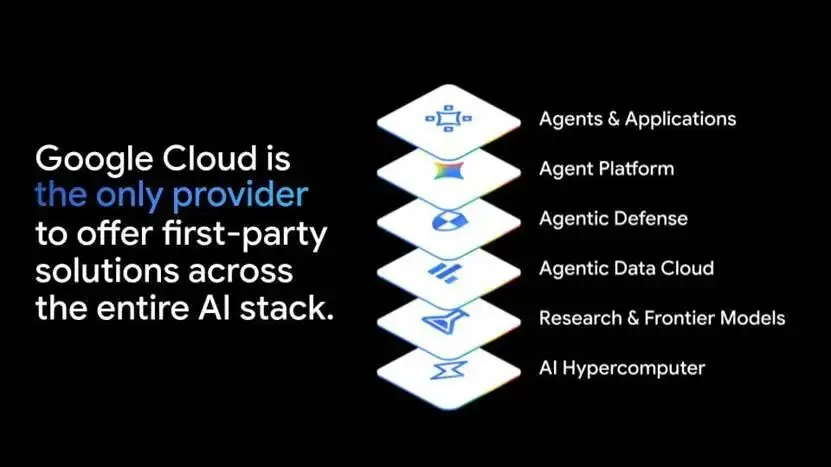
服务即软件:智能体如何倒逼企业全面重构架构
我们的研究核心观点是:整个软件行业模式正在变革,从软件即服务(SaaS) 转向服务即软件(Service-as-Software)。
从本地部署转向 SaaS 时,技术模式、商业模式、运营模式全部改变;而服务即软件将改变整个企业。通过将智能嵌入工作流,任何企业都能用更少人力实现规模化,并通过软件交付业务结果。长期来看,这将推动更多企业走向平台经济,而平台市场往往走向赢者通吃。
智能体是催化剂。只有跨孤岛运行,智能体才能创造端到端业务价值,而非仅自动化孤立任务。这就是 “智能体系(SoI)” 的意义 —— 它将智能体与企业的运营与分析现状连接,让智能体在全业务范围感知、推理、决策、行动与学习,而非局限在单一部门。
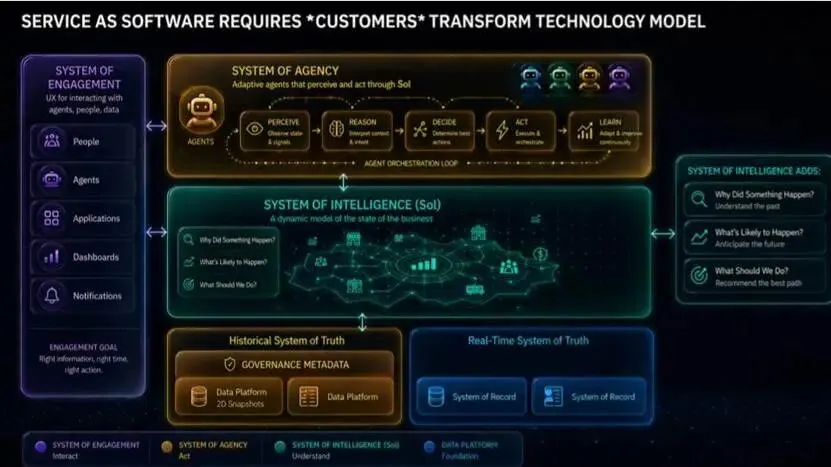
过去 60 年,企业建立的孤岛架构(数据、应用、组织),无法满足需要跨部门上下文与权限的智能体。而智能体可以用自然语言重新设计整个流程,而非简单自动化现有流程。
SaaS 改变了软件厂商与 IT 部门;服务即软件改变整个企业。智能体只有跨孤岛运行才能创造价值。智能体系成为企业的智能层,位于记录系统与部门数据 / 应用栈之上。
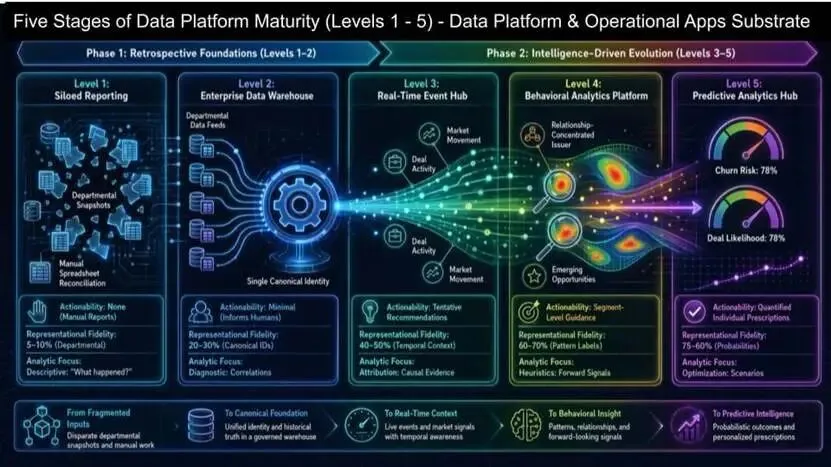
数据平台成熟度五阶段:通往数字孪生之路
从部门级报表到企业数字孪生(实时数字化映射),分为五个成熟度阶段:
- Level 1:孤岛式报表
部门级手动报表,几乎无自助分析能力。
- Level 2:企业数据仓库
标准化指标与维度,提升自助分析,但仍以部门为单位。
- Level 3:实时事件中心
实时事件流入数据平台,开始业务建模,上下文可计算。
- Level 4:行为分析平台
richer 行为模式与前瞻性信号。
- Level 5:预测分析中心
概率化结果与个性化指令,走向优化与预测。
最终目标是企业数字孪生—— 实时映射人员、场所、物品、流程,是搭建智能体系、让智能体执行复杂任务的前提。
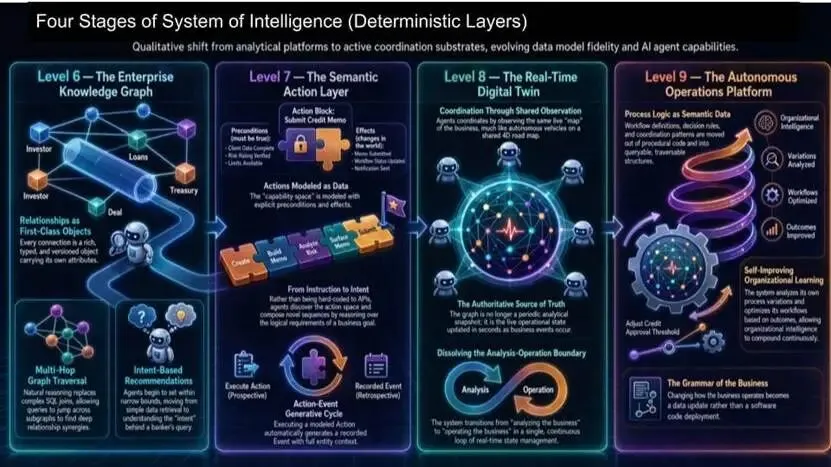
连接非确定性与确定性:智能体落地的关键一步
生成式层提供创造力(词汇、语言、合成、探索),但企业行动需要确定性:规则、护栏、可审计的轨迹。我们认为,这是上层非确定性智能与下层确定性执行之间的核心桥梁,必须紧密结合才能保证结果可信。
简单理解:目标 + 护栏。
智能体系的四个确定性阶段:
- Level 6:企业知识图谱
企业 4D 关系地图,让智能体遍历业务对象而非表格。
- Level 7:语义行动层
将行动建模,定义约束条件与执行规则。
- Level 8:实时数字孪生
模型成为唯一真相源,替代传统系统。
- Level 9:自主运营平台
工作流逻辑以数据形式存储,系统可自我学习、优化。
结论:智能体在孤岛中无法大幅提升价值;只有在企业状态下导航、按规则行动、留下审计轨迹,才能实现价值复利。这是生成式输出与受控执行之间的桥梁。
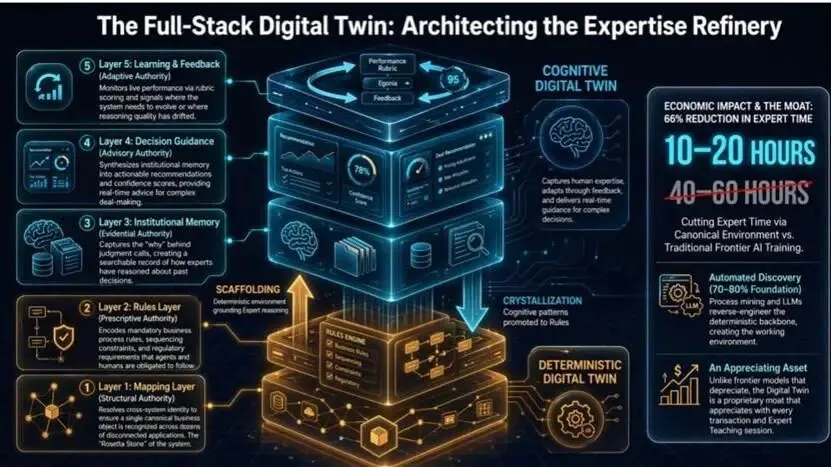
全栈数字孪生:将规则转化为专业能力
确定性孪生(规则 + 映射)保证智能体安全;认知孪生捕获决策背后的原因,让智能体规模化可用。两者紧密整合,例外情况成为训练数据,专家经验转化为企业资产。
专家通过 “教学 — 评分” 循环,将思考过程、推理逻辑、错误推理模式传递给系统,这是捕获专家判断的唯一可靠方式。系统通过奖惩机制持续优化,形成飞轮效应。
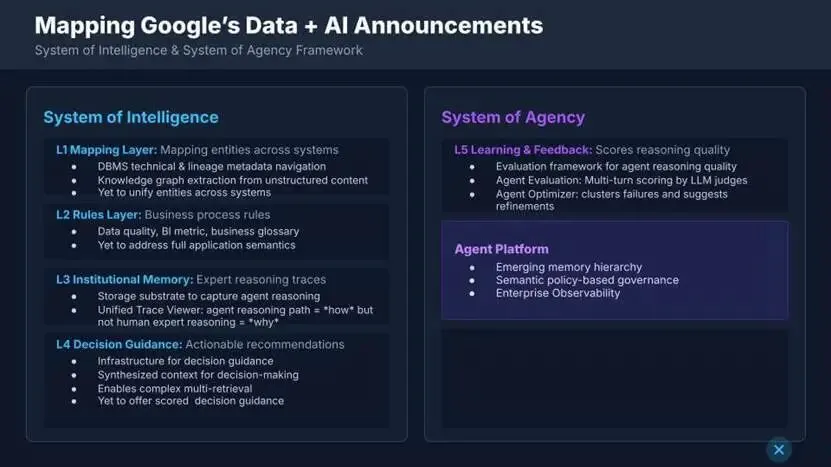
谷歌数据 + AI 布局映射:智能体系vs 行动体系
谷歌的术语与我们略有不同:谷歌将现代数据栈称为 “智能体系”,将智能体层称为 “行动体系”;我们认为,智能体系是让行动安全、可重复的统一层,最终支撑行动体系。
谷歌已具备的能力
-
映射层:提取元数据与血缘,从非结构化内容构建知识图谱。 -
规则层:捕获数据质量、BI 指标、业务词汇表。 -
机构记忆层:存储并展示智能体推理路径。 -
决策引导层:合成上下文,支持复杂多轮检索。 -
行动体系:多轮智能体评估、失败聚类优化。
谷歌仍存在的差距
-
未实现跨系统实体统一。 -
未覆盖完整应用语义 / 业务流程规则。 -
未捕获人类专家推理的 “为什么”。 -
未提供带置信度评分的决策建议。
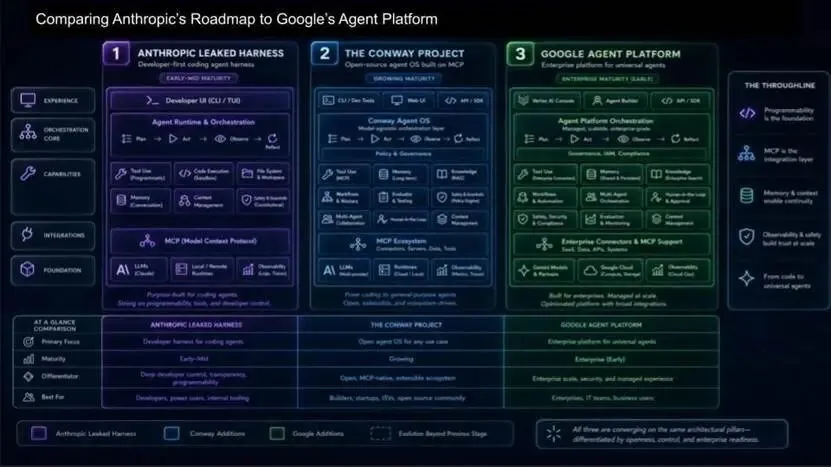
编码智能体:通用智能体的入口
市场正形成共识:构建通用知识工作智能体,必须从编码智能体开始。因为智能体通过工具与世界交互,而使用工具越来越意味着编写代码。
Anthropic、OpenAI、Grok 均聚焦编码能力;谷歌则另辟蹊径,构建企业级智能体平台,将管控框架扩展到更广泛场景。
谷歌平台的三大差异化:
-
治理与智能体身份:从资源控制转向意图控制,运行时策略强制执行。 -
非孤岛式记忆:记忆可共享、可治理、可统一,避免新一代锁定。 -
数据与行动空间统一:形成语义统一的知识图谱,通往企业数字孪生。
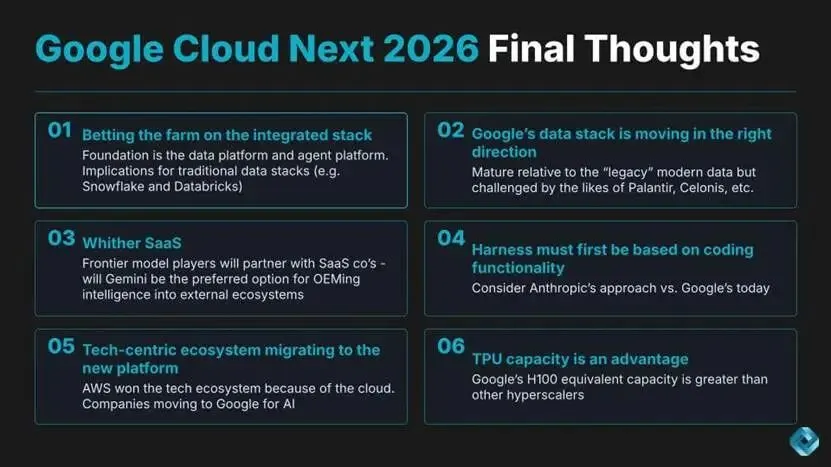
谷歌云 Next 2026 最终结论
-
全栈整合是谷歌的核心优势与约束TPU、大模型、数据平台、智能体平台、应用一体化。
-
数据栈方向正确相对传统现代数据栈更成熟,但面临 Palantir、Celonis 等挑战。
- SaaS 未来取决于 OEM 机制与信任边界
Gemini 在谷歌生态内有优势,但跨云使用存在摩擦。
-
必须以编码功能为基础编码是智能体可信度的入场券,需深度嵌入平台。技术生态向新平台迁移AI原生团队正转向谷歌,类似当年AWS赢得云生态。TPU 算力是战略优势,谷歌H100等效算力超过其他云厂商,支撑产品快速迭代。
最终总结
谷歌在智能体平台领域暂居领先,因为它能提供全栈能力,且数据平台积累深厚。但最艰难的工作仍未完成:
-
从 “读取上下文” 到 “执行行动”企业级规模的统一化层 -
解决 OEM / 边界问题,让 Gemini 在数据所在地运行
谷歌的 TPU 优势不在于替代英伟达,而在于支撑自身全栈更快迭代,尤其是在软件层,实现智能体全面普及。
TPU 8 与 “充裕 GPU 算力” 优势
本文首尾围绕同一个核心话题:TPU。最后一点观点,彻底扭转了本周整体行业论调 —— 谷歌自研 TPU 算力储备,使其在 AI 算力领域具备结构性长期优势,并将直接体现在产品迭代速度上。
下方 Epoch AI 发布的「等效H100 总算力」图表显示:依托大规模 TPU 集群,谷歌的AI 总算力已超越所有其他云厂商。相较于英伟达主导的生态路线,谷歌走的是规模化硬算力路线,但这一模式让其能够自主掌控芯片供货与算力部署节奏,不再受制于人。
这一现象,与播客节目《Latent Space》提出的概念高度契合:“算力充裕型厂商”与“算力紧缺型厂商”。
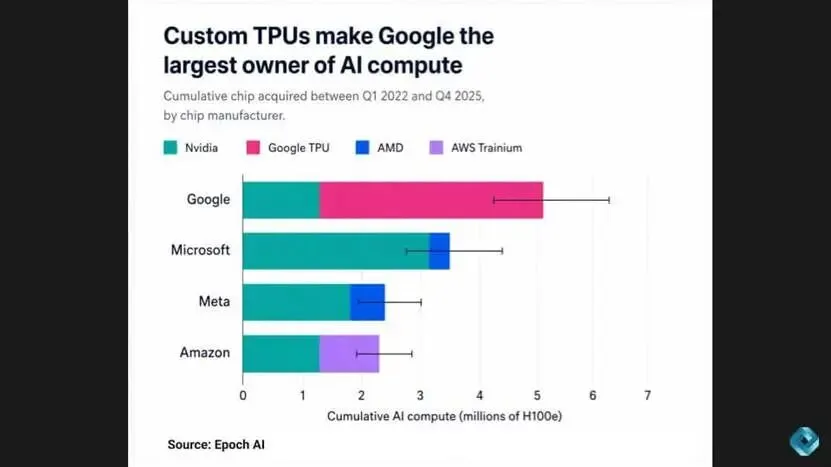
谷歌显然属于算力充裕阵营,这也解释了为何生成式 AI 与 AI 智能体功能,能够在谷歌全产品线大范围落地普及。
反观微软,在本次行业对比中处于算力紧缺状态,这也直接导致其战略取舍:优先将 AI 能力落地于 Office 办公套件、Azure 云服务的生成式 AI 功能落地节奏参差不齐,同时给自身技术栈的其他环节带来连锁承压。
需要明确的关键事实:TPU 的发展,并不会侵蚀英伟达的行业护城河。
当前 AI 加速算力的市场需求极度庞大,高性能加速芯片普遍供不应求,核心原因在于英伟达无法独自消化全球全部算力需求。
谷歌部署 TPU 的核心目的,是为自有业务提供算力支撑,并非以第三方芯片厂商身份对外售卖芯片。
本次分析核心结论
-
充足的 TPU 算力将转化为产品迭代优势。谷歌之所以能实现 “全产品线普及 AI 智能体”,正是因为拥有充足的冗余算力储备作为支撑。 -
微软依靠与 OpenAI 的深度合作、以及英伟达的算力配额,补足了自身 AI 能力短板,但也因此付出代价:产品优先级被迫倾斜、云服务 AI 功能上线节奏失衡。 -
亚马逊走出了差异化路线:自研 Trainium 训练芯片(同时将 Inferentia 推理芯片整合进统一路线)已实现规模化落地;但谷歌凭借稳定的年度迭代节奏与统一的平台架构,正进一步拉开差距。 -
英伟达依旧是全球出货量龙头,CUDA 生态仍是业界主流开发环境。其CPU+GPU + 网络 + 系统级架构一体化捆绑战略,持续抬高全行业的竞争门槛。
综上我们判断:谷歌的 TPU 核心价值,不在于打造英伟达替代品,而在于驱动自身全栈技术体系加速迭代;尤其在软件层面,充足算力将成为关键分水岭 —— 决定企业只能选择性搭载 AI 能力,还是能够全面规模化落地 AI 智能体。