 夜雨聆风
夜雨聆风





从共现矩阵到 Word2Vec:一文搞懂词向量演化和 Embedding 层原理
这篇文章适合谁? 有 Python 基础、想搞懂词向量为什么要这么设计的同学。读完你会知道:共现矩阵、PPMI、SVD、Skip-gram、Embedding 层这一整条线是怎么一步步演化出来的,每一步在解决什么问题,以及 PyTorch 里
nn.Embedding背后的数学其实朴素到不值得单独起一个名字。参考:斋藤康毅《深度学习进阶:自然语言处理》,代码全用 numpy,能直接跑。
一、为什么我们需要词向量?
计算机不认识”苹果”这两个字,它只认识数字。所以做 NLP 的第一步,就是把词变成向量。
最朴素的办法是 one-hot 编码:词表里有 10 万个词,就给每个词分配一个 10 万维的向量,其中对应位置是 1,其他全是 0。
问题立刻就来了:
-
• 维度灾难:10 万维的向量,99.999% 的元素是 0 -
• 语义缺失:”猫”和”狗”的 one-hot 向量点积是 0,机器完全看不出它们有什么关系
我们想要的词向量应该具备两个性质:维度低(稠密)、语义相近的词在空间里也相近。
从 1950 年代到 2013 年,整整 60 年,研究者走出了一条从统计到预测的演化路径。这篇文章就把这条路重走一遍。
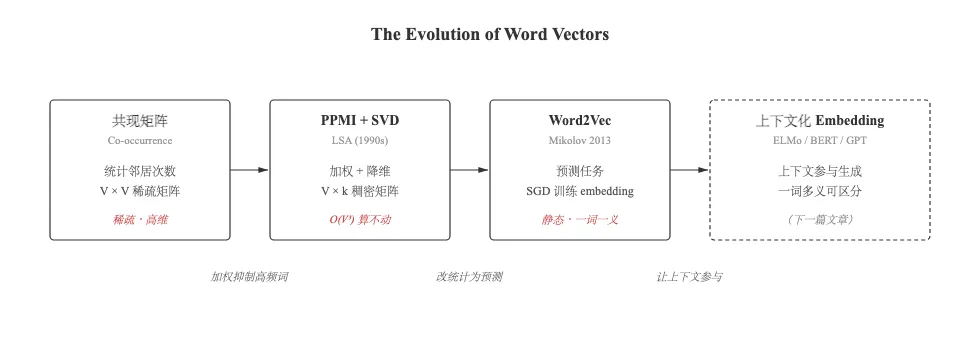
二、分布式假设:意思从哪里来?
1957 年语言学家 J.R. Firth 说过一句很有名的话:
You shall know a word by the company it keeps.
一个词的意思,可以由它周围经常出现什么词来表达。
比如 cat 和 dog,字面完全不同,但它们周围常出现 pet / feed / animal / furry。如果我们把每个词表示成”它周围出现过哪些词、各出现多少次”的向量,语义相近的词在向量空间里就会靠近。
这就是**基于计数方法(count-based)**的出发点。
三、先说一下 token:计算机怎么理解文字?
在讲共现矩阵之前,得先解决一个问题:计算机怎么把一段文字”拆开”?
完整的 NLP pipeline 长这样:
原始文本 → tokenization → token 序列 → id 序列 → 词向量 "I love NLP" ["I", "love", "NLP"] [3, 7, 42] [...]token 就是模型处理的最小单位。它不一定是”词”——可以是字、词、子词(subword)、甚至单个字符。tokenization(分词) 就是把文本切成 token 的过程。
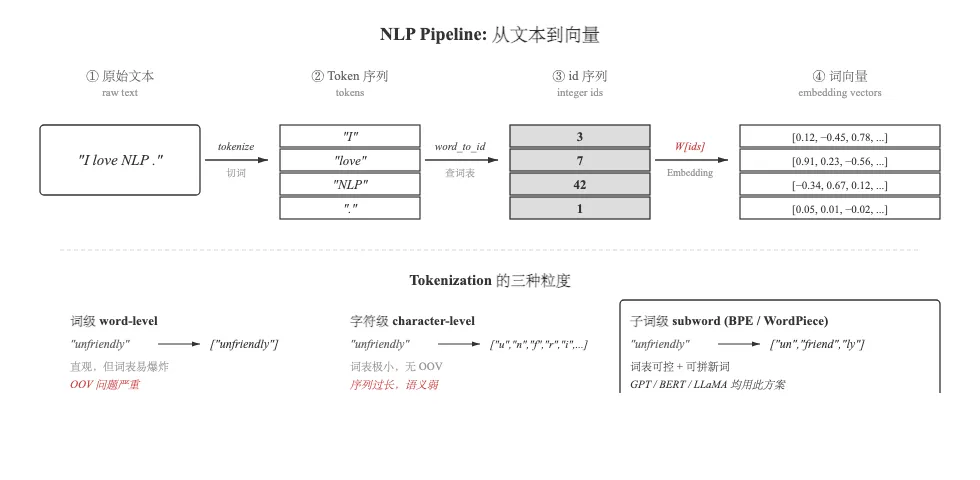
常见的三种 tokenization 方式
|
|
|
|
|
|---|---|---|---|
| 词级 |
|
|
|
| 字符级 |
|
|
|
| 子词级(subword) |
|
|
|
现代大模型(GPT、BERT、LLaMA)全都用 subword:它把 playing 切成 play + ##ing,既控制住了词表大小,又能处理新词、派生词。
本文的 tokenization
为了聚焦在”词向量”这条主线,我们用最朴素的空格分词——这也是 Word2Vec 时代的常见做法:
import numpy as npdef preprocess(text): text = text.lower().replace('.', ' .') words = text.split(' ') # ← 这里就是 tokenization word_to_id, id_to_word = {}, {} for w in words: if w not in word_to_id: new_id = len(word_to_id) word_to_id[w] = new_id id_to_word[new_id] = w corpus = np.array([word_to_id[w] for w in words]) return corpus, word_to_id, id_to_wordtext = 'You say goodbye and I say hello.'corpus, word_to_id, id_to_word = preprocess(text)# corpus = [0 1 2 3 4 1 5 6]# word_to_id = {'you': 0, 'say': 1, 'goodbye': 2, 'and': 3, 'i': 4, 'hello': 5, '.': 6}这一步完成了两件事:
-
1. 分词:把字符串切成 token 列表 -
2. 建词表:给每个 token 分配一个唯一 id,得到 token ↔ id的双向映射
后面所有讨论(共现矩阵、Word2Vec、Embedding 层)处理的都是 id 序列,而不是原始字符串——这是 NLP 的通用套路,记住它。
四、共现矩阵怎么建?
有了 id 序列,就可以开始统计共现了。对每个词,统计”窗口范围内”的邻居出现了多少次。窗口大小 window_size=1 表示只看左右各一个词。
def create_co_matrix(corpus, vocab_size, window_size=1): C = np.zeros((vocab_size, vocab_size), dtype=np.int32) for idx, word_id in enumerate(corpus): for i in range(1, window_size + 1): left_idx, right_idx = idx - i, idx + i if left_idx >= 0: C[word_id, corpus[left_idx]] += 1 if right_idx < len(corpus): C[word_id, corpus[right_idx]] += 1 return CC = create_co_matrix(corpus, len(word_to_id), window_size=1)矩阵的第 i 行就是词 i 的向量,每个元素含义是”词 i 旁边出现词 j 多少次”。
比如 say 的向量是 [1, 0, 1, 0, 1, 1, 0],它在 you / goodbye / i / hello 旁边都出现过。
用余弦相似度衡量词有多像
两个向量方向越接近,词义越相近:
def cos_similarity(x, y, eps=1e-8): nx = x / (np.sqrt(np.sum(x ** 2)) + eps) ny = y / (np.sqrt(np.sum(y ** 2)) + eps) return np.dot(nx, ny)print(cos_similarity(C[word_to_id['you']], C[word_to_id['i']]))# 0.7071 —— you 和 i 很像,因为都常出现在 say 前面分布式假设起作用了。
五、共现矩阵有什么问题?PPMI 来修正
想象一下 the car 这个组合。它们共现次数很高,但 the 几乎和所有词都共现,它的”高共现”其实不提供信息。
我们真正关心的是:「某两个词的共现,是否超出了它们各自独立出现时的随机概率?」
这就是 PMI(Pointwise Mutual Information,点互信息):
-
• 两词独立 → PMI = 0 -
• 共现远高于随机 → PMI 为正且大 -
• 共现远低于随机 → PMI 为负(但负值往往噪声大、不可靠)
所以实际用 PPMI(Positive PMI),把负值截成 0:
def ppmi(C, eps=1e-8): M = np.zeros_like(C, dtype=np.float32) N = np.sum(C) S = np.sum(C, axis=0) for i in range(C.shape[0]): for j in range(C.shape[1]): pmi = np.log2(C[i, j] * N / (S[j] * S[i]) + eps) M[i, j] = max(0, pmi) return MW_ppmi = ppmi(C)PPMI 比原始计数更能反映「有信息量的共现」。但它仍然有两个致命伤:
-
1. 维度 = 词表大小:中文词表动辄 10 万,向量 10 万维,大多数元素是 0 -
2. 抗噪差:稀疏向量里每个元素都很”孤立”,换个语料结果就抖
得想办法把稀疏高维压成稠密低维。
六、为什么要用 SVD 降维?
奇异值分解(SVD)把任意矩阵 X 拆成三个矩阵相乘:
-
• U:左奇异向量,每一行是”词”在潜在语义空间的坐标 -
• Σ:对角矩阵,数值越大代表这个潜在维度越重要 -
• V^T:右奇异向量
关键操作:只保留 Σ 最大的前 k 个奇异值,对应 U 的前 k 列就是每个词的 k 维稠密向量。丢掉小奇异值 = 丢掉不重要的细节 = 降噪。
U, S, V = np.linalg.svd(W_ppmi)# 取 U 的前 2 列作为每个词的 2 维向量for i in range(vocab_size): print(f"{id_to_word[i]:>8s}: {U[i, :2]}")这条路线叫 LSA(Latent Semantic Analysis,潜在语义分析)。
LSA 的致命问题
LSA 在小语料上效果不错,但面对互联网级语料(几十亿词、百万级词表):
|
|
|
|---|---|
| 算不动 |
|
| 不可增量 |
|
| 目标模糊 |
|
2013 年 Mikolov 等人提出 Word2Vec,把整个思路翻了过来:不再”先统计后降维”,而是直接定义一个预测任务,让神经网络去学一个小的稠密向量——统计信息会作为副产品被编码进去。
七、Skip-gram 网络怎么训练?
Skip-gram 的任务设定很简单:给定中心词,预测它的上下文词。
... goodbye and [I] say hello ... ↑ ↑ ↑ 上下文 中心 上下文模型要学:给定中心词 I,输出 and 和 say 的概率要高。
网络结构:
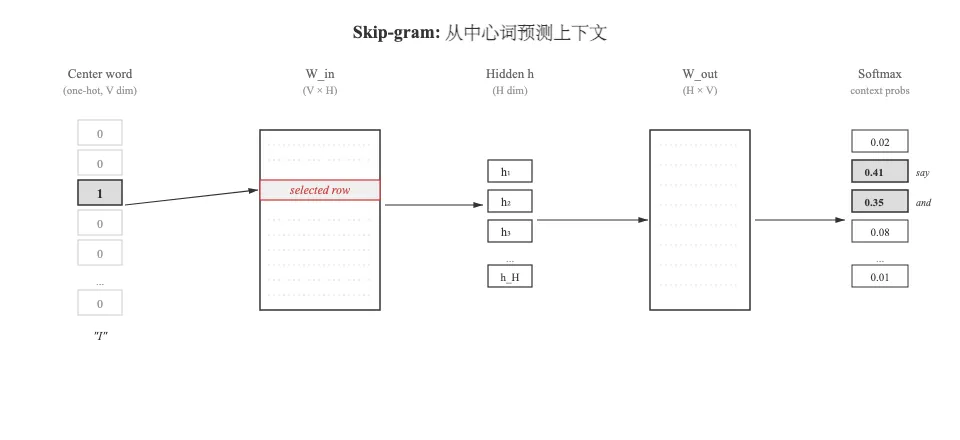
关键洞察:因为输入是 one-hot,one_hot × W_in 其实就是取 W_in 的某一行。所以 W_in 的每一行就是对应词的向量。训练的目标不是”预测得准”本身,而是让这些行(词向量)在训练过程中被推到合理的位置。
构造训练样本
def create_contexts_target(corpus, window_size=2): centers, contexts = [], [] for idx in range(window_size, len(corpus) - window_size): center = corpus[idx] for t in range(-window_size, window_size + 1): if t == 0: continue centers.append(center) contexts.append(corpus[idx + t]) return np.array(centers), np.array(contexts)每个中心词配 2 * window_size 个 (center, context) 样本。
八、Embedding 层是怎么来的?
在写 Skip-gram 代码之前,要先解决一个看似小、其实非常关键的工程问题。这也是 PyTorch 里 nn.Embedding 的由来。
按教科书画的网络图,前向是这样的:
中心词 id → one-hot 向量 (V 维) ── × W_in (V × H) ──> h (H 维)公式:。
但这件事在实际计算上离谱地浪费。假设 V=100 万,H=300:
-
• one-hot 向量里 999999 个 0、1 个 1 -
• 和 100 万 × 300 的矩阵相乘,要做 3 亿次乘加 -
• 结果只是 W_in 的某一行(那个 1所在位置对应的行)
也就是说:整场矩阵乘法就为了取一行。
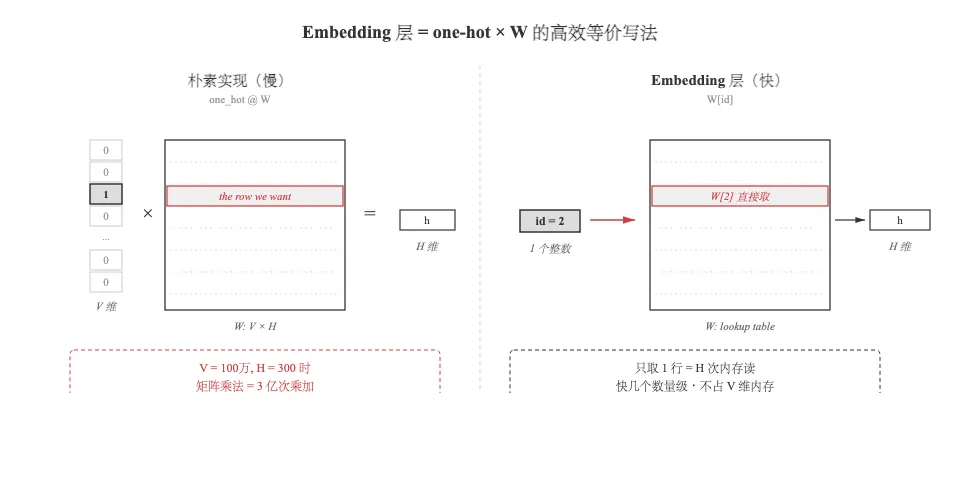
我们来实测一下差距:
import timeV, H = 50_000, 300W_in = np.random.randn(V, H).astype(np.float32)word_id = 12345# 方法 A: 朴素 one-hot 乘法one_hot = np.zeros(V, dtype=np.float32); one_hot[word_id] = 1t0 = time.time()for _ in range(100): h_matmul = one_hot @ W_int_matmul = time.time() - t0# 方法 B: 直接索引(Embedding lookup)t0 = time.time()for _ in range(100): h_lookup = W_in[word_id]t_lookup = time.time() - t0print(f'结果一致?{np.allclose(h_matmul, h_lookup)}')print(f'加速比: {t_matmul / t_lookup:.0f}x')两个结果完全一致,但索引查表快几个数量级,且不占 V 维 one-hot 的内存。
这就是 Embedding 层的全部思想:
把”one-hot → 矩阵乘 → 取一行”这个三步操作,直接简写成”按 id 从表里取一行”。
换个视角:W_in 本来在网络图里是一个”线性层的权重”,现在把它重新理解为一张查找表(lookup table)——每个 id 对应表里一行稠密向量。训练任务没变,变的只是实现方式。
反向传播也省了
朴素版本里,反向传播要算 ,得到一个 V×H 的矩阵,但里面只有第 word_id 行非零,其余全是 0。
Embedding 层直接跳过这一步:梯度只累加到被查询过的那些行上。
class Embedding: def __init__(self, vocab_size, hidden_size): self.W = 0.01 * np.random.randn(vocab_size, hidden_size).astype(np.float32) self.ids = None self.dW = None def forward(self, ids): self.ids = ids return self.W[ids] # 直接查表 def backward(self, dout): self.dW = np.zeros_like(self.W) # 同一个 id 在 batch 里可能出现多次,必须用累加 np.add.at(self.dW, self.ids, dout) return None为什么用 np.add.at 不用 dW[ids] = dout? 因为同一个 id 在一个 batch 里可能被查询多次(比如 the 是 stopword,到处都有),这种重复索引下,普通赋值只会保留最后一次的梯度,必须用累加。
小结
|
|
|
|---|---|
|
|
|
one_hot @ W 算 3 亿次乘加 |
W[id] 取一行 |
|
|
|
|
|
|
这正是 PyTorch nn.Embedding、TensorFlow tf.keras.layers.Embedding 在做的事——它不是一种新层,而是”one-hot 乘法”的高效等价写法。
九、手写一个 Skip-gram
把所有东西用 numpy 写一遍,每一步都看得见。
class SkipGram: def __init__(self, vocab_size, hidden_size): self.W_in = 0.01 * np.random.randn(vocab_size, hidden_size).astype(np.float32) self.W_out = 0.01 * np.random.randn(hidden_size, vocab_size).astype(np.float32) def forward(self, center_ids, context_ids): h = self.W_in[center_ids] # (B, H) —— Embedding lookup scores = h @ self.W_out # (B, V) scores -= scores.max(axis=1, keepdims=True) # 数值稳定 exp_s = np.exp(scores) probs = exp_s / exp_s.sum(axis=1, keepdims=True) B = len(center_ids) loss = -np.log(probs[np.arange(B), context_ids] + 1e-7).mean() self.cache = (center_ids, context_ids, h, probs) return loss def backward(self, lr): center_ids, context_ids, h, probs = self.cache B = len(center_ids) # softmax + 交叉熵梯度: probs - one_hot(context) dscores = probs.copy() dscores[np.arange(B), context_ids] -= 1 dscores /= B # W_out 的梯度 dW_out = h.T @ dscores # 隐藏层梯度 dh = dscores @ self.W_out.T # W_in 的梯度:只往对应行累加 dW_in = np.zeros_like(self.W_in) np.add.at(dW_in, center_ids, dh) # SGD 更新 self.W_in -= lr * dW_in self.W_out -= lr * dW_out训练
造个玩具语料(围绕 king/queen/man/woman 的模式):
text_big = ( 'the king is a man . the queen is a woman . ' 'the prince is a young man . the princess is a young woman . ' 'a man can be a king . a woman can be a queen . ' 'the boy is a young man . the girl is a young woman . ' 'the king rules the kingdom . the queen rules the kingdom . ' 'a boy grows into a man . a girl grows into a woman .')corpus, word_to_id, id_to_word = preprocess(text_big)vocab_size = len(word_to_id)centers, contexts = create_contexts_target(corpus, window_size=2)model = SkipGram(vocab_size, hidden_size=10)for epoch in range(3000): idx = np.random.choice(len(centers), size=128) model.forward(centers[idx], contexts[idx]) model.backward(lr=0.5)训练完成后,model.W_in 的每一行就是对应词的 10 维稠密向量。
十、词向量为什么能做类比推理?
Word2Vec 最惊艳的发现:词向量的差能编码关系。
因为”男女差异”这个语义被编码成了向量空间里的一个方向,只要朝那个方向走,就能在 king → queen 之间做转换。
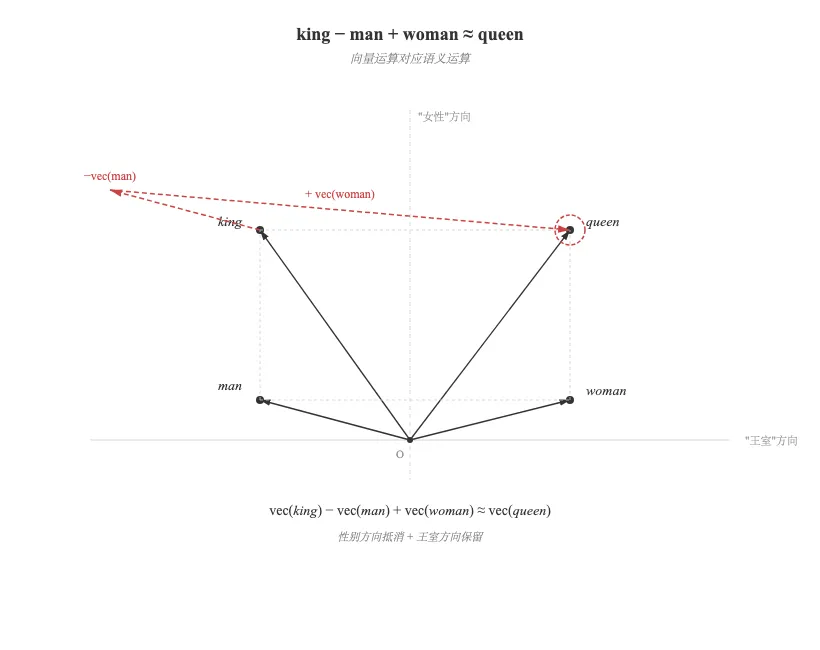
def analogy(a, b, c, W): """a : b = c : ? ==> vec(b) - vec(a) + vec(c) 最接近谁""" query = W[word_to_id[b]] - W[word_to_id[a]] + W[word_to_id[c]] sims = np.array([cos_similarity(W[i], query) for i in range(len(word_to_id))]) for i in (-sims).argsort(): if id_to_word[i] not in (a, b, c): print(f' {id_to_word[i]}: {sims[i]:.4f}'); breakanalogy('man', 'king', 'woman', model.W_in)# man : king = woman : queen玩具语料很小,效果不会像原论文那样惊艳,但你能看到向量空间的几何结构真的编码了语义——这才是 Word2Vec 最震撼的地方。
十一、三条路线对比总结
|
|
|
|
|
|---|---|---|---|
| 共现矩阵 |
|
|
|
| PPMI + SVD(LSA) |
|
|
|
| Word2Vec (Skip-gram) |
|
|
|
整条演化的内在逻辑:
-
1. 分布式假设:意思从共现里来 -
2. 直接统计 → 太稀疏 → 加权(PPMI)+ 压缩(SVD) -
3. 压缩代价太大 → 改成预测任务,让网络直接”学”稠密向量 -
4. Word2Vec 把这条路走到了头,但它解决不了”一词多义”
下一步:从静态到动态
Word2Vec 里 bank 只有一个向量,无法区分”银行”和”河岸”。要解决这个问题,就得让上下文参与向量的生成——这就是 ELMo → Transformer → BERT → GPT 这条线。
不过那是下一篇文章的故事了。
常见问题
Q:共现矩阵和 PPMI 的区别是什么?A:共现矩阵记录原始共现次数,the car 这种高频搭配会把 the 的向量拉得很偏。PPMI 用概率比值衡量「超出随机水平的共现程度」,对高频 stopword 不敏感,更能反映有信息量的搭配。
Q:SVD 降维和 Word2Vec 本质上是一回事吗?A:从数学上看确实有联系——有论文证明 Skip-gram with negative sampling 隐式地在分解一个 shifted PMI 矩阵。但工程上差别巨大:SVD 一次性算完但算不动大语料;Word2Vec 流式训练、可增量、易扩展,这是它在 2013 年之后统治工业界的根本原因。
Q:PyTorch 的 nn.Embedding 背后是什么?A:就是一张 (V, H) 的查找表。前向 embedding(ids) = W[ids],反向梯度只累加到被查询过的行上。它在数学上等价于”one-hot × W”,但省掉了 V 维 one-hot 向量的内存和矩阵乘法的计算。不是新层,是高效写法。
Q:为什么 np.add.at 不能换成普通的赋值?A:因为同一个 batch 里相同 id 可能出现多次(比如 the 频繁被查询)。普通赋值只会保留最后一次梯度,np.add.at 保证梯度累加——这对应”同一个词被查询多次,它的梯度应该被加多次”的数学事实。
Q:为什么 king – man + woman ≈ queen?A:训练过程中,性别、王室、年龄等语义属性被编码成向量空间里正交(或近似正交)的方向。向量减法剥离了”国王”里的”男性”分量,加法补上了”女性”分量,剩下的”王室”分量不变,所以落点在 queen 附近。
Q:token 和 word 是一回事吗?A:不一定。word 是自然语言里的词,token 是模型处理的最小单位——可以是字、词、子词(subword)或字符。本文用空格切词,一个 word 就是一个 token;但 GPT、BERT 用 BPE/WordPiece 做 subword tokenization,playing 会被切成 play + ##ing 两个 token。现代大模型里说的”token 数”几乎都指 subword token,不是自然意义上的词。
Q:Skip-gram 和 CBOW 哪个好?A:CBOW 用多个上下文预测中心词,Skip-gram 反过来。经验上:Skip-gram 对低频词效果更好(每个上下文词都是一个独立样本),CBOW 训练更快。Mikolov 原论文推荐 Skip-gram 处理小数据集,CBOW 处理大数据集。
关注我,一起从第一行代码开始把深度学习吃透。