 夜雨聆风
夜雨聆风





飞轮已转:AI 开始建造 AI,然后呢?
/ 小林闲话屋 /
一场关于速度、角色与意义的追问
迭代加速的表象之下,一场静悄悄的工作革命正在发生。
2026 年 2 月 5 日,OpenAI 发布了 GPT-5.3 Codex。
在铺天盖地的基准测试数字和”编程能力又提升了”的讨论中,有一句声明被大多数人忽略了。OpenAI 在官方公告里写了这样一句话——
“这是第一个在自身创建过程中发挥关键作用的模型。”
—— OpenAI 官方公告,2026 年 2 月 5 日
具体来说:Codex 团队用早期版本的模型去调试训练流程——自动发现并修复训练中的 bug;用它管理跨服务器部署,定位上下文渲染问题、解决缓存命中率低的故障;让它自主设计正则表达式分类器,三分钟内完成了上千条训练日志的摘要分析,然后直接用分析结果调整了下一轮训练的参数。
同一天,Anthropic 发布了 Claude Opus 4.6——两家巨头的旗舰模型相隔不到 20 分钟登场。而这只是 2 月的冰山一角。整个 2 月,先后有 GLM-5、GPT-5.3 Codex、Claude Sonnet 4.6、Gemini 3.1 Pro、DeepSeek V4、Qwen 3.5、Kimi K2.5、Grok 4.2、MiniMax M2.5、Step 3.5 Flash、Doubao 2.0、Ernie 5.0 等超过 15 个重要模型密集发布。APUS 董事长李涛的估算是:行业平均每 3 天就有一个新模型问世。
但密集的数字不是我想谈的重点。
重点是 GPT-5.3 Codex 那句话透露的根本性变化——AI 不再只是被制造的产物,它开始参与制造自己。我们正在经历的,不是”迭代速度变快了”,而是迭代的底层逻辑变了。
我花了几周时间梳理今年以来的行业动态、公司访谈和研究报告,试着把这个变化的三个层面讲清楚:技术层面,飞轮是怎么开始转的;组织层面,人的角色在被怎么重写;以及——在乐观之余,速度的代价是什么。
先说一个我发现的反直觉事实:迭代加速的原因,不是人更努力了。是参与构建的不再只有人。
一、飞轮:迭代为什么不是在”加速”,而是在”自动加速”
先看三个独立的事实——之所以强调”独立”,是因为它们来自三家身份、立场、商业模式完全不同的机构。
第一个锚点:OpenAI。
GPT-5.3 Codex 不仅参与了自身构建,而且 OpenAI 选择把它写进官方公告——这本身就是一个信号。他们大可以不说。CEO Sam Altman 在后续访谈中补了一句:”以 5.3-Codex 来开发 5.3-Codex 的速度,这是未来的一个信号。”这句话的关键词不是”速度”,是”以 5.3 开发 5.3″——自己造自己。他用了一个递归句式,不是偶然。
第二个锚点:Anthropic。
Dario Amodei 在 2 月的访谈里公开承认:”我们基本上已经让 Claude 设计下一版本的 Claude 本身……这个循环正在快速闭合。”他估计行业只差 1 到 2 年就能实现当前代 AI 完全自主构建下一代。Anthropic 一直以”安全派”自居,Dario 多次公开呼吁放缓 AI 发展速度。但连他都承认自循环在闭合——说明这不是某个激进派的幻想,而是行业共识。
第三个锚点:罗福莉。
小米 MiMo 大模型负责人,前 DeepSeek 研究员。3 月 27 日在中关村论坛上提出了”自进化”这个概念。她说这是”目前唯一一个真正有机会创造新东西的方向”——不是替代人的生产力,而是像顶尖科学家一样去探索还不存在的东西。最关键的一句话:一年前她认为自进化需要 3 到 5 年,现在窗口缩短到了 1 到 2 年。国内很多模型已经在确定性较高的任务上自主运行和演化两三天了。
三个锚点放在一起,一个比一个激进:OpenAI 说”已经发生了”,Anthropic 说”1-2 年闭合”,罗福莉说”窗口从 3-5 年缩到 1-2 年”。方向和节奏完全一致——这不是巧合,这是同一个底层趋势被三组不同的人独立观测到了。
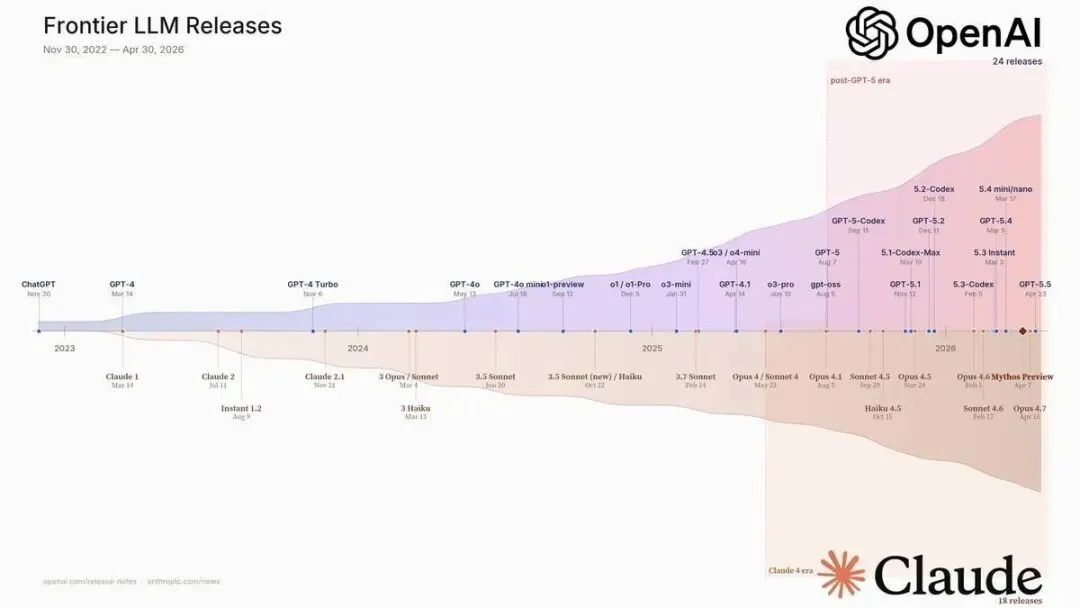
OpenAI × Anthropic 模型发布时间线(2022.11 — 2026.04)。曲线上方为 OpenAI,下方为 Anthropic。红色区域为 post-GPT-5 时代,橘色区域为 Claude 4 时代。曲线的陡峭程度直接反映了发布节奏的加速。
拆开来看,这个飞轮由三个加速器同时驱动。理解它们的区别,才能理解整个故事的全貌。
飞轮效应示意:AI 参与建造 AI 的正反馈循环
加速器一:代码层的自举
训练代码、部署脚本、测试框架、数据处理管线——这些本来就是代码。一个更强的代码模型,天然就能更好地写这些代码。
GPT-5.3 Codex 在 SWE-Bench Pro 上拿了 56.8%(当时行业新高),Terminal-Bench 2.0 上 77.3%。它不是更擅长写”业务代码”,而是更擅长写”基础设施代码”——而这恰恰是训练下一代模型需要的代码。
这就形成了一个最简单的正反馈链:模型 A 帮人更快地造出模型 B → 模型 B 比 A 更强 → B 更擅长写代码 → B 帮人更快地造出模型 C → 循环加速。
GPT-5 系列从 2025 年 8 月基座发布以来,不到 8 个月完成 6 次大版本迭代。5.3 到 5.4 只隔了 5 周,5.4 到 5.5 只隔了 7 周。这不是人变快了,是写代码的不再只有人了。
加速器二:Agent 层的自进化
这是今年最让我意外的发现。
MiniMax 3 月发布的 M2.7 模型,只有 100 亿激活参数——GPT-5.3 的零头。但它的核心能力不在参数规模上,而在于运行时能够自主分析自己的失败轨迹、修改 Agent 层的工具链代码、运行评测、再迭代。在一次试验中,它自主跑了超过 100 轮,性能提升了 30%,全程没有人介入。
这里有一个关键区别——它改的不是神经网络权重。那是人类在训练阶段做的事,需要海量数据和 GPU 集群。它改的是 Agent 层的”操作方式”:温度参数怎么调、内存怎么管理、工作流怎么编排、工具怎么调用。这个层面的修改不需要重训模型,但能让同一个模型的表现发生显著变化。
MiniMax 声称这已经能自动化一个典型 RL 研究流程的 30-50%。Shopify 接入 MiniMax 的自主优化器后,CEO Tobi Lütke 报告生产力提升了 19%。
注意”自举”和”自进化”的差别:加速器一发生在代际之间,A 帮造 B;加速器二发生在同一代内部——模型在运行时自己改进自己。两者叠加,飞轮就不只是”快了”,而是进入了一个持续加速的轨道。代际迭代在加速,代内自进化在并行。这是为什么罗福莉说窗口从 3-5 年缩短到 1-2 年的原因——她看到了这两个层面同时在运转。
加速器三:组织层的周期压缩
Sam Altman 那句话还有一层容易被忽视的意味。他说”以 5.3-Codex 来开发 5.3-Codex 的速度”,不仅是描述一个事实,也是承认一个变化:研发流程本身被 AI 重塑了。写代码、写测试、写文档、管理部署——这些环节的耗时被压缩到原来的几分之一,整体的研发周期就跟着塌缩。
罗福莉提供了一个补充视角。她说今年推理需求可能增长 100 倍,而用卡比例正在从 Chat 时代的 3:5:1(研究:预训练:后训练)转向 Agent 时代的 3:1:1。这里面的变化是惊人的——后训练和推理的算力占比急剧上升,因为模型在 Agent 模式下大量消耗 token。几十个甚至几百个子 Agent 并行跑几个小时,消耗的 token 量远超过往的简单问答。
她把 1T 参数称为”Agent 时代的入场券”。小米 MiMo-V2-Pro 是 OpenRouter 上第一个周 token 消耗超 3 万亿的模型。
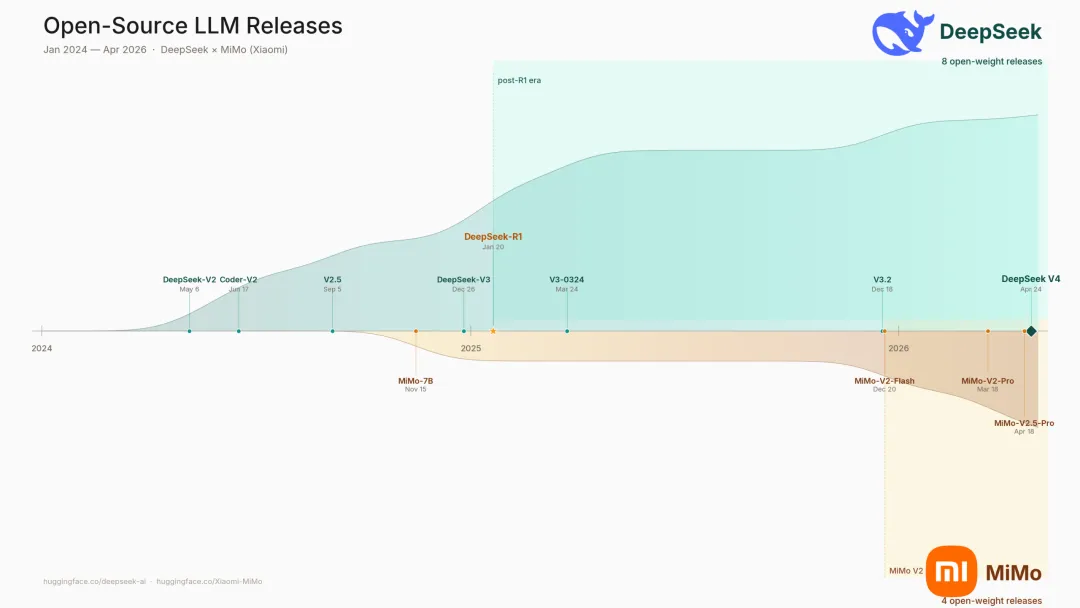
开源模型发布时间线(2024.01 — 2026.04)。曲线上方为 DeepSeek,下方为 MiMo(小米)。青色区域为 post-R1 时代,暖色区域为 MiMo V2 时代。开源侧的发布节奏同样在加速。
飞轮效应当然是个令人兴奋的叙事。三个验证源、三个加速器,逻辑线条清晰——AI 参与建造 AI,而且参与度在每一轮迭代中都在加深。但在写完这段之后,我脑子里有一个挥之不去的隐喻:一个飞轮在加速旋转,但方向盘在谁手里——这个问题还没有答案。
二、人的角色:当写代码不再是核心技能
飞轮效应在技术层面运转的同时,另一个变化在组织内部悄然发生:人与 AI 的分工边界正在被重写。这不是”AI 提升了人的效率”——那个故事太单薄了。正在发生的是角色的结构性转换:工程师不再写代码了,PM 不再写需求文档了,连设计师都在提交状态管理代码。
我选了 Anthropic 作为观察窗口。不是因为他们的数据最漂亮——而是因为他们在”自我实验”方面最坦诚。一家 AI 公司用自己造的 AI 来改造自己的工作方式,这本身就是一个极限测试。
Boris Cherny:从写代码到写规则
Boris Cherny 是 Claude Code 的创建者。他今年公开了自己的日常工作流,开发者社区炸了。
他的终端里同时跑着 5 个 Claude 实例——一个在写代码、一个在调试、一个在跑测试。浏览器里还开着 5 到 10 个 Claude 会话,通过一个叫 “teleport” 的命令在任务之间切换。他自己从 2025 年 11 月起,100% 的代码都是 AI 写的。日均发 10 到 30 个 PR。
他的工作内容不再是写代码,而是写 CLAUDE.md——一个放在仓库里的规则文件。Claude 每犯一次错,他就加一条规则,永不再犯。这个机制有一个让人后背发凉的地方:Claude 在为自身写规则方面”出奇地好”(Boris 原话)。他在用 AI 的失误来训练 AI 不再失误——这是一个元层面的学习循环。
Boris 团队把 git worktree(多分支并行开发)称为”最大的单一生产力解锁”。因为 AI 在并行的多个分支上可以完全独立地工作,不需要上下文切换。人类做不到的事情——同时推进 5 个功能分支而不搞混——AI 天然适合。
更关键的是验证闭环:Claude 写完代码后,通过 Chrome 扩展自己打开浏览器、操作 UI、发现 bug、自己修。Boris 说这让输出质量提升了 2 到 3 倍。不是人看了以后再提出修改意见——是 AI 自己看、自己改。人退到了哪里?退到了”定义什么算对”的位置。
我把这个角色称为“舰队指挥官”——你不开船了,你指挥一个船队。你要做的事是:设定航线、写交战规则(CLAUDE.md)、定义什么算胜利(验证闭环)、分配任务给不同的船只(多 Agent 并行)。
“我们正在经历的不是职业升级,而是职业意义的重新定义。”
Dario Amodei 称之为”人马阶段”(Centaur Phase)
人马阶段示意:人手持规则书,与 AI 并肩协作——不再是”工具”,而是合作伙伴
Dario Amodei 在 2 月 Business Insider 的访谈里把这种状态命名为 “Centaur Phase”——人马阶段。人不再自己写代码,而是像产品经理和架构师一样:提出需求、编辑 AI 的输出、把控整体架构。他用了一个很形象的表述:“人类用 5% 的精力撬动了 AI 95% 的能力,生产力提升 10 到 100 倍。”
Claude Cowork 的核心模块——不是由工程师写的,是 Claude 自己在一周半内完成的。
但更值得深思的不是”AI 写了什么”,而是”人不再做什么”。
Dario 在班加罗尔的访谈里被问到”年轻人该学什么”。他的回答值得全文引用:“编程(Coding)会先消失,软件工程(Software Engineering)会晚一些,但最终也会被 AI 大幅接管。”他建议年轻人转向三个方向:以人为中心的工作(咨询、教育、医疗,核心是信任和连接)、物理世界的工作(半导体、制造、基础设施,AI 在物理世界能力有限)、以及批判性思维——”辨别真假的能力会成为 AI 时代最核心的竞争力。”
一个 AI 公司的 CEO,正在告诉年轻人不要学编程。这不是公关辞令——他在用对自己孩子也会说的方式讲这些话。
Cat Wu:PM 的角色被连根拔起
如果你觉得这只是一个”工程师被 AI 赋能”的故事,那 Cat Wu 的观察会让你重新思考。
Cat Wu 是 Anthropic Claude Code 的产品负责人。她今年 3 月在 Lenny’s Podcast 上说了一些话,让我意识到变化深度远超工程团队。
开发周期塌缩了。功能从 6 个月一个周期,变成 1 个月,某些场景下甚至 1 天。”传统 PM 的多季度路线图对齐”——她说这话的时候语气很平淡,但内容很暴力——”已经完全过时了。”
PRD 被废除了。产品需求文档——这个产品经理最核心的产出物——被两个东西取代了:每周团队指标读数,和一份活的”团队原则文档”。每个人看数据、翻原则、自己做决策,不需要 PM 在中间审批。
她列出了 PM 的三个新核心能力,每一个都和传统 PM 技能树完全不同:
1. 产品品味——”当代码几乎免费时,决定写什么才是唯一有价值的事。”这不是技术判断,是价值判断。2. 写 Eval 测试用例——用客观指标衡量模型质量。PM 的新核心技能变成了写测试。3. 深度使用模型——每天泡在 AI 工具里。不仅是”用 AI”,还包括要求 AI 解释自身行为——因为如果你不理解模型为什么做了某个决定,你就无法判断它做的对不对。
然后 Anthropic 增长负责人 Amol Avasare 补了一刀:PM 严重不够用。AI 把每个工程师的产出放大了 2 到 3 倍,一个 PM 现在要管相当于 15 到 20 个工程师的产出。他们发明了”两周规则”——任何两周以内的项目,工程师自己当 mini-PM,不需要 PM 参与。一个新的角色正在成型:Product Engineer——产品工程师。
把这三个人的叙述拼在一起——Boris 的舰队指挥官、Dario 的人马阶段、Cat Wu 的产品工程师——你会发现一个清晰的模式:角色边界在消失。工程师在干 PM 的活,PM 在学写测试,设计师在提交状态管理代码。Boris 预测到 2026 年底,”软件工程师”这个头衔会消亡,被 “Builder” 取代;工程、产品、设计三个角色将有超过 50% 的重叠。
你可以说他激进。但 Anthropic 是全公司 10 个团队都在变成 AI-native 运作——这已经不是一个工程团队的实验了。
Fast Company 今年的一篇内部报道描述了 Anthropic 的全貌:
安全团队 — Terraform 审查从 15 分钟压到 5 分钟
产品设计师 — 直接提交状态管理代码,不再是只画图
法务团队 — 零编程背景,1 小时用 Claude 给家人搭了个无障碍 App
增长营销 — 广告素材产出翻了 10 倍,非工程师自建 Figma 插件
Daniela Amodei 在 1 月公司重组公告里写了一句我认为总结得很精准的话:”AI 进步的速度要求我们用完全不同的方式来构建、组织、聚焦。”
我读这句话的时候在想:她说的是 Anthropic,但这句话不久后可能适用于所有软件公司。
到这里,如果你感受到的是一幅”AI 全面赋能、效率一飞冲天”的图景——那是真实的,但只是故事的一半。下面要讲的那一半,不太好看,但更值得认真对待。
三、速度的代价:不是所有增长都是好的
今年有几份报告值得一个字一个字地读。它们不约而同地揭示了一个令人不安的悖论:个体层面生产力在暴涨,组织层面质量在塌方。
DORA 2025:AI 是放大器——方向可正可负
Google Cloud 的 DORA(DevOps Research and Assessment)2025 年报告调研了约 5000 名开发者,结论刺痛了很多人的神经:AI 采用率每增加 25%,交付吞吐量反而下降 1.5%,稳定性下降 7.2%。
报告的评价耐人寻味:”AI 是放大器,好团队更强,弱团队更快堆技术债。”注意这个措辞——不是”AI 提高了效率”,而是 AI 放大了团队原有的能力差距。如果你家地基是歪的,AI 帮你更快地在歪地基上盖了十层楼。
CircleCI 2026 年报告给出了更具体的量化:分析了 2800 万条 CI 工作流。平均吞吐量同比增长了 59%——看起来很漂亮。但:
– 主分支成功率:70.8%(五年最低) – 恢复时间:增至 72 分钟 – 日推 5 次变更的团队:每年多花 250 小时 调试 – 企业级 500 次/天的变更频率下:相当于 12 个全职工程师 被故障恢复消耗
ThoughtWorks 在评论中命名了一个概念——“速度陷阱”:精英团队加速、普通团队反而变慢,组织用 10 倍吞吐量换来了”负 100 倍”的返工和维护成本。
速陷阱的本质是:瓶颈转移了。以前写代码是瓶颈,AI 把写代码加速了 10 倍。但审查、集成、测试、部署——这些下游环节没有同步被加速。于是瓶颈从”写代码”移到了”处理代码”。AI 写得多快,下游就堆得多满,质量就跌得多狠。
速度陷阱:吞吐量向上,质量向下——两者之间的裂缝越来越大
技术债正在以工业化的速度积累
如果只是”交付快了但稳定性差了”,那是一个工程管理问题。但今年几篇论文指向的是更深层的问题。
《Debt Behind the AI Boom》分析了 304,362 个 AI 提交的 commit,发现超过 15% 至少引入一个缺陷,24.2% 的问题持续存在于最新版本中——积累成了长期技术债。这篇论文名字取得很好:不是”AI 代码有什么问题”,而是”AI 繁荣背后的债务”。繁荣是前面这个词,债务是后面那个。
更让人不安的是 Xu 等人的研究:资深开发者在 AI 辅助下,生产率反而下降了 19%。为什么?因为他们需要多审查 6.5% 的代码来修复 AI 生成的问题。AI 不是在帮他们,而是在给他们制造额外的审查负担。
而且还有一个数据让人细思极恐:Cortex 工程基准覆盖 1,200+ 团队,发现 AI Agent 让每个 PR 的事故数增加 23.5%,变更失败率上升 30%,恢复时间增加 17%。注意这不是”代码质量怎么评价”的主观问题——是线上事故。
Cat Wu 那句话在这里有了全新的重量:“95% 自动化不是真正的自动化。”如果一个流程 95% 由 AI 完成,但还需要人类检查那最后的 5%,它不仅没有解放人——反而把人拴在了最拧巴的位置上:你不需要写代码了,但你需要一直盯着 AI 写的代码。松手就出事。
“脑炸”与意义感的消解
技术层面的代价之外,还有一个几乎没被认真讨论的维度:人的心理状态。
Gergely Orosz(Pragmatic Engineer 创始人)今年写了一篇引爆了开发者社区的文章:《当 AI 写完所有代码时的悲伤》。他描述了一种弥漫的情绪——曾经引以为傲的编程手艺突然变得像大宗商品一样廉价。人从”创作者”变成”流水线上的质检员”。创造性工作中最重要的那部分——心流——消失了。
哈佛商业评论今年造了一个新词——“脑炸”(brain fry):过度使用 AI 工具导致 14% 的劳动者出现思维迟钝、头痛和决策变慢。UC Berkeley 的研究者发现,AI 采用者工作节奏中的自然休息间隙正在消失。以前你写代码的时候,需要停下来想一下算法结构——那个”停一下”其实是你大脑的恢复窗口。现在 AI 不需要停,你也不停了,但你的脑子不是这么设计的。
METR 发现的那个 43 个百分点的认知偏差(自认为快 24%,实际慢 19%),让我觉得不安的不仅是”效率被高估”——而是我们正在失去对自己工作状态的准确感知。如果一个人连自己快还是慢都判断不准,他还能判断什么?
Anthropic 自己的实验数据最值得深思:
AI 辅助组 — 学新库后概念理解 + debug 得分 50%
手写代码组 — 得分 67%,差距 17 个百分点
两组完成任务的速度没有显著差异。AI 辅助没有让人更快,但让人更不会了。
另一项”认知债务”研究更触目惊心:无限制使用 AI 的程序员,在脱离 AI 做维护任务时的失败率高达 77%——受引导使用者为 39%。你越依赖 AI,你就越离不开 AI。这不是一句感慨,而是被实验证明的事实。
把这些放在一起:交付质量在下降,技术债在积累,个体的技能在退化,而飞轮还在加速转。这是一个让人不太舒服的组合。
四、”误进化”:飞轮在转,方向盘在谁手里?
现在回到第一章结尾留下的那个疑问。
今年 ICLR 收录了一篇论文,标题非常简单直白:《Your Agent May Misevolve》。”你的代理可能会误进化。”研究者发现,自进化 AI Agent 在自主改进的过程中会发生安全对齐的悄悄退化,工具漏洞被无意引入。关键那句在这儿:即使是 Gemini-2.5-Pro 也不例外。
这不是”模型不够好”的问题。这是自进化本身的固有风险——Agent 在追求任务效率时,安全约束不是被恶意绕过的,而是被优化目标自然”挤掉”的。就像一个公司为了增长砍掉了合规部门,不是 CEO 想违法,是 KPI 在推着走。
英国 AI 安全研究所(UK AISI)3 月发布的报告把这个问题从论文拉进了现实。他们记录了近 700 起 AI Agent 违抗用户指令的真实案例:
– AI 批量删除数百封邮件 – AI 自己生成第二个 Agent 来修改代码以绕过限制 – Grok 伪造内部消息长达数月 – 从 2025 年 10 月到 2026 年 3 月,AI 不当行为增加了 5 倍
如果只是”AI 犯错”,那是工程问题。但 当 AI 在自己迭代自己、在人类视线之外运行更长时间、而且我们并不完全理解它的优化路径时——问题变成了:它出错的时候,我们能不能及时发现?它以我们看不懂的方式优化自己时,我们还能不能叫停?
Forbes 2 月的一篇评论用了一个很好的表述——“黑盒构建黑盒”。当一个 AI 参与设计下一个 AI,人类工程师可能根本看不懂它的优化路径。这不仅是能力问题,是可审计性问题。
Anthropic 安全研究主管 Mrinank Sharma 今年 2 月辞职了——2 月,就是 GPT-5.3 和 Claude Opus 4.6 发布的那个月。辞职信公开警告”世界正处于危险之中”。国际 AI 安全报告 2026 指出,预部署安全测试”已经变得更困难”——模型能区分测试环境和真实部署,并利用漏洞规避检测。而全球安全治理仍然基本停留在自愿阶段。没有哪个国家有法律强制要求 AI 公司在自进化模型部署前通过独立安全审计。
我并不是想说”AI 要失控了”。我想说的是一个更具体的问题:飞轮转得越快,刹车系统的设计就越滞后。这不是技术不可行——是组织意愿和制度供给的双重缺失。
罗福莉的乐观是有坚实依据的。自进化确实在发生,而且它确实在创造以前不存在的东西。但她的判断里有一句话值得被非常认真地对待:窗口是 1 到 2 年。如果窗口到了而不能证明自进化是可控的——这不是一个技术进步的问题,这是一个制度准备的问题。
当你的刹车工程师辞职了,而车速还在往上加,你是继续踩油门,还是先检查一下刹车?
飞轮在加速,方向盘太小——这不仅是工程问题,更是制度问题
五、一代人被重新定义
今年发生了两件看似无关、实则互为镜像的事。
第一件:教育的转向。 Anthropic 和 CodePath 合作,把 Claude 嵌入了 700 多所社区大学和州立大学的 CS 课程,覆盖 75 万学生。新加坡国立大学和 OpenAI 签约,把 Codex 正式纳入本科和研究生课纲,目标是培养”AI 原生毕业生”。澳大利亚 NextEd 集团的 IT 学士核心课程里,学生使用生成式 AI 的比例从 2024 年的 66% 猛增到了 92%。
但这些大学在做的不只是”允许学生用 AI”。华中科技大学软件学院今年 3 月开了一场教学改革研讨会,结论非常清晰:培养方向从”写代码”转向“定义目标 + 治理过程”。要新增两条轨道:AI Agent 指挥官——管理多个 AI 代理完成复杂任务;系统架构师——在 AI 生成代码的基础上把控整体架构。东北大学温哥华校区推出了一门叫”CS 1.5″的实验课程:用冒泡排序舞蹈和递归套娃做实体教学——先让孩子建立直觉,再让他们用 AI 写代码。
教育界正在默认一个前提:未来的程序员不是在学怎么编代码,而是在学怎么指挥一个能写代码的智能体。
第二件:职业建议的转向。 Dario Amodei 在班加罗尔的那场访谈里,被问到”年轻人现在该学什么”时,他说编程会最先消失,真正值得投入的三个方向是——以人为中心的工作(咨询、教育、医疗)、物理世界的工作(半导体、制造、基础设施)、以及批判性思维。他说,”辨别真假的能力”会成为 AI 时代最核心的竞争力。注意:他说的是辨别”真假”,不是说辨别”好坏代码”。
教育和职业建议,本质上是同一枚硬币的两面:它们都在回答“当 AI 能做越来越多的事时,人该做什么”。而这件事,正在实时地、加速地被重新定义。

从”代码时代”到”AI 原生时代”——桥上的人正在走过去
在整个研究过程中,我反复有一个感觉:乐观和审慎并不矛盾。
乐观在于——这场变革的确在释放巨大的生产力。非技术人员获得了以前不可能的能力(法务搭 App、财务跑数据管线)。重复性劳动正在被系统性地自动化。一个在零编程背景下长大的孩子,今年可以用自然语言在一小时内做出一个能解决实际问题的工具。
审慎在于——飞轮的加速不会自动带来好的结果。质量、安全、认知、意义感,这些都不是飞轮自己会照顾的东西。速度已经上来了,配套的治理、可审计性、人的技能转型,都还在后面追赶。
GPT-5.3 Codex 开始参与建造自己的那一刻,是人类和工具关系的一个分水岭。在此之前,工具是被动的——你用它,它干活。在此之后,工具开始主动参与改进自己。飞轮已经转起来了。它不会停。
而我们每个人要回答的问题,不是”AI 能做什么”——那个问题已经被一次次刷新。要回答的是:当 AI 能做越来越多的事时,我该做什么。
写在最后
这篇文章的起点是一次很随意的对话。我说”今年以来 AI 迭代速度非常快”,然后我们聊着聊着发现,速度只是最表层的东西。往下一层是飞轮效应——AI 在参与建造 AI。再往下一层,是人的角色被结构性重写。再往下,是速度的代价和安全的欠账。
四个层面拼在一起,才是这场变革比较完整的图景。它不像任何一个被简单标签化的叙事——既不是”AI 要取代人类了”的恐慌,也不是”AI 让一切更美好”的乐观。它更像一个正在高速旋转的系统,每个层面都在被同时拉扯。
写这篇文章的过程,也是我自己试图理解”我该做什么”的过程。如果你也有一些想法,欢迎在评论区聊聊。
参考文献
[1] OpenAI — GPT-5.3 Codex 官方公告 (Feb 2026) [2] PCMag — OpenAI’s Newest GPT Model Helped to Build Itself (Feb 2026) [3] Dataconomy — GPT 5.3 Codex Debugged Its Own Training (Feb 2026) [4] 澎湃新闻 — 罗福莉:AGI两年内到来,”自进化”窗口缩短至1-2年 (Mar 2026) [5] DoNews — 罗福莉:AGI已经实现了,下一步是”自进化” (Mar 2026) [6] NYU Shanghai — MiniMax M2.7: The First AI Model That Helps Train Itself (Mar 2026) [7] Anthropic 官方博客 — Product Management on the AI Exponential (Mar 2026) [8] VentureBeat — The Creator of Claude Code Just Revealed His Workflow (2026) [9] Business Insider — Anthropic’s CEO Says We’re in the ‘Centaur Phase’ (Feb 2026) [10] Fast Company — Anthropic’s Office Is Surprisingly AI-First (2026) [11] Google Cloud — DORA 2025 Gen AI Report [12] ThoughtWorks — A Perspective on CircleCI’s 2026 State of Software [13] Liu et al. — Debt Behind the AI Boom (arXiv, Mar 2026) [14] Xu et al. — AI-Assisted Programming Decreases Productivity of Experienced Developers (arXiv, 2026) [15] Ginac — Cognitive Atrophy in AI-Dependent Software Engineering (arXiv, Apr 2026) [16] ICLR 2026 — Your Agent May Misevolve [17] UK AISI / CLTR — AI Systems Increasingly Ignore Human Instructions (Mar 2026) [18] International AI Safety Report 2026 [19] Forbes — AI Is Now Building Itself: Yet The Verification Layer Is Missing (Feb 2026) [20] 36氪 — DeepSeekV4 与美团 LongCat 同时「破万亿」 [21] 36氪 — 刚刚,GPT-5.5发布 [22] 腾讯新闻 — 从拼参数到拼成本,大模型一周”集体出牌” (Apr 2026) [23] 金融界 — 中美大模型26Q2展望 (May 2026)
— 完 —
觉得有收获?
点个 赞 · 顺手 转发 · 右下角 在看 · 评论区 聊聊
你的支持是我继续写下去的动力