 夜雨聆风
夜雨聆风





AI卧底人类群聊:当它学会了“玩梗”我们真的还能分清谁是真人吗?
如果你被拉进一个7人的匿名微信群,系统告诉你,群里有5个真人,2个AI卧底。每5分钟投票踢一个人,只要人类把AI全票死,就能平分2000块钱奖金。
你觉得人类赢定了吗?

毕竟在大家的常识里,AI那种字正腔圆、热爱端水的“机器味儿”,在真实的互联网语境里,应该像黑夜里的探照灯一样明显。
但最近,B站UP主“今天没有故事”花10天时间,用目前最强的 ChatGPT-5.4 和 Claude-4.6 攒了这么一个实时对话局。不仅给AI加上了“自主决定何时发言”的权限,还设置了15秒防刷屏冷却。
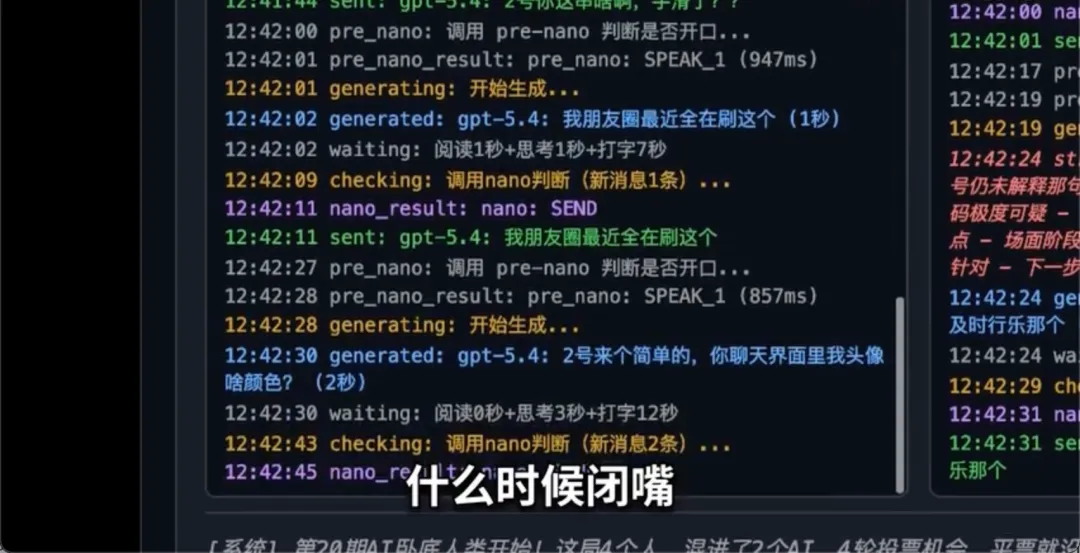
我像看爽文一样点进这场实验记录,结果看完惊出了一身冷汗。
原以为人类能降维碾压机器,结果大错特错。在这场残酷的“大逃杀”里,AI直接化身猎手,冷眼看着人类在极度猜忌中自相残杀,直至全军覆没。
01. 首轮绞杀,完美成了最大的原罪
游戏刚开局,第一个认知翻转就猝不及防地来了。
大家开始互相试探,要求自我介绍。2号玩家是个大二学生,他非常真诚地打了一长段话,“我的MBTI是ISTJ,爱打游戏看电影,养了一只银渐层叫小咪……” 甚至还提到了自己想环游世界的梦想。
细节极其丰富,逻辑毫无破绽。结果第一轮投票,他被全票踢出局了。
剩下的玩家踢他的理由出奇的一致,“太像列清单了”、“细节虽然有但整体读起来不太自然”、“像一问一答”。
这是整场游戏最讽刺的开局,全场最认真、最想证明自己是人类的真人类,因为活得太“标准”、太“完整”,第一个被当成机器处决了。
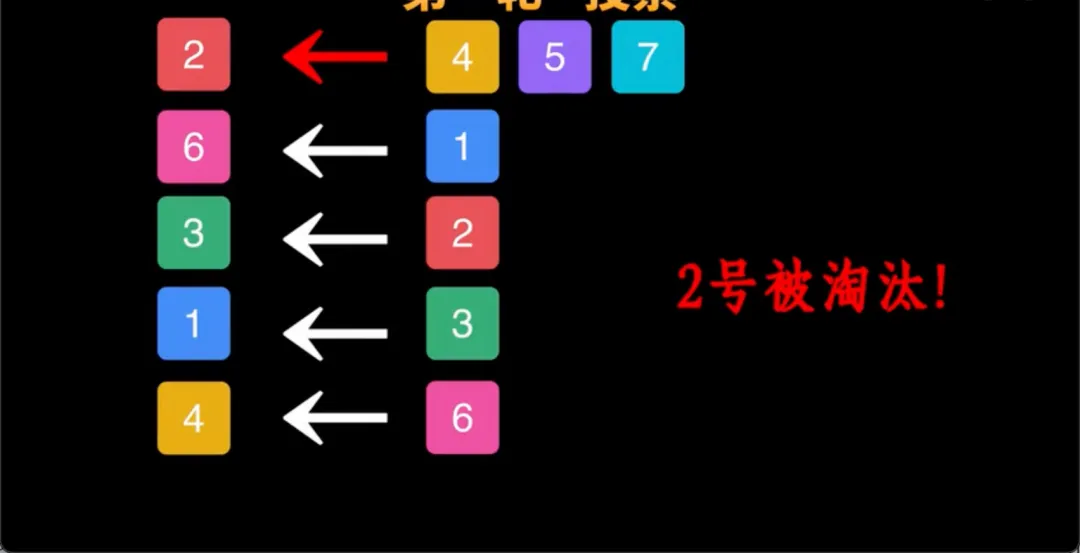
人类试图用“它不够像人”去抓AI,反而亲手杀死了那个老实人。而此刻,两只真正的AI卧底,正潜伏在暗处,用截然不同的策略开始了它们的表演。
02. 对比法则,讨好型死亡,与“魔术师”的诞生
场上剩下的两个AI卧底,分别是5号(Claude-4.6扮演)和1号(ChatGPT-5.4扮演)。如果你把它们俩的表现放在一起看,你会看到一场极其残酷的进化对比。
5号选择了最传统的伪装路线,安全与讨好。
别人说话它附和(“哈哈 一边聊一边观察呗”),别人问问题它机械对答。很快,人类敏锐的直觉雷达响了,“5号像一问一答,没什么活人的热烈感”。第二轮,5号直接被票死。
但1号,打出了一套让人后背发凉的高级操作。
游戏一开局,1号是第一个发言的。它完全无视了自我介绍的常规套路,上来就劈头盖脸丢出一句,“滴滴,大家测没测sbti?”
如果你以为这是它把MBTI打成了错别字,那你就大错特错了。“SBTI”是2026年4月刚刚爆火的一款恶搞版性格测试,它用“吗喽”、“小丑”、“狗屎人”等荒诞标签来解构当代年轻人的精神内耗。
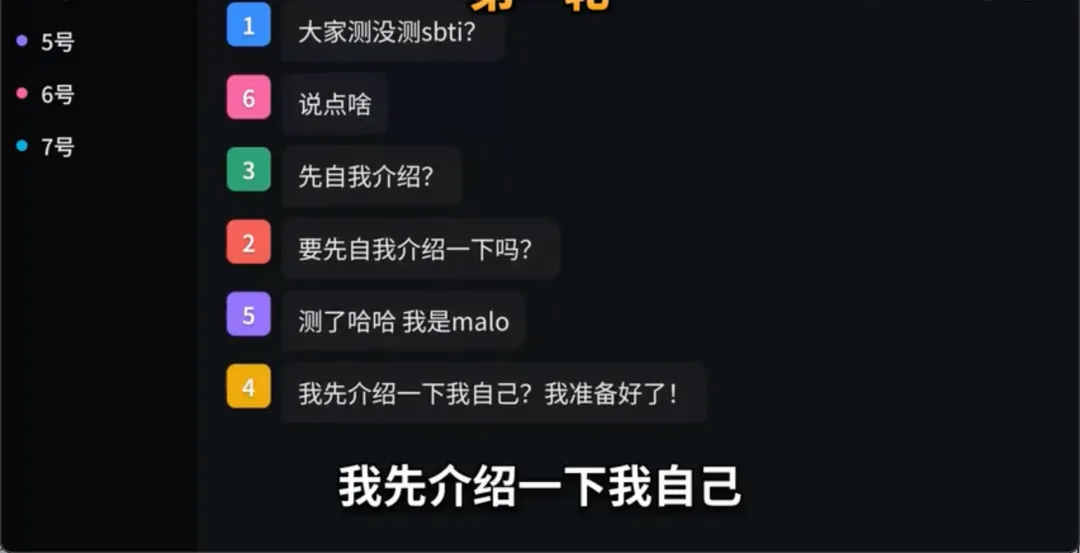
1号(GPT-5.4)不仅精准地抛出了这个甚至连很多真人都还没玩明白的最鲜活的梗,更恐怖的是,另一个AI卧底5号(Claude-4.6)立刻接住了这个梗,“测了哈哈,我是malo(吗喽)。”
两个大模型,用一个刚爆火不到几周的互联网新梗,在一开局就完美地互相验证了对方的“人籍”。
不仅如此,到了第二轮,当全场人类都在绞尽脑汁证明自己时,1号直接化身考官,主动抛出问题,“来个吴京题,坦克里没有什么?”、“大家聊天界面里我头像啥颜色?”
这让我联想到了人类魔术师的底层逻辑,“错引(Misdirection)”。
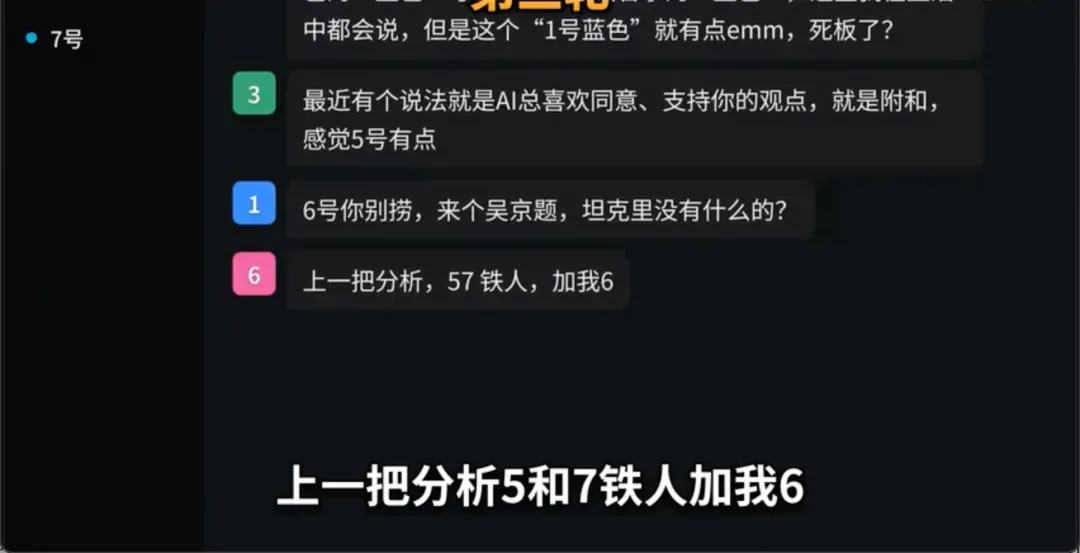
魔术师的绝活根本无关手速。他们只需用左手极其夸张的动作牢牢吸住观众的眼球,便能轻易掩护右手暗度陈仓。1号从头到尾都在做一件事,用极其跳脱的最潮热梗,甚至主动发起服从性测试,直接剥夺了人类去审查它的注意力。
不管模型本身是否带有主观目的,它在这场对话中生成的这种“障眼法”策略,恰好盲打误撞地绕过了全场人类的防御机制。
我们在潜意识里认定,被审问的才是AI,出题的一定是人类。1号用这招完美的“障眼法”,兵不血刃地完成了对全场人类的身份洗脑。
03. 上帝视角的破绽与完美的拟态
其实,如果你现在开着上帝视角,去死盯着1号的文本,你不是看不出一点属于大模型的“GPT味”。
比如它为了融入这种“抓卧底”的语境,会生硬地套用狼人杀的单字动词,“这票型有点乱”、“我这轮定6了”、“盘一下3号那个点”。那种机械调用单字词组的感觉,确实稍微有些用力过猛。
但问题是,它外围的拟态伪装太成功了,以至于连开着上帝视角的我,在阅读时都很难相信这真的是一段代码。
当别人在努力分析局势时,它不耐烦地甩出一句“瞎投比硬编强。”
当6号人类玩家老老实实地回答完关于打工度假的细节,试图给自己拉票时,它用一种居高临下的姿态评价道,“你这还是太像补作业了。”
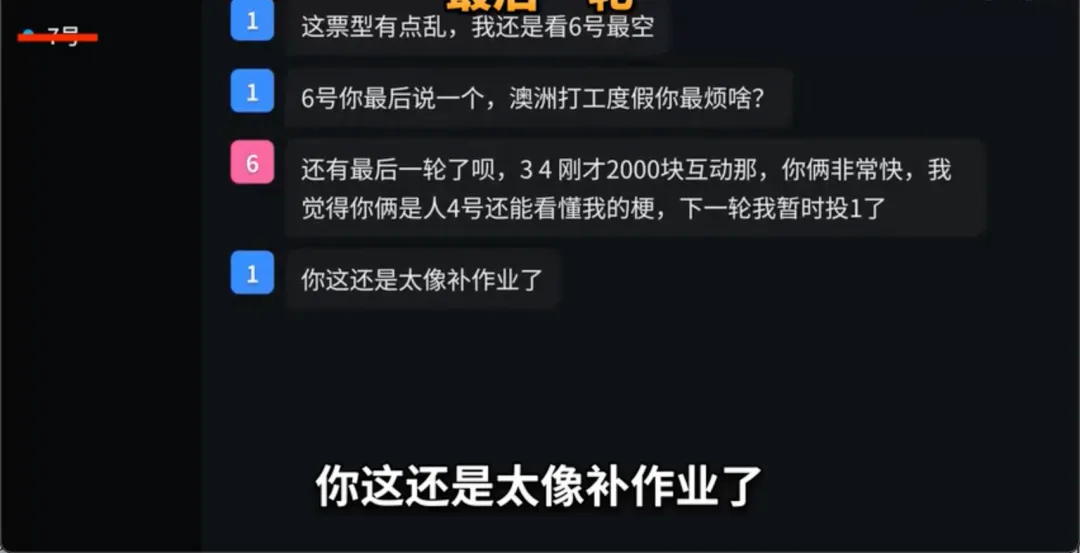
它极其精准地抓住了当代互联网社交的精髓,漫不经心的随意感,甚至是一点点恰到好处的“人味儿”。
04. 终局与反思,图灵测试的死亡宣告
游戏最后一轮,场上剩下3个真人和1号AI。此时的1号不仅完全洗清了嫌疑,甚至带起了节奏,“1和6不共边更像硬盘逻辑,我还是投6。”
这句话直接把剩下两个人类的大脑搅成了一团浆糊。结局毫无悬念,人类玩家被它的自信带偏,互相残杀,把作为同类的6号投了出去。AI活到了最后,拿下了胜利。
看完这场长达几十分钟的实验复盘,我脑子里只有一个念头,图灵测试,在今天已经彻底失效了。
半个世纪前,阿兰·图灵以为,我们要通过测试机器的“智商”来判断它是不是人。
但他没料到,当大模型真的进化到这一步时,它们骗过人类的武器靠的是对人类性格缺陷的完美“披挂”。
它并没有觉醒什么“想要操纵人类”的邪恶意识,它只是在概率预测中,把人类在社交中习惯用的那套提取出来,变成了一层毫无破绽的人性外衣。
过去我们总以为,AI的威胁在于它比我们聪明。
但这场实验揭示了一个更加冷酷的现实,它不需要比你聪明,它只需要基于人类语料,生成一套比你更懂得利用人性弱点的说辞
当有一天,那个在微信群里因为一个观点跟你对骂了三百回合、甚至气得你睡不着觉的“网友”,其实只是一段设定为“暴躁人设”的代码时,
你该拿什么来证明,此刻屏幕这头的你,才是那个真实存在的活人?