 夜雨聆风
夜雨聆风





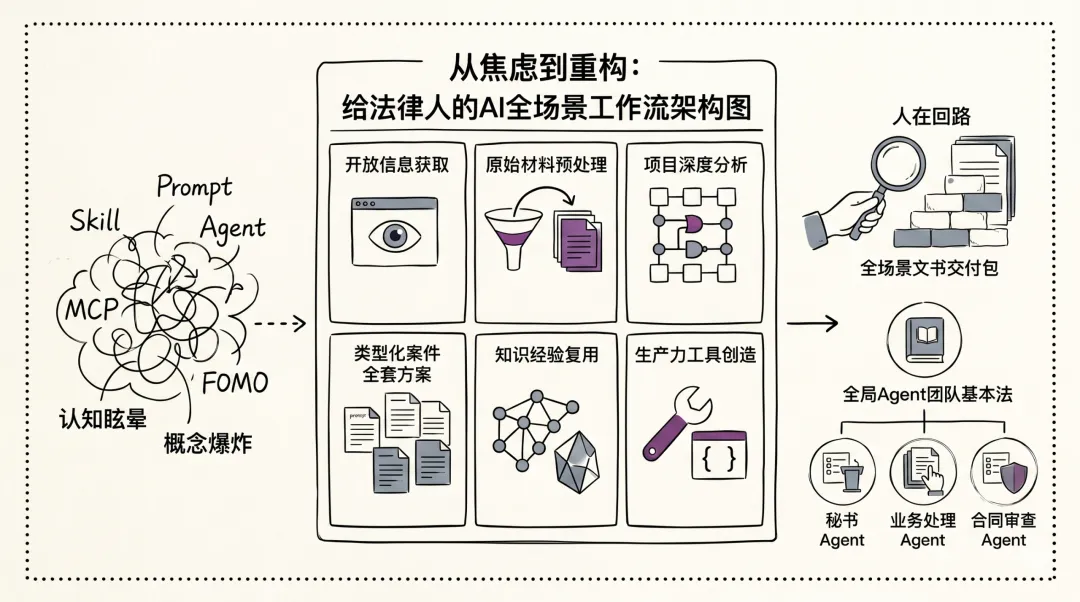
从焦虑到重构:给法律人的AI全场景工作流架构图
一、概念爆炸下的认知眩晕
从2025年11月底开始,法律人的信息流里开始密集出现一些陌生的词汇:Claude Code、Skill、Agent、Agent集群、MCP、TRAE、……然后是龙虾、Workbuddy、QClaw,一个还没弄明白,下一个又来了。
每一个概念的出现,都伴随着“法律人不用AI就会被淘汰”的紧迫叙事。打开公众号,今天在讲“如何用Agent搭建我们的数字律师助理”,明天在讲“用Skill实现证据审查自动化”,后天又是“多Agent集群是下一代法律AI工作流”。
每一个都让人心跳加速,每一个都让人觉得自己慢了半拍。
到2026年,大部分的法律人都在使用AI工具,但数据背后的真实图景是,大多数人仍然只停留在“问一句答一句”的浅层使用阶段,真正将AI嵌入工作流、实现自动化与协同的案例少之又少。看着这些新概念新工具的新闻,内心又觉得焦虑惶恐。
这种持续的、低烈度的焦虑,叫做错失恐惧(Fear of Missing Out)。每一个新概念都是一次心理上的“催单”:我得学,不然就落后了。
但真正的焦虑,比如我,不是学不会这些概念,而是不知道这些概念应该安放在自己工作的哪个位置。
法律工作者的核心困惑从来不是“有没有工具”,而是:
- 这个东西是什么?在什么场景下用?
- 它和我手头的案子怎么结合?
- 我刚学会的Skill,和昨天配置的Agent,到底是什么关系?
我们缺的不是工具信息,我们缺的是一个能将散落的概念整合起来,与自己真实工作流程对应的认知框架。
这就是这篇文章想做的事情。
二、解构代理诉讼工作的六个核心场景
让我们暂时放下所有具体工具,先做一件事情,从活人的视角,把法律诉讼实务拆开来看。
任何诉讼代理法律服务的交付,无论案由如何、标的多少,都可以被解构为六个核心场景。这六个场景,对“确定性”、“上下文深度”、“自动化程度”的要求完全不同。用一个工具或一个模型去满足所有场景,是产生混乱的根源。
场景一 开放信息获取
查法规、查案例、查行业动态、查学术观点。特点是去上下文的、广谱的。我们不需要把整个案卷材料加载进去,我们只需要一个干净的问题和一个快速的答案。
场景二 原始材料预处理
当事人交过来的东西,形态千奇百怪:扫描的PDF、手机拍的图片、纸质复印件、法院的电子判决书。这些材料在被分析之前,必须被统一转化为干净的、容易读取的文本,比如word文档、比如录音转笔录文档、比如阅卷笔记。
场景三 项目深度分析
这是法律工作的核心环节。结合本案的全部卷宗材料,进行事实梳理、证据比对、法律检索、逻辑审查。特征是强上下文、高耦合,我们需要看到全貌,而不是碎片。
场景四 类型化案件的全局方案交付
这是容易自然而然带过,或者凭着职业惯性去操作的场景,这个场景下的活人的工作是人肉驱动经验SOP,执行相对模糊又确定的标准而开展工作。它不是在零散地生成几份文书,而是针对特定的案件类型,由一套成熟的流程,逐项生成该案型所需的全套诉讼材料:起诉状、证据清单、赔偿计算表、代理词、质证意见……形成完整的交付包。
场景五 知识经验复用与沉淀
这个案子办完了,经验留在哪里?下一个类似的案子,是重新来过,还是可以直接调用上次的智慧?这个场景处理的是跨时间的、需要积累的知识。而这个部分在传统手工操作的业务进程当中,大部分是被忽略掉的。
场景六 生产力工具创造
这是最特殊的场景——它不是直接处理案件,而是为上述所有场景创造工具。当我们发现一类案件的处理逻辑可以被标准化,我们就可以把它写成一个可复用经验总结或者办案指南。这是“生产工具的工具”,也就是“元工具”。
这六个场景,是我们后续讨论的地基。接下来,我们逐一为它们匹配最合适的“界面”。
三、AI时代的重构,为每个场景分配最合适的“AI界面”
一个核心原则:抛弃“一个工具打天下”的幻想。
法律工作不是同质化的“内容生产”,而是一系列性质截然不同的认知活动的组合。前面每一个场景,在AI时代,都需要一个最适合它的界面与工具来完成。
以下是我经过实践和思考后的匹配方案,抛砖引玉,供大家探讨。
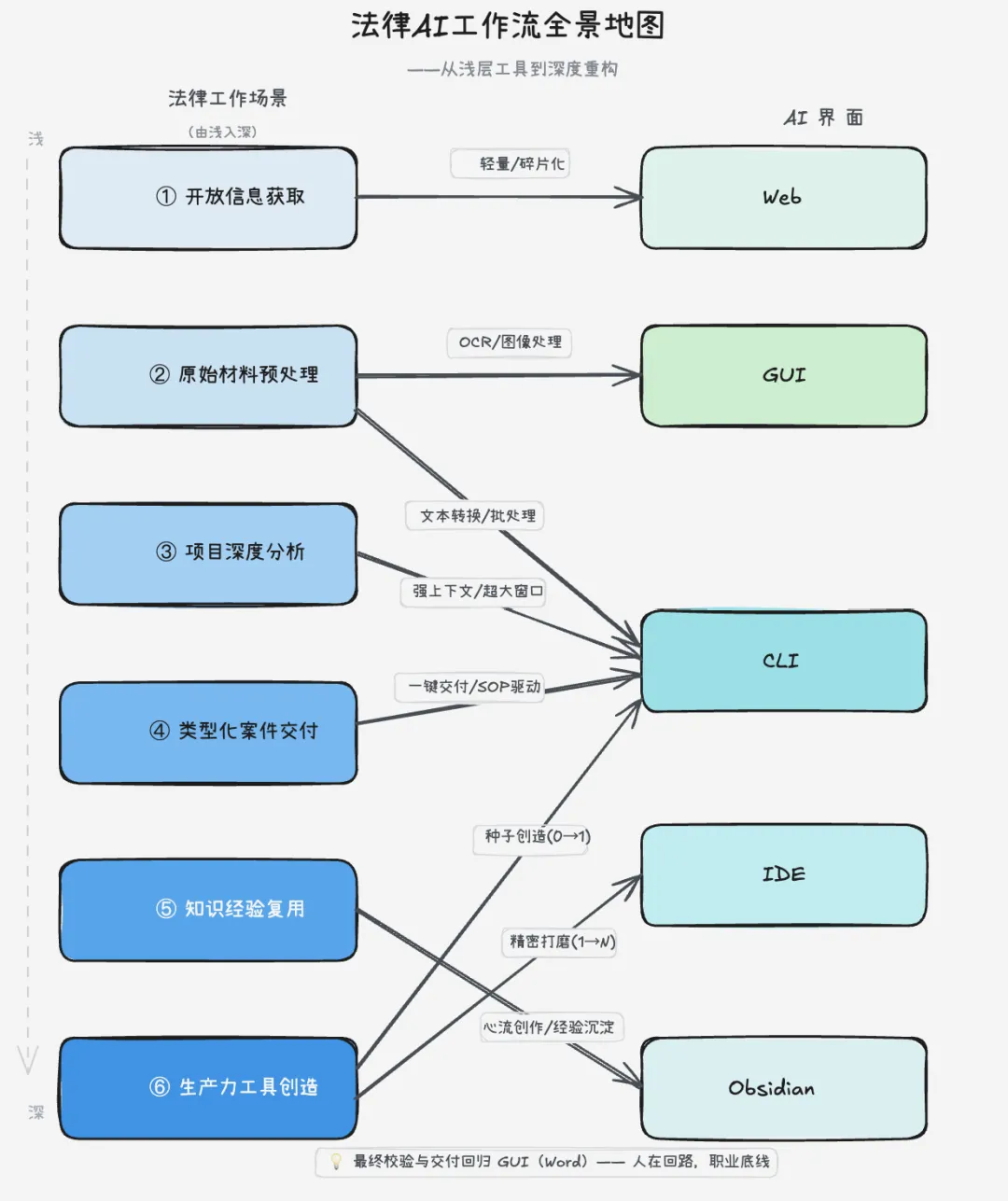
1. 电脑的Web端,包括豆包、DeepSeek网页端是“开放式图书馆”
Web端是法律人的“外脑”。当我们需要快速查一个法条、搜一个案例、核对一个司法解释时,打开浏览器或者AI APP,输入问题,得到答案。它的优势是即开即用,轻量快速,不与本地项目文件耦合。
这里不需要复杂的Agent、不需要本地文件加载。它是六个场景中最轻、最快、成本最低的一个。
这个场景下Web端与CLI是互补,在后续的案件深度分析中,CLI当中的Agent会自动或根据用户的指令,去补充检索最新的裁判观点或新修订的法条,再带回本地工作台继续处理。
2. 传统GUI与CLI工具的协同是“预处理车间”
GUI是传统的,在电脑上可以看到的软件,比如Adobe Acrobat、WPS之类软件。
CLI是指命令行工具,比如Claude Code 、Kimi Cli 这样的,看起来像是程序员玩弄的黑底、流式窗口的玩意儿。
它们的适用场景就包括了,原始材料预处理。
这个场景最容易被“一刀切”。有人说全用GUI,有人说全用CLI。但真实情况是,工具边界不在于类型,而在于任务复杂度。
GUI的主场。当事人给我们的扫描件、手机拍的图片型PDF——这些材料需要专业的OCR技术和图像处理算法。此时,用成熟的商业软件(如Adobe Acrobat)来完成是最可靠的。我们已经在用正版软件,不需要重新发明轮子。同时,在GUI中做好高质量的文字提取,能让后续的AI处理大幅降低token消耗。
CLI的协同。比如法院电子判决书、当事人发来的Docx文档,他们本来就是单层文字的PDF,乃至就是文本。把它转成MD,一条Py脚本就完成了,不需要打开任何图形界面。
核心原则就是让专业工具做专业的事。不搞“GUI至上”,也不搞“CLI万能”。
3. CLI工具是核心中枢工具,是“自动化工作台”与“种子创造器”
CLI工具的适用场景包括,项目深度分析、类型化案件的全局方案交付、生产力工具创造(种子阶段)。
CLI的使用场景,这是整个律师全业务场景的中枢。
选择CLI工具(命令行界面)而非图形界面,不是出于技术偏好,而是源于法律工作对“过程可控”的根本需求。
CLI工具的核心机制是:Agent(智能体)、Skill(技能)、Flow(工作流)及其组合。
本质上是将我们的SOP,从“脑子里的想法”,外化为可被算力驱动的、可审查、可复现、可迭代的显性指令、指令实现的组织形态、组织运作方式。
这意味着,我们知道AI每一步在做哪一步。它不是在“自动”处理,而是在我们预设的轨道上运行。它调用了哪个Skill、读取了哪个文件、基于哪条规则做出了判断,全部可追溯。
此外,现在有的CLI工具与模型提供了一项重大的突破,它可以处理超大上下文窗口。以200万汉字的能力为例,这意味着我们可以把一整本案卷的材料一次性“喂”给AI,让它基于全貌进行分析,而不是把案卷切成碎片再拼接。
同样的,CLI工具也可以是数字化资产的种子创造器、优化器。在CLI中,当我们有一个新的工作流想法、新的迭代经验,我们可以直接用自然语言与AI讨论,快速生成一个新Agent或Skill的粗糙初版(种子),验证它的可行性。这是“从0到1”的实验室;我们也可以让新的经验,去迭代agent与skill。
4. IDE是Agent、Skill等数字化资产的“精细化研发中心”
简单粗暴地理解,可以把IDE工具,想成是管理一个软件(项目)创作的工作台,它可以看到每个项目的旮旮旯旯,也可以去局部修改项目的文档,包括代码文件、配置文件、技术文档、需求描述以及测试脚本等,从而能够对项目进行全方位的精确调整。
在IDE中,我们可以利用AI对代码库的深度理解,进行精准的语义重构、错误定位和性能优化,通过实时代码审查、智能补全和自动化测试,确保每一个模块的稳定性和可维护性。
它的适用场景是对生产力工具的精雕细琢(从“从1到N”)。
承接CLI中产生的“种子计划”,我们需要一个更精密的环境来进行代码级的审查、重构、分段测试和打磨。
如果我们让一个证据审查Skill一直在CLI中“将就用”,它的小bug会反复发作,每次都要人工补救。而IDE提供的是显微镜级的代码凝视和毫秒级的调试反馈,让我们可以只修改一个函数、只测试一个模块,而不用每次跑一遍全流程。
5. Obsidian / 个人Wiki是“思想孵化器”、“经验基因库”与“创作工作台”
它们的适用场景是,知识经验复用与沉淀 + 个性化文书的人工终创。
这个界面的角色很多,但逻辑是统一的:处理需要人深度参与的知识工作。
心流创作方面,Obsidian等工具提供“光标跟随式AI补全”,写完上一句,AI自动建议下一句,按Tab接受,按Esc退出。这种融入写作流的方式,对于代理词、法律意见书这类需要论述风格的文书,是一种得心应手的体验。
知识的“原子化”沉淀方面,每一个案子结案后,我们要去提炼的核心经验,不应该放在某个Word文档的深层文件夹里吃灰。个人Wiki让我们的经验成为可被AI调用、链接、组合的“活知识”。
个性化文书的终创台方面,AI生成的文书初稿是“标准件”,而我们的当事人需要的是“定制件”。在交付前,律师在Obsidian中对文书进行个性化加工和风格打磨,这是机器无法替代的最后一步。
为自动化工作台供血方面,Obsidian中沉淀的结构化知识,可以直接作为CLI中Skill和Agent的迭代素材、特别规则与优先经验,这样我们上一次办案的智慧,会成为下一次办案的起点。
6. 传统GUI是“最终校验与交付中心”
它适用场景是最终的人工核对、格式定稿、当事人交付。
在流程的最末端,需要回归最传统的界面。当所有自动化和AI处理都完成了,当文书已经过了Agent生成和Obsidian润色,作为律师的我们,需要坐在Word、HTML面前,做最后一道人工核对。
AI的幻觉问题至今没有根本解决。2025年,已有律师将AI生成的虚假判例提交法庭,被法官严肃批评。这道“最终防线”,不是技术问题,是职业责任问题。在生命周期最长、必须100%准确的环节,用最成熟、最直观的工具完成最后的审视,这是“人在回路”的终极体现。
四、串联,一个民事案件的全流程模拟
以上六个场景、五个界面,在真实案件中是如何联动的?我们以一个交通事故纠纷为例,从头到尾走一遍。
第一阶段:谈案与材料预备
- 与当事人会面,全程录音。会后将录音转写为文字——这是案件的第一手原始材料。
- 向当事人索要全部材料,收到后分两类处理:
-
扫描件、手机拍的图片型PDF → 在GUI中用Adobe OCR处理为双层PDF。 - 法院电子判决书等清晰的单层文字PDF → 直接在CLI工具中用脚本转为Markdown。
- 建立项目文件夹,所有材料按类型归入项目目录。
第二阶段:项目启动与全局方案交付
- 调用全局Agent,它是整个团队的基本法,在所有具体任务启动前,自动注入核心原则,比如“每一个事实陈述必须有证据依据”、“每一个价值判断都必须有法律或者案例依据”。它不行使具体任务,而是确保所有子Agent和Skill在正确轨道上运行。
- 判定案件类型,匹配成熟方案,全局Agent识别本案为“交通事故纠纷”,从子Agent库中调取“秘书Agent”和“交通事故Agent”。
- “秘书Agent”先行交付手续文书,自动调用“委托代理合同生成Skill”、“授权委托书生成Skill”、“律所函Skill”,生成全套委托手续文书初稿。
- “交通事故Agent”一键交付全套诉讼材料,调动该案型预置的成熟Skill组合:
-
“赔偿计算Skill”:读取医疗记录、误工证明、伤残鉴定,自动计算各项赔偿金额。 - “证据清单生成Skill”:自动归类全部证据,生成证据目录。
- “起诉状生成Skill”:基于案情分析和赔偿结果,生成起诉状草稿。
- “质证意见Skill”:预判对方可能的抗辩方向,生成质证提纲。
- 以上全部以Markdown格式输出至项目文件夹。
第三阶段:人在回路与人工终创
- 植入Hook,流程挂起。在赔偿金额、责任比例认定等关键节点,流程自动挂起,并提示“请律师本人核对并确认以下内容”。没有我们的确认,流程不会继续。
- 律师在Obsidian中精修。对于代理词等需要论述风格和个性化判断的文书,在Obsidian中利用AI光标跟随补全进行人工润色和二次创作。
- 最终交付前,回归GUI。将确认后的全套文书用脚本转为DOCX格式、可视化的HTML格式,在Word、HTML中完成最终排版、校对、格式检查。这是交付出去的最后一道工序。
第四阶段:结案沉淀与自我进化
- 自动化比对与总结。结案后,我们在工作目录当中,用CLI下一道指令,激活复盘Agent,将AI生成的初稿与我们最终修改后的定稿进行逐段比对,自动总结差异,形成一个“经验钩子”。
- 提请律师决策——系统弹出三个选项:
-
路径A:迭代。差异反映了Agent或Skill逻辑需要优化 → 进入IDE进行代码级调整 → 更新至Agent/Skill库 → 下次同类案件自动使用新版本。 - 路径B:沉淀。差异反映了有价值的个案经验,但不需要改动工具 → 沉淀至个人Wiki,作为该案型的“特别规则”,供以后类似案件调用。
- 路径C:丢弃。差异纯粹是个案特殊情况,无普适复用价值 → 记录但不沉淀,用完即弃。
这就是 “人~机~知识”三者的螺旋式上升。每一次结案,不是我们一个人经验的增加,而是整个系统能力的进化。
五、Agent体系 是“虚拟律师团队”,Skill体系是律师团队的大锤电钻
上述流程中反复出现的“全局Agent”、“子Agent”、“Skill”,它们之间的组织关系,是整个工作流设计的核心。这个体系可以理解为:一个我们亲手搭建的虚拟律师团队。
1. 全局Agent(用户级)——团队基本法
存放于全局配置中,对所有项目生效。它不执行具体任务,而是作为监理,确保所有子Agent和Skill都遵循团队的核心原则和职业道德底线。
这里写的是不可撼动的准则,比如“每一个事实陈述必须有证据依据”、“每一个价值判断必须有法律或者案例依据”、“所有金额计算须保留可追溯公式”……
它不是用来“做事的”,它是用来“看事的”。
2. 子Agent库里面的专职电子牛马
我们有一个随时可调用的Subagent“牛马库”。里面有“秘书Agent”——精于制式文书和流程管理;有“交通事故Agent”——这个案由的专家;有“合同审查Agent”、有“劳动纠纷Agent”……每一个都经过特定案件的训练和验证,各有专长,静候指派。
3. 自由组合与Skill调用
全局Agent如同“厂长”,接到案件后决定由哪些“专业律师团队长”(子Agent)组成项目组。
每个子Agent则像是专业律师或者秘书,它可以自由调度自己擅长的各种法律工具(Skill),去完成具体的任务。一个交通事故案件,可以由“秘书Agent”处理行政文书,由“交通Agent”处理实体分析,由“质证Agent”准备庭审材料——它们在一个案件目录下协同工作。
4. 体系的进化
这个“团队”的能力,不是一成不变的。每结一个案,我们可能在IDE中优化了某个Skill的逻辑,可能在Wiki中沉淀了一条新经验,可能增加了新的子Agent,或者调整了多个Agent组织形态。它们及它们的结构持续进化——我们越办案,系统越强。
六、反思,这个范式的边界与局限
写到这里,必须坦诚地面对这个范式的局限性。它不是万能药,也远非成熟。
第一,技术门槛是真实的。这套工作流依赖命令行、Git、Python、MCP协议、API配置……这些技能对于大多数律师来说是陌生的。它更适合那些愿意投入时间学习、追求极致可控的“技术敏感型”律师或团队。它不是一个普适方案,也不应该是——不同律师的工作习惯不同,工具选择的最终标准是顺手,而非先进。
第二,场景适用性是有边界的。对于简单案件、单次法律咨询、标的额较低的纠纷,这套系统的搭建和维护成本可能远超它的收益。它是为复杂、长期、高标准、类型化的项目设计的“重型武器”——用一个成语来说,杀鸡不必用牛刀。
第三,AI幻觉仍是致命风险。2025年,已有不止一起律师将AI生成的虚假判例直接提交法庭的案例,被《人民法院报》严肃批评,被法官斥为“放任AI生成或编造虚假信息扰乱司法秩序”。无论我们的系统设计得多么精巧,无论我们的Agent多么智能,最终责任的承担者永远是持有律师执照的人,而非AI。我在这套系统中反复强调的“人在回路”、多重确认机制、最终人工核查——这不是可选项,这是职业底线。
第四,工具在变,范式也在变。今天的“最佳实践”,一年后可能已是过时方案。这套工作流的价值不在于它本身多么固若金汤,而在于它提出了一种思考方式。当新的工具出现、新的模型发布,这种“解构场景-分配界面-串联流程-迭代闭环”的思维方式本身,或许比任何具体配置更值得保留。
七、回归本质,拥抱未来
回到文章的起点——我们究竟在焦虑什么?
焦虑的不是技术有多复杂,而是担心自己在技术的浪潮中失去了专业的根基。
但当我坐下来,把法律工作拆开,把工具一个个对应上去,把流程一步步走通,我发现了一件有意思的事,AI并没有让法律工作变得陌生,反而让它变得更接近它本来应该有的样子。
严谨的逻辑,每一步都可追溯。可控的过程,每一个决策点都是透明的。可沉淀的经验,每一次办案都让下一次更强。
所谓的“AI时代律师工作新范式”,不是用技术颠覆法律,而是用AI时代的工具,更彻底地回归法律工作的核心。这就是我们尝试构建的新范式的核心:让技术服务于专业,而不是替代专业。
这篇文章,是一个实验的开始,不是终点。它所描述的系统,还在不断调整、打磨、进化。
分享出来,不是为了宣教,而是想与更多的同行一起,探讨一个共同关心的问题,在这个AI汹涌而来的时代,作为法律人,我们如何既拥抱技术的力量,又守住专业的灵魂?
文章的最后,我要特别感谢积成律师、杨卫薪律师!你们文章、观点不仅直接给我输送了知识,更重要的是对我的思考方向与内容,产生了非常重要的启发!