 夜雨聆风
夜雨聆风





AI情感处理模型|DuSE:结合语境,语义,面部表情,识别人类情绪表达
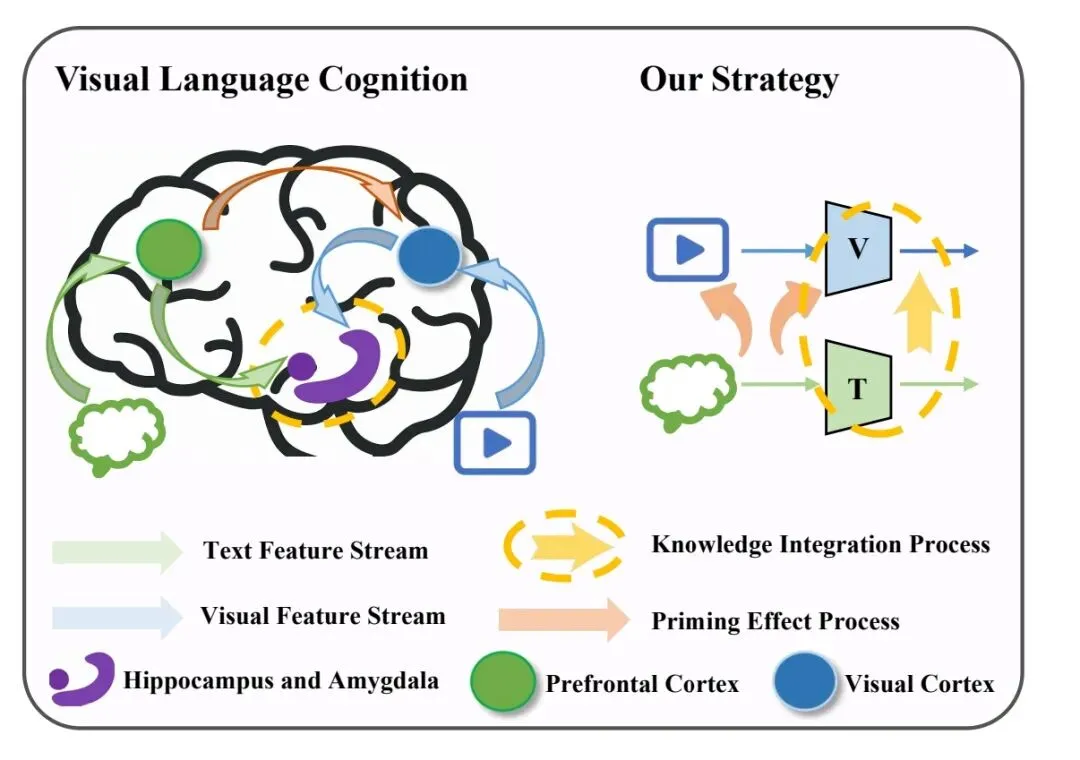
我们平常识别他人情绪时,不光依靠观察面部,还会结合对话语境、表达内容来综合判断,大脑里的特定区域也会快速对接收到的面部表情做出反应,不仅能识别出情绪,还能推测对方产生情绪的原因,也就是我们所说的共情。
现在研究人员模仿人脑这套工作逻辑,开发出了动态面部表情识别(DFER)技术,这项技术已经应用在很多领域:
– 医疗场景中,可以通过分析抑郁症、自闭症患者的面部微小表情,辅助医生评估患者的情绪健康状态;
– 服务机器人交互中,可以识别出用户是微笑还是满面困惑,自动调整对话策略,让服务体验更贴心;
– 智能驾驶场景中,车载系统可以监测驾驶员状态,如果识别出驾驶员存在疲劳相关的面部状态,就会触发警报,甚至自动停车来保障安全。
实际上人脑识别情绪是多模块配合的:语言提示可以帮助我们更快完成表情分类,还会结合过往积累的知识经验,多个脑区协同处理信息。因此现在研究方向转向了「多模态」策略,以此提升识别的稳定性,更贴近人脑的识别逻辑。
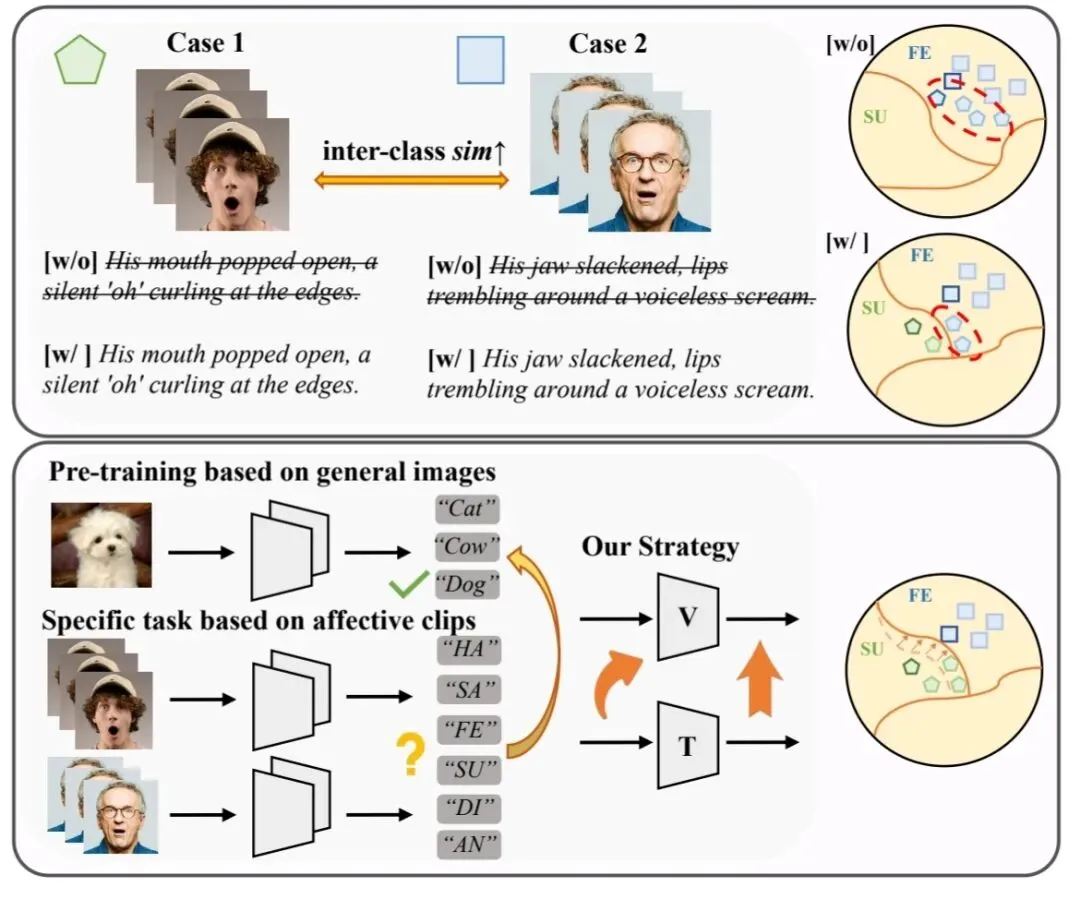
CLIP经典预训练模型,可以通过大量图文数据,把视觉信息和语言信息映射到同一个语义空间,还能直接识别未见过的图片,但用来做动态情绪识别存在三个明显缺陷:
1. 仅能对齐静态图片和文字,无法捕捉表情的动态变化过程,类似嘴角逐渐下垂这种变化过程就无法捕捉;
2. 只是通用型的图文关联模型,没有针对情绪感知做优化,不符合人脑识别情绪的逻辑;
3. 调整模型参数时需要改动整个模型的权重,必须依赖大量标注好的数据才能正常使用。
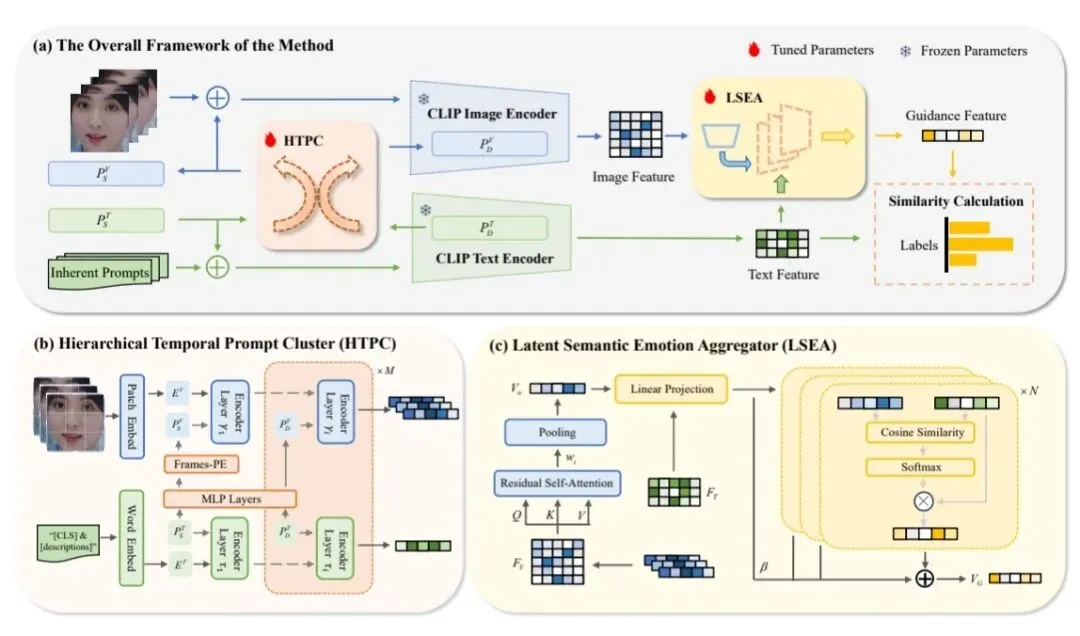
而本次提到的DuSE模型,刚好解决了CLIP的这三个问题,核心做了四项优化:
1. 捕捉表情的动态变化:将CLIP的整段文字提示拆分为按时间排序的片段,比如拆分为「嘴唇颤抖→嘴角下垂→恐惧表情」,再让视频每一帧和对应的文字描述精准对齐,就可以捕捉到表情的完整变化过程;
2. 结合情绪知识完成推理:模仿大脑记忆的运行机制,将CLIP提取出的视觉特征(比如识别出“张嘴”这个动作),和对应的情绪语义(比如“恐惧”)动态关联,沿着「面部动作→视觉识别→知识匹配→输出情绪」的逻辑完成推理,和人脑的思考逻辑保持一致;
3. 少量标注数据即可适配新场景:仅需要用自然语言编写提示就能激活CLIP的跨模态能力,依靠“提示+知识”双通路就能适配新场景,所需的标注数据量仅为原有方法的十分之一;
4. 识别结果逻辑可追溯:它可以展示出是哪部分面部特征触发了最终判断(比如“颤抖的嘴唇”激活了对应“恐惧”的识别单元),判断逻辑符合认知科学,结果清晰透明。
最终测试结果显示,和微调后的CLIP相比,DuSE在通用动态表情数据集Wild DFER上,跨模态识别效率提升,刚好解决了CLIP无法捕捉动态变化、缺少情绪领域知识、依赖大量标注数据这三个核心问题。
*声明:本账号只作为信息搬运工使用,旨在提供客观信息参考,不构成任何消费建议或专业指导。若有疑问,欢迎沟通交流。