AI编程的最大误区:我们在升级模型,而他们在升级环境
读完这篇,企业IT程序员能把”先立规矩再用AI”的反直觉逻辑说清楚,并能起草一份驾驭AI生成代码的架构约束清单,而不需要等待公司搞大规模AI转型试点。 一、这个实验,颠覆了我对AI编程的所有假设 2025年8月,OpenAI内部一支只有3人的工程团队,做了一个近乎疯狂的决定。 他们规定:从第一行代码开始,不手写任何一行代码。
5个月后,他们交付了一个被数百名OpenAI内部员工每天使用的软件产品。代码仓库里有大约100万行代码 ,覆盖范围包括:应用逻辑、测试、CI配置、文档、可观测性工具,以及所有内部开发工具。
而且,他们估计完成这一切所花的时间,只有手写代码方式的十分之一。 (来源:OpenAI Harness Engineering Blog)
这不是PPT里的数字。这是该团队工程师Ryan Lopopolo在2026年3月发布的工程博客中,亲自记录下来的数据。 当这支团队后来扩大到7人时,更令人困惑的事情出现了:
平均每位工程师每天合并3.5个Pull Request——而且随着团队规模扩大,这个吞吐量非但没有下降,反而还在增长。 (来源:OpenAI Harness Engineering Blog)
先停在这里想一秒:在你的团队里,每人每天产出多少个有意义的PR? 这篇文章,是我读完这篇工程博客后,从其中提炼出来的10个反直觉发现。有些结论,和大多数企业程序员的直觉完全相反。 二、工程师的角色,被彻底重新定义了 反直觉法则一:这支团队最重要的转变是:工程师的主要工作不再是写代码,而是设计”让AI能写好代码的环境”。 他们发现,早期进展慢不是因为AI能力不足,而是因为环境还没准备好——AI缺少必要的工具、抽象层和内部结构。
把大目标分解成小的构建单元(设计、编码、评审、测试等),让AI逐步构建这些单元,再用这些单元去解锁更复杂的任务。
反直觉法则二:当某件事失败时,解法几乎从来都不是”再试一次”——而是先找到缺失的能力,把它变成AI可以理解和执行的形式。 这句话非常值得反复读:“解法几乎从来都不是’再试一次’。” InfoQ 2025年终AI Coding盘点的一篇文章,从国内视角印证了同样的规律:AI agent宁愿从零开始实现功能,也不复用已有库——因为对模型来说,”自己写一个能跑的版本”风险最低。解决这个问题,不是换更好的模型,而是建立”必须复用已有模块”的架构约束。 ❓问题 :为什么同样的AI工具,不同团队产出差距那么大? 💡概念 :AI的输出质量,由运行环境的质量决定,不只由模型能力决定 🔧操作 :把”AI为什么生成了这段糟糕的代码?”改成”环境里缺少什么让AI走偏了?” ✅验证 :下次你在修AI生成的bug时,停下来问:这个问题能不能通过加一条Lint规则来预防? 三、你那套”烦人”的架构规范,才是AI的真正燃料 大多数企业程序员的本能是:严格的架构规范会拖慢AI工具的引入速度。
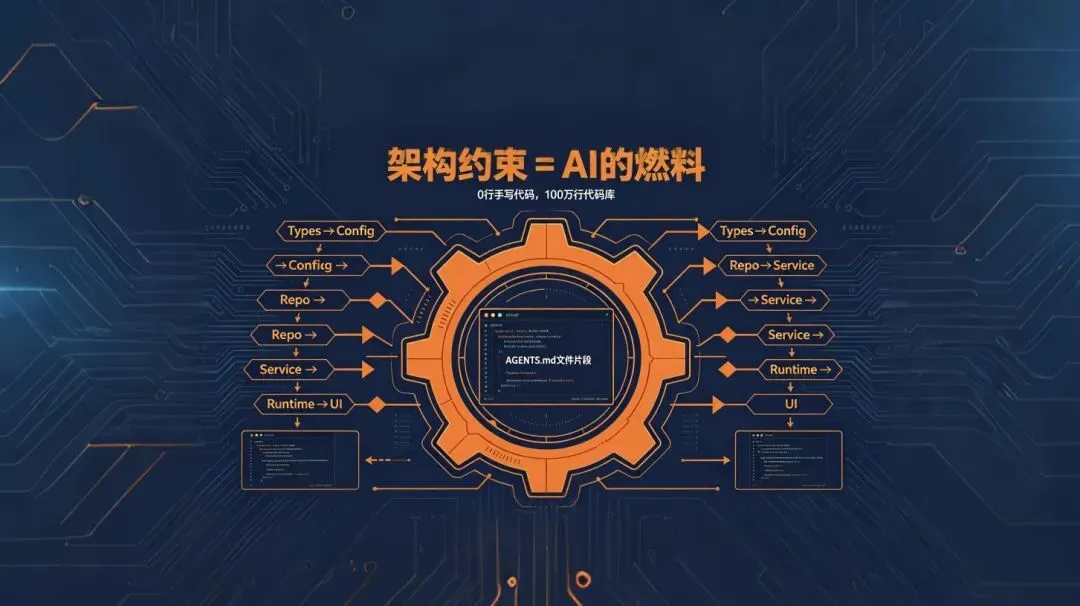
反直觉法则三:“文档约束不足以保证一个完全由AI生成的代码库保持内聚性。通过强制执行不变量(invariants),而不是微观管理实现细节,我们让AI能够快速交付,同时不会侵蚀架构基础。” 反直觉法则四:“这是那种通常要等到有了数百名工程师才会考虑的架构。但在有了coding agent之后,它是最早期的前提条件。约束,才是让速度和架构稳定性并存的根本原因。” 以前,架构规范是”以后再说”的事。现在不行了。有了AI,混乱的代码库会被以10倍速度复制成10倍混乱的代码库。 为每个业务域定义固定的代码层次(Types → Config → Repo → Service → Runtime → UI),用自定义Linter强制执行依赖方向 写的是”不变量”,不是”实现规范”——比如”每条日志必须携带预定义的必填字段集合 (如trace_id 、service 、severity ),由 schema 静态校验。”,而不是”日志要用log4j” Linter的报错信息被专门设计成对AI可读的修复指引 ,让AI看到报错就知道下一步如何改 反直觉法则五:“你们深度关心边界、正确性和可复现性。在这些边界之内,允许团队(或agent)在表达解决方案时有相当大的自由度。” 不规定AI用哪个库,但规定它不能跨越哪些层次边界。 这和VentureBeat报道的EY案例高度吻合:EY开发团队将AI agent接入内部工程规范和合规框架后,实现了4-5倍的编程效率提升 。脱离规范的agent,只能产出需要大量返工的通用代码。 架构约束是约束AI的”笼子”?不,它是AI的导航系统 。 四、AGENTS.md:它是目录,不是百科全书 他们一开始也尝试过”一个大AGENTS.md”方案——把所有规范都写进去。失败了。失败原因有四: 上下文是稀缺资源
:一个巨大的指令文件会挤占任务本身、代码和相关文档的空间 当所有事情都”重要”时,什么都不重要
文档即刻开始腐烂
:agent分不清什么还有效,人也懒得维护,整个文件变成”吸引人的麻烦” 单一文件无法做机械化校验
反直觉法则六:“所以我们不把AGENTS.md当百科全书,而是当目录(table of contents)。” 具体的结构:AGENTS.md大约100行,只充当指向其他知识源的地图;真正的知识库在结构化的docs/ 目录里,包含设计文档、执行计划、产品规格等。 反直觉法则七:“从agent的角度来看,任何它在运行时无法访问的信息,实际上等于不存在。” 这句话对企业IT程序员尤其刺耳——因为你们积累了十年的系统知识,散落在Confluence、邮件链、群聊记录和老员工的脑子里。对AI代理来说,这些知识全部等于不存在 。 那次Slack上对齐了架构决策的讨论?没有写进代码仓库,对AI来说就跟不存在一样——就像三个月后新入职的工程师永远不会知道那次讨论一样。 ❓问题 :为什么AI总是”不了解”你们系统的特定规则? 💡概念 :AI只能使用它在上下文窗口里看见的信息;看不见的等于不存在 🔧操作 :打开AGENTS.md,删掉超过20%的内容(那些移到docs/目录),把剩余部分改成”指向其他文档的导航地图” ✅验证 :一个新入职的工程师看了AGENTS.md,能在3分钟内找到任何他需要的文档吗? 五、瓶颈迁移了:从”写代码”变成了”QA处理量” 随着AI代码吞吐量增加,这支团队遇到了一个完全意料之外的新瓶颈。 反直觉法则八:“随着代码吞吐量的增加,我们的瓶颈变成了人工QA处理量。” 这个转变意味着:当AI产出速度远超人类消化速度,人力时间和注意力成为全新的稀缺资源。 他们的解法不是招更多测试人员,而是把QA这件事也变成AI能做的事: 让app可以按git worktree各自独立启动,AI能为每个变更运行独立实例 把Chrome DevTools Protocol接入agent运行时,让AI能自己驱动浏览器做UI验证 将日志、指标、链路追踪全部暴露给本地可观测性技术栈,让AI能用LogQL和PromQL查询自己代码的运行状态 反直觉法则九:“在某些情况下,让agent重新实现一部分功能,比费力调用某个公共库的不透明行为,成本更低。” 企业程序员的本能是”重复造轮子!”。但在AI编程环境下,逻辑不同了:让AI能完整理解、验证和修改的代码,比依赖一个对AI不透明的外部依赖更有价值。 他们的例子:用自实现的map-with-concurrency helper替换p-limit 这类第三方包,因为自实现版本完全集成了OpenTelemetry追踪,有100%的测试覆盖,行为完全符合运行时预期。 六、重新定义研发节奏:修正比等待更便宜 反直觉法则十:“代码仓库以最少的阻塞性合并门控运行。Pull Request是短暂的。测试偶发失败通常用后续运行来解决,而不是无限期阻塞进度。在一个agent吞吐量远超人工注意力的系统里,修正是廉价的,等待是昂贵的。” 这和传统企业IT的PR流程完全相反——通常是:代码评审 → 测试评审 → 安全评审 → 合并,每一环都可能等上几天。 当AI能持续以每人每天3.5个PR的速度产出,阻塞性流程的成本会急剧放大。 他们的做法是:将大部分评审工作交给agent-to-agent处理,只在需要人类判断时才升级到人工审核。人类负责设定优先级、把用户反馈翻译成验收标准、验证最终结果。 他们还建立了定期运行的”文档园丁agent”——持续扫描过时或不再反映真实代码行为的文档,自动开PR修复。 技术债就像高息贷款:持续分批偿还,远比积累后集中爆破代价更低。 七、给企业IT程序员的三个今天就能做的动作 读到这里,你可能在想:这些是OpenAI精英团队在全新项目上做的实验,跟我的业务场景有什么关系? 关系是:这些反直觉法则,在企业IT场景下反而更容易落地——因为你已经拥有”架构约束”这一核心原材料。 Stack Overflow在2026年3月的一篇博文里说了一件有趣的事:在引入AI coding agent时,“拥有成熟代码规范的企业,具有显著的先发优势” 。 你们那套有时候让人觉得”烦人”的架构规范、代码审查标准、命名约定——这正是AI代理需要的导航系统。你不需要从零开始,你只需要把已有的规范”执行化”。 三个今天就能开始的动作:
把现有规范变成可执行的Lint规则 :找出团队规范文档中最重要的3条原则,把它们转化为Linter规则(可以让AI帮你写),让规则在CI里强制执行,而不是靠人工记忆。重写AGENTS.md(或等效文件) :不超过100行,只写”这里有什么、去哪里找”,删掉所有具体的实现指引(那些放到docs/ 目录)。定义一个”不可逾越的边界” :选一个最重要的架构约束(比如”禁止Service层直接调用数据库,而用Repository 层独占数据库访问权”),写一个架构测试来验证它,然后让AI去维护这个测试。写在最后:纪律迁移了,没有消失 Harness团队的实验揭示了一个比”AI能写代码”更深层的道理: 软件工程的纪律没有消失,它只是迁移了——从代码本身,迁移到了为AI生成代码服务的脚手架里。
以前,这个纪律体现在一行一行优雅的代码里。现在,它体现在架构约束、知识库结构和反馈闭环的设计里。 工具变了,但工程师最核心的工作没有变:让复杂系统在约束内,可靠地运行。 如果你也在用AI coding工具,欢迎在评论区聊聊你们团队目前面临的最大挑战:是AI生成的代码质量不稳定?团队规范难以落地?还是已经踩过某些你愿意分享的坑?
参考资料
Ryan Lopopolo(OpenAI).Harness engineering: leveraging Codex in an agent-first world. 2026-03-11. InfoQ.AI Coding 2025年终盘点:Spec正在蚕食人类编码,Agent造轮子拖垮效率,Token成本失控后上下文工程成胜负手. 2025-12-31. VentureBeat.EY hit 4x coding productivity by connecting AI agents to engineering standards. 2026. Stack Overflow Blog.Building shared coding guidelines for AI (and people too). 2026-03-26.
 夜雨聆风
夜雨聆风