 夜雨聆风
夜雨聆风





AI学界的一个"皇帝新衣":27%的性能提升,有75%是注水的
AI学界的一个”皇帝新衣”:27%的性能提升,有75%是注水的
最近读了一篇让我后背发凉的论文。
不是因为它提出了什么惊天动地的新方法,恰恰相反,它做的事情是”打假”。它用一组扎实的实验数据证明:过去两年,数据集蒸馏领域里那些被顶会接收、被大肆宣传的性能提升,大部分是假的。
不是数据造假,是比数据造假更隐蔽的东西:评估标准不统一。
先说说什么是数据集蒸馏
如果你训练过AI模型,你一定知道,训练数据越多,模型通常越强。但问题是,数据多了,训练成本也跟着暴涨。ImageNet-1K有超过120万张图片,用这些图片从头训练一个模型,没几张高端显卡根本搞不定。
于是就有人想:能不能把120万张图片”浓缩”成一小撮,比如每个类别只保留10张,总共1万张,然后用这1万张图片训练出来的模型,和用120万张训练出来的差不多?
这就是数据集蒸馏。
打个比方。你要准备一场考试,课本有1000页。数据集蒸馏做的事,就是帮你提炼出10页精华笔记。这10页笔记不能覆盖所有知识点,但学完之后,考试成绩不能差太多。
听起来很美好对吧?
过去两年,这个领域确实非常火热。各种新方法层出不穷,论文一篇接一篇,性能记录一次又一次被打破。从SRe²L到CDA,从RDED到EDC,每一篇都在说自己比前人强了多少。
但这篇论文告诉我们:这些”提升”里,有很多经不起推敲。
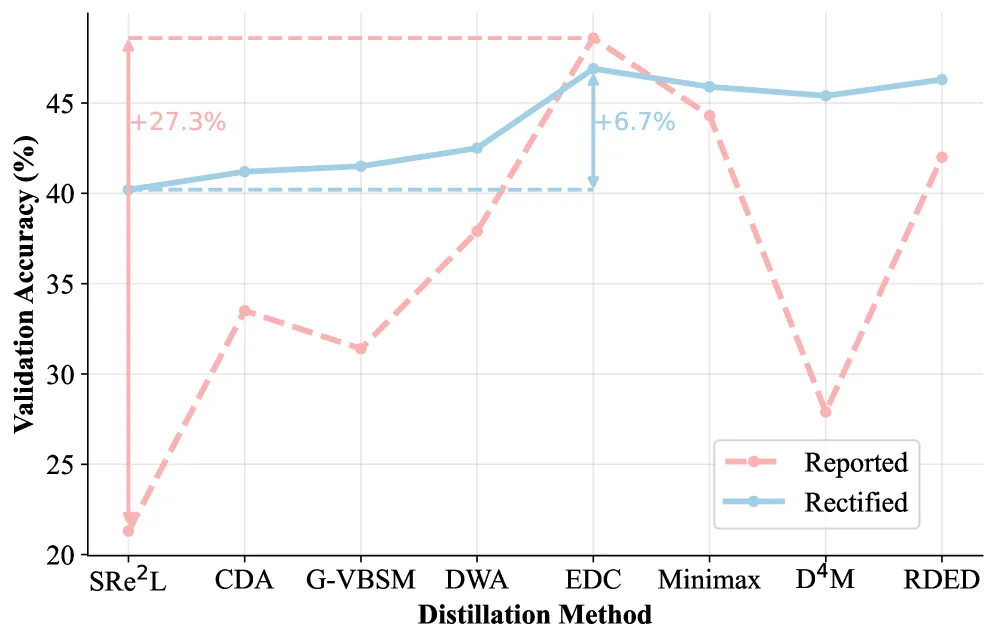
一个27%的提升,实际只有6.7%
论文的标题叫”Rectified Decoupled Dataset Distillation”,简称RD3。来自哈尔滨工业大学(深圳)、鹏城实验室和清华大学的研究团队。
他们做了一件很简单但很费力的事情:把所有主流方法放在同一个测试标准下,重新跑一遍。
结果令人震惊。
在ImageNet-1K这个最权威的图像识别数据集上,各方法之前报告的性能差距高达27.3%。比如说,EDC方法声称自己比最早的SRe²L方法高出了一大截。
但当RD3把所有方法统一到相同的测试条件后,这个差距直接缩水到了6.7%。
也就是说,27.3%的”提升”里,有大约四分之三不是来自方法本身的进步,而是来自评估设置的差异。
这就像一场跑步比赛,有人说自己比对手快了30%。但仔细一看,他穿的是专业跑鞋,跑道是下坡路,计时器是他自己带的。把条件拉平,他只快了7%。
差在哪?一个参数就能差出10%
具体差在哪?
论文逐一拆解了这些”隐形加成”。
第一,批量大小(Batch Size)。 最早的SRe²L用的是1024,后来的方法偷偷改小了。RD3发现,把批量大小统一改成50,几乎所有方法的准确率都能提升将近10%。这个提升和你的蒸馏方法好不好没关系,纯粹是训练参数的功劳。
第二,学习率衰减策略。 有的方法用标准余弦退火,有的加了平滑因子,还有的根据不同数据集手动调参。调得越精细,分数越高。但这分数高,是调参的功劳,不是蒸馏算法的功劳。
第三,数据增强策略。 CutMix、随机裁剪、随机翻转、Patch交换,各种增强手段叠加使用。策略越激进,性能越好。但问题是,这些增强手段对所有方法都有帮助,你用了不给别人用,这就是不公平比较。
第四,软标签的生成方式。 有的方法用单个教师模型生成软标签,有的用多个教师模型的混合软标签。混合软标签普遍更强,但有些方法只在论文里给自己的方法用了混合标签,基线方法却用的是单教师标签。
这些差异单独看都不大,但叠加在一起,就是27.3%和6.7%的差距。
最扎心的发现:随机图片居然能赢
如果说上面的发现让人警醒,那接下来这个发现就真的扎心了。
RD3团队做了一个实验:不用任何蒸馏方法,直接从原始数据集里随机抽图片,配上教师模型生成的软标签,然后训练。
结果在CIFAR-10、CIFAR-100、ImageNette和ImageNet-1K这些数据集上,随机抽出来的图片训练的模型,居然超过了所有精心设计的蒸馏方法。
你没看错。费尽心思蒸馏出来的”精华数据”,还不如随便抽的图片管用。
为什么?因为在大规模数据集上,教师模型的软标签本身携带了大量知识。只要图片足够多样,软标签就能把知识”灌”进学生模型。随机抽的图片天然就有最大的多样性,反而最配合软标签发挥作用。
这就像老师讲课,学生只要坐得住、听得进,用什么课本反而不那么重要了。老师讲得好(软标签质量高),比课本选得好(蒸馏方法精巧)更关键。
当然,在细粒度数据集(比如ImageWoof,专门区分不同品种的狗)上,蒸馏方法确实还是比随机采样强。因为这些任务需要高度代表性的图片,不是随便什么图都能撑得住。
数据集蒸馏的三条路线
为了让你更清楚这个领域的格局,我简单介绍一下目前的三种主要方法。
第一条路线:优化合成。 用一个训练好的模型当”老师”,然后从零开始,一个像素一个像素地”画”出合成图片。画的标准是:这些图片的统计特征(比如批量归一化层的均值和方差)要尽量接近原始数据集。SRe²L、CDA、G-VBSM、DWA、EDC都属于这一类。
第二条路线:生成合成。 用扩散模型(就是和Midjourney、Stable Diffusion同类的模型)直接”生成”新的图片。代表方法是Minimax和D4M。好处是生成的图片多样性天然就高,坏处是生成过程很慢,而且有时候生成的图片和目标类别关联性不强。
第三条路线:选择裁剪。 不生成新图片,而是从原始数据集中找到最能代表每个类别的图片区域,裁剪下来,拼成合成数据集。代表方法是RDED。优点是速度快、成本低,缺点是在低压缩比(图片很少)的时候多样性不够。
RD3的公平评估表明:没有一种方法在所有场景下都赢。 在高压缩比(每个类别只保留1张图)时,不同方法各有千秋;在低压缩比(每个类别保留100张图)时,性能差距更小,但计算时间差距可以达到100倍。
为什么这篇论文重要
你可能会说,这不就是一篇”打假”论文吗?有什么大不了的?
大在两个地方。
第一,它暴露了AI研究中的一个系统性问题。 当一个领域发展很快、论文很多的时候,大家都在争着刷分、抢排行榜。为了多几个百分点的提升,什么手段都上。调参、换评估策略、选对自己有利的数据集,这些都变成了”常规操作”。但从来没有人系统地追问:这些提升到底是真进步,还是统计噪声?
RD3做了这件事。结论是:在这个领域里,大部分所谓的”进步”经不起公平检验。
第二,它给出了一个建设性的解决方案。 RD3不只是批评,它建立了一套标准化的评估框架,包括统一的批量大小、学习率策略、数据增强方式、软标签生成方式。所有方法在同一个框架下比较,分数才是真分数。
而且,RD3还发现了一些真正有用的通用技巧。比如说,用多个教师模型的混合软标签,可以让所有方法都受益;用更好的初始化(比如从RDED的输出开始),可以让优化类方法的性能大幅提升。这些才是值得花精力研究的方向。
这对我们意味着什么
我自己在做智能体系统的开发,也关注AI领域的前沿研究。这篇论文给了我几个提醒。
第一,看到”XX方法比YY方法提升了N%”的标题,先别激动。 看看它们的评估条件是不是一样的。不一样的话,这个N%基本可以打折。打完折再看值不值得关注。
第二,标准化很重要。 无论是做研究还是做工程,公平比较是进步的基础。没有公平比较,你永远不知道自己是在前进还是在原地打转。
第三,有时候”笨方法”就够了。 随机采样配上好标签就能赢过精心设计的蒸馏方法,这说明在AI领域,简单粗暴往往被低估了。与其花大力气设计精巧的算法,不如先把基础做好。
数据集蒸馏这个领域方向是对的。用更少的数据训练出更强的模型,这在算力有限的场景下(比如私有化部署、边缘计算)有巨大的实用价值。但方向对不代表路径对。
RD3这篇论文的价值,不在于它提出了什么新方法,而在于它让这个领域慢下来,回头看了看自己走过的路,发现有些路其实是绕了弯的。
慢下来检查方向,有时候比埋头赶路更重要。
参考:
-
Rectified Decoupled Dataset Distillation: A Closer Look for Fair and Comprehensive Evaluation