 夜雨聆风
夜雨聆风





OpenAI携手五巨头开源革命性超算协议:一举解决超大集群LLM训练不稳定和网络性能难题

OpenAI联手英伟达、AMD、微软、Broadcom、英特尔,搞出了一个新的超算开放网络协议,叫MRC(Multipath Reliable Connection,多路径可靠连接)。
今天,MRC规范通过Open Compute Project(OCP)正式向行业开放。
https://openai.com/index/mrc-supercomputer-networking/
MRC:
https://www.opencompute.org/documents/ocp-mrc-1-0-pdf
为什么需要MRC
在星际之门之前,OpenAI已与合作伙伴历时数年,共同开发、部署并维护了三代超级计算机。这段经历让OpenAI深刻认识到,要在Stargate这样的规模下高效使用算力,必须重新思考并大幅降低整个技术栈每一层的复杂度,网络设计也不例外。

训练大模型,每一步都可能涉及数百万次数据传输。只要有一次传输延迟,影响就会在整个训练任务中扩散,让GPU白白等待。网络拥塞、链路故障、设备故障,是造成这类延迟的最常见原因。
问题还会随着集群规模的增大变得更严重、更难解决。
OpenAI面临两个核心挑战。
第一,尽量避免网络拥塞。虽然部分瓶颈无法消除,比如两块GPU同时向同一目标发送数据,但其他情况下的拥塞可以通过设计来规避。
第二,把网络故障对训练任务的影响压到最低。在足够大的规模下,即使是最优质的网络,也会持续出现链路和交换机故障。以前,一次故障就可能让训练任务崩溃,要么从上一个检查点重新开始,要么等待网络重新计算路由,这个过程可能要花上几十秒。这在GPU算力和时间上都是巨大的浪费。同步预训练场景下,成千上万块GPU跨机器协同、步调一致地训练同一个模型,任何一次链路抖动的影响都被成倍放大。
MRC是什么
MRC的目标,不只是快,还要做到性能可预期,即便面对故障也如此。
OpenAI的Scaling团队与AMD、Broadcom、英特尔、微软、英伟达合作,历时两年开发出了这个协议。MRC内置于最新的800Gb/s网络接口,可以把单次传输分散到数百条路径上,在微秒级别绕过故障,同时运行更简单的网络控制平面。
MRC基于RoCE(RDMA over Converged Ethernet)扩展而来,RoCE是IBTA标准,支持GPU和CPU之间的硬件加速远程直接内存访问。MRC在此基础上借鉴了超以太网联盟(UEC)的技术,并进一步引入基于SRv6的源路由,以支持大规模AI网络架构。
目前,MRC已在OpenAI所有最大规模的英伟达GB200超级计算机上部署,包括位于德克萨斯州阿比林的Oracle Cloud Infrastructure(OCI)站点,以及微软的Fairwater超级计算机。MRC已用于训练OpenAI多个模型,使用了英伟达和Broadcom的硬件。
相关论文为 Resilient AI Supercomputer Networking using MRC and SRv6
https://openai.com/index/mrc-supercomputer-networking/
三大核心机制
1.多平面网络
传统做法是把一个网络接口当作一条800Gb/s链路使用。MRC把它拆成多条更小的链路,比如一个接口连接八台不同的交换机,形成八个并行的独立网络平面,每个平面运行在100Gb/s。
这个变化对集群架构影响很大。一台能以800Gb/s连接64个端口的交换机,换成100Gb/s后可以连接512个端口。这样只需两层交换机,就能构建一个全互联约13.1万块GPU的网络。传统的800Gb/s网络则需要三到四层。
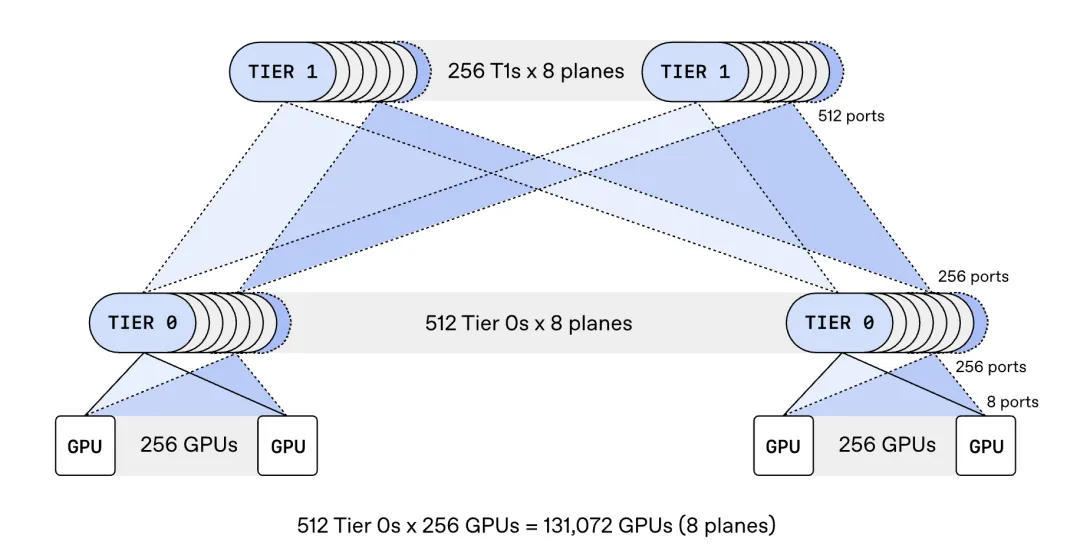
结果是:成本更低、功耗更低、路径冗余更多。同时,更多流量可以留在Tier 0交换机本地处理,性能更好。
但路径多了,充分利用也是难题。传统AI训练网络协议要求每次传输走固定路径,保证数据包按序到达。在大型多平面网络里,这会带来两个问题:不同数据流在同一链路上碰撞造成拥塞,以及每条数据流只能用一个平面。如果只做多平面网络、不改协议,结果反而会拥塞严重、性能很差。
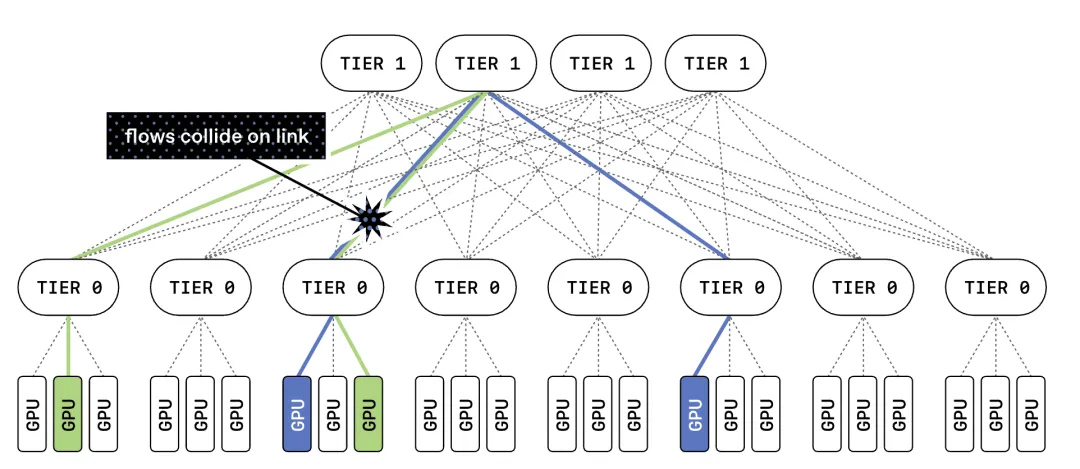
2.自适应包喷射
MRC从根本上改变了这一模式。它把单次传输的数据包分散喷射到数百条路径上,跨越所有平面。数据包可以乱序到达,但每个MRC数据包都包含最终内存地址,目标端收到后可以直接按地址写入内存,无需等待重排序。
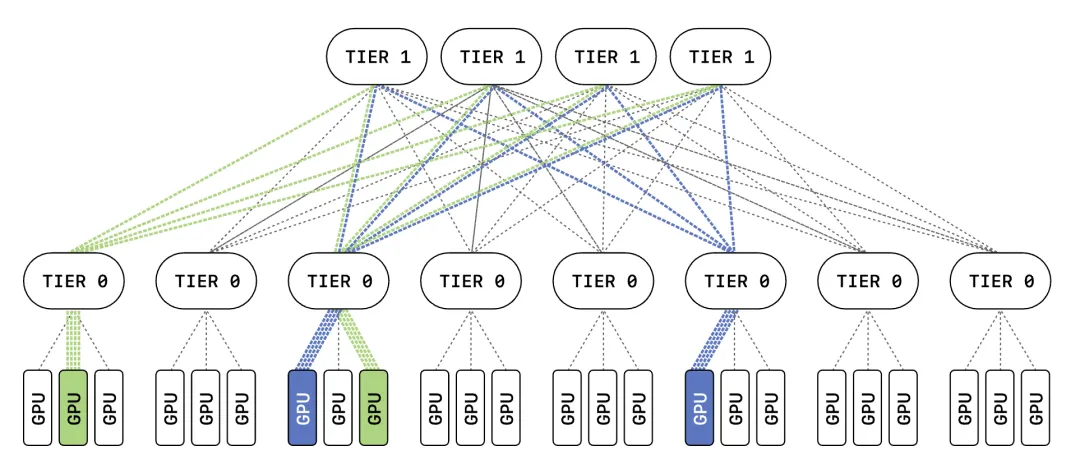
每条MRC连接对所用的多条路径维护少量状态。检测到某条路径出现拥塞,就切换到另一条,让负载在网络中均匀分布。如果丢包,MRC会立即停用该路径,重传可能丢失的数据包,并发送探测包确认是否真的发生故障、故障是否已恢复。
拥塞也会造成丢包。MRC通过包裁剪来处理这种情况:如果交换机因拥塞需要丢弃某个数据包,它会把载荷裁掉,只把包头转发给目标端,触发显式重传请求。这样可以减少误判,避免把拥塞丢包错误识别为路径故障。
多平面拓扑、包喷射、负载均衡、包裁剪组合在一起,让MRC能在微秒级别检测故障并绕行,而传统网络架构绕过故障可能需要几秒甚至几十秒。
3.SRv6源路由
传统交换机运行BGP等动态路由协议来计算路径、绕过故障。但交换机是运行复杂软件的复杂设备,出现微妙故障时,问题难以诊断,修复前可能一直影响连接。
有了MRC,动态路由变得不再必要。MRC直接禁用动态路由,改用IPv6 Segment Routing(SRv6)。SRv6让发送方直接在每个数据包里指定路径,做法是把交换机标识符序列嵌入数据包的目标地址。
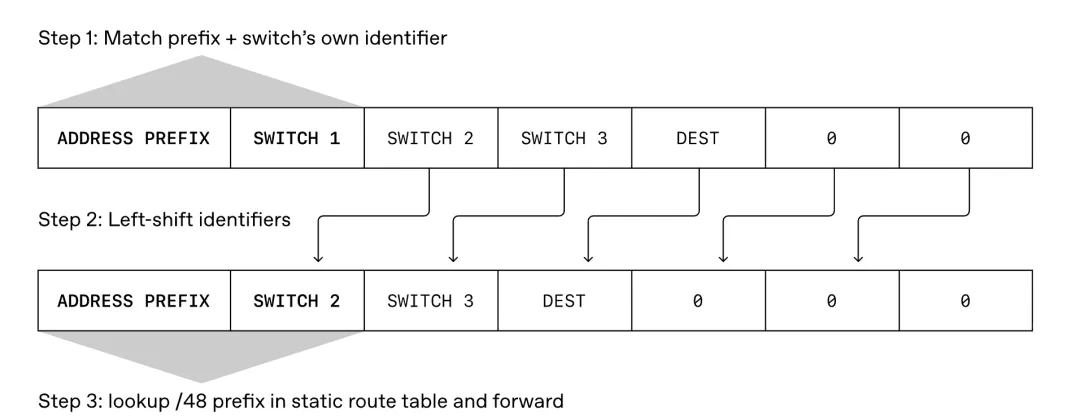
转发时,交换机检查目标地址中是否包含自己的标识符,如果包含,就把它移除,将目标地址向后移动,露出下一跳交换机的标识符,再查静态路由表确定下一跳。这个静态路由表在交换机初始配置时写入,之后不再更改。
路径失效,MRC停用即可。交换机不需要重新计算路由,只需按照静态路由盲目转发。
实际表现
训练网络有数百万条链路。在足够大的规模下,链路抖动不可避免。OpenAI观察到Tier-0和Tier-1交换机之间每分钟都会出现多次链路抖动,但MRC保证这些抖动对同步预训练任务没有可测量的影响,严重程度甚至不需要立即安排维修。
更大的考验是交换机重启。在训练某个近期ChatGPT和Codex前沿模型期间,OpenAI不得不重启四台Tier-1交换机。以前,重启交换机需要运维团队非常小心,避免中断训练。有了MRC,甚至不需要通知正在跑训练任务的团队。链路维护也一样,以前需要协调停用链路,现在可以带电维修,能用就用,不能用MRC自动绕开,修好后自动恢复。
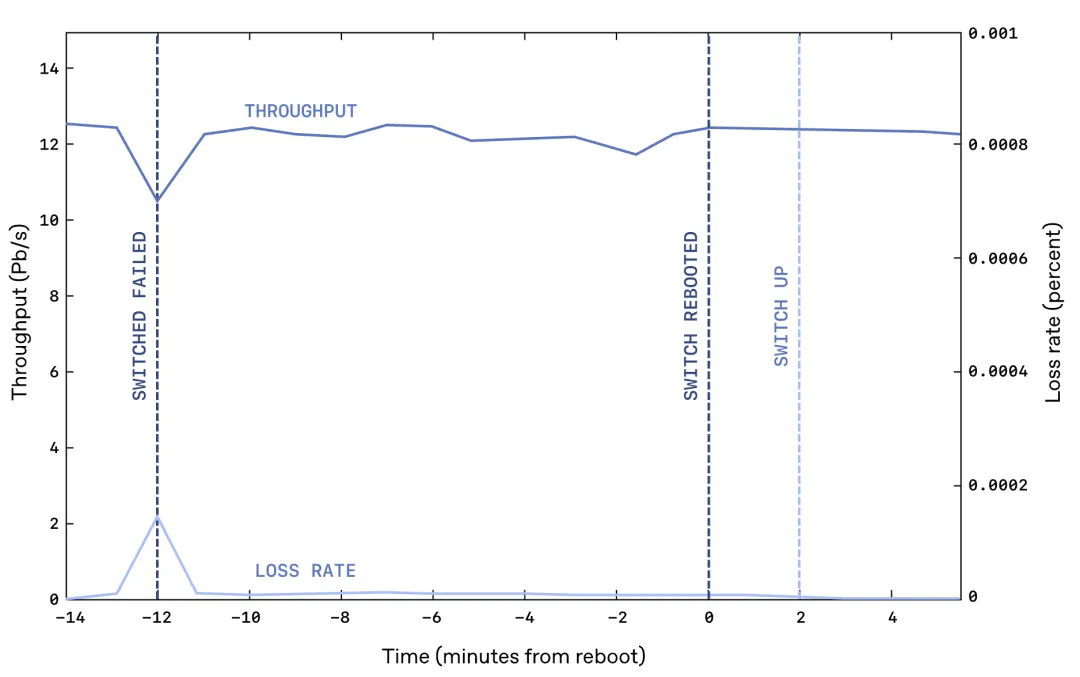
在GPU网络接口与Tier-0交换机之间的链路故障方面,以前一旦断链,训练任务就会失败。现在,8口网络接口丢失一个端口,最大速率降低八分之一,MRC检测到后重新计算路径、通知对端不再使用该平面,故障链路通常在一分钟内恢复,MRC随即把该平面重新纳入使用。实际上,丢失接口链路造成的性能下降,往往远小于物理带宽损失的比例。
总结一下
MRC带来三个关键优势:
一、只需两层以太网交换机,就能为超过10万块GPU的超级计算机构建多平面高速网络,容错能力强,功耗低于等效的三层或四层单平面网络。
二、自适应包喷射让网络核心几乎不出现拥塞,显著降低同步训练中各数据流之间的吞吐量差异,多个任务共享集群时也互不影响。
三、SRv6源路由快速绕过故障,只走正常路径,运行简单静态控制平面,彻底消除整类动态路由故障。
随着训练集群规模持续增长,网络设计越来越决定可用算力有多少能真正被用上。MRC帮助GPU在拥塞、链路故障和维护事件中保持协同,而这些情况在以前都会打断训练。在相当大的规模下,这种可靠性和效率不是锦上添花,而是同步前沿模型训练得以进行的前提条件。
–end–
最后记得⭐️我,每天都在更新:如果觉得文章还不错的话可以点赞转发推荐评论
/…@作者:你说的完全正确(YAR师)