 夜雨聆风
夜雨聆风





AI视频工具悄悄走到了第三阶段
这两年我看了一堆号称要颠覆AI视频的新产品。看了一阵子,我大概看出了一个规律。
第一代AI视频工具,是文生视频的盲盒。 一句话扔进去,等几分钟,开出来什么算什么,不满意只能重新投币。
第二代多了个Agent入口,AI开始能用对话方式调度。但Agent是悬浮在产品之外的「插件」,对话归对话,画布归画布,AI在另一个房间帮你跑腿。
最近我用了一个国产的画布型AI视频工具,叫RHTV。打开第一眼我就感觉,AI视频工具可能在悄悄进第三阶段了。
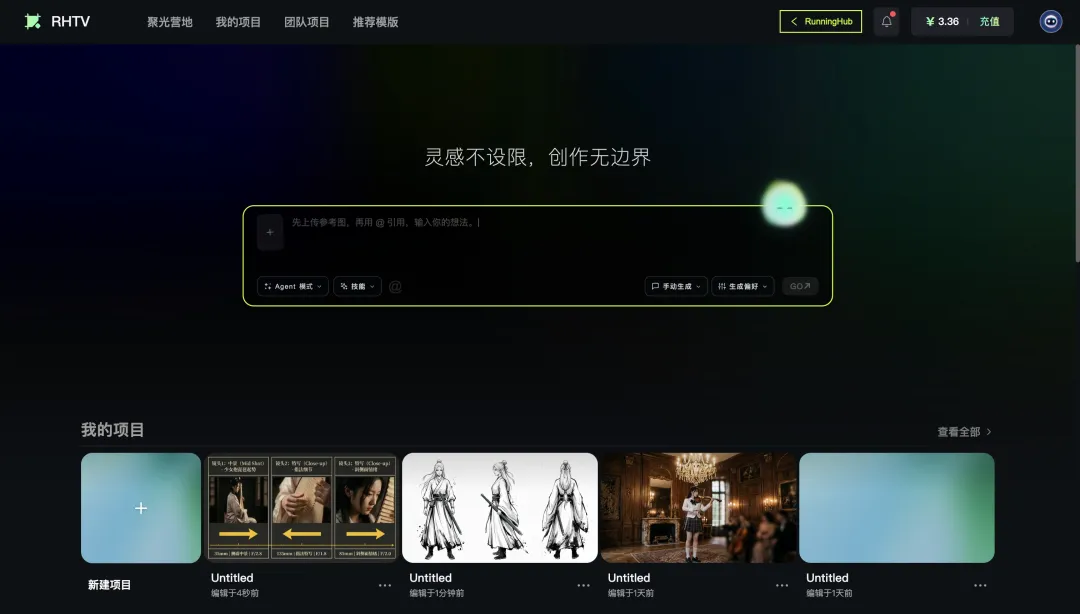
这一代的关键词是「画布原生」。Agent不是悬浮在画布之外的服务,而是画布本身的大脑。它住在你的工作流里,看得见你每一步在做什么,也让你看得见它每一步在想什么。
听起来好像只是产品形态的小调整,但用过之后我意识到,它其实在重新定义「人和AI怎么一起做事」这件事。
一、AI视频工具的三阶段演化
把过去两年的AI视频工具按使用体验排一下,能很清晰地看到三个阶段。
第一阶段,文生视频盲盒。
你输入一句话,等模型出片。整个过程是黑盒,AI怎么理解你的需求、怎么选模型、怎么处理细节,全在后端,用户看不到。结果不满意只能重新生成,没有局部修改的概念。
这个阶段最大的问题不是出不出好东西,是不可控。 一支15秒的短片,你想换其中一个镜头,必须把整个15秒重做。这种「一掷定乾坤」的体验,能用来玩,但很难拿来真正干活。
第二阶段,双入口模式。
产品意识到了「全自动」的问题,于是引入了Agent。但很多产品只是在原有的画布旁边加了一个「对话面板」:你跟Agent聊天,Agent帮你生成,结果再回到画布。
看起来「AI智能体」是有了,但本质上Agent是个外挂插件。它不在画布里,它在画布旁边。
这个阶段的体验有种微妙的撕裂感。你在画布里精雕细琢一个分镜,想让AI帮忙优化,得切到对话框,跟Agent解释你在做什么。AI不知道你画布里的上下文,每次都得从头说起。Agent成了一个外接的传话筒,不是真正的搭档。 第三阶段,画布原生Agent。
这就是RHTV在做的事。Agent就在画布里,左下角一个按钮唤起。你选中一个素材或节点,直接对RH智能体说「把这个调暗一点」,它知道你说的「这个」是什么,因为它和你看的是同一张画布。
更关键的是,RH智能体不是只负责执行。它有自己完整的本地决策链:理解需求 → 规划路径 → 生成提示词 → 组装节点。每一步都可见,每一步都可改。你看到的不只是结果,是它怎么得出这个结果的。
这三个阶段,本质上是三种「人和AI的关系」。第一阶段是「使唤AI」,第二阶段是「协助AI」,第三阶段才是「和AI一起想」。
二、什么是「画布原生」
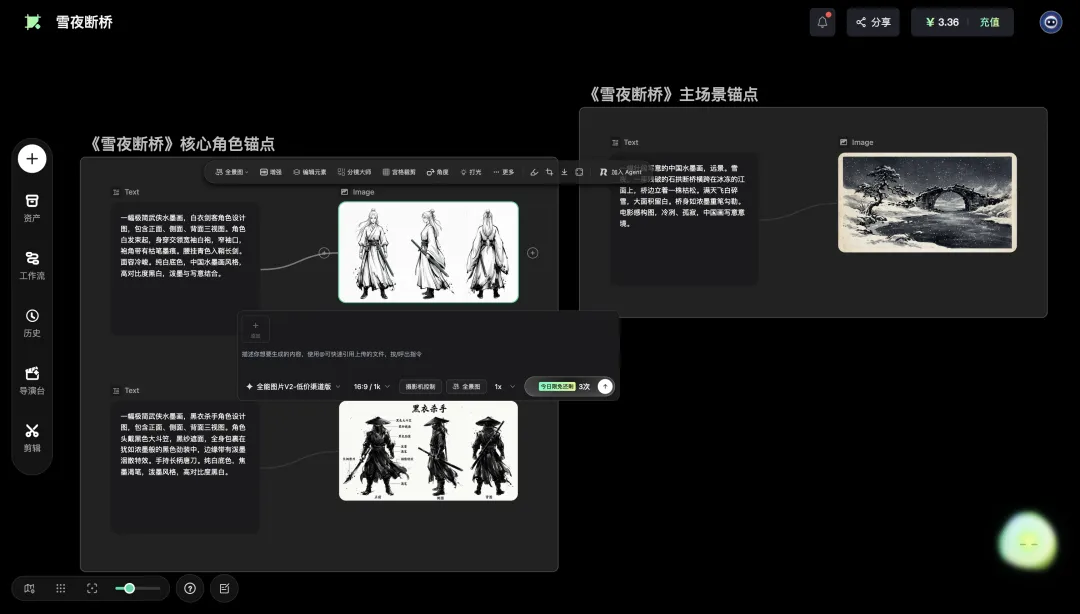
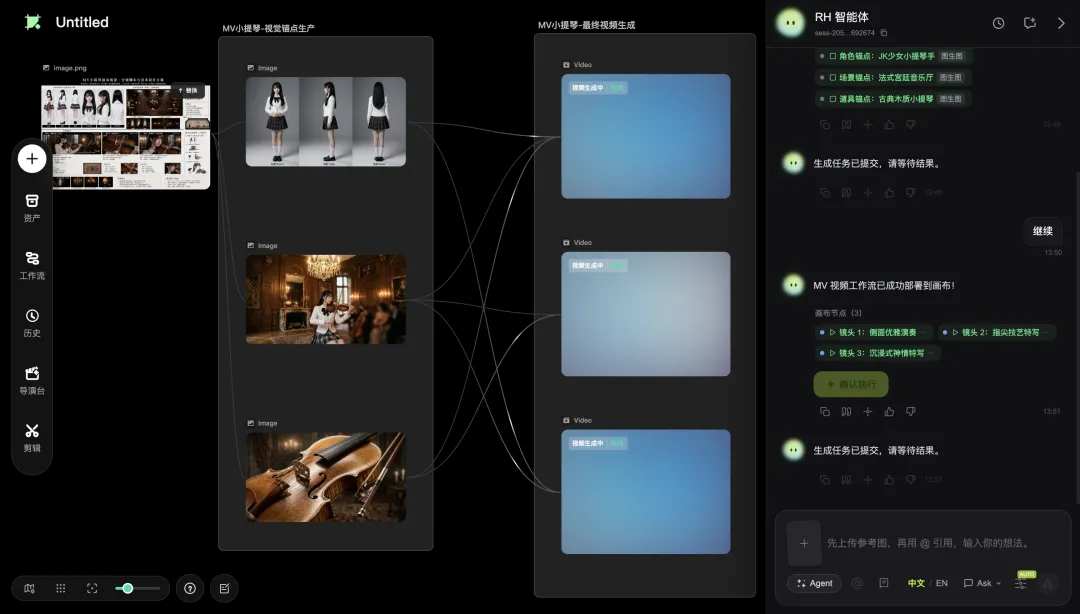
「画布原生」这个词第一次出现的时候,我也没太懂它和「在画布里加个AI按钮」有什么区别。后来在RHTV里跑了一个真实的MV项目,我大概理清了它的样子。
先说背景。我用GPT-Image-2做了一张「MV小提琴演奏场景·分镜脚本与美术设计方案」的综合参考板。一张图里,把这支MV的前期工作几乎全做完了:角色6视角图(JK制服小提琴少女)、法式宫廷场景的平面图+立面图+剖面图、3个分镜的方案(侧面中景、小提琴特写、斜侧情绪特写)、4种灯光参考、还有色调推荐。

这张图本身就挺值得说一下。文生图模型走到今天,一张图就能把一支MV的前期规划全做完。 导演脑子里所有该想的:人物、场景、镜头、运镜、光线、色调,都可以让AI一次性铺出来。
但问题随之而来:前期规划完成度变高了,可下一步怎么走?
按传统玩法,我有两个选项。
选项一是手动拆解:把参考板里的角色图抠出来作为@参考,把场景图抠出来作为另一组@参考,把分镜文字复制成prompt,再分3次手动调度Seedance 2.0。这个流程下来,光准备工作就够你折腾大半天,每改一处还得重来一遍。
选项二是直接把整张参考板丢给Seedance 2.0:它会把这张密密麻麻的板子当成「一张包含人物+场景+小图+文字框的图」整体识别。结果就是稳定性差、可控性差、可拓展性差,输出基本是不可用的。
也就是说,当文生图把「想清楚」这件事压缩到几分钟,AI视频领域反而出现了一个新的工具空缺:能不能有一个工具,看得懂这张参考板,能把它结构化拆解,能把每个分镜变成画布上可调度的节点?
这就是我说的「画布原生Agent」要解决的问题之一。它不止是酷炫,也是真的有能力去适配是最新一代具有agent思维的图像生成模型甩出来的高密度规划素材。
我决定换个玩法:把整张参考板丢给RHTV的画布,对RH智能体说一句话:
「按这张分镜板生成MV,3个镜头」。
然后我就坐着不动了。
RH智能体接到指令之后,没有像传统模型那样直接闷头开生成。它先做了一件事:识别。
它在画布的对话面板里,把这张参考板的核心元素逐条标记出来:
-
角色:JK制服小提琴少女 -
场景:法式宫廷 -
道具:小提琴
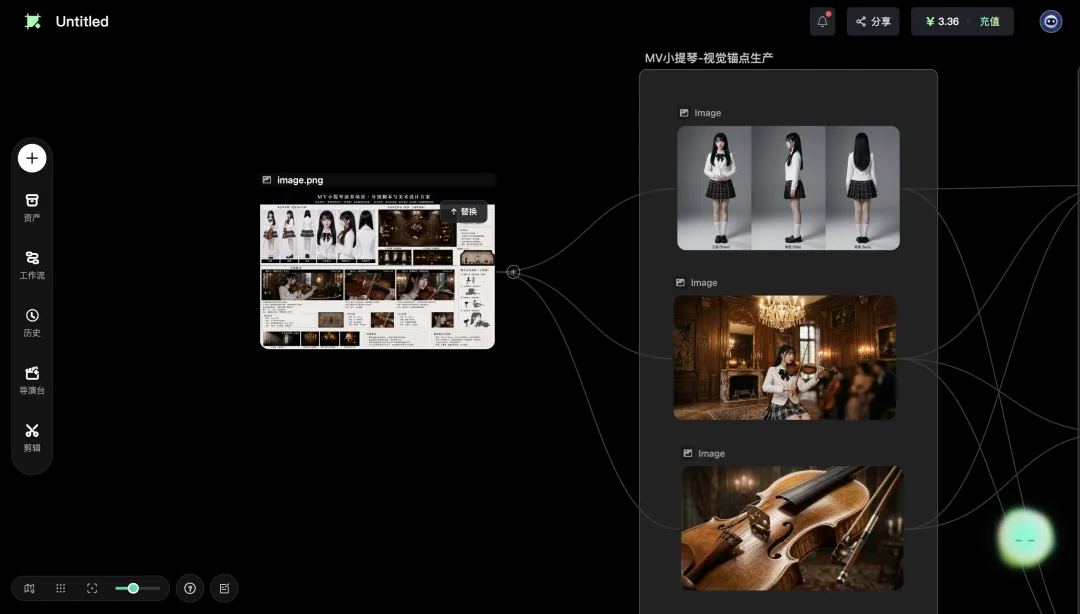
这个动作的关键不是它「识别对了」,而是它把识别过程暴露给我看了。我能看到RH智能体对这张参考板的全部解读,确认无误后才让它继续。如果它把JK制服理解成了和服,我可以在这一步就拦住它,不会等10分钟后看到一团离谱的成片再来反悔。
我一直觉得,能不能看见AI在想什么,是判断一个AI产品是工具还是搭档的分水岭。 工具只对结果负责,搭档要对过程透明。
三、透明的力量
确认完元素,RH智能体开始自己建工作流。
它在画布上拉出了两组节点:
第一组叫「MV小提琴-视觉资产生产」,里面是3个image节点,分别承担参考板拆解、角色生成、场景生成。
第二组叫「MV小提琴-最终视频生成」,里面是3个video节点,对应分镜板里的3个镜头:
-
镜头1:侧面优雅演奏 -
镜头2:指尖技艺特写 -
镜头3:沉浸式神情特写
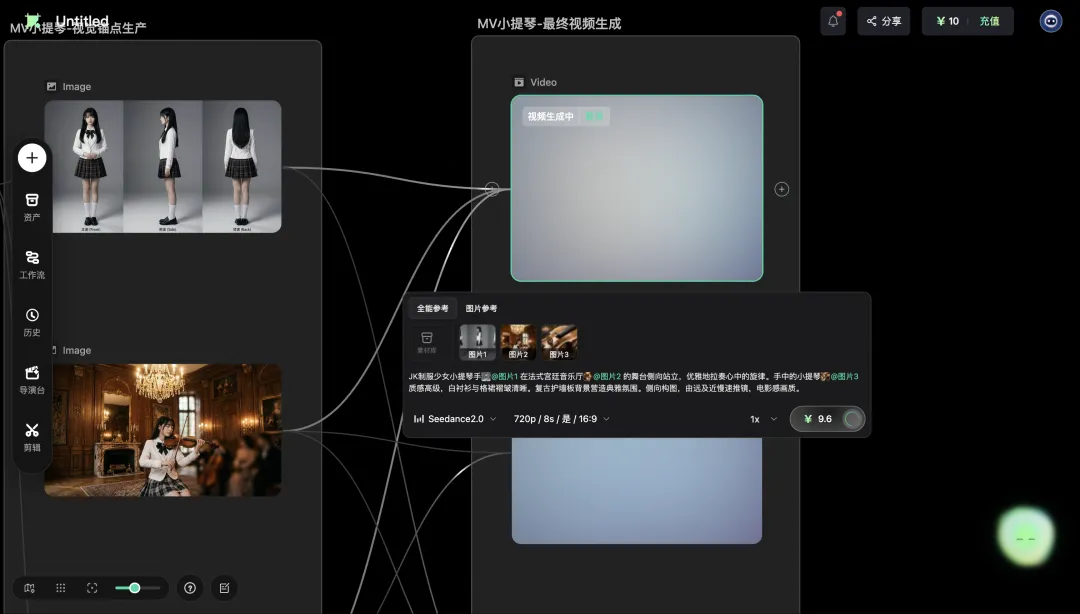
更让我意外的是,RH智能体还把节点之间的参考关系也自动配置好了。哪个视频镜头用哪张图做参考、参考的优先级是什么,全部展开在对话面板里。
这是传统Agent模式做不到的事情。它们的输出是个「黑盒视频」,它知道自己怎么做的,但不告诉你。RHTV的智能体是把它的整个工作思路展开成画布上一张可视化的图,哪个节点干什么、连给谁,一目了然。
AI创作这两年最大的痛点,其实不是模型不够强,是不可控。
你可能听过太多创作者抱怨:「这个镜头明明只有一个细节不满意,凭什么要重做整支视频?」这个痛点的根源就是黑盒。第一代和第二代AI视频工具,把创作过程锁在后端。你输入prompt,等结果,不满意再调prompt,再等结果。整个反馈循环里,你永远不知道AI到底是怎么处理你的话的。
画布原生Agent真正值钱的,可能不是它会自动搭工作流,而是它把整个工作流摊开给你看。
每个节点都带着明确的语义角色,每条连线背后都有可解释的参考关系。我想在哪个环节插手就在哪个环节插手:换衣服只改character节点,换灯光只改lighting节点,调某个镜头的运镜只改对应的video节点,下游会自动适配,不用重跑整条链路。
这一点对专业创作者特别重要。轻度玩家要的是「一键出片」,专业创作者要的是「可改」。 一段广告片、一段品牌视频、一支短剧,几乎不可能一次成型,必然要反复迭代。如果每次迭代都意味着重新跑整条流程,那AI不是在帮你创作,是在浪费你的时间。
四、能力上限的赌注
聊到这里要回答一个问题:为什么是RHTV做出了「画布原生Agent」,而不是其他家?
我觉得答案在生态。
AI视频工具的核心矛盾,是用户的需求边界永远在扩展,而单个产品团队的开发能力是有限的。今天用户要漫剧,明天要TVC,后天要MV,再后天要新的视觉风格。每一个新需求,封闭系统都得自己开发模型、调试节点、上线功能。
这种模式有个天然的天花板:产品能力的上限就是产品团队的上限。
RHTV的解法是站在Runninghub生态之上。RunningHub是目前国内最活跃的AI内容创作者共创的图像音视频内容平台,有国内规模最大的ComfyUI创作者,沉淀了10万+社区AI应用、13681个可用节点、170+标准模型API。每天全球开源社区贡献的新节点、新工作流、新模型,都会自动纳入RHTV的能力矩阵。
这不是「接入了开源」那么简单,是「产品的能力上限由全球开源社区决定」。每天都有开发者在贡献新的节点、新的工作流、新的插件,这些都会自动出现在RHTV用户的能力面板里。
封闭系统在和全球社区赛跑,结果其实是注定的。
短期看,封闭系统可能能通过精打细磨的官方能力赢得用户。但长期看,5万+工作流的复用、10万+应用的可调用、五大模态全覆盖(图像、视频、音频、3D、文本),这种规模一旦展开,单个团队是追不上的。
RHTV的智能体能力不会过时,因为它的能力天花板由社区决定,不由产品团队决定。这是一个关于长期主义的产品判断。
五、Seedance 2.0的特殊化处理
讲完范式和生态,再讲一个具体的、最近半年内创作者最关心的话题:Seedance 2.0。
字节这一代视频模型,业内已经在叫「导演之选」。它支持@参考、首尾帧、上传真人参考视频驱动动作。这些能力让它在动作戏、复杂运镜、人物表演等场景成了第一梯队。
但Seedance 2.0这种顶级模型,有个普遍问题:在大多数平台上,它就是被「接入」了。你能调用它,但调得很基础,等待时间长、画质有限、玩法受限。
回到我刚才那支小提琴MV。Agent建好工作流之后,我点了「确认执行」,Seedance 2.0就接管了视频生成。
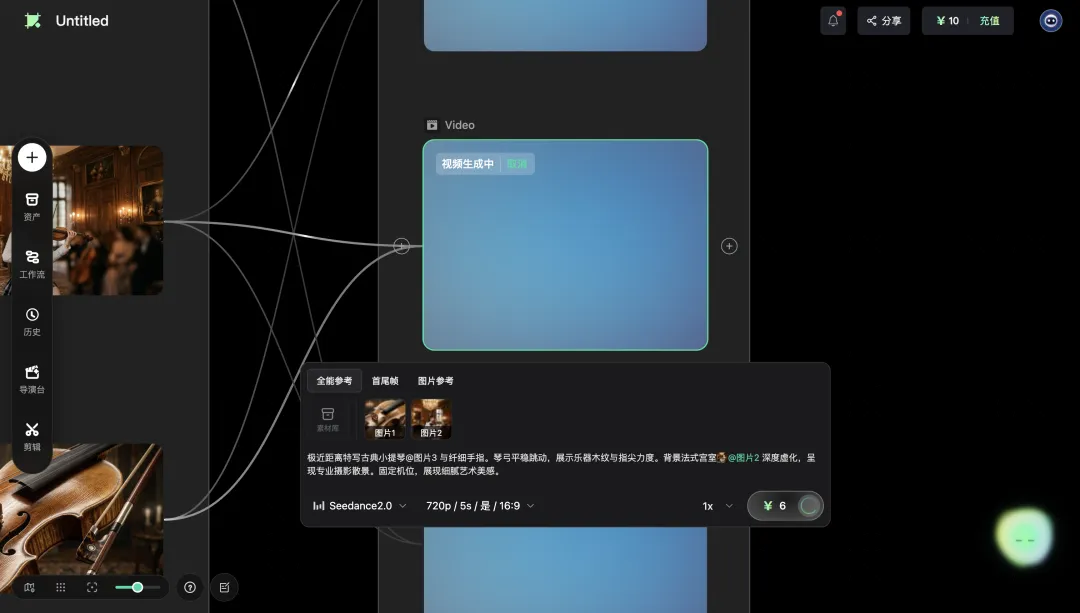
配置面板上能看到模型版本(Seedance 2.0)、分辨率(720p)、时长(5秒/帧)、宽高比(16:9),还有「全部参考 / 首尾帧 / 图片参考」三种参考模式的切换,连Seed这种细节参数都可以看。这些东西全部暴露给用户,每一个我都能看到、能改、能针对单个镜头微调。
跑完之后,第一个镜头出来了:一个JK制服的少女在法式宫廷宴会厅里演奏小提琴。水晶吊灯的光在她身上散开,木地板的反光、墙面的雕花、远处虚化的烛台都在。少女演奏的姿态自然,没有早期AI视频里那种「融化感」,运镜平稳。
这是我对Seedance 2.0的最新印象更新。RHTV对它的处理方式叫「增强式接入」:不排队、速度快、支持4K和真人生成,年度会员折算下来等于6折用。
但我觉得最值得说的,还不是价格和速度,而是RHTV把Seedance 2.0的全部能力以节点参数的形式开放给用户。你不只是在用一个模型,你是在调度一个模型。
优秀的AI工具平台和普通的「模型接入商」的差别,就在于对核心模型的特殊化处理。 不是做加法(接入更多模型),而是做乘法(让最好的模型在你的平台上用得最好)。
收尾·新范式
回到开头那个判断:AI视频工具走到了第三阶段。
第一阶段解决「AI能不能做出视频」,第二阶段解决「用户怎么调用AI」,第三阶段开始解决「人和AI怎么一起做事」。
画布原生Agent不只是功能升级,更像是范式更新。 它把Agent从「画布之外的服务」变成「画布之内的大脑」,把AI创作从「开盲盒」变成「看得见的协作」,把产品的能力天花板从「团队上限」变成「生态上限」。
我有个直觉:未来一年,AI视频工具的竞争会沿着这三条线展开。哪些产品在做画布原生,哪些还停留在双入口;哪些把Agent的思考过程暴露出来,哪些还藏在后端;哪些站在开源生态上,哪些还在自研封闭体系里。
这三条线决定了,谁会沉淀成这一代AI视频工具的基础设施,谁只是过渡形态。
回到我那支MV:从我把分镜板丢进画布、说一句话,到Agent自动拆解、配置参考、调度Seedance 2.0生成——整个过程我没碰过prompt,没自己抠过图,没切换过界面。我做的事情只有两件:上传一张参考板、说一句中文。
这种体验对我来说挺新的。它和我过去用过的所有AI视频工具,确实不太一样。
如果你也是创作者,建议你去自己跑一遍,看看「Agent住在画布里」是种什么样的体验。
RHTV.ai