 夜雨聆风
夜雨聆风





AI大模型与四农普(四):作物识别——实战派的7种方案对比
AI大模型与四农普(四):作物识别——实战派的7种方案对比
——RF统治实战项目,UTAE/Mamba无人采用,物候特征工程才是真壁垒
地块边界画出来了,下一个问题:每个地块种的什么?
四农普的作物识别和地块分割是完全不同的技术路线。地块分割靠的是空间特征——边界、形状、纹理,一张图就能搞定。作物识别靠的是时间特征——小麦3月返青、5月抽穗、6月收获,玉米6月播种、9月成熟,同一个地块在不同月份看起来完全不一样。
这意味着:作物识别不能只看一张图,必须看时间序列。
从Random Forest的物候特征工程,到UTAE的时间注意力,到SITSMamba的线性复杂度时序建模,再到Prithvi-EO-2.0的遥感基础模型——2025-2026年,作物识别的技术栈在快速演进。
但本文不只是罗列模型。我调研了四农普遥感测量项目中多个实战团队的技术方案,把学术前沿和生产实战做了一个全面对比——结论可能会让你意外。
一、作物识别的核心逻辑:物候是关键
先搞清楚一个底层逻辑:作物分类的核心特征不是”学出来的”,是”算出来的”。
NDVI时间序列的物候指标——起始期、峰值时间、累积值、下降速率——才是区分作物的真正关键。不同作物的NDVI曲线长这样:
|
|
|
|
| 冬小麦 |
|
|
| 春玉米 |
|
|
| 大豆 |
|
|
| 水稻 |
|
|
| 冬油菜 |
|
|
| 棉花 |
|
|
一张单时相影像几乎不可能准确区分作物。 多时相比单时相精度提升10-20%。这就是为什么作物识别必须用时间序列模型。
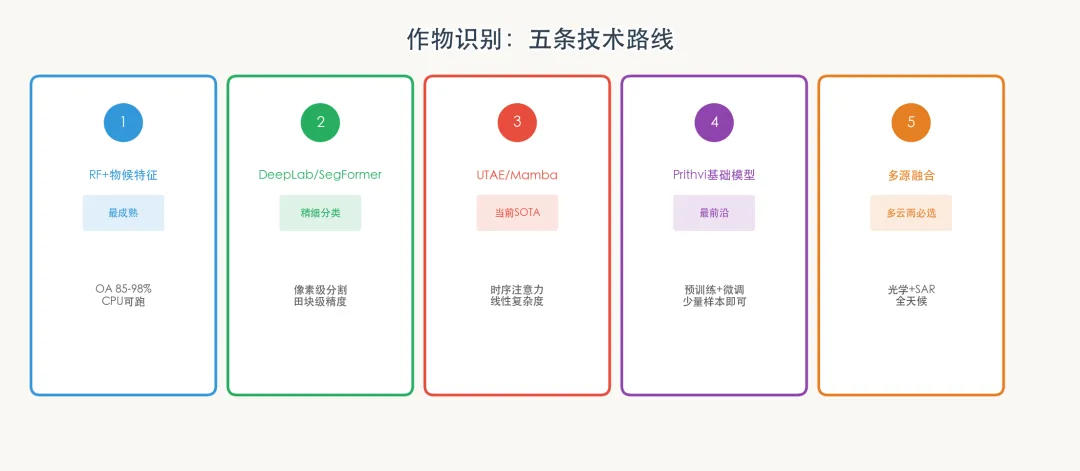
二、五条技术路线 + 生产验证
路线一:RF/XGBoost + 物候特征(绝对主力)
别急着上深度学习。在实际四农普项目中,RF/XGBoost是使用最广泛的分类器——多个实战团队中有5个以RF或XGBoost为主力分类器。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
5/7实战团队采用,通过率最高 |
为什么RF依然能打?因为它的输入不是原始像素,而是手工计算的物候特征:NDVI时间序列、红边指数(Sentinel-2 B5/B6/B7)、纹理特征(GLCM)、SAR后向散射。这些特征已经把物候信息提炼出来了,RF只需要学会分类规则。
物候特征工程的三个层次:
基础层:NDVI时序的统计特征——均值、方差、最大值、最小值、偏度、峰度。大部分团队做到这一步,精度约85-90%。
进阶层:逐像素物候指标提取——NDVI峰值出现日期(DOY)、上升期起始日期、累积NDVI、下降速率。有团队专利记录显示,这种逐像素物候匹配可以将地市级精度提升约17%。
壁垒层:全国作物精细物候数据集——覆盖全国1000+粮食大县、积累20年的物候观测+光谱数据库。这是某个三农普核心团队用863重点项目积累出来的,不是花钱就能买到的东西。这才是RF/XGBoost精度能到98%的真正原因——不是模型多先进,是特征工程多深厚。
XGBoost是RF的有效替代。有团队在山区/丘陵区域用XGBoost替代RF,配合地形特征(海拔、坡度),效果优于RF。实战中的常见策略是:平原用一种模型,山区用另一种模型,两种模型的结果互为训练样本。
实战案例:
-
• 多源时序+RF,OA达98%(20年物候数据集支撑) -
• 多源归一化+PCA+GLCM+SVM,OA达91%(新疆棉花/玉米/冬小麦) -
• 半干旱区Sentinel-2物候指标+RF,OA达93%
路线二:U-Net/DeepLab/语义分割(辅助角色)
把作物分类当作语义分割来做——每个像素预测一个作物类别。
生产验证:多个实战团队中,没有任何一个把语义分割作为作物识别的主力模型。
但在特定场景下有价值:
-
• 有团队在平原区使用改进的UNet+Transformer混合架构(U-MixFormer,WACV 2025),mIoU比主流提升3-4.1% -
• 配合XGBoost形成”双模型协同”——XGBoost结果作为U-MixFormer训练样本 -
• 田块级精细分类时,语义分割比像素级分类更合理
LGD-DeepLabV3+(局部-全局双分支)在作物分类中mIoU达58.48%,比原版提升8.83%,是值得关注的改进。
结论:语义分割在作物识别中是”锦上添花”,不是”雪中送炭”。RF/XGBoost做不好的场景,语义分割通常也做不好——问题不在模型,在数据。
路线三:UTAE / Mamba 时序模型(学术SOTA,生产未采用)
专门为卫星时间序列设计的深度学习架构。
UTAE(Unstructured Temporal Attention Encoder):法国INRIA开发,将时间注意力与空间编码解耦,对不规则采样的卫星时序数据进行自适应时间聚合。在PASTIS-R基准上长期保持SOTA。
SITSMamba(2024):用Mamba状态空间模型替代Transformer的自注意力机制,线性复杂度解决了Transformer处理长时序数据的O(n²)瓶颈。
|
|
|
|
|
|
|
O(n) |
|
|
|
无限制 |
|
|
|
|
|
|
未采用 | 未采用 |
GMAT(2025)将Mamba与Attention通过门控方式融合,进一步提升了时序作物分类精度。
为什么学术SOTA在生产中无人采用?
-
1. 太新:UTAE 2021年发表,SITSMamba 2024年——四农普项目需要经过验证的稳定方案 -
2. GPU成本:时序Transformer训练需要大量GPU,省级项目不一定有预算 -
3. 边际收益不大:3-5种主粮的省级分类,RF+精细物候特征已达95%+精度 -
4. 可解释性差:四农普是国家级统计任务,需要可审计的分类过程。RF可以输出特征重要性排序,Transformer不行 -
5. 只在极端场景有优势:物候高度重叠的长江中下游(冬小麦/冬油菜/双季稻混淆)才真正需要
路线四:遥感基础模型(学术前沿,生产未采用)
|
|
|
|
|
| Prithvi-EO-2.0
|
|
|
|
| SSL4EO-S12 |
|
|
|
| AgriFM |
|
|
|
| CropSTS |
|
|
|
生产验证:多个实战团队中没有任何一个使用基础模型。
原因和路线三类似:四农普需要可解释、可复现、可审计的方法。基础模型的”黑箱”特性在统计调查中是风险。RF的分类过程可以通过特征重要性排序和决策规则可视化来解释——统计局需要这个。
基础模型的价值在”未来”:预训练阶段已学过全球各种地表类型的时序特征,微调只需少量本地样本。从”从头训练”转向”预训练+微调”是趋势,但2026年的四农普还用不上。
路线五:多源融合 SAR+光学(南方省份核心技术)
长江以南多云多雨,光学遥感数据获取困难。解决方案是光学+SAR融合。
这是5条路线中”生产验证最扎实”的一条——负责南方省份的实战团队全部采用了SAR方案。
SAR作物识别的完整管线(来自专利技术):
Sentinel-1 VH/VV极化数据 → Lee Sigma滤波去噪 → VH/VV交叉极化比计算
→ 双逻辑斯蒂回归拟合时序 → S-G平滑滤波 → DTW/twDTW曲线匹配 → RF分类实测指标:春玉米F1=0.86,夏玉米F1=0.88。
云修复技术(解决光学数据缺失问题):
构建”虚拟星座”(Landsat-8/9 + Sentinel-1/2),针对4种变化场景分别处理:自然发散、人为发散、同向变化、无变化。实测全面优于传统MNSPI方法。
多源光谱归一化:
另一个关键技术:以Sentinel-2A为基准,构建线性转换方程,将不同卫星(高分WFV、Landsat OLI等)的NDVI统一到同一标准下,形成无缝的10m分辨率NDVI时间序列。这不是简单的数据拼接,而是把不同传感器的光谱差异系统性地消除了。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
CROMA(350M参数)是专门做SAR+光学融合的基础模型,在多云雨地区作物分类中表现突出。

三、五条路线 vs 生产实战:一张对比表说清楚
|
|
|
|
|
| RF/XGBoost |
|
绝对主力(5/7实战团队采用) |
|
| 语义分割 |
|
|
|
| UTAE/Mamba |
|
无人采用 |
|
| 基础模型 |
|
无人采用 |
|
| SAR融合 |
|
南方项目全部采用 |
|
核心结论:真正的壁垒不在模型架构,在三个地方——
-
1. 物候特征工程:20年数据积累 vs 现算NDVI,精度差10%+ -
2. 后处理精细化:多源光谱归一化、SAR管线、云修复,这些不在任何论文里 -
3. 按区域分区部署:平原用XGBoost/深度学习,山区用RF,南方用SAR+云修复——没有”万能模型”,只有”按区域组合”
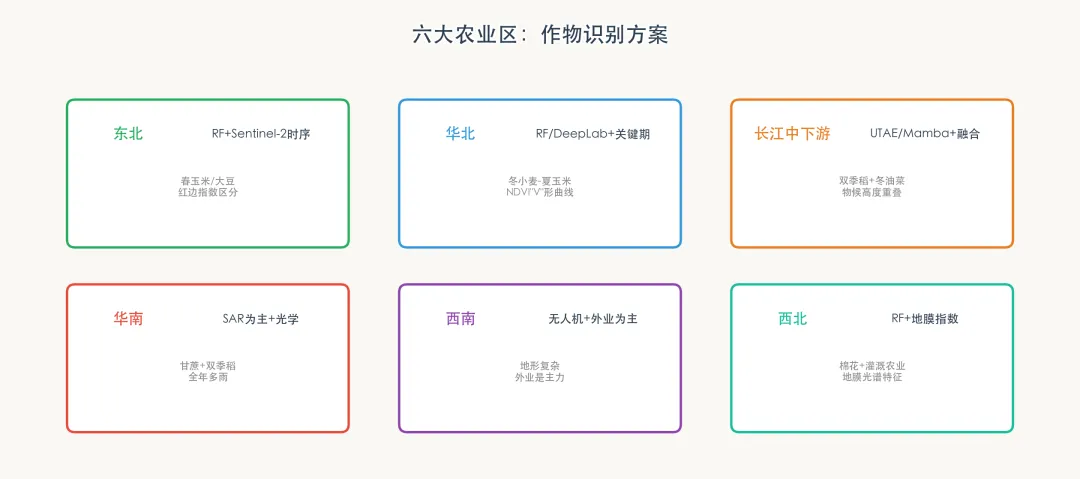
四、四农普实操:六大农业区各有打法
东北:RF + Sentinel-2时序 + 红边指数
地块大、种植单一(春玉米、大豆、春小麦)。大豆和玉米在7-8月NDVI均达峰值,是主要混淆对。需要红边指数(Sentinel-2 B5/B6/B7)辅助区分。
推荐:Sentinel-2多时相NDVI + 红边指数 + RF分类。简单高效,精度可达95%+。如果想追求极致,可以加20年积累的全国作物物候数据集。
华北:RF/DeepLab + 多时相关键期
冬小麦-夏玉米一年两熟制。5-6月是转换期,NDVI曲线呈典型”V”形。棉花生育期最长(4-10月),9-10月吐絮期是区分窗口。
推荐:RF(省级尺度)或 DeepLabV3+(田块级精细),抓关键物候期影像。
长江中下游:时序深度学习 + 多源融合 + SAR
双季稻+冬油菜+冬小麦,物候期高度重叠。全国最难搞的作物识别区域。 冬油菜3-4月盛花期的黄色花瓣是最佳区分特征。冬油菜与冬小麦的光谱混淆最典型——没有多时相数据根本分不开。
推荐:UTAE/SITSMamba时序模型 + Sentinel-1/2融合 + SAR云修复 + 野外验证。这个区域是唯一”必须上时序深度学习”的地方——RF确实不够用。
华南:SAR为主 + 光学补充
甘蔗+双季稻+热带水果。多云多雨是最大障碍。
推荐:Sentinel-1 SAR为主数据源 → VH/VV极化比+DTW曲线匹配 → RF分类。光学影像能获取到时补充。云修复技术在这里是刚需。
西南:无人机 + 野外验证为主
地形复杂、地块破碎、多云多雨。卫星遥感在这里力不从心,AI辅助只能做到局部提效。
推荐:无人机航拍获取关键物候期影像 + RF/DeepLab分类 + 大量野外验证。这个区域,外业是主力,遥感是辅助。
西北:RF + 地膜光谱指数
新疆棉花全国最大面积,地膜覆盖在春季影像上有明显光谱特征。灌溉农业与旱地的光谱差异显著。
推荐:RF + 地膜光谱指数(PGHI)+ 多时相NDVI + 多源光谱归一化。技术难度相对较低。
五、物候匹配迁移学习:一个被低估的方向
有一个技术方向值得单独说——物候匹配迁移学习。
核心思路:利用已有的成熟作物数据集(如美国USDA CDL),通过计算物候时间差,找到最佳匹配时间范围,将”知识”迁移到中国的新区域。
管线:
时序重建(异常检测+线性插值+S-G滤波)→ 逐像素物候特征提取
→ 物候时间差计算 → 最佳匹配时间范围 → RF分类实测:地市级精度提升约17%。这意味着你不需要从零开始标样本——只要找到物候相似的参考区域,就可以借用已有知识。
这个方向在四农普中的实际价值很大:中国2800多个县,不可能每个县都有足够的训练样本。物候匹配迁移学习提供了一种”低样本快速部署”的路径。
六、多源光谱归一化:让不同卫星”说同一种语言”
四农普要求分辨率优于2米(比三农普的16米提升了8倍),单一卫星数据源很难满足全覆盖需求。实际项目中需要混合使用多颗卫星的数据——但不同传感器的光谱响应不一样。
解决方法:以Sentinel-2A为基准,构建线性转换方程,将不同卫星的NDVI统一到同一标准下。
GF-1 WFV NDVI → 线性转换 → 统一10m NDVI
Landsat OLI NDVI → 线性转换 → 统一10m NDVI
Sentinel-2 NDVI → 基准(不转换)转化后形成无缝的10m分辨率NDVI时间序列。这不是简单的数据拼接——是把不同传感器的光谱差异系统性地消除了。 然后在统一的NDVI时序上计算物候特征(PCA + GLCM纹理 + 物候指标),送入SVM/RF分类。
实测(新疆沙雅县,棉花/玉米/冬小麦):OA 91.11%。
七、实操建议
-
1. 先做物候分析,再选模型。 搞清楚你所在区域的主导作物和关键物候期。3-5种主粮用RF/XGBoost就够,物候高度重叠区域才需要UTAE/Mamba。 -
2. 物候特征工程比模型架构重要10倍。 RF精度85%→98%的差距,不在模型,在特征。逐像素物候指标、20年积累的物候数据库、红边指数辅助——这些才是精度的来源。 -
3. 按地形分区部署模型。 平原用XGBoost/U-MixFormer,山区用RF,南方用SAR管线。没有万能模型,只有按区域组合。 -
4. 关注物候匹配迁移学习。 样本不足时,找物候相似的参考区域迁移知识,地市级精度可提升17%。比从零标样本高效得多。 -
5. 南方省份必须掌握SAR管线。 VH/VV极化比→滤波→DTW匹配→分类,这套管线是南方多云雨区的标配。没有SAR,光学数据缺太多。 -
6. 多源光谱归一化是基础功夫。 混合使用多颗卫星时,先统一光谱标准再提取特征。跳过这一步直接分类,精度会打折扣。 -
7. 野外验证不能省。 AI再强也替代不了地面真值。预算里给野外验证留足时间和经费,否则模型精度再高也是自嗨。
你们省的作物分类用的什么方案?RF还是深度学习?评论区聊聊。
本文是”AI大模型与四农普”系列第四篇。上期聊了地块勾画,5种分割模型的实战对比。下期聊遥感标注工具——X-AnyLabeling实战技巧,把前两期的模型落地到标注操作中。
参考资料:
• Prithvi-EO-2.0: https://github.com/NASA-IMPACT/Prithvi-EO-2.0 • SITSMamba: https://github.com/XiaoleiQinn/SITSMamba • PASTIS-R基准数据集: https://github.com/VSainteuf/utae-paps