 夜雨聆风
夜雨聆风





国内端侧AI SoC 个人洞察&分析
端侧AI SoC全景解析
算力、能效与未来趋势
这里整理了下当前国内主流端侧AI SoC的玩家、算力指标TOPS的意义及局限,分享五大洞察和主流厂商盘点,揭示决定Ai芯片体验的五大关键因素,希望能和大家一起探讨端侧AI芯片的现状与未来发展方向。
端侧AI SoC现状与TOPS解析
大家好,今天咱们聊个很实在的话题:现在全球主流的端侧AI SoC,到底都有哪些玩家?它们的算力和特点是什么?
先提前说明一下:英伟达、寒武纪这类主打云端的AI芯片,今天就不展开了,咱们聚焦在「端侧」场景里的主流方案。
最近看端侧AI SoC芯片,发现基本绕不开一个指标:TOPS。
TOPS(Tera Operations Per Second),AI算力的硬指标,说人话就是「每秒能完成多少万亿次运算」,数字越大,理论上跑模型的速度就越快。
举个很直观的例子:
1B参数的模型,用200 TOPS的NPU来跑,单次推理速度大概就是 1B ÷ 200 TOPS ≈ 10ms ,基本能做到实时交互。
下面自己根据理解,也整理了几点的洞察,大家有不同的观点和意见,欢迎相互交流~
1. 关于端侧AI SoC的五个洞察
🫵洞察一:“端侧AI SoC进入爆发期”——成立
手机、车载、机器人、AIoT都在往本地推理走的背后驱动力:
– 隐私(不上传云)
– 延迟(实时响应)
– 成本(减少云算力消耗)
🫵洞察二:真实的AI性能=TOPS × 内存带宽 × 软件优化 × 算子支持
现在的很多人会有两个误区:
1.“模型参数/TOPS = 处理速度”——不对👋
2.“高算力” = “高速度” ——不对👋
为啥?因为处理速度快慢,不仅跟算力有关,内存带宽,访存延迟、软件优化、算子支持等同样重要!
用TOPS衡量算力,是行业通用简化表达适合做横向对比的第一层筛选,但“只是一个简化估算方法”。
例如:同样是6 TOPS,瑞芯微RK3588的实际推理速度远低于英伟达Orin Nano,核心瓶颈是内存带宽和架构优化,而非单纯算力。
你看苹果的A系列芯片,TOPS不是最高的,但为什么跑大模型比安卓快?因为它把内存带宽做到了极致,数据不用来回“跑腿”,自然就快了。
就像英伟达的GPU,不是光靠CUDA核心堆出来的,是Tensor Core、NVLink、CUDA生态一起撑起来的。没有好的“数据通道”,再强的算力也只是一堆闲置的引擎。
👉虽然现在大家都在卷TOPS、卷参数,但我认为TOPS会像当年的CPU主频一样,早晚会失效。
🫵洞察三:“能效比比算力更重要”——非常对,端侧AI的本质不是算力,而是“约束下的最优解”
端侧AI和云端最大的区别,就是受限于电量和散热。对手机、手表、扫地机器人这类设备来说,“能在低功耗下跑出好效果”,比单纯的高算力更重要。
同样是10 TOPS,有的芯片跑起来发热严重,用半小时就降频;有的却能在不烫手的情况下稳定输出,后者才是真正的好方案。
👉 谁在约束下做得最好,谁的赢面就越大。实际拼的是:
– TOPS/W
– sustained performance(持续性能)
洞察四:AI SoC竞争正在从“硬件”转向“系统能力”
芯片 + OS + SDK + 模型
👉 类似当年: Apple vs Qualcomm
🫵洞察五:未来3年,AI SoC会分裂成三条路线
1)手机轻量化(低功耗)
2)车载安全冗余(高可靠)
3)机器人泛化智能(高灵活)
2. 主流端侧AI SoC厂商 × TOPS的局限
自己简单整理了一下国内AISoC的主要厂商,如果这里数据有问题的话欢迎指正
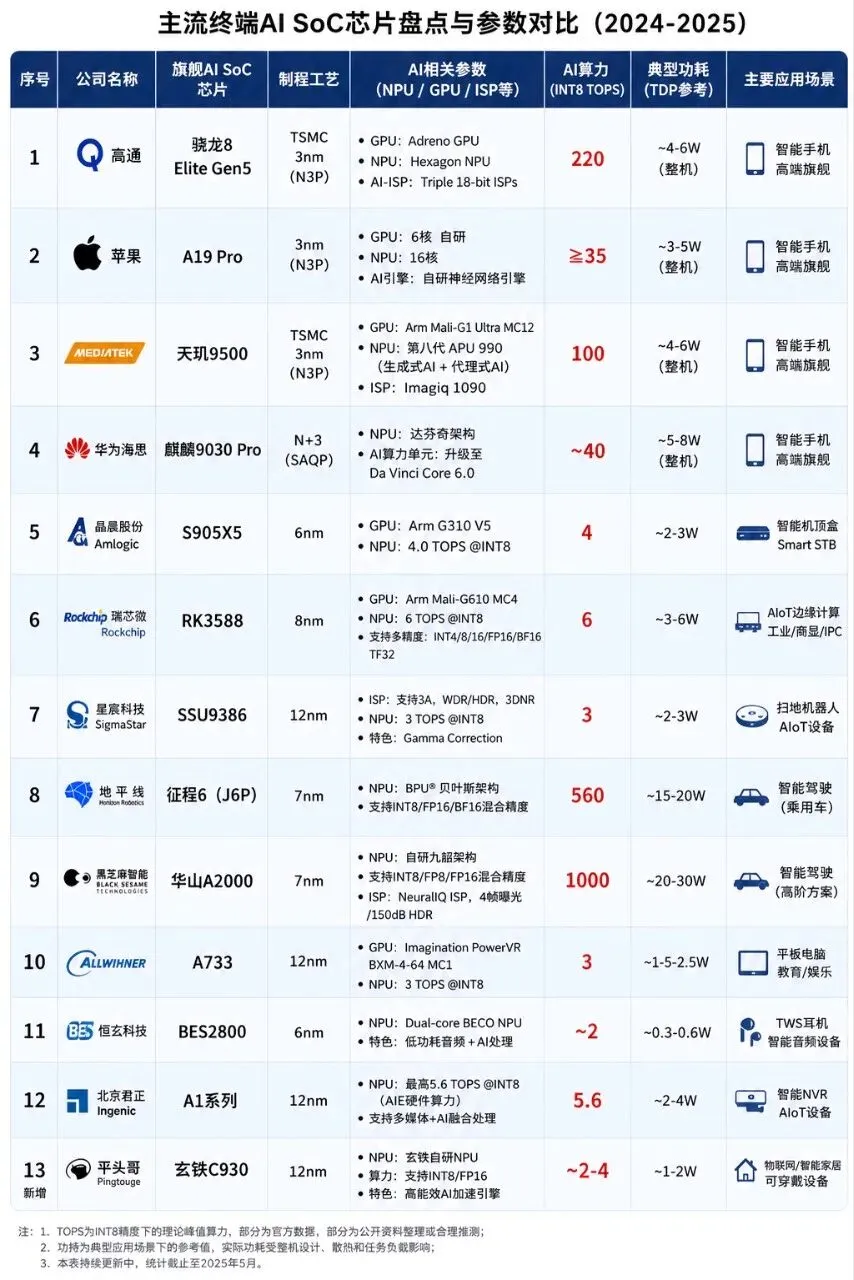
我自己现在看这类表,会默认加一个前提:不同芯片的TOPS口径、精度、甚至任务类型都不一样,即便TOPS一样,但也没办法完全等价,这个表更多只能看“趋势”,不能直接当结论。
为什么“100 TOPS ≠ 100 TOPS”,为什么不同设备的TOPS基本不能直接对比?
很多人默认一个前提:TOPS越高,AI越强。这个在今天已经不成立了。
原因主要有三个。
1)精度口径不同(这是最大变量)同样标100 TOPS,可能来自:
– INT8(主流)
– INT4(压缩计算)
– 稀疏计算(sparsity)
行业里一个比较常见的换算经验:
INT4 TOPS ≈ INT8 TOPS × 1.5~2(“虚高”)
稀疏TOPS:实际任务中未必能跑满
👉 也就是说:标称200 TOPS的芯片,真实有效算力可能只相当于80~120 TOPS。2)
2)峰值算力 vs 可用算力
绝大多数芯片厂给的是:
👉 theoretical peak
但真实情况取决于:
– 算子是否支持(Transformer / Attention / Conv)
– 编译器调度能力
– 内存带宽是否跟得上
行业里一个比较真实的数据区间:
👉 实际可用算力 ≈ 峰值的 30% ~ 70%能稳定跑到60%,已经算很优秀的了。
3)任务类型
完全不同不同设备不同平台,其实是完全不同的负载:
– 手机,典型任务主要是多模态、大语言模型跟影像,上面运行的主要是轻量化跟强实时的模型。
– 汽车,典型任务主要是BEV感知和规划,利用的是多传感器跟高安全性的模型
– 机器人,侧重SLAM + 控制,所以讲究的是持续运行 + 强鲁棒,以及安全冗余。
👉 同样是100 TOPS:
– 手机要低功耗(<5W)
– 车可以到几十甚至上百W
– 机器人更看长期稳定
所以不能放在一条线上比。
决定端侧AI体验的5大关键因素
真正决定体验的,不是算力,是这5个东西如果你只记一件事,可以记这个:
👉 AI SoC = 算力 ×(能效 × 内存 × 软件 × 延迟)
下面稍微展开一下
1)能效(TOPS/W)——第一优先级
在端侧,功耗就是天花板。几个参考区间(行业大致水平):
– 手机SoC:
👉 3~8 TOPS/W(峰值)
👉 持续运行更低
– 车载SoC:
👉 1~3 TOPS/W(但总功耗高)- 边缘AI盒子:
👉 2~6 TOPS/W
👉 结论很简单:能效决定你能不能“长期跑AI”,而不是跑一次benchmark。
2)内存系统(被严重低估)
这是很多非芯片背景的人最容易忽略的点。AI推理里一个常见现象:
👉 算得动,但喂不饱。
关键指标:
– DRAM带宽(GB/s)
– 片上SRAM(MB级)
– 数据搬运效率
一个经验判断:
👉 大模型推理里,带宽瓶颈占到性能损失的50%以上。
这也是为什么很多芯片:TOPS很高实际推理却很慢
3)软件栈(差距最大但最隐性)
同一颗芯片,不同厂商能跑出完全不同效果。高通Hexagon、苹果Core ML、华为昇思……编译器、算子库、生态优化,决定了你有再好的芯片,能不能真正跑稳大模型。没有生态,再高TOPS也只是纸面参数。
这里头要总结的话,差异主要在:
– 编译器(graph optimization)
– Kernel优化(算子实现)
– 模型适配(量化 / 切图 / 融合等)
一般软件优化能带来 2~5倍性能差距,这点在手机SoC上尤其明显。
4)延迟(Latency,而不是吞吐)
很多宣传强调吞吐(throughput),但用户感知的是:
👉 响应时间
比如:
– 拍照AI处理:<50ms 才算“实时”
– 语音助手:<200ms 才算自然
– 端侧大模型:首token延迟决定体验
👉 很多芯片TOPS很高,但延迟不稳定。
5)模型适配能力
未来不是拼“能不能跑AI”,而是:
👉 能不能跑主流模型
关键点:
– Transformer支持是否完善
– Attention优化
– 是否支持混合精度(FP16 + INT8)
写在最后
现在的端侧AI,很像十年前的手机行业:人人都在拼参数、堆数字,但普通用户根本分不清好坏。真正懂行的人,从来不只盯着TOPS。而是看精度、看带宽、看能效、看生态。
你觉得接下来端侧AI最先爆发的,是手机、自动驾驶,还是机器人?
欢迎评论区一起交流。
END
@江应玺