夜雨聆风
夜雨聆风





解析docx文件失败,国内解决nltk下载失败
nltk_data 下载问题
>>> import nltk
>>> nltk.download('punkt')
[nltk_data] Downloading package punkt to /home/joe/nltk_data...
[nltk_data] Error downloading 'punkt'from
[nltk_data] <https://raw.githubusercontent.com/nltk/nltk_data/gh-
[nltk_data] pages/packages/tokenizers/punkt.zip>: Remote end
[nltk_data] closed connection without response
False
解决办法
-
下载github zip文件
https://github.com/nltk/nltk_data/archive/refs/heads/gh-pages.zip, -
解压,将目录内的package目录修改为
nltk_data,ntlk_data目录移动到自己的家目录 -
手动解压以下目录下 zip文件 tokenizers目录和taggers目录
-
验证方法
import os
from langchain_core.documents import Document
from langchain_community.document_loaders import (
PyPDFLoader,
TextLoader,
UnstructuredWordDocumentLoader
)
all_docs_list = []
# 1. 加载 PDF
print("正在加载 PDF...")
try:
pdf_loader = PyPDFLoader("RAG.pdf")
pdf_doc = pdf_loader.load()
all_docs_list.extend(pdf_doc)
print(f"PDF 加载完成,共 {len(pdf_doc)} 页")
except Exception as e:
print(f"PDF 加载失败: {e}")
# 2. 加载 TXT (建议加上 encoding 参数)
print("正在加载 TXT...")
try:
# 显式指定编码,防止中文乱码或解码卡死
txt_loader = TextLoader("RAG.txt", encoding="utf-8")
txt_doc = txt_loader.load()
all_docs_list.extend(txt_doc)
print(f"TXT 加载完成,共 {len(txt_doc)} 段")
except Exception as e:
print(f"TXT 加载失败: {e}")
# 3. 加载 DOCX (这一步最有可能卡住)
print("正在加载 DOCX (这可能需要一些时间,请确保已安装 LibreOffice 和 NLTK 数据)...")
try:
docx_loader = UnstructuredWordDocumentLoader("RAG.docx")
docx_doc = docx_loader.load()
all_docs_list.extend(docx_doc)
print(f"DOCX 加载完成,共 {len(docx_doc)} 个文档")
except Exception as e:
print(f"DOCX 加载失败: {e}")
# 4. 打印结果
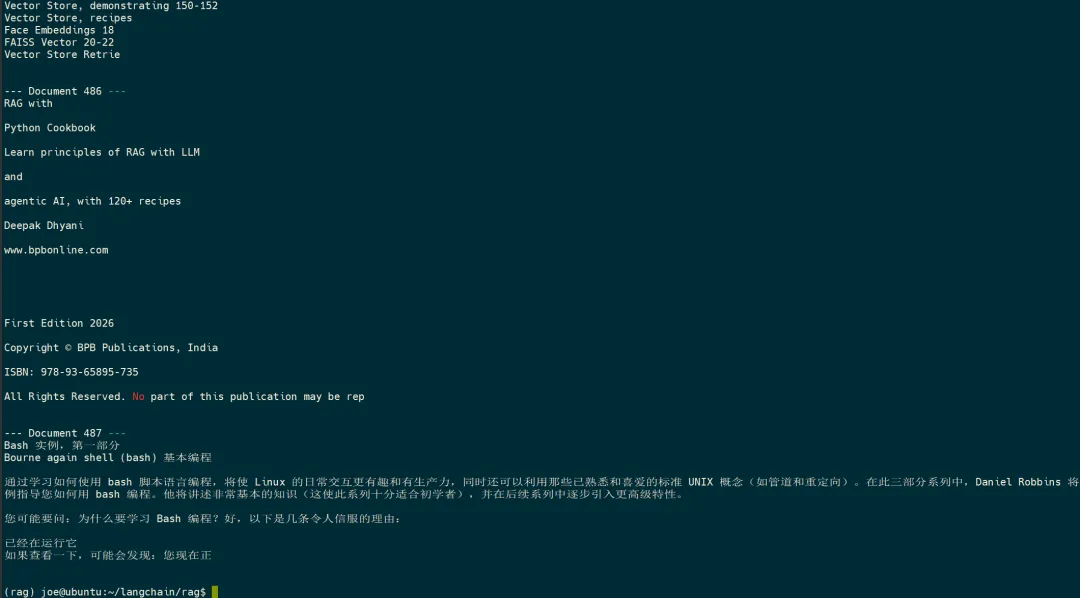
print(f"\nTotal documents loaded: {len(all_docs_list)}\n")
for i, doc in enumerate(all_docs_list):
print(f"--- Document {i+1} ---")
print(doc.page_content[:275])
print("\n")