 夜雨聆风
夜雨聆风





LTV演进实战:从简易公式到OpenClaw全自动化预测
我说你想问的是 LTV,这个数没办法直接查。说没办法直接查的意思是——你不能跑过来跟财务讲一个用户值 4800,人家问你怎么算的,你说不出来了。
我说这个事我也不是一下子就弄清楚的,说说我走过的弯路。
───────────────────────────
开始的时候我只有一个笨办法
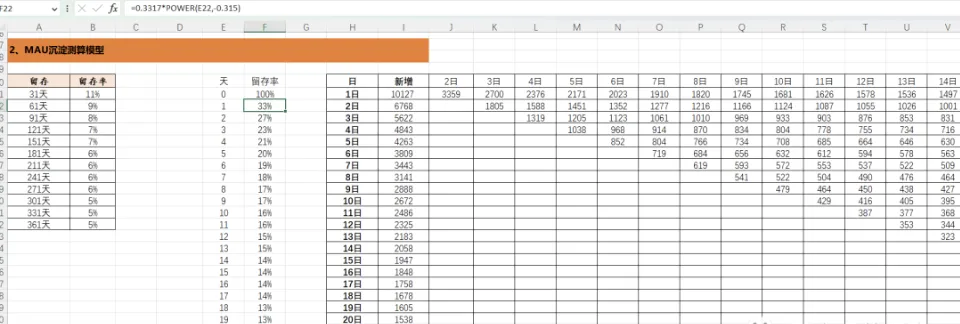
头两三个月,数据就那点东西。月均消费、月流失率。没了。再多一个数都没有。
我拿这俩数这么算:
python
# 速算LTVltv = arpu_monthly * (1 / churn_rate_monthly)# 比如 arpu=240, churn=8%, ltv≈3000
看着挺对的。公式也对。但有个前提是流失率不随时间变、ARPU 也不随时间变——实际上这俩数变起来快得很。
我碰过一个业务,头三个月月流失率 12%,到了第六个月自己降到 4.5%。就自己降的,不是我们做了什么。差了快三倍。拿速算版去算,出来的 LTV 比真实值差不多低了个 40%。拿到这个数的时候差点干一件事:砍一条渠道。因为速算版显示它”亏钱”。后来幸亏忍住了没动——回头查才知道是数据不够闹的。
速算版差点让我砍了一条渠道。幸亏忍住了——不是渠道不行,是数据不够。
所以到后面我就明白了,速算版就干两件事用得上:在刚起步的时候排个序看哪些渠道大概率有问题、标一下异常。不做预算分配。做预算分配拿这个数去算钱,等于闭着眼睛下注。
那个阶段大概持续了半年不到的样子。数据多一点了之后,我开始觉得这个 40% 的误差实在说不过去了。
───────────────────────────
数据攒多了,换了 BG/NBD 加 Gamma-Gamma
换这个版本的时候其实磨了一阵子。不是拿到数据直接扔进去就能用的那种——RFM 时间窗口取多长、频次怎么定义、多少次算活跃——这些都要自己定,定不对出来的数字就是不对的。
两个模型拆开算的。BG/NBD 猜用户未来一段时间里会来买多少次,Gamma-Gamma 猜每次大概花多少钱。两个数最后乘到一起。
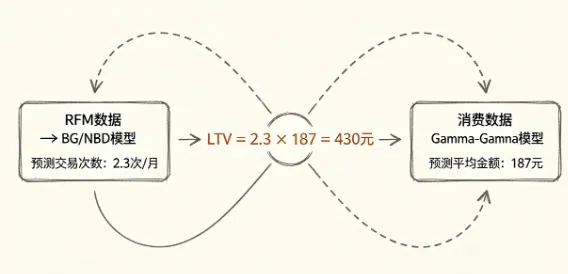
python
from lifetimes import BetaGeoFitter, GammaGammaFitter# BG/NBD 预测未来180天交易次数bgf = BetaGeoFitter()bgf.fit(data[‘frequency’], data[‘recency’], data[‘T’])pred_txn = bgf.conditional_expected_number_of_purchases_up_to_time(180, data[‘frequency’], data[‘recency’], data[‘T’])# Gamma-Gamma 预测平均交易金额ggf = GammaGammaFitter()ggf.fit(data[‘frequency’], data[‘monetary_value’])pred_avg_value = ggf.conditional_expected_average_profit(data[‘frequency’], data[‘monetary_value’])# LTV = 交易次数 x 平均金额ltv_pred = pred_txn * pred_avg_value
跑完的结果比速算版像样多了。我拿一组 9000 人的历史数据往回测——180 天后实际的 LTV 跟预测值对一对,中位误差大概在 20% 上下。9000 人的量级,20% 的误差,我觉得能用了。
但有个硬伤。BG/NBD 假设交易率服从 Gamma 分布、流失概率服从 Beta 分布。两条假设放到一些场景里就是对不上的。
我碰过一个春节前后做活动拉进来的用户群——拉进来头两周,基本上没人买,安安静静的。到第三周,突然集中买了一波,跟 Gamma 分布的形状差了整整一个量级。模型完全不知道怎么算这批人。用户量 5000 往下的时候这种情况特别明显,或者业务有明显的季节波动。
所以大概用了一年不到吧,我又碰到新的问题了。速算版和概率模型,它们有一个共同的毛病:都只用了交易数据本身。用户是从哪里来的、爱买哪类东西、是老油条还是刚来几天——一概不知道。
────────────────────────────
把用户标签加进去之后
做用户画像那段时间,我顺手把 LTV 模型也改了一版。反正标签已经有了,注册渠道、活跃频次、品类偏好、客单价区间、优惠券敏感度,这些直接往 XGBoost 里塞。
|
特征大类 |
具体特征 |
对LTV的解释力 |
|
用户画像 |
注册渠道、城市级别、设备类型 |
★★☆ |
|
活跃行为 |
7日登录天数、30日浏览深度 |
★★★ |
|
消费行为 |
首单金额、30天购买次数、客单价 |
★★★★★ |
|
优惠敏感 |
优惠券使用率、满减参与率 |
★★★☆ |
|
品类偏好 |
主要消费类目、跨类目购买次数 |
★★☆ |
跑完回来翻特征重要性,我愣了一下。排第一的居然是首单金额和 30 天内购买次数——这俩东西,就是你用户来了之后买的第一样东西花了多少钱、还有头三十天里来买了多少次。光靠这俩特征,对 180 天 LTV 的解释力已经超过了 BG/NBD 三参数。注册渠道排在第五还是第六来着,很靠后。
首单金额和30天购买次数,两个特征就盖过了BG/NBD三参数。剩下的画像标签主要是冷启动兜底。
剩下的画像特征,主要是在冷启动的时候派得上用场——用户刚注册还没买过东西,什么都没有,只能靠画像来猜。
python
import xgboost as xgbfeatures = [‘first_order_amount’, ‘purchase_cnt_30d’, ‘login_days_7d’, ‘browse_depth_30d’, ‘coupon_usage_rate’, ‘category_diversity’, ‘city_tier’, ‘register_channel’]model = xgb.XGBRegressor(n_estimators=200, max_depth=5, learning_rate=0.05)model.fit(X_train[features], y_train)ltv_pred = model.predict(X_test[features])
模型回测误差在 15% 左右。但要说明一个事:日活没到 3000 的时候我没用过 XGBoost。样本不够,跑出来基本是噪声——有段时间我手贱试了试,两千多日活的时候训了一个,出来的结果跟扔骰子差不多的。
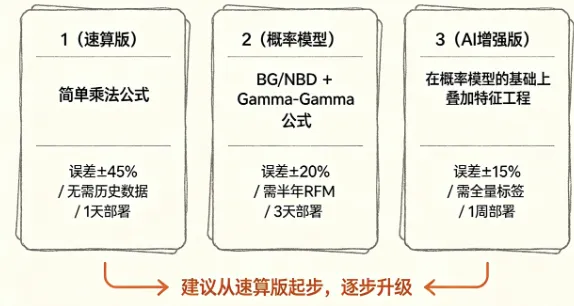
|
做法 |
误差 |
条件 |
|
|
起步 |
ARPU / 流失率 |
±45% |
有月均消费和流失率就行 |
|
上了量 |
BG/NBD + Gamma-Gamma |
±20% |
需要六个月以上的 RFM |
|
最精细 |
XGBoost + 画像 |
±15% |
日活三千以上,用户标签齐全 |
─────────────────────────
不看分布只看均值,交了学费
手上有三个版本的 LTV 了,按说够用了。结果还是摔了一跤。
有段时间我拿 LTV 当硬指标跟 CAC 直接比——渠道 A,CAC 180,LTV 1600,比值 8.9。渠道 B,CAC 240,LTV 1300,比值 5.4。一打眼就知道该把钱往渠道 A 放。
然后三个月后翻明细数据的时候翻出事了。渠道 A 的用户里边,40% 的消费额集中在 2% 的人身上。再往深了一查,这 2% 是老用户换了个手机号重新注册的,根本不是新客。把这部分剥掉之后渠道 A 的 LTV 掉到 780,比值从 8.9 变成 4.3。
渠道A 40%的消费额集中在2%的人身上。一查——老用户换号复购,根本不是新客。
渠道 A 那边的人跑过来问我:「为什么砍我们预算?」我说你们 LTV 虚高,里面掺了大量老用户换号复购的。人家不认。他们说那我换号复购也是从你投放来的嘛——我说不是,他们几个月前就用过产品了,只是换号再注册。来来回回搞了好几次沟通。
这件事逼着我改了习惯:算 LTV 之后加一步,看分布。
看均值不看分布,这个习惯我用了一个季度才改掉。改习惯比改代码费劲。
|
用户分群 |
LTV中位数 |
LTV P90/P10 比值 |
判断 |
|
渠道A |
¥340 |
18.2 |
头部占比太高,渠道质量可疑 |
|
渠道B |
¥280 |
6.1 |
分布均匀,渠道质量稳 |
|
渠道C |
¥410 |
4.8 |
高质量且稳定 |
渠道 A 的 P90 除以 P10 是 18.2。顶部一小撮人贡献了绝大部分,底下基本上全是无效的。渠道 B 的比值 6.1,虽然中位数看着比 A 低一点,但质量是均匀的。
之后我把投放预算从渠道 A 往渠道 B 挪了大概三成。三个月后整体 ROI 从 2.1 涨到 2.7。挪这三成我犹豫了快一个季度——倒不是不知道怎么算 P90 除以 P10,是习惯性的看完均值就下决定了,根本想不起来再看一眼分布。改掉这个习惯花了蛮长时间。
────────────────────────
后来用 OpenClaw 搭成自动的了
LTV 这个东西你得盯着,它不是算一次能管三个月的。用户群在变,渠道质量在变,什么时候上了个活动,数据就能给你拐一道弯。一个月前跑出来的结果,过一个月再看已经不能用了。
LTV不是算一次管三个月的。用户群在变、渠道在变、上个活动数据就能拐弯。
年初我把整套东西用 OpenClaw 迁成了自动的。做了两件。
每月全量刷新。一号凌晨把过去 12 个月的数据拉出来,跑一圈 XGBoost,预测全量用户的未来 180 天 LTV,结果直接写业务数据库的 ltv_prediction 表里。投放系统读这张表。
yaml
# OpenClaw cron 配置:每月刷新LTVjob:name: ltv_monthly_refreshschedule:kind: cronexpr: “0 3 1 * *”payload:kind: agentTurnmessage: >执行LTV月刷新:1. 从业务库拉取最近12个月全量用户行为数据2. 更新用户标签(活跃度/消费/优惠敏感/品类偏好)3. 用XGBoost重新训练模型并预测全量用户未来180天LTV4. 将结果写入 ltv_prediction 表5. 推一份汇总报告到飞书群
每日预警。每天拉当周新用户的预估 LTV,跟三个月前同期的做比较。哪个渠道的 LTV 中位数连着 7 天低于历史均值 20% 往上,自己推一条到群里。
yaml
# OpenClaw cron 配置:每日LTV偏差预警job:name: ltv_daily_alertschedule:kind: cronexpr: “0 9 * * *”payload:kind: agentTurnmessage: >执行每日LTV预警:1. 拉取最近7天新用户按渠道聚合的预估LTV2. 与3个月前同渠道同期均值做比较3. 偏差超过20%的渠道,生成预警并推送到飞书群
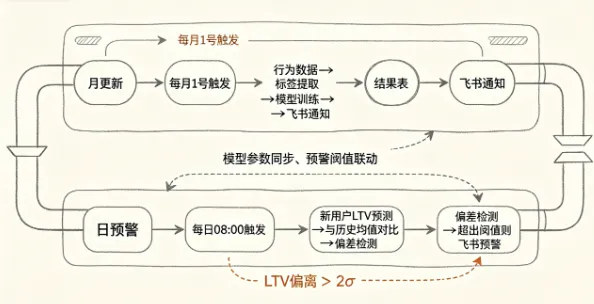
以前自己搭这个调度办法也想过——Python 脚本套 crontab,再加日志和容错,每次想改个东西还得开 IDE 调。迁到 OpenClaw 以后配置拆成 yaml 了,改起来不用动代码,群里直接能看到每次跑的情况。
但让我觉得值这件事的,倒不是省了多少时间。是团队里每个人都能看到 LTV 的变化曲线,不用再跑过来问我「蛋蛋,昨天那个决策为什么今天看着不对了」。大家自己看。
────────────────────────────
跑偏了说远了啊。反正 LTV 这个事情,总结下来我自己踩的最大的一个跟头就是看均值不看分布。这个东西不是多难的数学,是习惯。改习惯比改代码费劲。