 夜雨聆风
夜雨聆风





把生信分析做成一次对话:我在 Bio-OpenClaw 项目里看到的东西

这两年大家聊 AI Agent,常见的场景是写代码、整理文档、做客服。
但说实话,我一直觉得,真正值得期待的地方不只是“让 AI 回答问题”,而是让它进入那些流程复杂、工具分散、结果又必须可追溯的专业场景里。
比如生物信息分析。
我最近看了一个实际项目:Bio-OpenClaw Platform。它不是一个单点脚本,也不是简单套一层聊天框,而是把 OpenClaw Agent、专业生信流程、任务系统、知识库和 Web 平台整合到了一起。
一句话概括:
它想把“生信分析”从命令行里的长流程,变成一次可对话、可追踪、可复用的工作流。
先看它解决的是什么问题
传统生信分析,尤其是 mNGS、RNA-seq、单细胞这类流程,通常会遇到几个很现实的问题:
-
• 工具链长:fastp、Bowtie2、Kraken2、Bracken、Seurat、DESeq2、ggplot2……每一步都有参数。 -
• 环境复杂:本地、服务器、集群、数据库、参考基因组,经常要来回切。 -
• 过程难追踪:命令跑到哪一步、日志在哪、结果文件是哪一版,时间一久就容易混。 -
• 经验难复用:一个工程师调好的流程,很难直接变成团队可以稳定复用的能力。 -
• 新人上手慢:不是不会分析,而是不知道该从哪一步开始问、怎么判断结果是否靠谱。
Bio-OpenClaw 的思路,是把这些东西拆成几个平台能力:
自然语言对话负责入口,Skill 负责流程复用,任务引擎负责执行和追踪,知识库负责专业上下文。
这个设计挺务实。
它没有试图让 AI “凭空懂生信”,而是把 AI 放在一个有工具、有文档、有任务状态、有结果文件的系统里。
这个项目现在长什么样
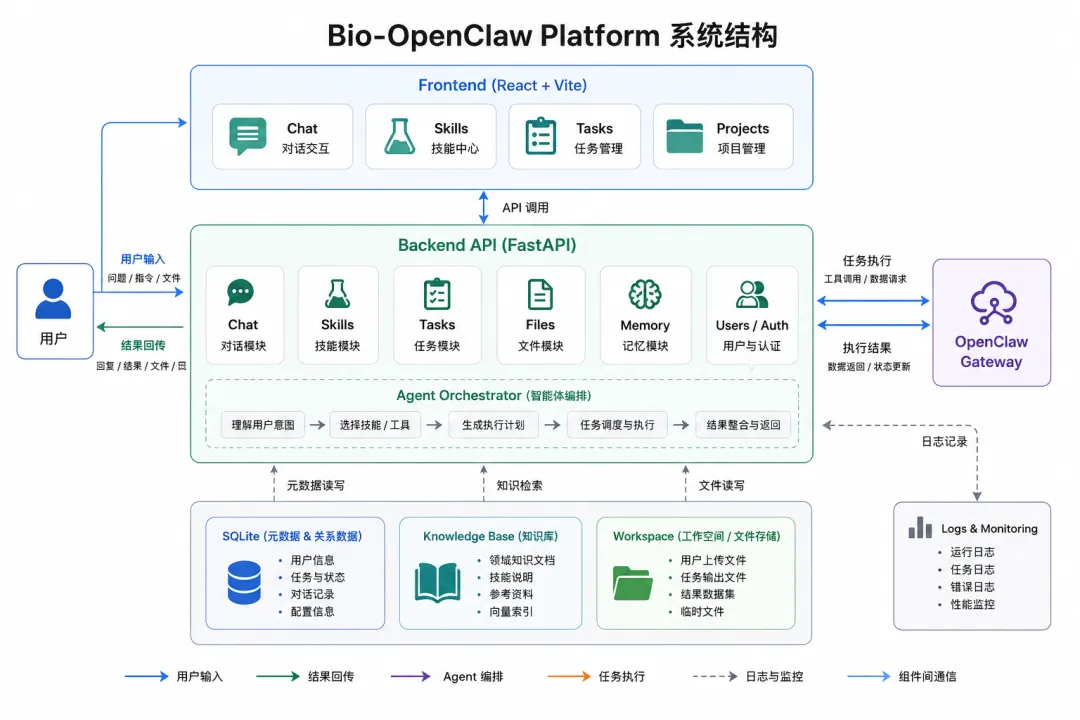
从项目结构看,它已经是一个完整的前后端平台。
后端是 FastAPI + SQLite + WebSocket/SSE,前端是 React 19 + Vite,AI 底座通过 OpenClaw CLI / OpenClaw Gateway 接入。
项目里能看到这些核心模块:
-
• chat:对话与流式回复 -
• skills:Skill 创建、发布、版本管理、文件管理 -
• tasks:异步任务、日志、进度、结果预览 -
• projects:项目管理与项目文件空间 -
• files:个人知识库、个人云盘、共享知识库 -
• memory:Agent Memory 记忆系统 -
• users/auth:用户、角色、JWT 登录认证
我也看了一下服务状态,项目并不是停在文档阶段:
-
• 后端服务在 8000端口运行 -
• OpenClaw Gateway 在 18789端口运行 -
• 前端 Vite 服务也在运行 -
• SQLite 数据库里已经有用户、对话、项目、任务和 Skill 数据
当前数据库里有:
-
• 2 个用户 -
• 8 个 Skills -
• 4 个项目 -
• 8 个任务 -
• 69 条消息
这说明它已经经历过一定程度的真实使用和调试,而不是刚初始化出来的空壳。
最有意思的是 Skill 机制
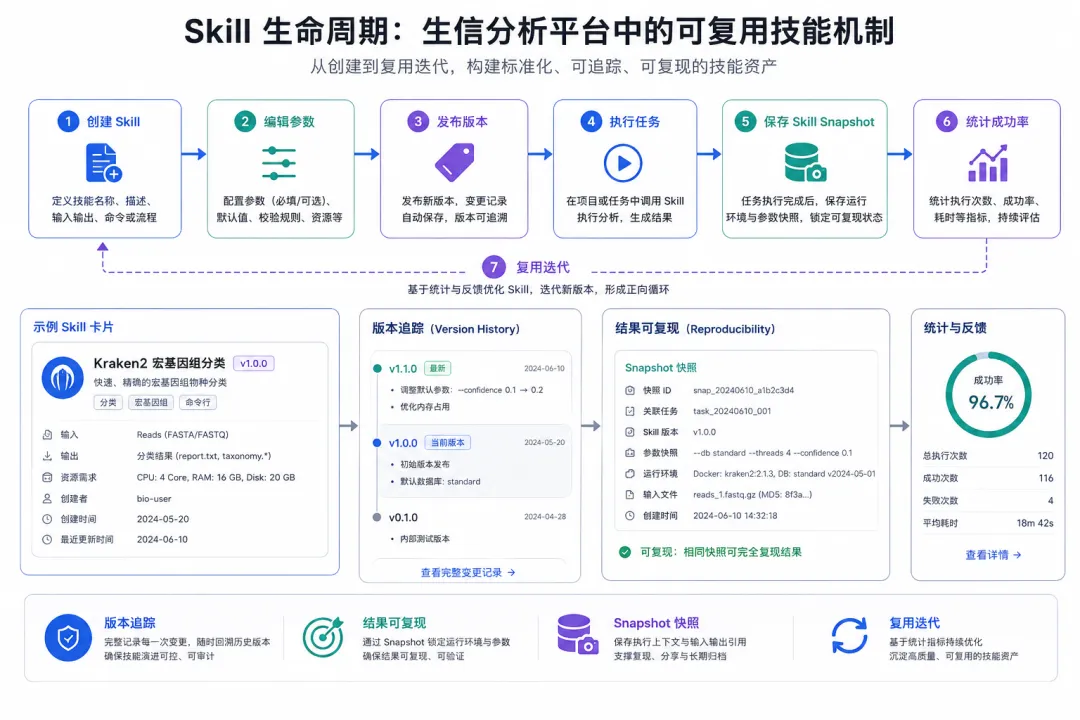
Bio-OpenClaw 里最值得写一笔的,是它的 Skill 技能市场。
这里的 Skill 不只是一个“提示词模板”,而是把一个分析流程封装成可管理、可发布、可版本追踪的能力单元。
项目里内置了多个生信 Skill,例如:
-
• fastp 质控 -
• DESeq2 差异表达分析 -
• 火山图生成 -
• Seurat 单细胞聚类 -
• Kraken2 宏基因组分类
每个 Skill 可以有描述、版本、参数、依赖、资源文件和执行统计。
更关键的是:任务执行时会保存 Skill Snapshot。
这点很重要。
因为生信分析最怕的一件事,就是几周后回头看结果,发现当时用的流程已经被人改过了,参数也不确定了。
Bio-OpenClaw 的做法是,在任务执行时把当时的 Skill 内容保存下来。这样后面即使 Skill 升级了,仍然可以知道某次任务到底是按哪个版本跑出来的。
这就把“AI 帮我跑一下”往“结果可复现”方向拉了一步。
在科研和临床相关场景里,这一步非常关键。
对话不是聊天,而是任务入口
很多 AI 平台的问题是:聊天归聊天,真正干活还得人自己打开终端。
Bio-OpenClaw 的设计更进一步。
用户可以在对话里描述需求,比如:
帮我对这批 mNGS FASTQ 做质控、宿主去除和 Kraken2 分类,并输出结果摘要。
平台后端会把对话消息保存到数据库,同时调用 OpenClaw Agent,让 Agent 结合 Skill、知识库和项目文件去编排执行。
任务一旦被创建,就进入异步任务系统:
-
• 后台子进程执行,不阻塞主服务 -
• 前端通过 SSE 流式显示 AI 回复 -
• WebSocket 推送任务进度与状态 -
• 页面里可以查看日志、取消任务、预览结果文件 -
• 任务卡住时有自动清理机制
我看到代码里还做了一个很细的处理:如果任务被标记失败,但输出目录里其实已经有结果文件,系统会自动把状态纠正为完成。
这就是实际跑任务后才会遇到的问题。
写平台的人明显不是只做了一个 Demo,而是在处理真实异步任务系统里的麻烦事。
它的知识库不是摆设
项目里有一个 knowledge-base 目录,里面放了一批面向生信分析的文档。
包括:
-
• 单细胞 RNA-seq 分析指南 -
• mNGS 宏基因组分析流程 -
• 常用 R / Python 生信包速查 -
• 参考基因组与数据库说明 -
• 常见病原体速查表 -
• FASTQ、10x、CSV、BAM 等数据格式规范 -
• 临床 mNGS SOP -
• 10x 单细胞 SOP -
• 参数推荐值 -
• 故障排查 FAQ
这部分特别适合和 Agent 结合。
因为生信问题并不只是“命令怎么写”,还包括:
-
• 为什么这一步要这么做? -
• 这个参数该怎么取? -
• 结果异常时怎么判断? -
• 不同样本类型的阈值是否一样? -
• 哪些数据库适合当前场景?
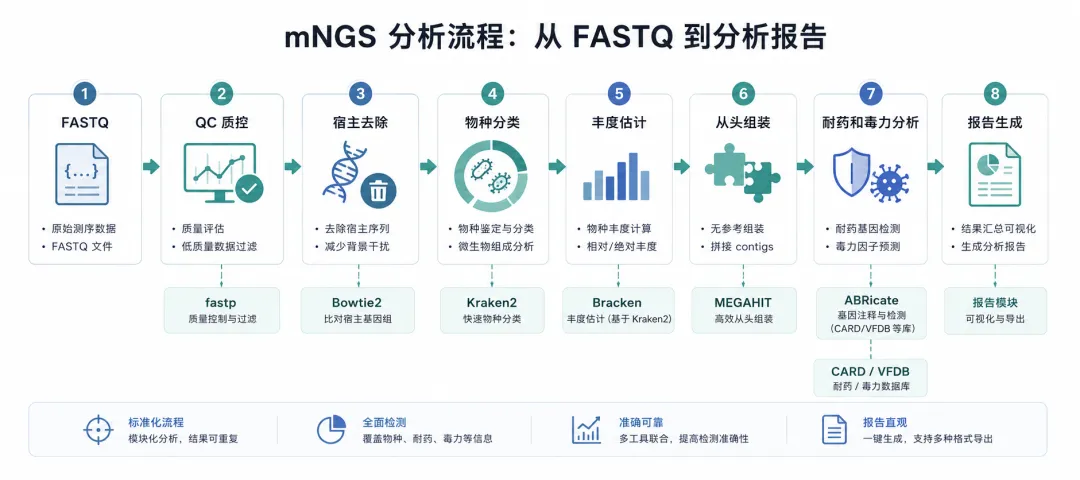
比如 mNGS 文档里,把分析流程写成了:
FASTQ → QC → 宿主去除 → 物种分类 → 丰度估计 → 组装 → 耐药/毒力分析 → 报告生成
并且给出了 fastp、Bowtie2、Kraken2、Bracken 等步骤的参数解释和指标判断。
这意味着 Agent 不只是调用工具,还能在回答时引用平台维护的专业知识。
对团队来说,这其实是在沉淀“组织经验”。
技术架构:不花哨,但挺稳
从工程实现看,这个平台的技术选型偏实用。
后端用 FastAPI,负责 API、认证、数据库、任务调度、WebSocket 和 OpenClaw 调用。
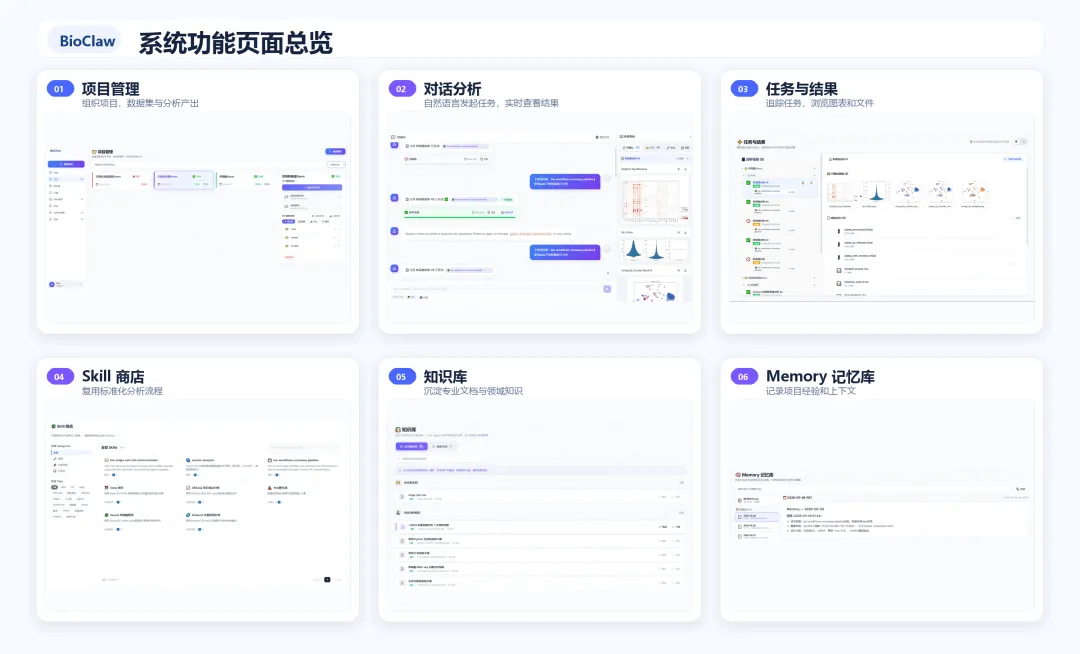
前端用 React + Vite,页面包括:
-
• 对话页 -
• Skills 页面 -
• 任务面板 -
• 项目管理 -
• 结果页 -
• 知识库 -
• 云盘 -
• Memory 页面 -
• 设置与用户管理
数据库用 SQLite + aiosqlite。
这点我反而觉得是优点。
很多内部工具一上来就把部署链路做得很重,结果真正使用的人还没进来,维护成本先上去了。
Bio-OpenClaw 选择 SQLite,意味着它可以先用一个轻量数据库把核心闭环跑起来:用户、对话、消息、项目、任务、Skill、设置。
等到团队规模、任务并发、审计要求真的上来,再考虑更重的数据库也不迟。
另外,项目有自动迁移逻辑。新增字段时不是手动删库重建,而是检查列是否存在,再安全添加。
这种细节很朴素,但对一个会持续迭代的平台来说,挺重要。
我觉得它的价值在三个地方
第一,把“会跑流程”变成“会沉淀流程”
生信团队里经常有隐形知识:
某个参数为什么这么设、某个样本类型怎么判断、某个工具版本有哪些坑。
过去这些知识散落在脚本、群聊、个人笔记里。
Bio-OpenClaw 用 Skill 和知识库把它们收进平台,至少提供了一个可以持续沉淀的容器。
第二,把“黑盒执行”变成“过程可见”
对分析任务来说,用户最焦虑的不是等,而是不知道发生了什么。
这个平台把任务进度、步骤、日志、结果文件预览都放到前端。哪怕任务还在跑,用户也能看到状态。
这会明显降低沟通成本。
第三,把“AI 对话”接到真实系统
很多 AI 应用停在“建议你这样做”。
Bio-OpenClaw 想做的是“我帮你把这件事推进到任务系统里,并且留下记录”。
这就是 Agent 产品和普通聊天机器人的分界线。
当然,它也还有继续打磨的空间
从当前项目状态看,它已经有完整骨架和真实运行痕迹,但如果要走向更大范围使用,我会重点关注几件事:
-
• 权限体系是否要细化到项目、文件、Skill 级别 -
• 任务执行环境是否需要容器化,减少依赖漂移 -
• Skill 的输入输出协议是否要进一步标准化 -
• 结果报告是否能形成固定模板,便于交付和归档 -
• 临床相关场景是否需要更严格的审计日志 -
• 高并发任务是否要从本地子进程升级到队列或集群调度
这些不是否定,反而说明这个项目已经进入“平台化”问题域了。
真正有用的系统,才会遇到这些问题。
写在最后
我看完 Bio-OpenClaw 最大的感受是:
它没有把 AI 当成一个漂在页面上的聊天框,而是把 AI 嵌进了生信分析的工作现场。
对用户来说,入口是自然语言。
对工程来说,背后是任务、日志、文件、权限、版本和知识库。
对团队来说,真正沉淀下来的不是一次回答,而是一套可以复用、可以追踪、可以继续演化的分析能力。
这可能也是 AI Agent 在专业领域里更值得期待的方向:
不是替代专家,而是把专家的流程、判断和经验,变成团队可以持续使用的系统。
如果说过去的生信平台解决的是“把工具装起来”,那么 Bio-OpenClaw 想往前走一步:
让分析过程能被对话启动,被任务系统承接,被知识库增强,被 Skill 长期复用。
这一步,挺值得继续看下去。