 夜雨聆风
夜雨聆风





你以为你在做RAG,实际上你卡在PDF第一公里
很多团队做知识库问答,第一步就写错了。
他们把 PDF 当成“可复制文本”,却忽略了 PDF 本质上是“排版结果”。结果就是:模型看起来读了文档,实际上读的是一堆顺序错乱、表格断裂、标题消失的碎片。
你以为问题在召回、在 embedding、在 prompt。但真正的瓶颈,往往在更早的一步:解析。
这也是我最近关注 opendataloader-pdf 这个项目的原因。它给了一个很清晰的思路:PDF 解析不是 OCR 工具链拼接,而是结构化理解。
一、RAG 为什么总“答非所问”?
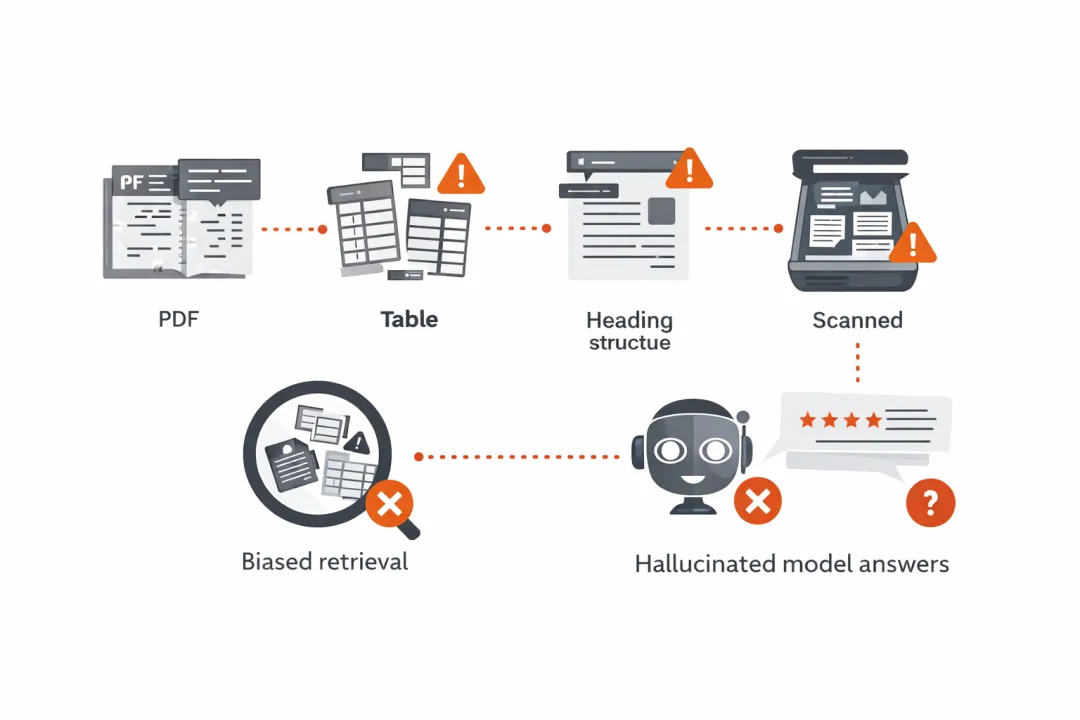
先看几个高频现场:
-
双栏论文被串成一条“蛇形文本”,上下文断裂。 -
财务表格被拆碎,行列关系丢失。 -
标题层级丢了,chunk 切分只能靠字符数硬切。 -
扫描件识别出文字,但结构没了,引用定位做不准。
这些问题不是“小瑕疵”。它直接决定你的 RAG 是“能演示”,还是“能上线”。
一句话总结:没有结构,RAG 只有检索,没有理解。
二、这个项目做对了什么?
opendataloader-pdf 的定位很直接:把 PDF 转成 AI 可用的数据,而不是仅仅“导出文本”。
它的核心输出包括:
-
Markdown(便于阅读与快速接入) -
JSON(包含元素级 bounding boxes,便于可追溯引用) -
HTML(方便渲染和二次处理)
并且它同时支持 Python / Node.js / Java 三套 SDK,这对企业团队很关键:算法同学、后端同学、平台同学可以用同一套解析能力,不必重复造轮子。
三、为什么我认为它值得关注:不是“能用”,而是“有指标”
开源项目最怕“只讲功能,不讲结果”。这个项目相对扎实的一点是,它把 benchmark 指标放在了台面上。
在公开对比里,它的 hybrid 模式给出的核心数据是:
-
Overall:0.90 -
Reading Order:0.94 -
Table:0.93 -
Heading:0.83
而本地确定性模式(非 hybrid)速度可到 0.05s/页。这意味着你可以按文档复杂度做策略分流:
-
普通数字 PDF:走本地快模式,优先吞吐 -
复杂表格/扫描件/公式图表:走 hybrid,优先准确率
这不是“二选一”,而是“按场景分层”。

速度和准确率不是非此即彼,分层解析策略可以同时拿到吞吐与质量。
四、它还有一个更大的方向:可访问性自动化
多数人只看到“给 LLM 喂数据”,但企业侧还有另一条硬需求线:无障碍合规。
EAA、ADA/Section 508 等要求正在收紧,很多组织面临同一个现实:人工做 PDF remediation,贵、慢、不可规模化。
这个项目公开提到的路线是:
-
已支持 Tagged PDF 结构提取(对已有标签文档直接利用) -
计划在 2026 年 Q2 推出 Auto-Tagging(untagged -> tagged) -
PDF/UA 导出属于企业能力层
如果这条路线跑通,价值不只是“让 AI 读懂”,而是“让文档体系合规化生产”。

从人工修复到自动打标,PDF 可访问性正在从“合规成本”变成“工程能力”。
五、给技术团队的落地建议
如果你正在做知识库或文档中台,我建议按这三步落地:
-
先把解析产物升级为“结构化资产”不要只存纯文本,至少保留标题层级、表格、坐标信息。
-
做“文档复杂度分流”普通文档走快路径,疑难文档走高精度路径,别让所有文件都走同一条 pipeline。
-
提前布局 tagged 文档策略即便你今天不做合规,明天也可能被业务逼着做。结构化能力越早建设,迁移成本越低。
六、30 秒起步(Python)
import opendataloader_pdfopendataloader_pdf.convert( input_path=["file1.pdf", "file2.pdf", "folder/"], output_dir="output/",format="markdown,json")先跑一个最小闭环:“解析 -> chunk -> 入库 -> 检索 -> 引用回溯”。只要你把这条链路打通,后面模型升级、向量库切换,都会轻松很多。
项目地址:
https://github.com/opendataloader-project/opendataloader-pdf结语
我们总说“AI 落地”,但很多项目失败,不是因为模型不够强,而是因为输入不够干净。PDF 这件小事,往往就是系统质量的分水岭。
你喂给模型的是文本碎片,还是文档结构,决定了它最后给你的,是答案,还是幻觉。