 夜雨聆风
夜雨聆风





小红书发布MOCR:3B参数模型解析文档所有内容,图形全部还原,超越Gemini 3 Pro
一句话讲清楚👉🏻 小红书HiLab团队与华中科技大学联合推出dots.mocr,这是一个3B参数的多模态OCR模型,不仅能识别文字,还能将文档中的图表、图标、公式等图形元素解析为可执行的SVG代码,在多个基准测试中超越Gemini 3 Pro。
传统OCR的”丢图”之痛
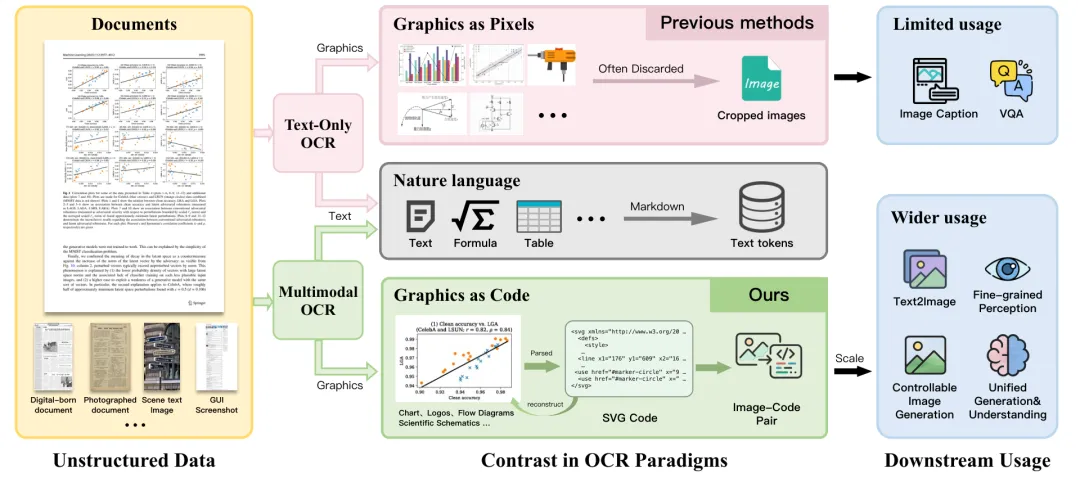
用过传统OCR工具的人都有体会:当你把一份包含图表的文档丢进去,文字倒是识别出来了,但文档中的柱状图、流程图、示意图这些图形元素呢?要么被裁剪成一张像素图贴回去,要么直接被忽略。这些精心设计的图表所承载的结构化信息,在OCR的输出中就这样丢失了。
这就像一个人读完一本图文并茂的教材后,能把文字内容转述给另一个人,但描述图表时只会说”这里有一张图”——然后把图片截图发过去。对方拿到的是一张位图,无法编辑、无法检索、无法复用。
这个问题在AI时代变得更加棘手。大语言模型和多模态模型的训练需要海量高质量的结构化数据,而文档中那些信息密度极高的图表、流程图、UI界面等视觉元素,恰恰是最有价值的监督信号来源。传统OCR管线把这些信号当作”垃圾像素”扔掉了。
MOCR:重新定义文档解析
针对这个问题,小红书HiLab团队和华中科技大学的研究团队提出了一个全新的文档解析范式——MOCR(Multimodal OCR,多模态OCR)。
MOCR的核心理念很简单也很颠覆:文档中所有承载信息的元素都应该被当作一等公民来解析。不只是文字,还包括图表、示意图、UI组件、图标、化学结构式等等。这些视觉元素不再被当作像素裁剪掉,而是被解析为可执行、可编辑、可组合的结构化代码(主要是SVG)。
具体来说,给定一张输入图像 ,MOCR会生成一个有序的解析元素序列 :
其中每个元素包含三个部分:$\mathcal{B}{k}c{k}p_{k}$ 则是对应的内容载荷。
的内容取决于 的类型:对于文本类区域, 是文本转录(纯文本、表格标记或LaTeX公式);对于可以用程序化方式描述的视觉符号(如UI组件、图标、图表), 则是可渲染的SVG代码。对于那些无法用简洁代码描述的复杂自然图像,则保留为像素内容。
这个范式带来了三个显著优势:
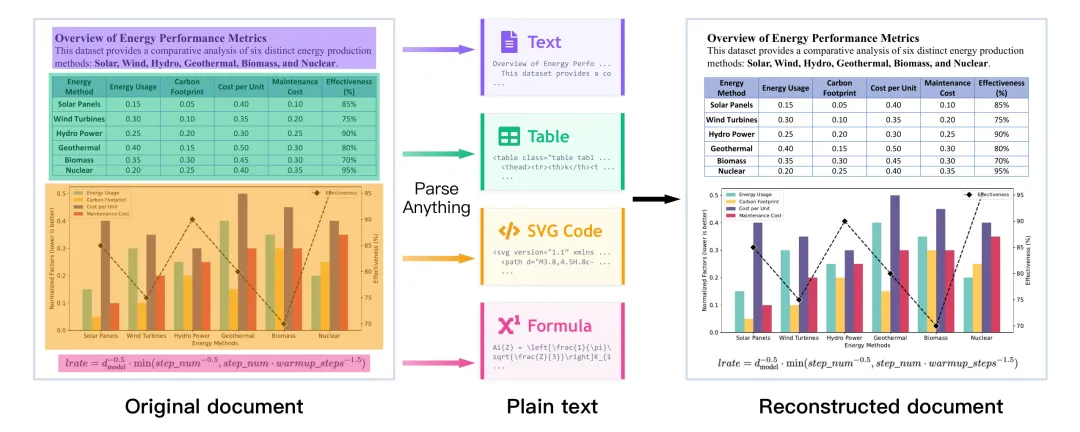
(1)结构化重建:文本和图形都被解析为结构化输出,实现更忠实的文档重建。你拿到的不再是一堆零散的文字和图片,而是一份可以重新渲染的完整文档描述。
(2)端到端训练:支持在异构文档元素上进行端到端训练,模型可以利用文本和视觉组件之间的语义关系。文字和图表不再被割裂处理,而是作为一个整体来理解。
(3)解锁监督信号:把以前被丢弃的图形转化为可复用的代码级监督信号,从现有文档中解锁多模态监督。这意味着海量PDF文档中隐藏的图表信息终于可以被利用起来了。
dots.mocr:3B参数的小巨人
有了MOCR这个范式,研究团队开发了dots.mocr这个具体系统。整个模型只有3B参数(视觉编码器1.2B + 语言模型Qwen2.5-1.5B),却能在多个基准测试上与参数量远超自己的模型掰手腕。
模型架构
dots.mocr的架构包含三个核心组件:
高分辨率视觉编码器:这是一个从零训练的1.2B参数视觉编码器。选择从零训练而不是复用已有模型,是为了让编码器能够原生适配文档解析任务,在密集文本和几何敏感的视觉符号(如图表、示意图)之间建立联合建模能力。该编码器能够处理最高约1100万像素的原生高分辨率输入,这对于保留细粒度细节和维持跨页面的长程空间一致性至关重要。
轻量级多模态连接器:作为视觉编码器和语言解码器之间的桥梁,负责将视觉特征映射到语言模型的输入空间。
结构化语言解码器:基于Qwen2.5-1.5B初始化。选择1.5B参数量是一个经过深思熟虑的权衡——小于1.5B的模型往往难以同时处理异构页面内容(文字、布局结构、视觉符号)并在单次自回归解码中生成长且高度结构化的SVG程序;而更大的解码器会显著增加训练和推理成本。选择基座模型而非聊天专用模型作为初始化,为大规模预训练提供了中性的起点。
分阶段训练策略
训练策略的核心是数据驱动。研究团队设计了三个连续的预训练阶段:
第一阶段:建立稳定的视觉-语言接口,通过通用视觉训练让语言模型能够可靠地消费视觉token并在视觉输入上锚定生成。
第二阶段:在通用视觉数据和纯文本文档解析监督的统一混合数据上进行广泛预训练,建立强大的文本解析基础,同时维持通用视觉鲁棒性。
第三阶段:逐步减少通用视觉数据比例,增加MOCR特定目标的权重,强化OCR解析和视觉符号解析(即图像到SVG转换)。所有阶段都使用单一的自回归目标,通过混合重加权和课程调度来控制优化稳定性。同时跨阶段逐步提高输入分辨率,以匹配密集页面解析和长序列结构化生成的难度增长。
预训练之后,使用数据引擎构建的高质量监督集进行指令微调。团队还发布了两个检查点:dots.mocr和dots.mocr-svg,后者在SFT阶段增加了SVG数据比例并加权更难的SVG程序,以在相同参数预算下更好地优化图像到SVG的解析。
数据引擎:从PDF到SVG的全链路
训练这样一个统一的MOCR模型,对数据的要求极为苛刻。除了常规的多语言、多样布局外,模型还需要学习将视觉符号解析为可复用的结构化表示。现有的任何数据集都无法在足够规模和质量上提供这种覆盖。
研究团队从四个互补来源构建了训练语料:
PDF文档:使用dots.ocr作为自动标注引擎,从原始PDF中构建多语言文档解析监督。通过分层采样(按语言、领域和布局复杂度)来强调困难样本。
网页:爬取并渲染网页为图像,转换为与PDF相同的MOCR解析格式。网页天然具有高分辨率和复杂布局,并提供HTML/DOM对齐的结构化信号来减少标注噪声,同时提供大量原生SVG图标、图表和UI组件。
SVG图形:从网络上收集SVG资产,渲染后构建图像-SVG配对。数据管线包括清洗(使用svgo去除无关元数据、标准化数值精度)和采样(领域级平衡和复杂度感知采样)两个阶段。
通用数据:包括通用视觉和OCR监督(如定位和计数),以保持与页面级解析并行的广泛能力。
实验结果:多项SOTA
文档解析:仅次于Gemini 3 Pro
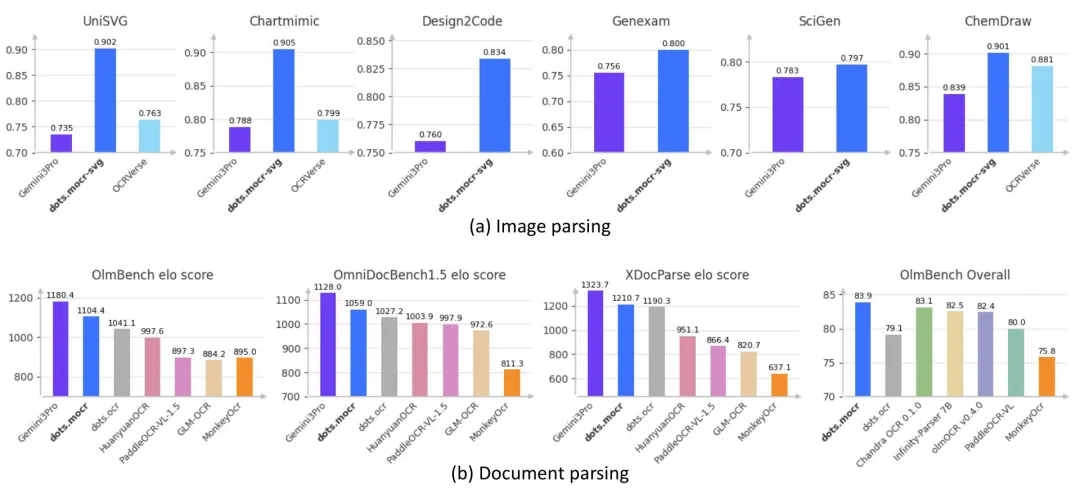
在文档解析的Elo评估中,dots.mocr在所有三个基准测试(olmOCR-Bench、OmniDocBench 1.5和XDocParse)上都取得了开源模型中的最强表现,仅次于闭源的Gemini 3 Pro。具体来说,dots.mocr的平均Elo评分为1124.7,远超排名第三的dots.ocr(1086.2)和其他开源竞品。
在olmOCR-Bench的详细类别分解中,dots.mocr在ArXiv(85.9)、旧扫描数学文档(85.5)、表格(90.7)和多栏布局(85.3)四个类别上取得了最高分,总体得分83.9创下了新的SOTA。
结构化图形解析:超越Gemini 3 Pro
在结构化图形解析方面,dots.mocr-svg的表现更加亮眼。在UniSVG基准上,dots.mocr-svg的整体ISVGEN评分为0.902,超越OCRVerse的0.763和Gemini 3 Pro的0.735。
具体来看,在ChartMimic(图表到代码)上得分0.905,Design2Code(网页布局)上得分0.834,ChemDraw(化学结构式)上得分0.901,均大幅超越Gemini 3 Pro。这说明一个3B参数的开源模型在结构化图形重建方面已经可以超越最强的闭源商业模型。
通用视觉语言能力
虽然dots.mocr主要面向多模态结构化解析,但在通用视觉语言基准上也保持了高度竞争力。在CharXiv的描述性任务上得分77.4(超越Qwen3-VL-4B的76.2),在推理任务上得分55.3(大幅超越4B模型的39.7)。在DocVQA(91.85)、ChartQA(83.2)、OCRBench(86.0)和CountBenchQA(94.46)等任务上也取得了稳健的表现。
定性效果:它到底能做什么?
理论说再多,不如看看实际效果。研究团队展示了dots.mocr在多种场景下的定性结果。
文档布局解析
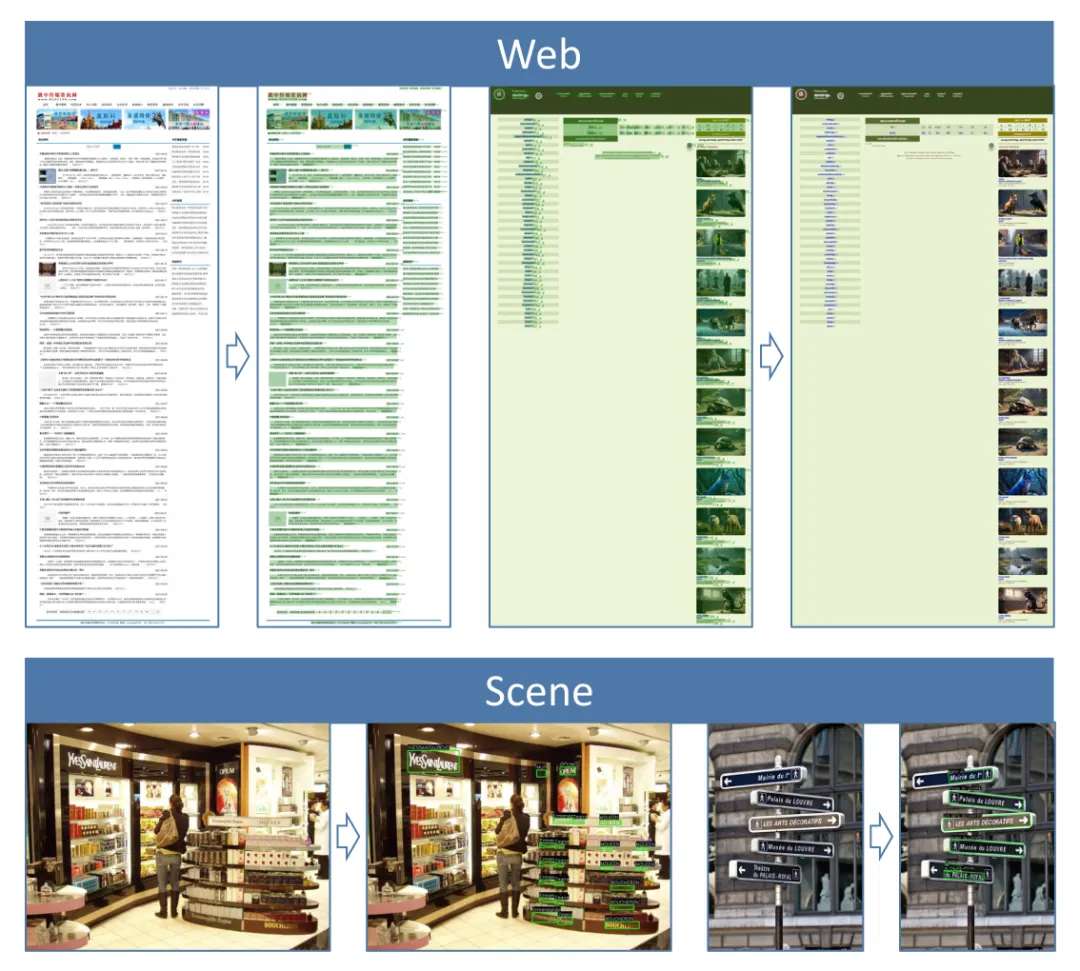
dots.mocr能够对异构文档进行稳健的布局分析,处理多语言页面、复杂多栏布局、密集表格、数学公式、扫描材料和手写笔记。它还能解析全长网页截图,保留全局阅读顺序和结构化组件。

图标SVG重建
dots.mocr-svg可以将光栅图标转换为简洁可执行的SVG代码,捕获几何原语、层次分组和空间关系,实现可缩放的矢量级重建。

统计图表重建
对于各种统计图表(柱状图、折线图、散点图和复合可视化),dots.mocr-svg能恢复图表结构、坐标轴、图例、数据编码和语义分组,生成可编辑和可复用的矢量输出。
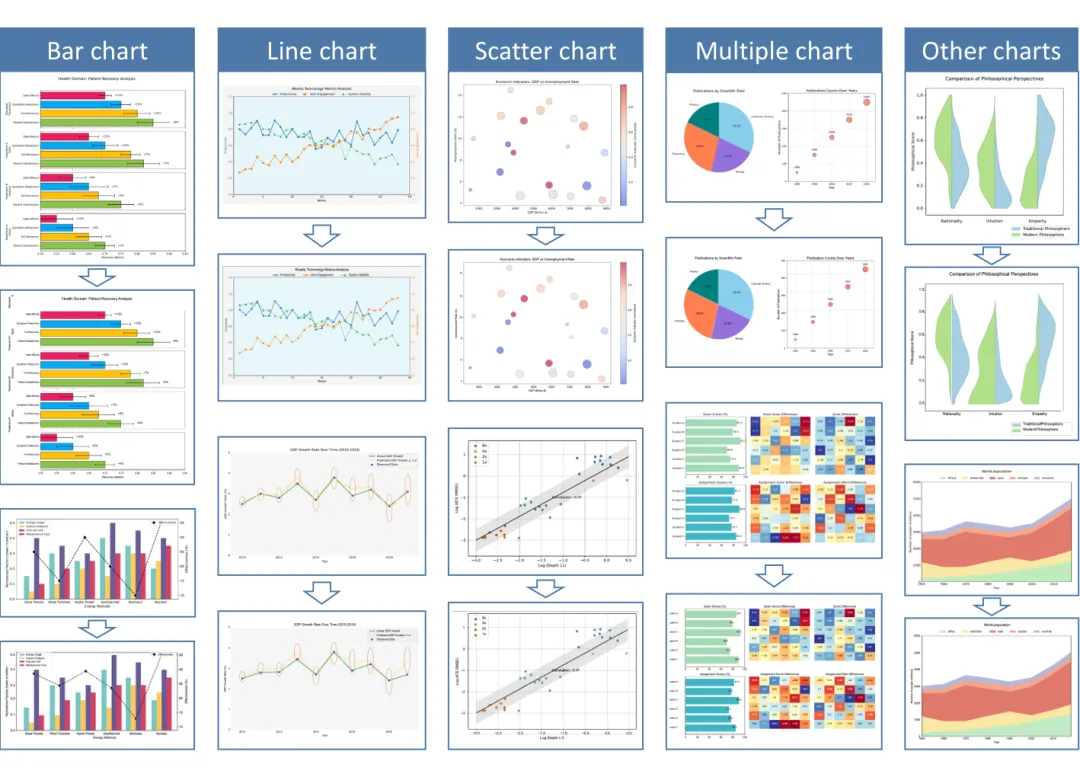
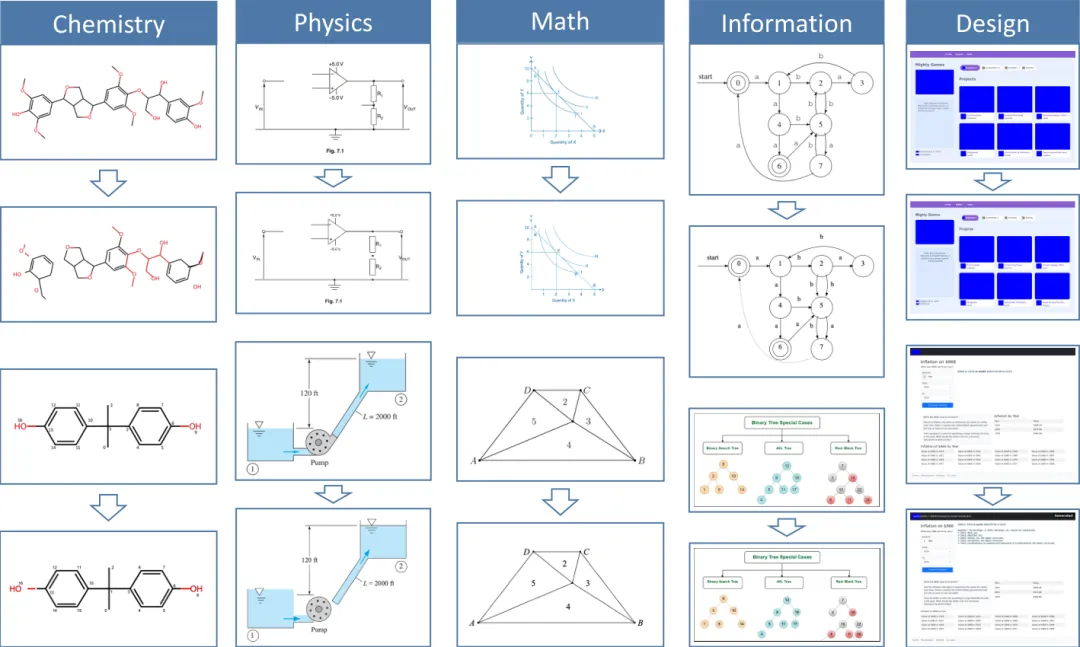
跨学科复杂图示
模型还能处理科学和设计领域的跨学科复杂图示,捕获复杂的几何结构、语义组件和层次组织,展示了超越标准图表的领域泛化能力。
通用视觉问答
在保持强大文档解析和SVG重建能力的同时,dots.mocr还能对文档、图表、UI截图和复杂图示产生连贯且上下文感知的回答,表明其在更广泛的视觉语言任务中也具有竞争力。

创新的评估方法:OCR Arena
值得一提的是,研究团队还提出了一个创新的评估框架——OCR Arena。
传统的OCR评估指标如WER(词错误率)或NED(归一化编辑距离)存在一个根本问题:它们依赖基于规则的匹配来对比真值,对语义等价但序列化方式不同的输出过于敏感。比如一个公式用不同的LaTeX写法表达,语义完全一致,但基于字符串匹配的指标会给低分。
OCR Arena采用了LLM-as-a-Judge范式:让一个高容量的视觉语言模型(如Gemini 3 Flash)作为评委,给定原始文档图像和两个模型生成的Markdown转录,判断哪个结果在保真度、结构和格式上更好。
为了消除LLM评委的位置偏差(倾向于选择先出现的候选),团队采用了严格的对称评估协议:每对模型A和B的对比都进行两次试验,一次A在前,一次B在前。只有当评委在两次试验中判断一致时才计入胜利,否则视为平局。所有结果通过Elo评分系统汇总,并使用1000次bootstrap重采样来增强统计稳健性。

更深远的意义:图像到代码的预训练数据引擎
MOCR的价值不仅仅在于一个更好的文档解析器。研究团队在论文中提出了一个更宏大的愿景:MOCR可以作为构建大规模图像到代码预训练语料的可扩展管线。
每一个被解析为SVG的图表,每一个被转换为结构化标记的示意图,都可以形成忠实的图像-代码-文本三元组,创建可控制、可扰动的训练数据。其规模仅受限于可用文档的数量。
而且MOCR范式是表示无关的。当前的实现使用SVG作为目标,但未来可以扩展到TikZ(科学图示)、D3.js(交互式可视化)、CAD格式(工程制图),或者化学结构和电路图等领域的专用标记语言。解析包含多样布局、嵌入式图形和多语言内容的完整网页,也极大地扩展了传统PDF为中心的语料库之外的可用训练数据池。
资源链接
📄 论文链接https://arxiv.org/abs/2603.13032
💻 代码仓库https://github.com/rednote-hilab/dots.mocr
🤗 模型权重https://huggingface.co/rednote-hilab/dots.mocr
🤗 SVG优化版本https://huggingface.co/rednote-hilab/dots.mocr-svg