 夜雨聆风
夜雨聆风





文献阅读系列|谁想用交通超级App?PLS-SEM与NCA联合分析的启示
顶刊文章读完,很多人的感受是:结论看懂了,但不知道他们怎么做到的。
这个系列就是干这件事——把分析过程拆开来,看清楚每一步在做什么、为什么这么做、换成你的研究能不能用。
今天拆的是发表在Transportation Research Part F(2025年)上的这篇:
Hasselwander, M. Who wants to use transport super apps? Insights from combined PLS-SEM and NCA methods.
研究问题本身不复杂:什么因素影响德国人使用交通超级App的意愿?
但分析框架值得细看——PLS-SEM + NCA双重分析,两套方法,两个维度,回答同一个研究问题里的两个不同问题。

先说清楚:他们要回答几个问题?
作者在引言里列了两个研究问题:
-
RQ1:哪些因素影响消费者的采纳意愿?
-
RQ2:哪些因素是必要条件?
这两个问题看起来相似,但逻辑上是不同的。
RQ1问的是”谁在推动结果”,RQ2问的是”谁是前提条件”。前者是充分性问题,后者是必要性问题。一套方法只能回答一个。这就是为什么要用两套方法——不是为了凑篇幅,是因为问题本身需要。
这是拆这篇文章最重要的第一步:搞清楚他们为什么要用两套方法,而不是一套
第一步:数据从哪来,怎么设计的
样本是575名德国智能手机用户,通过在线问卷收集,配额抽样(按性别、年龄、收入三个维度)。
有几个设计细节值得注意:
为什么是575而不是原始的1019?
作者从1019份有效问卷里,筛选出”把交通服务列为超级App最重要功能之一”的受访者,最终得到575份。这个筛选逻辑很关键——研究的是交通超级App,而不是超级App本身,所以只保留对这个核心服务有明确偏好的人,样本更精准。
共同方法偏差怎么处理的?
三个措施:匿名保证、预测变量和结果变量在问卷中时间上分开(不是紧挨着问)、事后跑Harman单因子检验。结果显示第一个公共因子只解释了40.6%的方差,低于50%的警戒线,说明共同方法偏差不是问题。
理论框架用的是UTAUT2,选了五个潜变量:
-
绩效期望(PE)
-
努力期望(EE)
-
社会影响(SI)
-
价格价值(PV)
-
习惯(HA)
-
外加性别、年龄、App疲劳三个控制变量
-
因变量是行为意愿(BI)
测量模型先评估,结构模型再估计。
这个顺序不能反,很多人省了第一步直接看路径系数,是不规范的。
测量模型评估看了三件事:
-
因子载荷是否都超过0.708(条目可靠性)——全部达标,只有一个HA的条目0.65不达标,直接删掉

-
AVE是否超过0.5(收敛效度)——全部达标
-
HTMT比率是否低于0.90(区分效度)——全部达标
测量模型没问题,才进入结构模型。
结构模型用的是Bootstrap10000次抽样来计算t值和置信区间,10000次是常见规范,比默认的5000次更精确。
路径系数结果:
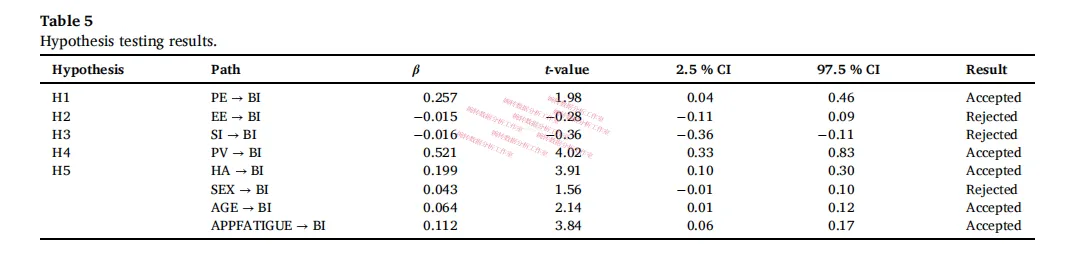
三个假设被支持,两个被拒绝:
-
✅ PE绩效期望:显著正向(β = 0.257)
-
✅ PV价格价值:显著正向,且效应最强(β = 0.521)
-
✅ HA习惯:显著正向(β = 0.199)
-
❌ EE努力期望:不显著
-
❌ SI社会影响:不显著
整体R²=0.78,解释力很强。
控制变量里,年龄越大,采纳意愿越强(β = 0.064)——这有点反直觉,但细想合理:老年人对打车、外卖等服务需求更大,年轻人反而更看重社交类超级App。
“App疲劳”显著正向影响采纳意愿(β = 0.112)——这也很有意思:越觉得手机App太多、越烦的人,反而更想用超级App来”一站式解决”。
PLS-SEM跑完,作者直接提取了各潜变量的复合得分(composite scores),把这些得分作为NCA的输入。
这是两个方法衔接的关键操作:不是用原始量表题目跑NCA,而是用PLS-SEM算出来的潜变量得分。这样两套分析用的是同一套数据基础,结论才有可比性。
NCA用的方法是CR-FDH。简单说,它在散点图上画一条”天花板线”——这条线以上没有数据点,代表了在给定X水平下,Y的理论最大值。
效应量d就是天花板以下的空白面积占总面积的比例,d越大,必要性越强。
作者对每个潜变量都跑了NCA,看哪些的d值显著(only PE (d = 0.10; p < 0.01) and PV (d = 0.06; p < 0.01) exhibit significant effect sizes):
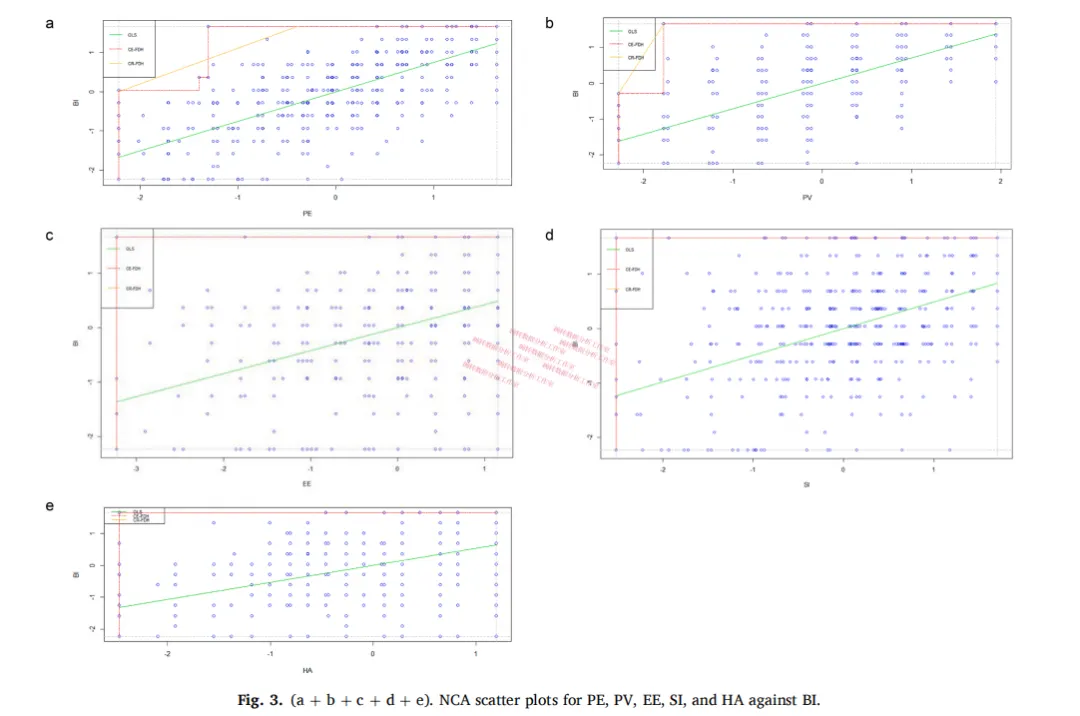
然后做了瓶颈分析——量化”要达到某个BI水平,各变量至少要到多少”
这个表直接告诉运营或产品:你想把用户采纳意愿拉到最高,绩效期望至少要拉到35.6%,价格感知至少要到12%。低于这个,其他一切努力都是在天花板以下打转。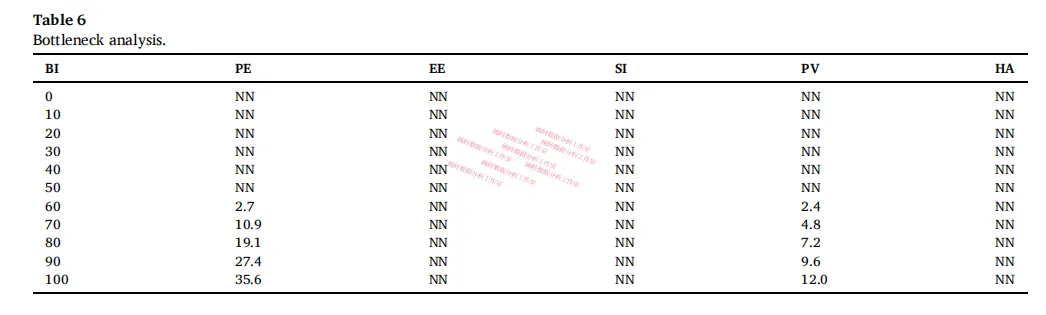
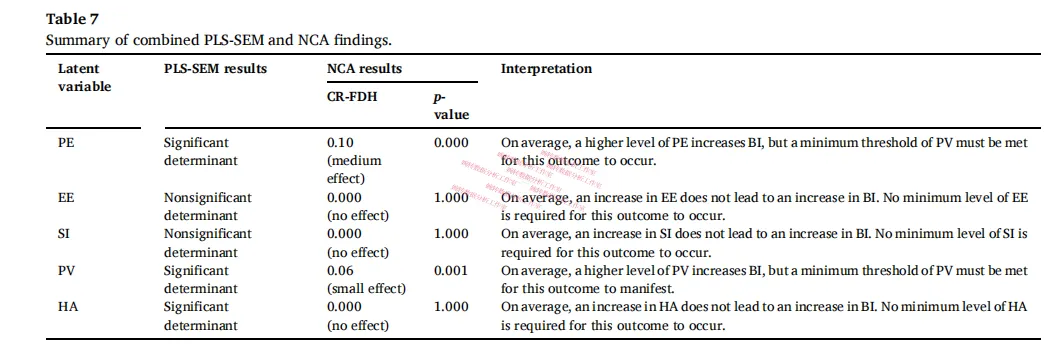
| 变量 | PLS-SEM | NCA | 解读 |
|---|---|---|---|
| PE | 显著 | 必要条件(中效应) | 平均效应存在,且是门槛变量 |
| PV | 显著 | 必要条件(小效应) | 平均效应存在,且是门槛变量 |
| HA | 显著 | 非必要条件 | 平均效应存在,但不构成门槛 |
| EE | 不显著 | 非必要条件 | 两个维度都没有 |
| SI | 不显著 | 非必要条件 | 两个维度都没有 |
HA这一行是整篇文章最值得停下来想的地方。
习惯在PLS-SEM里显著——”越习惯用手机,采纳意愿越高”,这没问题。但NCA告诉你它不是门槛——即使一个人平时不怎么用App,只要产品够好、价格够合理,他照样可能用。
如果只看PLS-SEM,你可能会建议”重点培养用户的手机使用习惯”;但加上NCA,你会知道这不是优先项——真正的优先项是绩效期望和价格感知,因为这两个才是底线。
这套组合在管理、营销、教育等领域都能用。如果你的研究问题包含以下任一:
-
“什么条件必须满足,用户才会……”
-
“哪些因素是不可或缺的前提”
-
“达到某个结果水平,最低需要多少X”
那NCA值得认真考虑。
需要注意的是,NCA不替代假设检验,是补充。先用PLS-SEM看路径系数和显著性,再用NCA看必要性——两套结论放在一起报,说的是不同维度的事,审稿人看到会觉得你想得很周全。
读这篇最大的收获,不是交通超级App的结论,是那张对比表给我的提醒:显著≠必要,不显著≠可有可无。
你手头的研究里,有没有哪个变量,你一直觉得它”肯定很重要”,但跑出来路径系数不显著——或者反过来,显著了但你怀疑它只是”锦上添花”?NCA或许能给你一个更清晰的答案。
关注我们,下期将继续为你带来更多前沿统计方法与软件实操解析,助你紧跟数据科学的脉搏!
-END-