 夜雨聆风
夜雨聆风





如何优雅地把NetCDF数据转成Excel
前几天在处理一批NC数据时,发现数据格式很复杂,还有一些时间、坐标、多维变量的清洗和提取问题。为了省去重复劳动,我编写了一段Python处理NetCDF数据的代码,自动化提取转换,还能 合并所有文件为一个总表,简直太香了!
🧪 适用场景
🔍 适合的实验项目:
地理/气象/海洋数据处理
大学生项目实践(数据清洗 + 自动化转换)
插件开发、数据可视化预处理
真实科研场景(如智能农业、大气模型等)
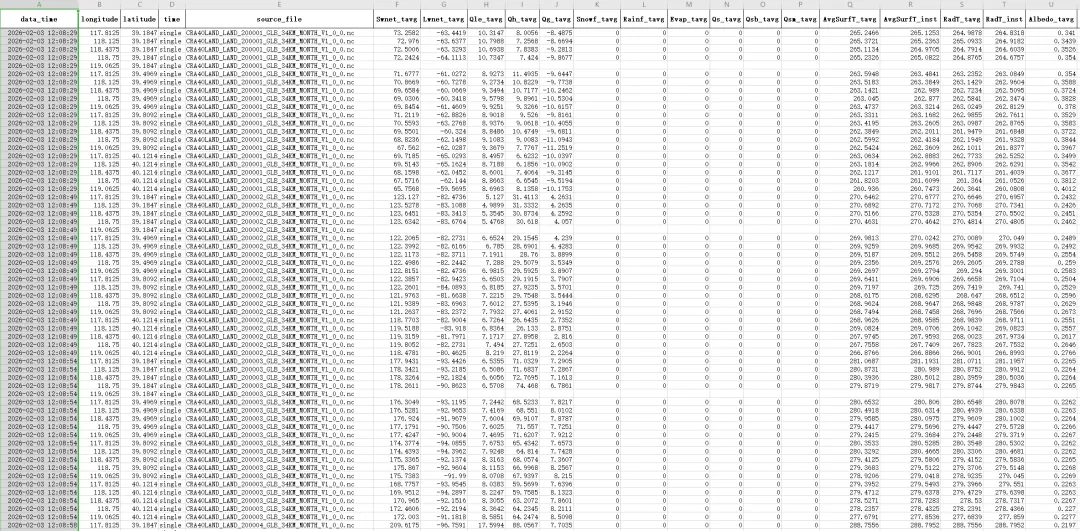
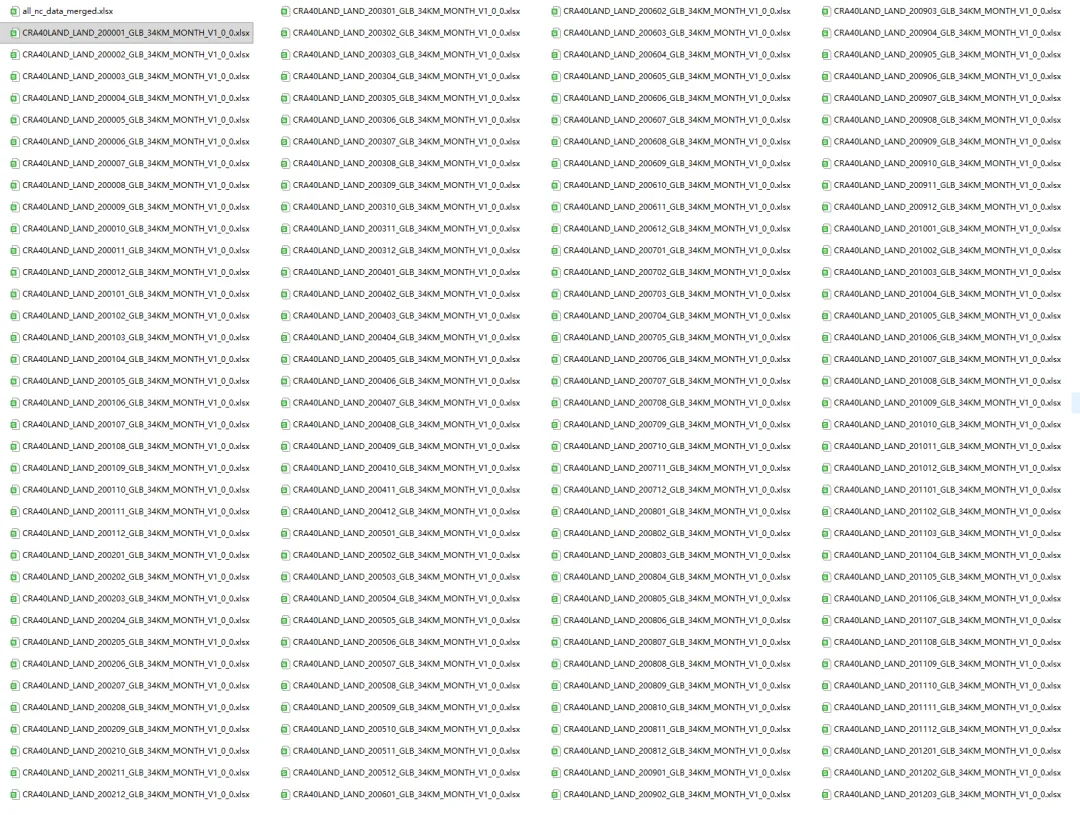
🧾 实操效果
运行这段代码后,我得到了这样的结果:
✅ 从多个NC文件中提取时间、经纬度与数值变量
✅ 每个NC生成了一个独立的Excel文件,命名清晰
✅ 所有数据被合并成一个总表,用于进一步分析
✅ 异常压力值自动处理,避免Excel报错
import netCDF4 as nc # 读取NetCDF文件import numpy as np # 数值计算import os # 文件路径操作import pandas as pd # 数据处理和Excel保存import warnings # 处理警告信息import re # 正则表达式,用于精准提取时间# 忽略无关警告,避免控制台刷屏warnings.filterwarnings('ignore', category=FutureWarning)warnings.filterwarnings('ignore', category=UserWarning)def extract_history_time0(history_str):"""从history字符串中提取原始时间戳(如Sep 16 08:10:24 2020):param history_str: nf.__dict__['history']的字符串内容:return: 提取的标准化时间字符串,无则返回'未知时间'"""if not isinstance(history_str, str):return '未知时间'# 正则表达式匹配:月份 日期 时:分:秒 年份(如Sep 16 08:10:24 2020)pattern = r'([A-Za-z]{3}\s+\d{1,2}\s+\d{2}:\d{2}:\d{2}\s+\d{4})'time_matches = re.findall(pattern, history_str)if not time_matches:return '未知时间'# 取最后一个匹配结果(原始数据处理时间,在history中靠后)raw_time = time_matches[-1]# 标准化格式:替换多个空格为单个standard_time = re.sub(r'\s+', ' ', raw_time).strip()return standard_timedef extract_history_time(history_str):if not isinstance(history_str, str):return pd.NaT # 无时间返回空的datetime值pattern = r'([A-Za-z]{3}\s+\d{1,2}\s+\d{2}:\d{2}:\d{2}\s+\d{4})'time_matches = re.findall(pattern, history_str)if not time_matches:return pd.NaTraw_time = re.sub(r'\s+', ' ', time_matches[-1]).strip()# 转为datetime类型try:dt_time = pd.to_datetime(raw_time, format='%b %d %H:%M:%S %Y')return dt_timeexcept:return raw_time # 转换失败则返回原始字符串def nc_read(path='tangshannew'):"""读取指定路径下所有.nc文件,单文件保存为独立Excel,同时合并所有数据到单个Excel表格修复:三维土壤剖面变量索引越界问题,优化变量筛选逻辑:param path: NC文件所在根路径,会遍历子文件夹"""# 确保输出文件夹存在output_folder = 'result_out'if not os.path.exists(output_folder):os.makedirs(output_folder)print(f'创建输出文件夹:{output_folder}')# 全局数据列表,收集所有NC文件的处理后数据all_data_list = []# 遍历所有NC文件for dirpath, _, filenames in os.walk(path):for filename in filenames:if not filename.endswith('.nc'):continue # 只处理.nc文件# 拼接NC文件完整路径nc_filepath = os.path.join(dirpath, filename)print(f'\n========== 开始读取:{nc_filepath} ==========')# 打开NC文件with nc.Dataset(nc_filepath) as nf:# 提取history中的原始时间nc_attrs = nf.__dict__history_str = nc_attrs.get('history', '')data_time = extract_history_time(history_str)print(f'从history中提取的原始时间:{data_time}')# 1. 获取经纬度数据lon = nf.variables['lon'][:].datalat = nf.variables['lat'][:].data# 尝试获取时间变量(若不存在则设为None)time_var = nf.variables.get('time') or nf.variables.get('valid_time')time_data = Noneif time_var is not None:time_data = nc.num2date(time_var[:], units=time_var.units).dataprint(f'识别到数据时间维度,共{len(time_data)}个时间片')print(f'经度维度:{len(lon)}个点,纬度维度:{len(lat)}个点')# 2. 优化变量筛选:仅保留 纯(lat, lon) 二维变量,排除带剖面/垂直维度的三维变量base_dims = {'lat', 'lon'}value_vars = []for var_name, var in nf.variables.items():# 跳过经纬度、时间等基础坐标变量if var_name in ['lon', 'lat', 'time', 'valid_time']:continue# 严格匹配:维度仅包含 lat, lon,无其他额外维度(如土壤剖面)var_dim_set = set(var.dimensions)if var_dim_set == base_dims:value_vars.append(var_name)if not value_vars:print(f'【警告】{filename}中未找到符合(lat,lon)维度的数值变量,跳过')continueprint(f'识别到有效数值变量:{value_vars}')# 3. 遍历维度收集数据single_file_data = []time_range = range(len(time_data)) if time_data is not None else [0]lon_range = range(len(lon))lat_range = range(len(lat))for t_idx in time_range:for lat_idx in lat_range:for lon_idx in lon_range:row = {}row['data_time'] = data_time # 从history提取的时间row['longitude'] = round(lon[lon_idx], 4)row['latitude'] = round(lat[lat_idx], 4)if time_data is not None:row['time'] = time_data[t_idx]else:row['time'] = 'single'# 添加原文件名列,方便合并后追溯数据来源row['source_file'] = filename# 遍历数值变量赋值,增加异常捕获for var_name in value_vars:try:var_array = nf.variables[var_name][:].data# 区分有无时间维度,正确索引二维数组if time_data is not None:# 维度顺序:time, lat, lonrow[var_name] = var_array[t_idx, lat_idx, lon_idx]else:# 维度顺序:lat, lonrow[var_name] = var_array[lat_idx, lon_idx]# 替换缺省值为NaN,方便Excel处理if row[var_name] == -9999.0:row[var_name] = np.nanexcept Exception as e:print(f'【警告】读取变量{var_name}失败:{str(e)}')row[var_name] = np.nansingle_file_data.append(row)# 同时添加到全局合并列表all_data_list.append(row)# 4. 单文件数据转DataFrame并保存single_df = pd.DataFrame(single_file_data)print(f'{filename}数据整理完成,共{len(single_df)}行记录')# 单文件Excel保存excel_filename = f'{os.path.splitext(filename)[0]}.xlsx'excel_filepath = os.path.join(output_folder, excel_filename)single_df.to_excel(excel_filepath, index=False, float_format='%.4f')print(f'{filename}已保存至:{excel_filepath}')# 所有NC文件处理完成后,合并数据并保存为总表if all_data_list:print('\n========== 开始合并所有NC文件数据 ==========')merged_df = pd.DataFrame(all_data_list)merged_excel_path = os.path.join(output_folder, 'all_nc_data_merged.xlsx')# 保存合并总表,设置浮点数格式,忽略索引merged_df.to_excel(merged_excel_path, index=False, float_format='%.4f')print(f'所有数据合并完成!总数据量:{len(merged_df)}行')print(f'合并总表已保存至:{merged_excel_path}')else:print('\n【警告】未读取到任何有效NC数据,未生成合并总表')print('\n========== 所有操作处理完成 ==========')if __name__ == '__main__':# 调用函数,修改path为你的NC文件实际路径(Windows路径推荐使用原始字符串/双反斜杠)nc_read(path=r'tangshannew')