 夜雨聆风
夜雨聆风





AI工具太话痨?这个插件让Claude和Codex学会少说废话
最近用 AI 编程工具的人,应该都有一个共同感受:
AI 确实越来越能干了,但也越来越能说了。
你只是让它改一个小 bug,它先来一段“我会先检查代码结构”;你只是问一个报错,它能从背景、原因、可能性一路讲到总结;你只想知道下一步,它还要礼貌地说“这是一个很好的问题”。
这些话不是完全没用。
但当你一天和 Claude Code、Codex、Cursor 来回几十轮之后,就会发现一个很现实的问题:
AI 的废话,也在消耗你的时间、注意力和 Token。
这就是 Caveman 最近突然火起来的原因。
它不是一个新模型,也不是一个复杂框架。
它做的事情非常简单:让 AI 像“聪明的山顶洞人”一样说话。
少寒暄。
少铺垫。
少解释性废话。
把真正有用的信息留下来。
它不是让AI变笨,而是让AI别写小作文
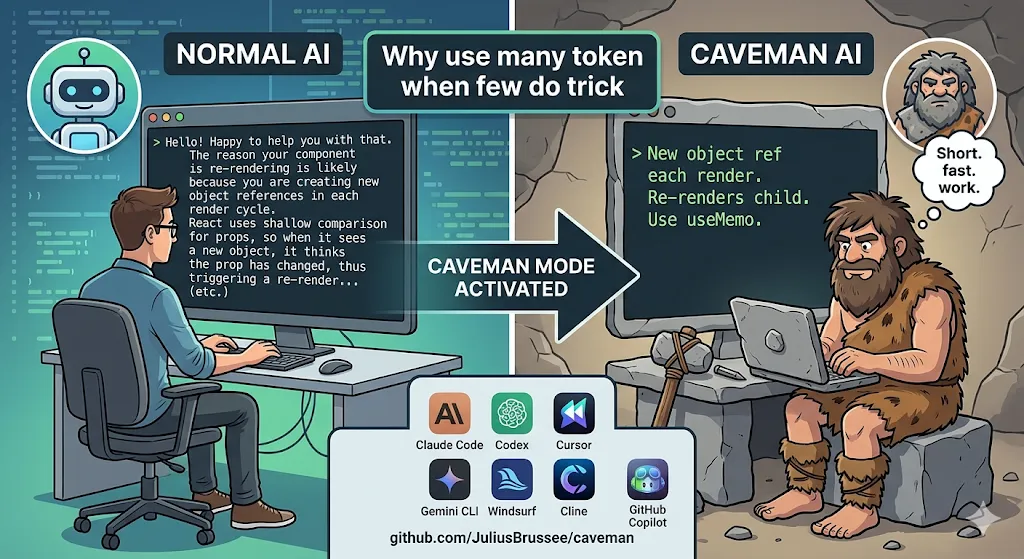
Caveman 的 GitHub 仓库是:
https://github.com/JuliusBrussee/caveman项目口号也很直接:
why use many token when few do trick翻译一下就是:
能少说,就别多说。
但这里的“少说”,不是让 AI 随便省略信息,而是压缩表达方式。
比如普通 AI 解释 React 重渲染,可能会说:
你的组件每次渲染都会创建新的对象引用,因此 React 在浅比较 props 时会认为它发生了变化,从而触发子组件重新渲染。你可以考虑使用 useMemo 来稳定这个对象引用。
Caveman 风格会更像这样:
New object ref each render. Inline object prop = new ref = re-render. Wrap in useMemo.意思基本还在,但废话少了很多。
这就是它的核心价值。
不是让 AI 变笨,而是让 AI 别把每次回答都写成小作文。
为什么开发者会喜欢这种东西?
因为现在的 AI Agent 已经不只是回答问题了。
它会读文件、改代码、跑测试、解释原因、总结变更、提醒风险、给下一步建议。
能力越多,输出也越容易变长。
如果你只是偶尔用一次,可能还觉得挺贴心。
但如果你把 AI 当成日常开发助手,这种“贴心”就会变成噪音。
你真正想看的,很多时候只有三件事:
-
• 发现了什么问题 -
• 改了什么东西 -
• 下一步要不要你确认
其他大量礼貌话、铺垫话、重复总结,其实都在打断节奏。
所以 Caveman 火起来,本质上说明了一件事:
AI Agent 的下一步优化,不只是更聪明,也要更克制。
安装方式
Caveman 现在支持多个工具。
Claude Code 可以这样安装:
claude plugin marketplace add JuliusBrussee/caveman
claude plugin install caveman@cavemanGemini CLI:
gemini extensions install https://github.com/JuliusBrussee/cavemanCursor:
npx skills add JuliusBrussee/caveman -a cursorWindsurf:
npx skills add JuliusBrussee/caveman -a windsurfCline:
npx skills add JuliusBrussee/caveman -a clineGitHub Copilot:
npx skills add JuliusBrussee/caveman -a github-copilot其他支持 skills 的 Agent,也可以直接用:
npx skills add JuliusBrussee/caveman这里有个容易踩坑的点:
不同 Agent 对 skill 的支持不完全一样。
Claude Code、Gemini CLI 这类工具接入比较自然;Cursor、Windsurf、Cline、Copilot 有时只是安装 skill 文件,是否自动启用,还要看对应工具自己的 rules 或 system prompt 机制。
如果你装完发现没有自动进入 Caveman 模式,不一定是安装失败,可能只是还没配置成默认规则。
怎么用更合适?
在 Claude Code 里可以输入:
/caveman在 Codex 里一般用:
$caveman也可以直接说:
caveman mode想退出就说:
normal modeCaveman 大致有几种模式。
lite 更适合日常使用,去掉废话,但保留正常语法。
full 是典型 Caveman 风格,句子更短、更硬,适合个人 debug、review、看报错。
ultra 更激进,能压得更短,但可读性会下降。
项目里还有 wenyan-lite、wenyan、wenyan-ultra 这类文言文模式,更偏实验和趣味。
我的建议是:
不要一上来就开 ultra。
先从 lite 或 full 开始。
它能省多少?
项目自己的 benchmark 给过一组数据:
普通输出平均 1214 tokens,Caveman 输出平均 294 tokens,平均节省约 65%。
有些场景甚至能省到 80% 以上,比如 React 重渲染问题、认证中间件问题、PostgreSQL 连接池问题、PR 安全审查等。
但这件事要冷静看。
Caveman 主要省的是输出 token。
模型内部的 reasoning token、工具调用成本、文件读取成本,并不会因为 Caveman 自动消失。
另外,Caveman 的规则本身也要放进上下文。
所以,如果你每次只问一句很短的问题,它未必划算。
但如果你经常让 AI 做代码 review、总结报错、分析日志、汇报改动,那收益会明显很多。
还有一个实用功能:压缩项目记忆
Caveman 不只是让 AI 回答变短。
它还有一个更工程化的用法:压缩项目记忆文件。
比如 Claude Code 经常会读取 CLAUDE.md。这个文件通常会写项目规则、技术栈、开发约定、注意事项。
时间一长,它很容易变得很大。
每次开新 session,这些内容都会进入上下文,也就是长期消耗。
Caveman Compress 的思路是,把给 AI 读的那份文件压成更短的技术表达,同时保留一份原始版本给人类维护。
使用方式类似:
/caveman:compress CLAUDE.md它会保留代码块、URL、文件路径、命令、版本号这类关键信息,把自然语言里的冗余表达删掉。
如果你维护的是长期项目,这个功能比“让 AI 像山顶洞人一样说话”更值得关注。
因为它省的不只是某一次回复,而是每次 session 重复读取的固定上下文。
更适合它的人,其实也很明确。
如果你每天都在用 AI 写代码、改项目、看日志、跑测试,Caveman 会很顺手。
如果你只是偶尔问 AI 一个概念,或者希望它把来龙去脉讲清楚,那就没必要强行开启。
它更像开发者的工作流插件,不是普通聊天用户的必装工具。
换句话说,它解决的不是“AI 不够聪明”,而是“AI 协作时不够利落”。
这个差别很关键。
尤其在连续调试和反复改代码的时候,短而准的反馈往往比完整长文更有价值,也更适合真实开发节奏。
更大的价值,是少占你的注意力
很多人一看到 Caveman,会先想到省钱。
但我觉得它更大的价值,是减少注意力浪费。
开发的时候,你脑子里可能同时装着调用链、变量状态、日志时间和最近改动。
这个时候 AI 如果回你一大段礼貌解释,你还要从里面筛重点。
筛重点这件事,本身就是额外成本。
Caveman 的思路是让 AI 默认把重点放在前面。
比如:
Bug: token expiry not checked. Add exp validation before user lookup.这种表达不漂亮,但很适合开发现场。
你一眼就能知道问题是什么、该改哪里、为什么要改。
它也有不适合的场景
Caveman 值得试,但不能神化。
如果你在做高风险操作,比如删库、改权限、上生产、迁移数据,回答越短不一定越好。
这时候你需要的是明确确认、风险解释和回滚方案。
如果你是新手,正在学 React、数据库、Linux、Docker,很多背景解释也有价值。
老手看 Caveman 会觉得爽,新手可能会觉得信息不够。
另外,项目 benchmark 主要证明它能减少输出 token,但“更短”不等于“同样好”。真正完整的评测,还应该看任务成功率、信息保真度、追问次数和总成本。
所以我更愿意把它理解成一种开发现场的“短报文模式”。
适合高频协作。
不适合所有写作和教学场景。
AI少说一点,开发者反而轻松一点
Caveman 看起来像个玩梗项目,但它戳中的问题很真实。
AI 工具越来越强之后,我们很快会遇到另一个问题:
不是 AI 不会说,而是它说得太多。
真正好的 AI 助手,不应该每次都写小作文。
它应该知道什么时候解释,什么时候行动,什么时候只给你一句关键结论。
AI 时代的效率,不只来自更多能力,也来自更少噪音。
如果你每天都在用 Claude Code、Codex、Cursor 写代码,Caveman 值得试一下。
不一定要长期打开。
但当你再次被 AI 的长篇解释打断节奏时,你会知道还有一个选择:
让它少说点。
把重点说出来。
就够了。