夜雨聆风
夜雨聆风





AI笔记7-机器学习项目实战-外卖点评情感预测
-
项目的目的 -
数据集的介绍 -
实战预测的步骤 -
内容小结
-
下载地址:
http://idatascience.cn/dataset-detail?table_id=429

-
字段介绍
|
|
|
|
|
|
|
|
|
|
|
|
-
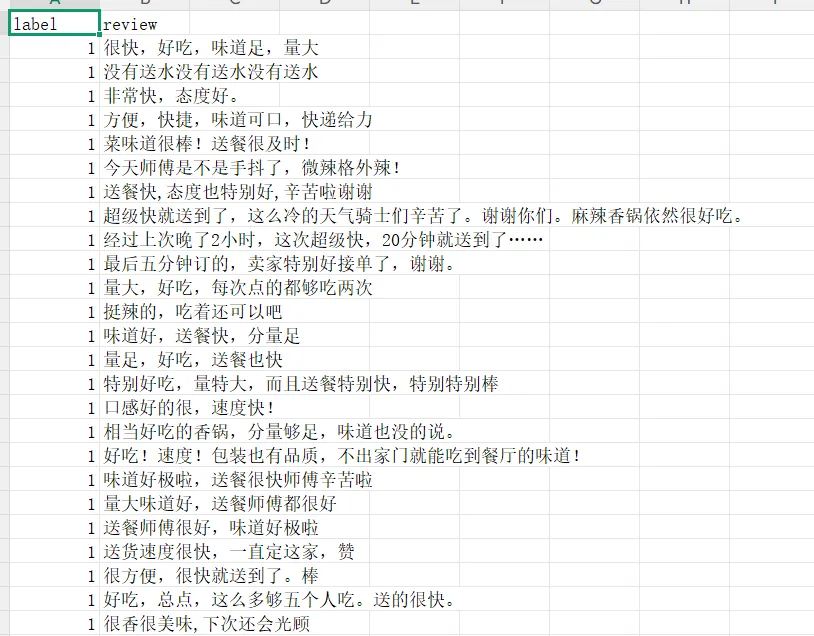
数据样例-下载的csv文件:
-
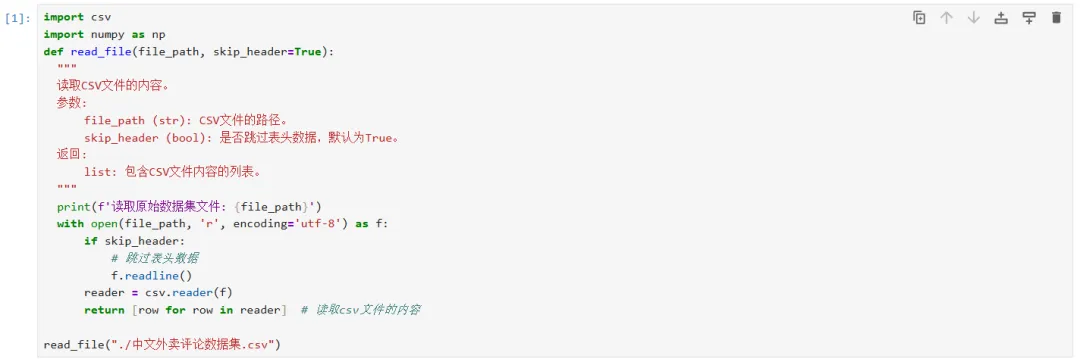
第一步:解决输入/输出
该问题是一个典型的分类问题,分析相关输入/输出如下:
-
第二步:构建数据集
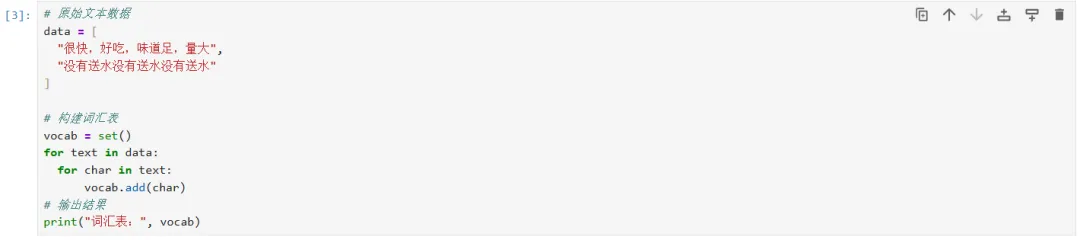
通过分析上述的数据集,可以看到该数据集基本满足上述特点,但是仍然存在一个比较大的问题:数据集是汉字,机器无法处理(因为机器学习底层是对数字的处理),所以我们首先需要对数据数字化(也叫汉字向量化)。
汉字向量化:
在机器学习中,汉字向量化是将汉字表示为计算机可识别的数值形式的过程。常用的方法有:
这是传统机器学习中常用的一种向量化方法。在这种方法中,每个汉字被表示为一个固定长度的向量,向量的大小等于字典的大小,每个条目对应于预定义单词字典中的一个单词,其中只有一个位置是1,其余为0。
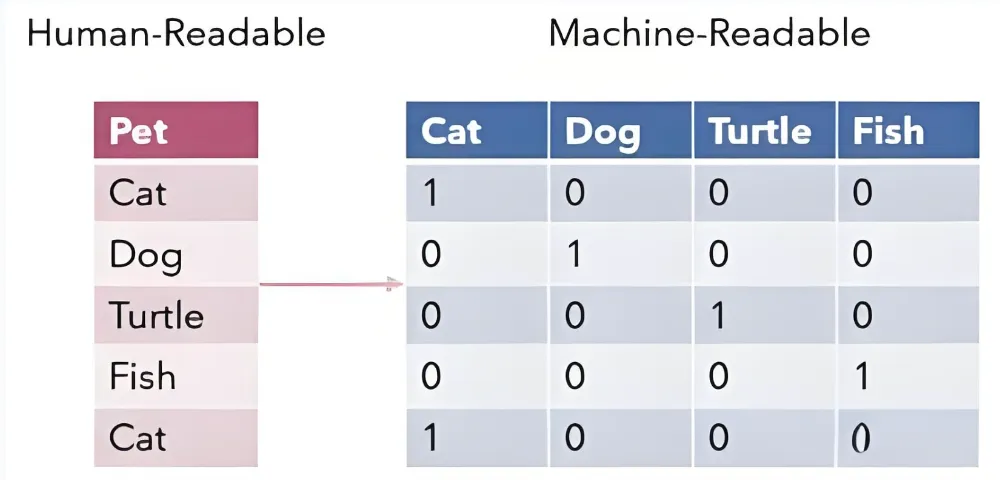
在词袋模型中,文本中的每个汉字被看作是独立的,没有关联性,然后根据字典统计单词出现的频数。这种方法虽然简单,但在文本向量化中具有一定的实用性。

以词袋模型为例:
如果将文本”方便,快捷,味道可口,快递给力”以字为单位进行切分,并使用词袋模型进行向量化,向量化过程如下:
构建字汇表:首先,将文本中的所有不重复的字作为字汇表。在这个例子中,字汇表为[“方”, “便”, “,”, “快”, “捷”, “味”, “道”, “可”, “口”, “快”, “递”, “给”, “力”]。
向量化过程:对于每个文本,统计字汇表中每个字在文本中出现的次数,形成一个向量表示。
在这个例子中,”方便,快捷,味道可口,快递给力”的向量表示如下:
“方”出现1次
“便”出现1次
“,”出现3次
“快”出现2次
“捷”出现1次
“味”出现1次
“道”出现1次
“可”出现1次
“口”出现1次
“递”出现1次
“给”出现1次
“力”出现1次
因此,根据字汇表的顺序,该文本的词袋模型向量化结果为: 1,1,3,2,1,1,1,1,1,1,1,1
代码设计思路:
1、读取csv文件并且将标签和特征数据切分出来。
2、如何将汉字转换为数字编码这个问题。
3、通过与GPT沟通词袋模型,我们了解到需要构建一个词汇表,然后根据词汇表数个数,所以这个问题可以分解为两个子问题:如何将数据集汉字建立成字典?和如何根据字典数文字出现的个数?
4、如何将数据集汉字建立成字典?可以使用一个双层循环,逐行逐字遍历数据集,然后把字加入到一个set变量中。(因为set数据类型有滤重功能)。
5、对于如何根据字典数文字出现的个数?需要下面几个小步骤:
–生成一个长度为字典长度,内容都为0的bow_vector。



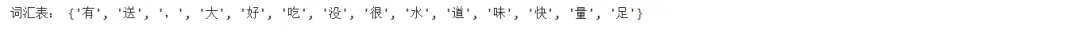


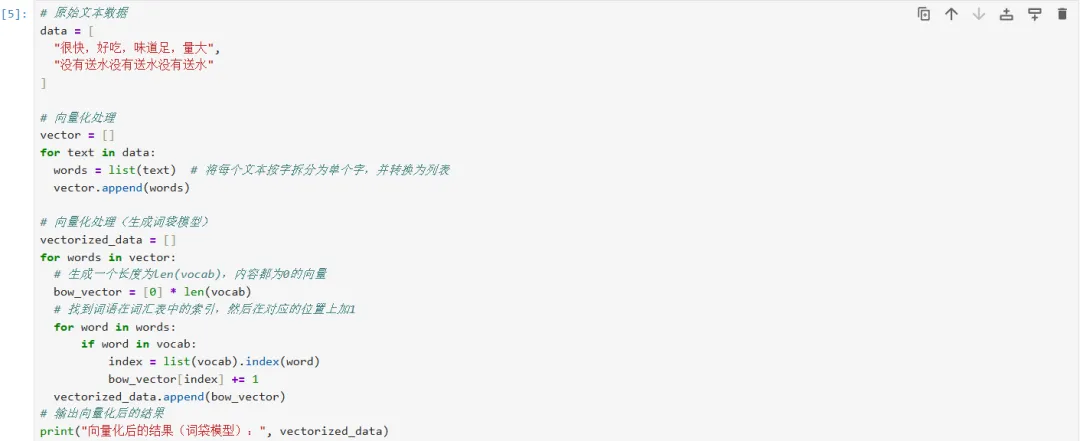
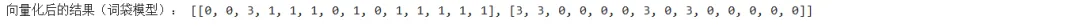
2、最终生成的向量化数据,可以保存在内存中,在下面的运行模型中直接使用;也可以将向量化数据保存到本地文件,然后在模型方法中读取后使用。我使用的方法是保存到本地后,在下面的decision_tree来读取使用。处理后的数据保存在vectorized_data.csv文件,其内容如下:
-
第三步:实验算法

-
第四步:工程优化
通过上述验证数据集已经可以使用,整体流程已经没有问题。接下来我们对代码进行重构:
1、将整体代码使用面向对象封装为类实现
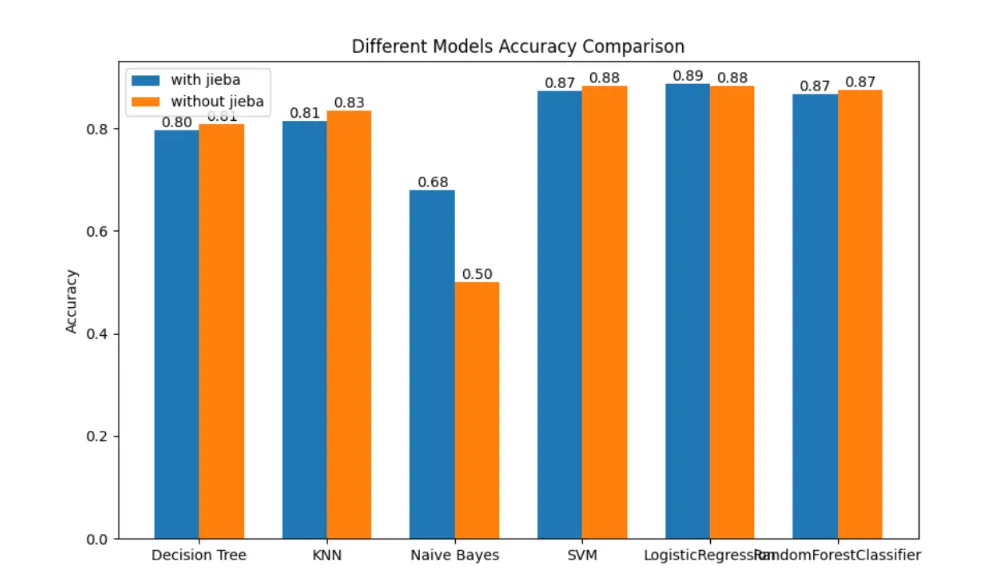
2、在汉字向量化处理中使用jieba的分词方式
3、在模型预测部分加入KNN、贝叶斯、线性回归、随机森林、SVC向量机的方式
由于重构的代码内容较多,本篇文章不再赘述,详情请见Github仓库
-
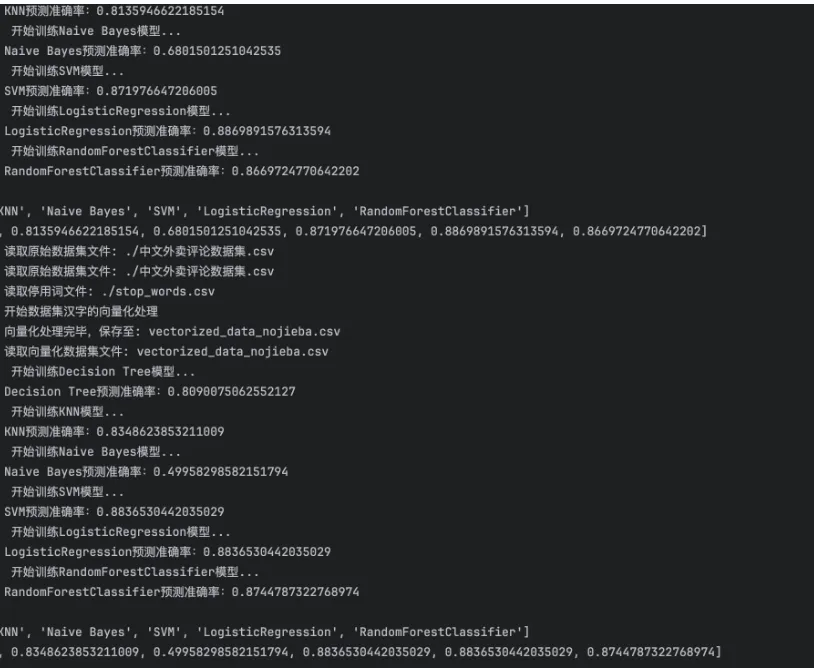
第五步:遴选算法
通过运行上述工程优化后的代码,执行结果如下: