 夜雨聆风
夜雨聆风





国际先进技术应用推进中心(深圳):跑得比人快,却还不会叠一件衣服——具身智能的数据暗战与“GPT时刻”还有多远?【附】
关注汇策网,下载最新最全政策汇编和研究报告。

2026年4月19日,北京亦庄。
300余台人形机器人同时起跑,在21公里的半程马拉松赛道上与人同场竞技。荣耀机器人“闪电”以50分26秒冲线,超越了人类男子半马57分20秒的世界纪录——这一成绩比去年首届赛事的冠军整整快了近三分之二。
就在同一天,高德自研的四足机器人“途途”完成了全球首次开放环境下的全自主导盲演示,在没有人工遥控的情况下自主引导视障人士穿越人流、绕行障碍、寻找补给站。
美国波士顿,特斯拉的Optimus人形机器人站在波士顿马拉松终点线旁,为跑者加油助威、与观众合影,以近乎零成本的方式完成了又一次公众认知植入。
然而,当这些机器人以超越人类的姿态奔跑、导盲、展示时,一个令人不安的事实却被刻意忽略:它们中的绝大多数,依然无法在真实仓库里稳定地完成最基础的操作任务——比如叠一件衣服,或者从杂乱堆放的箱子里抓取一个特定物体。
a16z的深度洞察一针见血:实验室里95%成功率的策略,一旦进入真实仓库,光照、背景、视角、物体材质发生变化,成功率可能迅速跌到60%。
这就是2026年具身智能的真实处境——一方面,产业热度达到历史巅峰:2026年开年仅100天,具身智能赛道融资总额已达345亿元,平均每天超过2笔资金注入该领域,单笔10亿元以上的融资已有15起,而2025年上半年这一数字仅为3起。它石智航以4.55亿美元刷新了国内具身智能单轮融资纪录,一年估值接近200亿元;自变量机器人完成近20亿元B轮融资,成为唯一同时获得字节、美团、阿里、小米四大互联网巨头投资的具身智能企业。
另一方面,瑞银证券的分析师却冷静地指出:即便今年很多厂商冲万台,人形机器人也未必真正进入商业化拐点。相当一部分需求仍停留在“为未来做准备”的阶段——科研机构、数据采集中心、文娱表演,而非能够稳定创造生产价值的工业场景。
运动的突破和操作的瓶颈,资本的狂热和商业的冷峻,政策的力挺和数据的匮乏——这四重张力构成了2026年具身智能产业最核心的矛盾图景。而解开这把锁的钥匙,不在机械结构,不在电机扭矩,甚至不在大模型架构,而在一个更基础的命题上:数据。
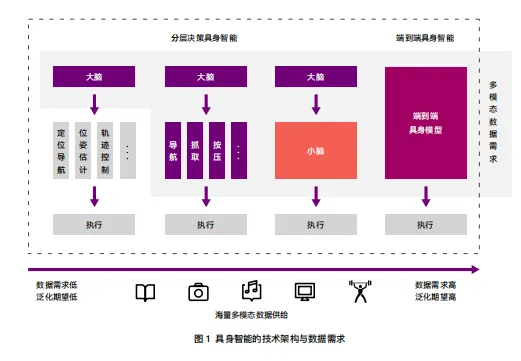
一、从“跑起来”到“干起来”:具身智能的能力断层
要理解当前具身智能的真实发展水平,首先需要区分两个截然不同的能力维度:运动能力和操作能力。
1.1 运动能力:从实验室走向开放场景
过去一年,人形机器人的运动能力经历了令人瞩目的跨越。在2025年的首届亦庄半程马拉松上,冠军机器人还需要人工遥控,成绩是2小时40分钟。一年之后,参赛机器人的奔跑速度普遍提升两到三倍,自主导航赛队占比已达近四成,完赛率超过45%。
这一进步背后,是硬件和算法的双重突破。关节扭矩大幅提升,液冷散热系统使机器人能够在21公里的连续奔跑中维持稳定性能;基于强化学习的运动控制算法在仿真环境中经过海量训练,让机器人能够应对弯道、坡道、狭窄路段等复杂地形。四足机器狗的运动控制已经相对成熟,可以在开放环境中实现自主导航,而人形机器人正在快速追赶。
但运动的突破恰恰暴露了操作能力的短板。一个能跑进人类纪录的机器人,在抓取一个杯子时,仍然需要事先精确计算每个关节的角度、抓握力度和接触点——因为任何微小的误差,都可能让杯子滑落或破碎。
1.2 操作能力:数据匮乏的真实代价
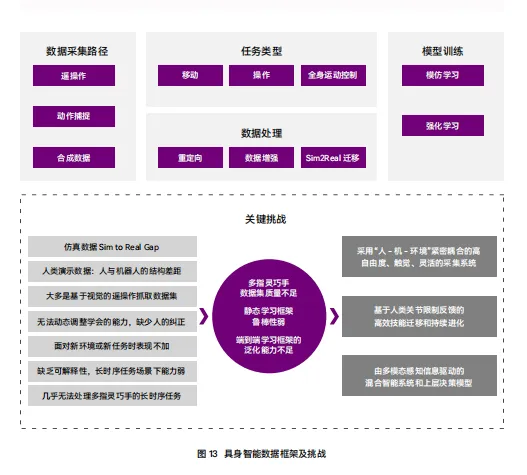
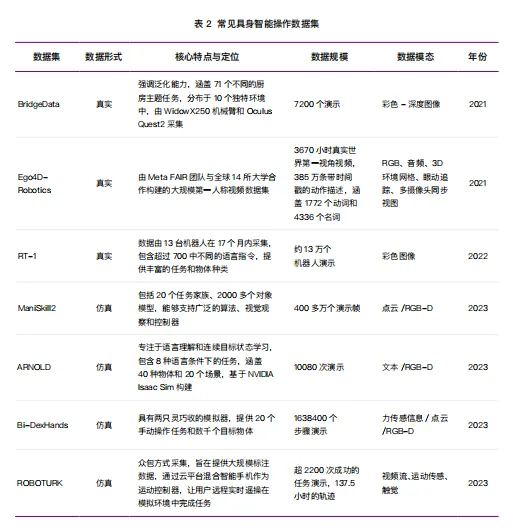
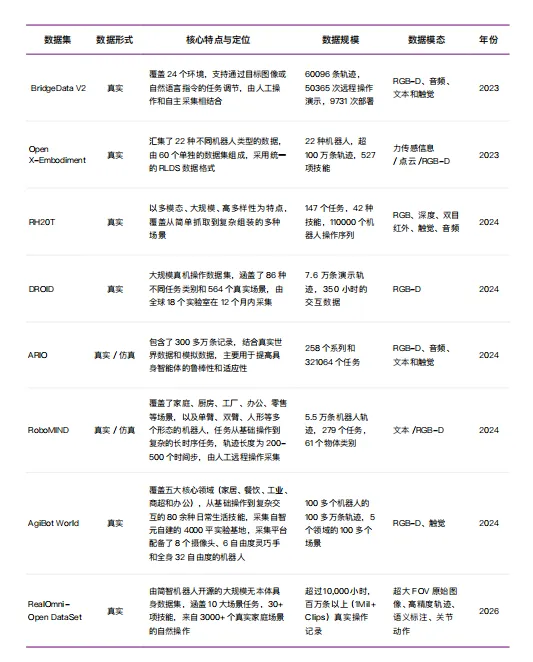
与运动控制主要依赖仿真环境和强化学习不同,精细操作的数据获取方式完全不同。行业普遍认为,要实现具身智能的“涌现”至少需要百万小时来自真实世界的物理互动数据,但目前积累的数量仅不到5%。
为什么会这么少?
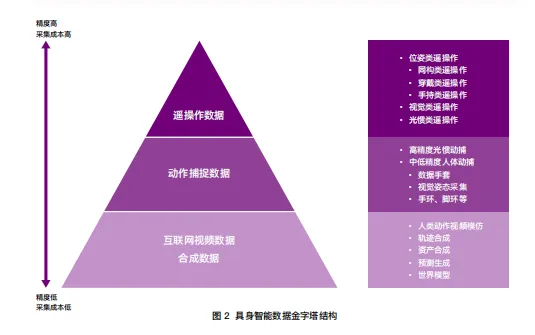
原因在于,操作数据不能像运动数据那样在仿真环境中大规模生成。一个机械臂抓取一杯水的完整轨迹,需要同步记录多摄像头视角、手腕角度、抓握力度变化、力触觉反馈等多维信息——而仿真环境至今无法精确模拟软体形变、摩擦力和接触力学等复杂物理现象。目前行业主要依赖三条数据采集路线:遥操作数据精度最高但成本昂贵;动作捕捉数据在真实性和可扩展性之间取得平衡;互联网视频数据和合成数据潜力巨大但面临从2D到3D、从人类到机器人的迁移难题。
GPT-5训练用了100万亿Tokens,而目前全球具身智能的高质量数据加起来大约只有50万小时——差距是以亿为单位的量级。灵初智能创始人王启斌直言:“数据量不够,模型层面的任何精巧架构调整都毫无意义。”
这种数据匮乏最直接的表现是:机器人学一个叠衣服的动作,可能需要人类操作员穿戴遥操作设备反复演示数十甚至上百次,每次采集都意味着时间和金钱的消耗。而在真实工作场景中,物体的形状、材质、摆放位置千差万别,训练时覆盖的场景稍微变化,成功率就断崖式下降。
这正是为什么我们在2026年看到的现象如此割裂:机器人在标准化赛道上跑得越来越快,但在真实仓库里干活的效率依然远低于人类。
二、数据采集路线的技术与商业竞合
既然数据是核心瓶颈,那么如何高效、低成本、大规模地获取数据,就成为决定行业竞争格局的关键战场。当前行业主要围绕三条路线展开激烈竞逐。
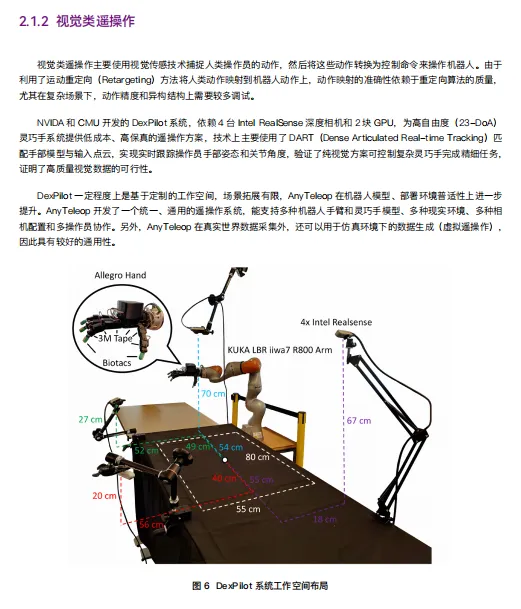
2.1 遥操作:高保真的黄金标准,还是不可持续的烧钱黑洞?
遥操作数据被公认为当前具身智能数据的“黄金标准”——因为它能同步记录下多维度的物理状态,提供了高保真、因果明确的物理交互轨迹。智元机器人在上海张江启用了行业首个数据采集工厂,占地4000平方米,分割为家居、餐饮、工业等不同主题场景,每日超过100台机器人同步训练,单机单日可产生上万条高质量轨迹数据。
然而,遥操作路线面临一个根本性的经济拷问:高度依赖专家操作,成本高昂、效率低下,无法实现数据量的指数级增长。简智机器人的实践显示,要实现“采集完成后2小时内新鲜数据送达模型”的目标,需要从硬件压缩、传输优化到云端处理的系统性能力——这本身就是一项需要长期投入的工程基础设施。
更关键的是,遥操作采集的数据与特定机器人本体结构强绑定。国内已建成或计划在建的具身智能训练场达到20余家,但“原本定位为公共产品和基础设施的数采训练场,在推动产业发展上却遇到了数据孤岛问题”——不同厂商的数据无法互通,这严重制约了行业整体效率的提升。
它石智航在融资后选择了一条反共识的路径:拒绝遥操作与纯仿真,坚持Human-centric(以人为中心)的真实世界数据范式,直接对齐真实物理世界。首席战略官Vincent解释:“创业最难的不是做不出来,而是机会太多导致资源不聚焦。”
2.2 无本体数据采集:打破“成本-规模-多样性”不可能三角?
斯坦福大学2024年提出的UMI框架开创了“无本体数据采集”的新思路,核心思想是将人类的操作智能与物理环境解耦,形成一种可规模化采集、且能跨机器人本体迁移的中间态数据。这条路线在2026年迎来了密集突破。
灵初智能开源了大规模人类手部操作数据集,并发布新一代具身大模型Psi-R2——首个使用10万小时量级人类数据预训练的世界动作模型。其创始人明确指出,他们正尝试用“人类原生数据”的采集与训练体系,直击具身智能最根本的生存难题——数据荒,并在物流仓库里验证商业与技术闭环的可行性。
觅蜂科技在2026年4月发布了一站式物理AI数据服务平台,宣称将在2026年实现千万小时级数据产能。其创始人姚卯青将商业模式比作“滴滴”——既有自营的“车队”(自营采集),也开放平台接入第三方数据源,目标是让高质量物理AI数据“像水电一样即取即用”。
光轮智能则刷新了具身数据行业的订单纪录:2026年一季度狂揽5.5亿元订单。公司客户已包括Figure AI、智元机器人、银河通用、DeepMind、字节跳动等头部企业,并与NVIDIA生态深度绑定,成为NVIDIA GROOT人形机器人基础模型的重要数据合作伙伴。
但无本体路线也面临自身挑战。无本体数据在动作完整性(如缺乏精确的力触觉信号)和运动精度(存在视觉估计误差、本体映射偏差)方面存在天然不足,其工程化难度体现在三个层面:数据治理需要构建高质量管线,算法设计需要针对数据特性定制模型架构,质量评估缺乏绝对真值依赖。
2.3 仿真与合成数据:从补充到主力?
当真实数据采集面临经济约束时,仿真和合成数据正从补充角色走向主力位置。NVIDIA在CES2026上发布了Cosmos世界模型系列,并在2026年3月推出Cosmos 3——首个整合合成世界生成、视觉推理与动作模拟的世界基础模型,支持Text2World、Image2World、Video2World的统一生成。其Isaac GR00T N1.6模型专为人形机器人打造,实现了全身控制能力。
黄仁勳的判断掷地有声:“物理AI已经来临,每一家工业公司都将成为机器人公司。NVIDIA横跨运算、开放模型与软件框架的全端平台,是机器人产业的核心基础。”NVIDIA正试图成为“机器人界的Android”——通过软硬件一体化策略降低机器人研发门槛,成为行业通用的底层供应商。
在国内,银河通用已发布全球首个全仿真预训练具身大模型GraspVLA,基于十亿量级的仿真数据进行预训练。群核科技通过酷家乐积累的超过5亿个3D结构化场景,构建了群核空间智能平台,已与智元机器人、银河通用、弯彻智能等头部具身智能企业达成合作,为其提供仿真训练数据。
流形空间是国内探索世界模型技术路线的初创企业,独创WMA路线,强调用世界模型作为机器人的基础模型,自研通用空间世界模型WorldScape,已在无人机领域实现落地。
然而,仿真数据面临一个根本性的挑战——Sim2Real Gap(仿真到现实的差距)。由于仿真是对现实世界的简化建模,误差必然存在,包括物理简化、感知简化、动作简化等。特别是以电机等硬件为核心的执行器,存在响应延迟、饱和、齿隙和热效应等问题,目前仍无法被充分模拟。
世界模型被认为可能是补足这一短板的关键。2026年初,这一方向迎来密集突破:蚂蚁灵波发布的LingBot-VA首创“边推演、边行动”框架,在LIBERO基准测试中任务成功率高达98.5%;生数科技开源的Motus将五种主流具身基础模型范式统一到同一框架中,在50项通用任务测试中成功率较Pi0.5提升35%;英伟达与斯坦福联合发布的Cosmos Policy展示了基于规划的推理路径。
但需要清醒认识到,世界模型仍处于早期探索阶段,在长时序预测中的误差累积、物理一致性保持、实时推理效率等方面仍面临共性挑战。技术突破需要时间,仍需要大量资金和时间投入。
三、商业化的三重门:从“能跑”到“能用”的距离
2026年,行业叙事正在从“秀肌肉”转向“能干活”。但这条路上横亘着三道门槛,每一道都足以淘汰一批玩家。
3.1 订单的性质:验证性采购 vs. 生产力需求
当“万台量产”“融资加速”成为主流叙事,一个关键问题却很少被认真审视:这些订单究竟流向哪里?
瑞银分析师王斐丽指出,当前大量出货并未真正进入工业或商业场景,而是流向科研机构、数据采集中心、文娱表演等“非工作型”用途,而非作为可以稳定工作的生产工具。宇树科技的招股书显示,其最大客户群体仍为高校及科研机构,主要用于算法研究与二次开发。优必选累计拿下的近14亿元订单中,多为地方政府主导的具身智能数据采集与测试中心。
换句话说,当前相当一部分需求停留在“为未来做准备”的阶段,机器人在这些场景中的主要任务是“被训练”,而非“去工作”。这种现象被业内人士总结为三类订单:品牌展示单——客户为话题付费,不是为生产力付费;试点验证单——客户为“不掉队”付费,而不是为效率付费;战略合作单——客户更多是为PR价值付费。
瑞银的判断是:人形机器人会先在技术门槛低的简单应用场景采用(如导览和娱乐等商业场景),但这类需求市场空间有限,难以成为长期增长的主引擎。
3.2 ROI的经济账:10万-15万元的生死线
当机器人真正进入工业场景时,客户的决策逻辑更加直接——只看两件事:能不能完成工作,经济性是否成立。
一个典型的ROI计算模型是:若替代一名年成本10万元的工人,则对应机器人的设备成本加上维护费用,通常需在1.5至2年内收回。这要求具身智能产品的售价需降至10万-15万元级别,同时需要满足几乎类人的工作效率和7×24小时连续作业的无故障要求。
然而当前行业现状是:一方面,核心零部件价格昂贵,供应链尚未成熟,如六维力传感器、谐波减速器等;另一方面,机器人在动态环境下的操作精度、响应速度和可靠性,距离大规模商用仍有差距。具身智能系统的复杂性,尚无法与经过数十年优化的专用设备相比,导致客户买得起,但用不起。
从目前披露的信息来看,工业场景中的“复购”仍然较为有限。除优必选与车厂形成小规模试点合作外,其他头部厂商的工业落地仍更多停留在早期阶段——整体来看,当前行业的订单仍以“验证性采购”为主,而非基于生产力需求的扩张性采购。
不过,也有积极的信号开始显现。极智嘉、卧安机器人、宇树科技等企业在2026年先后实现盈利转正,经营现金流大幅改善。极智嘉的财务结构尤其值得关注:2023年至2025年,营收从21.43亿元增至31.71亿元,增幅近48%;同期三费合计占营收比从53.8%降至36.08%,而研发费用却逆势增长18.79%。这说明“自我造血”的商业化路径正在被验证。
3.3 海外市场:更具确定性的优先选择
基于ROI的刚性约束,海外市场成为更具商业确定性的方向。发达国家普遍面临人力成本高企、用工难、老龄化加剧等结构性矛盾,对自动化替代的需求更为迫切,市场接受度更高。
2026年,中国人形机器人出海正在从“会表演”加速迈向“能干活”。从CES到MWC,中国人形机器人走进不同国家的制造和商业应用场景。数据显示,2025年全球人形机器人装机量中,中国占比已超80%。国内人形机器人整机企业数量已超140家,发布产品超330款。
优必选已与欧洲集成商合作,将机器人部署于欧洲大型零售商ROSSMANN的物流中心,标志着中国自研机器人正式进军海外工业场景。英伟达CEO黄仁勳评价中国机器人行业的崛起时用了“令人敬畏”这个词,认为其原因在于中国的微电子、电机等机器人技术基础领域“都是世界顶尖水平”。
2026年被业界视为人形机器人行业“规模化量产与商业化落地元年”。研究报告显示,全球人形机器人产业将在2026年下半年进入商业化关键阶段,中国企业正迅速明确商业应用场景并扩大生产规模,预计2026年产量将显著增长。
四、自动驾驶的镜像:数据体系如何决定成败
如果说具身智能仍在摸索中前行,那么自动驾驶十余年的发展史则提供了一面极具参考价值的镜子。其核心启示在于:从依赖纯真机采集的静态数据,到仿真生成与真机验证结合的根本性转变,是自动驾驶走向规模化的关键转折。
4.1 高精地图的教训:静态数据的不可持续
自动驾驶早期高度依赖高精地图,通过专业采集车队获取厘米级精度的道路信息。这种做法在早期降低了感知算法的压力,让系统快速搭建起来,但很快就暴露了致命缺陷:制作成本极高,维护地图“鲜度”需要持续投入,而依赖高精地图的车辆只能在已测绘区域运行,限制了泛化能力。
高精地图从“提升效率的权宜之计”演变为“系统的基础依赖”,最终因规模化成本和泛化能力限制而被行业重新评估。一个深刻教训是:地图是静态的,场景是动态的,具身智能不能仅依赖实验室或工厂预采的固定数据集,真正的智能体现在对未知环境的适应。
这一教训对具身智能的直接启示是:如果行业仅依赖遥操作在固定环境中采集的数据,最终训练出的策略将同样面临“只能在采集场景中工作”的泛化困境。
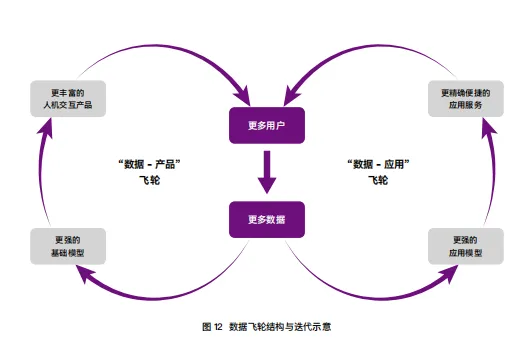
4.2 数据飞轮的断裂:具身智能的“先有鸡还是先有蛋”困局
自动驾驶的一个天然优势在于:车辆拥有明确的产品定义和既有的行驶场景,这使得数据采集可以与产品销售同步启动——每卖出一台车,就新增一个数据采集节点。而具身智能截然不同:机器人还没有大规模进入真实场景,就没有足够的数据来训练智能;没有足够智能的机器人,就无法进入真实场景创造价值。
数据飞轮在启动前是断裂的,需要企业主动、额外、持续地投入资源进行数据采集,无法像自动驾驶起步时“边卖车边采数”。这个判断精准地点出了具身智能面临的独特困境。
正因如此,智元机器人选择了一条破局之路——开源数据集AGIBOT WORLD 2026。2026年4月7日,智元正式开源这一覆盖具身智能全域研究的真实场景数据集,所有数据均采集自100%真实世界,涵盖商业空间、酒店、商超、家居等多元场景。
智元总裁彭志辉(稚晖君)的战略逻辑很清晰:开源数据集、开放仿真平台Genie Sim 3.0、建设数据服务平台觅蜂科技——目标是让全行业一起生产数据,形成数据飞轮。这种做法与特斯拉Optimus的垂直整合路线形成鲜明对比:特斯拉选择自己做硬件、自己做模型、自己建数据护城河,好处是数据不外流,坏处是只有自己一家公司的数据能用。智元则试图用开放生态的策略,撬动整个行业的力量来突破数据瓶颈。
4.3 失败数据的价值:从“演示”到“实战”的关键跳板
自动驾驶的发展还揭示了另一个重要规律:在demo演示阶段需要筛选后干净的专家数据,但实际应用充满噪声,模型需要从大量失败案例中学会判断好坏。被忽视的负面样本对模型能力提升同样有重要作用。
在具身智能领域,这一认知正在转化为实践。智元机器人提出了ADC(对抗数据采集)模式,通过增加数据的信息密度和多样性,以20%的数据量达到传统方案2.7倍的效果。同时,其提出的HIL-SERL系统,通过“Human-in-the-Loop”的强化学习,让机器人在真实世界中1-2.5小时内学会多种高精度、灵巧的操作任务,成功率接近100%。
五、关键博弈:巨头入局、技术路线与世界模型
5.1 科技巨头的“物理世界卡位战”
2026年,科技巨头在具身智能领域的布局明显提速,竞争从数字空间延伸至物理世界。
阿里巴巴通过高德推出了首款四足机器人“途途”,其核心依托自研的ABot全栈具身技术体系,包含Abot-World世界模型、Abot-N0具身导航模型及具备反思纠错能力的Abot-claw架构。这一动作补齐了阿里从“云端大脑”到“物理躯干”的最后一环。菜鸟日均处理超8000万包裹,饿了么与淘宝闪购日订单量突破8000万单——从干线物流到“最后一公里”,四足机器人在园区配送、外卖取送、驿站分拣等场景中都有明确的用武之地。
特斯拉则走在更具野心的道路上。2026年3月,特斯拉官方发布Optimus Gen3量产版本的演示视频,重点展示了22个自由度的仿生灵巧手(指尖操作精度可达0.08毫米)和升级的减速机构。马斯克表示,Optimus Gen3将于2026年夏季启动生产,2027年实现大规模量产。更令人瞩目的是,特斯拉决定逐步终止Model S与Model X车型的生产,将加州弗里蒙特工厂原有产线全面转为Optimus专用制造基地,初期规划年产5万至10万台,长期目标为100万台。
字节跳动推出的GR-2模型,在预训练阶段观看了3800万个互联网视频片段,微调阶段使用了4万条机器人轨迹数据,最终在超过100个任务中实现了平均成功率97.7%。
这场“物理世界卡位战”的底层逻辑是:从电脑到手机,行业竞争焦点从“功能的堆砌”转向“平台的可靠性、成本与通用性”。具身智能也可能走向类似路径——未来硬件本体标准化,利润变薄但市场总量急剧扩大,一个全新的开发者群体将应运而生。
5.2 VLA路线与世界模型路线:谁会率先突破?
当前,具身智能的核心技术路线主要分为两大阵营。主流路径是端到端的VLA(视觉-语言-动作)模型,但当VLA模型的参数规模从7B扩张到更大的量级后,能力增长并未如预期般持续涌现,反而呈现出了“边际递减”的上限。
与此同时,世界模型路线正在崛起。智源研究院在《2026十大AI技术趋势》中将世界模型定义为AGI新范式,指出行业共识正从语言模型转向能理解物理规律的多模态世界模型,“预测下一个状态”成为核心方向。
世界模型的逻辑非常诱人:让机器人在“想象”中评估和选择最优策略,从而处理需要长时序推理、规避风险或实现复杂目标的任务。NVIDIA的Cosmos系列、DeepMind的Genie、OpenAI的Sora、World Labs的空间智能模型都在朝这个方向努力。
但需要保持应有的谨慎:世界模型仍处于早期探索阶段。当前模型在长时序预测中的误差累积、物理一致性保持、实时推理效率等方面仍面临共性挑战;“互联网数据+真实数据”路线与Sim2Real仿真路线正在并行探索,尚未形成统一收敛。
六、结语:穿越周期,拥抱即将到来的生态革命
2026年,具身智能正在经历一场深刻的叙事转换——从“能否做到”转向“能否有用”。这场转换远比想象中艰难,因为它不再是单一技术指标的突破,而是涉及数据、成本、可靠性、标准等多维约束的系统工程。
从政策层面看,具身智能已连续第二年被写入政府工作报告,工信部等八部门印发《“人工智能+制造”专项行动实施意见》,首个覆盖人形机器人全产业链的国家级标准体系正式发布。政策的顶层设计正在为产业构建基础设施。
从市场层面看,IDC预测2026年全球智能机器人硬件市场规模将接近300亿美元,中国具身智能机器人市场规模将突破110亿美元。中商产业研究院的数据则显示,2025年中国具身智能市场规模约9150亿元,同比增长20.4%。《中国发展报告2025》更指出,具身智能市场规模有望在2035年突破万亿元。
从数据层面看,行业的胜负手正在从“谁能造出机器人”转向“谁能驱动数据飞轮”。智元开源数据集、觅蜂打造数据平台、光轮刷新数据订单纪录、NVIDIA构建仿真生态——这些信号共同指向一个判断:具身智能的竞争,本质上不是硬件的竞争,而是AI数据基础设施的竞争。
2026年最值得关注的发展方向
数据采集与治理服务平台的崛起。行业标准的缺失导致“数据孤岛”问题,亟需统一的数据采集平台和权威的第三方评测体系。觅蜂科技提出“让数据像水电一样即取即用”的愿景,智域基石致力于“将海量、杂乱、非标、分散的原始数据转化为可加工、可交付、可复用、可持续供给的高质量训练输入”——这些正是数据基础设施层的核心玩家。
垂直场景解决方案的深度挖掘。聚焦具体行业、解决确定性问题、创造可计算的ROI,是目前最具商业明确性的路径。京东已定位为“具身智能超级供应链”,发布全链路具身智能数据基础设施。开普勒则放弃“广而浅”的横向泛化数采模式,聚焦工业垂类纵向泛化核心赛道。
“云-边-端”协同架构的成熟。未来图景是:云端利用大规模算力进行持续技能训练、测试与优化;边缘侧服务器承担本地机器人的实时协同、数据预处理和隐私敏感计算;机器人本体则进化成为相对标准化的通用移动计算平台,通过标准接口按需加载和执行技能包。
站在2026年4月这个时间节点,我们正在见证一场比互联网更深刻的技术革命。具身智能的价值不仅在于创造出能跑能跳的机器人,更在于它将人工智能从数字空间延伸到物理世界,重新定义了“智能”与“行动”的关系。而数据,正是这场革命的底层燃料——谁能掌握数据的采集、治理与应用能力,谁就能在这场万亿级的产业竞赛中占据先机。
具身智能的“GPT-3.5时刻”不会凭空到来。它需要百万小时的真实世界物理互动数据作为燃料,需要开放的行业标准和评测体系作为基础设施,需要从“演示”到“部署”的工程化跨越作为验证。但通往高阶智能的发展路径是渐进的:先通过小数据在确定性问题中证明工程价值、获取初始现金流;再通过深耕场景,用大量数据驱动迭代,建立垂直行业壁垒;最终,海量数据与前沿算法相结合,不断提升智能表现水平。




















本文根据《国际先进技术应用推进中心(深圳)·具身智能数据行业研究白皮书》核心内容与2026年4月最新行业动态撰写。
📌 延伸阅读与产业洞察:如果你想获取更全面的行业研究报告、具身智能产业链图谱、投融资实时数据、政策解读和专家观点,欢迎加入 「汇策网知识星球」 。我们持续跟踪具身智能、AI大模型、自动驾驶等前沿科技赛道,每日更新产业动态与深度分析,助你在技术变革中把握先机。
1.点击阅读原文链接,直接下载《国际先进技术应用推进中心(深圳)·具身智能数据行业研究白皮书》。
2.添加汇策网小助手微信咨询,微信号HCWZH001
3.长按识别下图二维码,下载更多报告。


内容说明:文章由汇策网智库根据网络资料整理,以为读者提供阅读参考为目的,相关内容如有侵权,请留言或私信汇策网智库公众号删除。