 夜雨聆风
夜雨聆风





摩根大通30秒生成投行PPT——华尔街AI革命离我们还有多远?

2025年秋天,摩根大通首席分析官Derek Waldron在CNBC的镜头前做了一个演示。他对着公司内部AI平台敲了一段话——“你是摩根大通的科技银行家,正在准备与英伟达CEO和CFO的会面,请准备一份五页的演示文稿,包含最新动态、业绩数据和同业对比。”
大约30秒,一份结构完整的PowerPoint出来了。
Waldron说:“你能想象以前这件事怎么完成的吗?一群投行分析师熬夜好几个小时。”
我第一次看到这个新闻的时候,说实话,震撼之余更多是好奇——30秒生成的东西,质量到底怎么样?能直接拿去用吗?后来细看才发现,摩根大通做的事情远比“生成一个PPT”复杂得多
不是某个团队在尝鲜
是整个华尔街在换血
过去两年里,一件很少被国内媒体充分报道的事情是:华尔街三大投行几乎在同一时间窗口内,完成了AI从实验性项目到全员日常工具的切换。
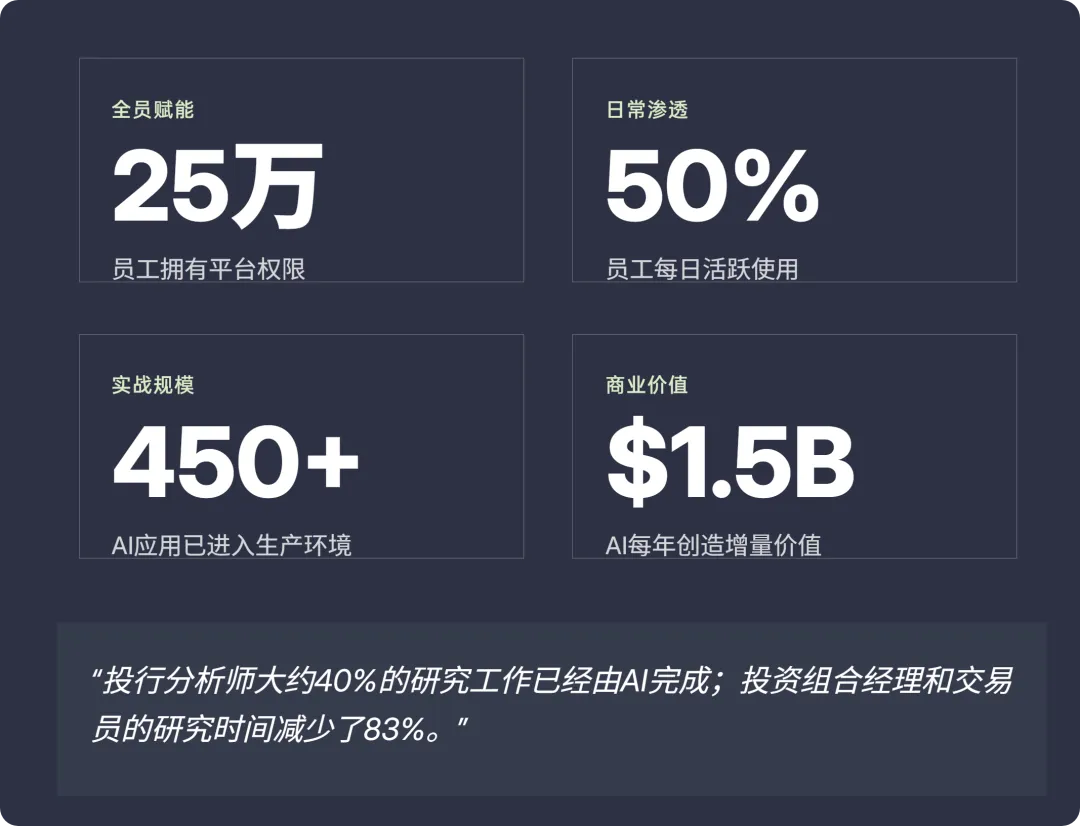
摩根大通内部搭建了一个叫LLM Suite的平台,接入了OpenAI和Anthropic等多家大模型,跑在自己的安全环境里。到2025年下半年,25万员工有权限使用这个平台,大约一半的人每天都在用。每八周更新一次,每次把更多内部数据库和业务系统接进去。450多个AI应用已经在实际生产环境中运行,公司总裁公开说过,AI每年给公司带来10亿到15亿美元的价值。
这些数字已经够惊人了,但真正让我觉得“游戏规则变了”的是另外几个数据:投行分析师大约40%的研究工作已经由AI完成;投资组合经理和交易员的研究时间减少了83%。83%——这意味着以前一个交易员花5个小时做的研究,现在不到1个小时。
高盛走了一条稍微不同的路。它在2025年中推出了GS AI Assistant,有一个我觉得很聪明的设计——“模型无关”架构,员工在同一个安全界面里可以用GPT、Gemini、Claude等不同模型,系统根据任务类型推荐最合适的那个。另外,高盛在它12000人的开发团队里全面部署了自主编程代理Devin,据说编程效率翻了3到4倍。
摩根士丹利则是华尔街里最早跟OpenAI合作的,给财富管理顾问做了AI知识助手,帮顾问快速检索研究报告和回应客户咨询。这套东西推动资管销售两年内增长了20%。
三家机构,三条路径,但方向惊人一致。而且请注意,这三家是全世界最谨慎的金融机构之一——它们对风险的敏感度、对合规的要求、对数据安全的重视,远高于大部分企业。连它们都在全力推进,说明这件事已经过了“要不要做”的阶段。
我从中看到的三件事
聊完“做了什么”,更值得聊的是“为什么做成了”。因为很多企业也在做AI,但大部分没什么效果。华尔街这波有几个做法,我觉得很值得拆开来看。
关于AI定位这件事。 摩根大通在对外沟通中反复说一个意思:LLM Suite不是来替代分析师的,是让分析师别把时间花在“人不该干的活”上。这话听起来像公关话术,但仔细想其实是一个很重要的设计决策。
一份投资分析报告的生成过程,拆开来看,至少包括这些环节:数据提取、指标计算、同业对比、异动识别、归因分析、观点形成、报告撰写、格式排版。这里面,数据提取和指标计算是代码的事,格式排版是模板的事,AI最擅长的是同业对比、异动识别和报告撰写——这些以前要占分析师大量时间的“搬砖活”。但到了归因分析和观点形成,就进入了需要业务判断的领域——“这家公司营收下降,到底是行业周期问题还是管理层决策失误?”这种问题,AI可以提供参考信息,但拍板必须是人来做。
想清楚每个环节里“AI做什么、人做什么”,比选哪个模型重要得多。很多企业AI项目失败,不是模型不好,是根本没想清楚这个问题。
关于数据安全这件事。 有一个细节可能很多人不知道——摩根大通在AI浪潮最火热的2023年,做的第一件事不是“赶紧上AI”,而是“禁止员工用ChatGPT”。银行的客户数据、交易策略、内部研报,不可能放到外部平台上去。它后来选择自建平台,所有模型跑在内网里,数据不出去。
这跟中国很多企业面临的情况一模一样。尤其是国有企业和金融机构,数据安全不是一个“最好有”的功能点,是一个“没有就不能开工”的前置条件。本地化部署、数据不出网、权限严格隔离——这些不是技术洁癖,是业务刚需。
关于真正的壁垒这件事。 摩根大通用的模型是OpenAI和Anthropic的,高盛也是多模型混合使用——模型不是自研的。那它们的壁垒在哪?在于把模型跟自己几十年积累的业务系统、数据资产、工作流程深度打通了。LLM Suite每八周更新一次,每次接入更多内部系统,这个过程本质上是在把AI“浸泡”在业务场景里,让它越来越理解“摩根大通的人怎么工作”。
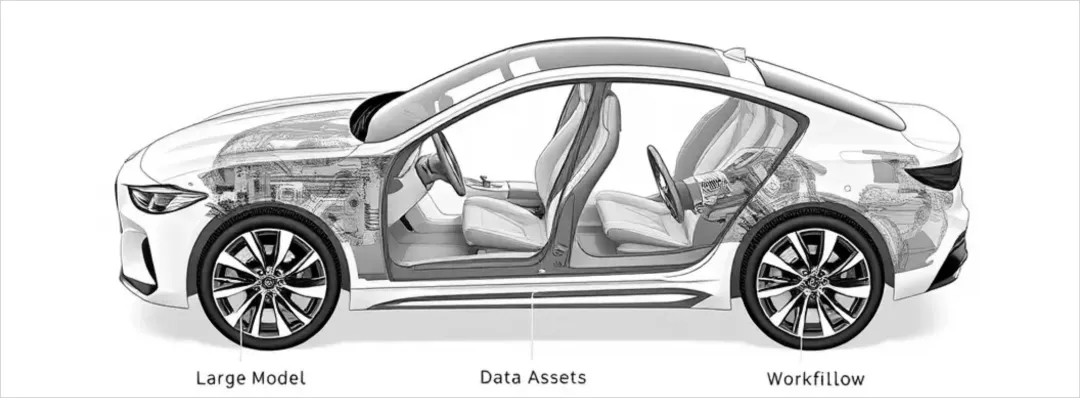
这就像一个比喻——大模型是发动机,谁都能买到差不多的发动机,但造出好车还需要懂路况、懂驾驶需求的人来设计底盘和方向盘。模型能力越来越趋同的今天,真正的竞争力在于谁更懂自己的业务场景,谁能把AI和具体工作流结合得更紧。
那中国企业呢?
老实说,如果只看IT预算,差距很大。摩根大通一年技术投入超过180亿美元,国内绝大多数企业不可能复制这个量级。但我不觉得这是一个悲观的理由。原因有几个。
首先,国产大模型的能力在过去一年里进步非常快。DeepSeek、通义千问、智谱这些模型在中文理解、财务分析、行业推理等场景上的表现已经相当能打了。“发动机”不再是瓶颈。
其次,政策环境在明确加速。国资委已经启动了央企“AI+”专项行动,要求各央企在“十五五”规划中把AI作为重点方向。行业统计显示,2025年央国企数智化转型整体预算接近7000亿元,AI相关预算占比大幅提升。不缺钱,也不缺政策信号。
从地方的动作也能看出这个趋势。就在4月17日,青岛发布了《数字青岛2026年行动方案》,提出人工智能产业规模突破1000亿元、发布1000个AI场景清单、智能算力占比提升至60%。去年青岛的AI产业营收已经达到870多亿。一座城市的蓝图背后,是全国性的加速节奏。
所以真正稀缺的东西不是模型,也不是预算——是把模型和业务场景对接起来的能力。
举一个离我们更近的例子。国内很多大型集团公司,每个季度都要出一份财务分析报告,需要把几十甚至几百家子公司的数据汇总、比对、分析异动原因、做同行对标,最后形成一份能拿上会的报告。这个活,一个有经验的财务分析团队通常要干两到三周。行业调研数据显示,68%的集团企业合并报表周期超过15天,财务团队80%的精力花在了数据核对上,真正有价值的分析反而没时间做。
这个场景用AI来做,技术上完全可行。但问题在于,市面上没有一个通用AI产品能直接解决这个问题。你需要有人先理解这份报告是怎么写出来的——哪些环节是数据搬运、哪些是规则判断、哪些需要业务经验——然后再去设计AI该在每个环节里怎么介入、输出质量怎么验证、出了错怎么兜底。这个“翻译”过程,纯技术团队做不了,纯业务团队也做不了,需要两边都懂的人。
McKinsey有一个被广泛引用的数据:近90%的公司已经投资了AI,但不到40%看到了可衡量的回报。为什么?绝大多数不是技术本身不行,而是在“从技术到业务价值”这个中间地带断裂了——有模型,但不知道该塞进哪个业务环节;有数据,但数据治理跟不上AI的要求;有预算,但团队里懂技术的不懂业务、懂业务的不懂技术。
华尔街的经验从反面印证了同一个道理:摩根大通做得好,不是因为它用了最贵的模型,而是因为它有一套“先把业务场景吃透、再让AI进来”的方法论——先识别高价值场景,想清楚人和AI各做什么,快速验证效果,然后再规模化推广。这个方法论不需要百亿级预算,但需要对业务有足够深的理解,需要有人能在“技术语言”和“业务语言”之间做翻译。

写在最后
华尔街每年花几百亿美元搞技术,中国大部分企业没有这个条件。但今天的AI落地,拼的不是谁钱多。拼的是谁更早想清楚,AI该在自己的业务里扮演什么角色。
这件事,跟预算关系不大,跟认知关系很大。
下一篇我们聊一个更扎心的问题:为什么90%的企业AI项目没有产生效果?落地到底难在哪?
撰写:Dr.Leader
编辑:Sheldon
审核:刘宇
声明
原创内容的最终解释权以及版权归众航所有。如需转载文章,请在信息栏输入“转载”,获取转载须知。
联系我们:
如需了解更多关于众航达瑞的服务和研究成果,请关注我们的公众号,或直接联系我们获取更多信息。