 夜雨聆风
夜雨聆风





从Claude Code源码看智能体驾驭(Harness)设计模式
引言
当我们讨论AI Agent时,通常聚焦于模型能力——推理、规划、工具调用。但一个生产级Agent系统的真正挑战不在模型,而在驾驭(Harness)——如何安全、高效、可持续地驱动模型的每一步行动。
本文从源码层面,拆解Claude Code的六大核心设计维度:
-
1. Query主循环:Agent的心脏——一个永不退出的while(true) -
2. 工具编排:44个工具的并发执行与权限管控 -
3. 上下文工程:四层压缩策略保活长对话 -
4. 记忆系统:三层记忆架构与自动梦境整合 -
5. 子代理架构:Forked Agent模型与缓存共享 -
6. 权限沙箱:分级信任与自动分类器
读完本文,你会理解为什么Agent框架和Agent运行时是两个完全不同的工程问题。
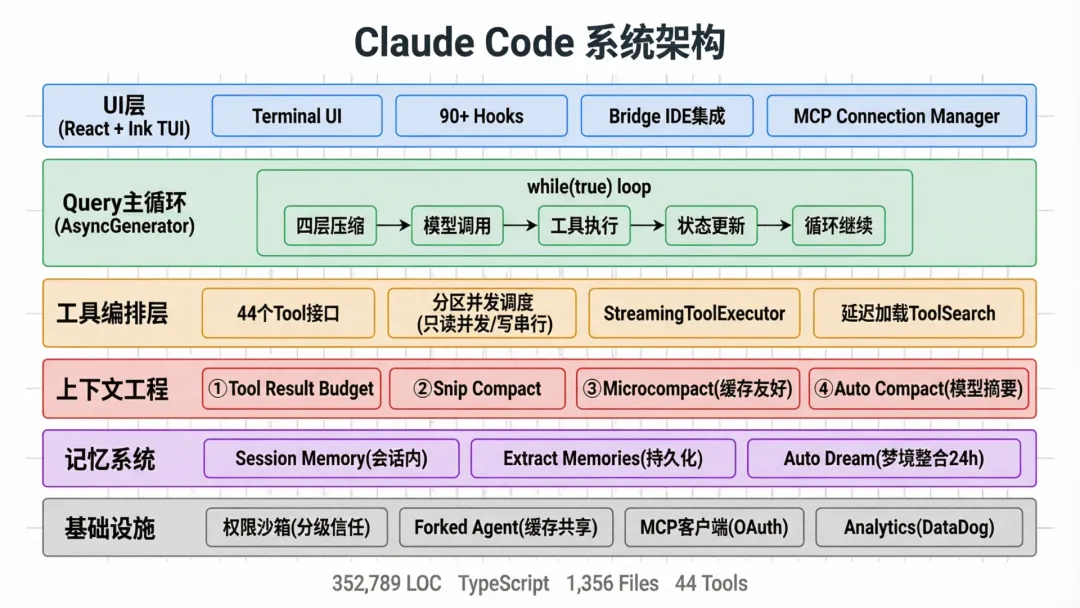
一、Query主循环:永不退出的心脏
1.1 Agent Loop的本质
所有Agent系统的核心都是一个循环:用户输入 → 模型推理 → 工具执行 → 结果反馈 → 再次推理。Claude Code把这个循环实现为一个AsyncGenerator:
// query.tsexport async function* query(params: QueryParams): AsyncGenerator<StreamEvent | Message, Terminal> { const terminal = yield* queryLoop(params, consumedCommandUuids) return terminal}为什么用Generator而不是普通函数?因为Agent的响应是流式的——模型一边思考一边输出,工具一边执行一边回报进度,用户可以在任何时候中断。Generator天然支持这种”逐步产出、随时暂停”的语义。
1.2 主循环的完整生命周期
进入queryLoop后,你会看到一个经典的结构:
async function* queryLoop(params, consumedCommandUuids) { let state: State = { messages, toolUseContext, ... } while (true) { // ① 上下文预算控制 let messagesForQuery = [...getMessagesAfterCompactBoundary(messages)] messagesForQuery = await applyToolResultBudget(messagesForQuery, ...) // ② 历史裁剪(Snip Compact) if (feature('HISTORY_SNIP')) { const snipResult = snipModule.snipCompactIfNeeded(messagesForQuery) messagesForQuery = snipResult.messages } // ③ 微压缩(Microcompact) const microcompactResult = await deps.microcompact(messagesForQuery, ...) // ④ 上下文折叠(Context Collapse) if (feature('CONTEXT_COLLAPSE')) { const collapseResult = await contextCollapse.applyCollapsesIfNeeded(...) } // ⑤ 自动压缩(Auto Compact) const { compactionResult } = await deps.autocompact(messagesForQuery, ...) // ⑥ 调用模型(Streaming) for await (const message of deps.callModel({ messages, systemPrompt, tools, ... })) { yield message // 流式产出给UI } // ⑦ 工具执行 for await (const update of runTools(toolUseBlocks, ...)) { yield update.message } // ⑧ 循环继续或终止 if (!needsFollowUp) break state = { ...state, messages: [...messages, ...toolResults] } }}这个循环的精妙之处在于每次迭代前的四层上下文压缩。在第⑤步,如果对话太长,系统会启动AutoCompact——用模型自身生成对话摘要,替换原始消息。这确保了Agent可以无限期运行,不会因为上下文溢出而崩溃。
1.3 状态管理的哲学
State对象的更新采用了不可变模式:
// Continue sites write `state = { ... }` instead of 9 separate assignmentsstate = { ...state, messages: [...messages, ...toolResults], turnCount: state.turnCount + 1, transition: 'tool_result',}每次迭代产生新的State对象,而不是就地修改。这种不可变设计让状态追踪变得可预测——任何一个时刻,你都可以确信当前State是完整的、一致的。
1.4 熔断与恢复
主循环内置了多层熔断机制:
-
• Max Output Tokens恢复:当模型输出被截断时,自动恢复并继续 -
• 流式回退(Streaming Fallback):主模型失败时,自动切换到fallback模型 -
• 压缩熔断器:连续压缩失败3次后,停止重试(避免无限循环浪费API调用)
// Stop trying autocompact after this many consecutive failures.// BQ 2026-03-10: 1,279 sessions had 50+ consecutive failures (up to 3,272)// in a single session, wasting ~250K API calls/day globally.const MAX_CONSECUTIVE_AUTOCOMPACT_FAILURES = 3这个注释说明了这不是理论设计——这是从真实生产数据中得出的经验值。1,279个会话曾经陷入无限压缩循环,每天浪费25万次API调用。
二、工具编排:44个工具的并发执行引擎
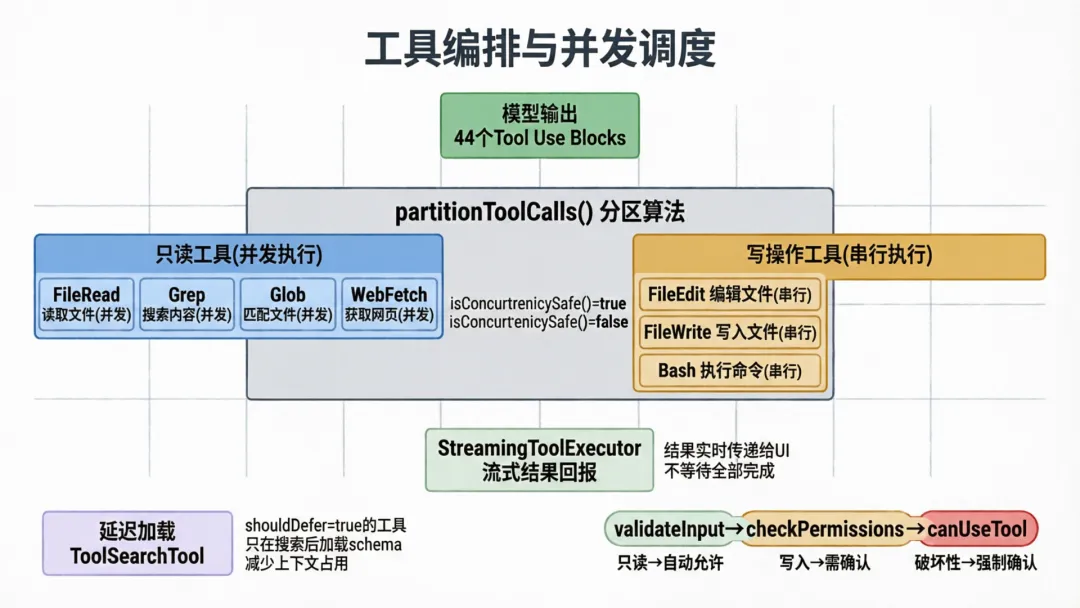
2.1 工具接口设计
Claude Code的Tool接口可能是所有Agent系统中最完整的:
type Tool<Input, Output, P> = { name: string aliases?: string[] // 工具别名(向后兼容) searchHint?: string // 用于ToolSearch的关键词 shouldDefer?: boolean // 是否延迟加载 alwaysLoad?: boolean // 是否始终加载(不受延迟影响) maxResultSizeChars: number // 结果大小上限 call(args, context, canUseTool, parentMessage, onProgress?): Promise<ToolResult> isConcurrencySafe(input): boolean // 是否可以并发执行 isReadOnly(input): boolean // 是否只读 isDestructive?(input): boolean // 是否破坏性操作 checkPermissions(input, context): Promise<PermissionResult> validateInput?(input, context): Promise<ValidationResult> // ... 还有10+个可选方法}44个工具中,每个都实现了这个接口。关键设计点:
-
• :决定工具是否可以与其他工具并行执行 -
• :只读工具可以获得更宽松的权限 -
• / :控制工具的加载策略(延迟加载减少上下文占用) -
• :工具输出超过阈值时自动持久化到磁盘,避免上下文膨胀
2.2 分区并发调度
toolOrchestration.ts实现了一个精巧的分区调度算法:
function partitionToolCalls(toolUseMessages, toolUseContext): Batch[] { // 将工具调用分成批次: // 批次1: 连续的只读工具 → 并发执行 // 批次2: 写操作工具 → 串行执行 // 批次3: 又一组只读工具 → 并发执行 // ...}这意味着如果模型同时请求读取3个文件和编辑1个文件,系统会先并发读取3个文件,然后串行执行编辑操作。最大化并行性的同时保证写入安全。
最大并发数通过环境变量控制,默认10:
function getMaxToolUseConcurrency(): number { return parseInt(process.env.CLAUDE_CODE_MAX_TOOL_USE_CONCURRENCY || '', 10) || 10}2.3 延迟工具加载(Tool Search)
Claude Code引入了ToolSearchTool——一个搜索工具的工具。不是所有44个工具都一开始就暴露给模型,有些工具(如Notebook编辑、PowerShell、Tungsten等)被标记为shouldDefer: true,只有在模型通过ToolSearch查找后才会加载完整schema。
这个设计解决了一个核心问题:工具schema太大会挤占上下文窗口。44个工具的完整JSON Schema可能占几千个Token,但大部分任务只需要5-6个工具。
2.4 流式工具执行(Streaming Tool Executor)
// StreamingToolExecutor.tsclass StreamingToolExecutor { constructor(tools, canUseTool, toolUseContext) { // 工具一边执行,一边流式回报结果 } discard() { // 流式回退时丢弃未完成的结果 }}流式执行允许工具结果在产生的同时就传递给UI和后续处理,而不需要等待所有工具执行完毕。这对于Bash命令(可能运行几分钟)特别重要——用户可以实时看到命令输出。
三、上下文工程:四层压缩策略
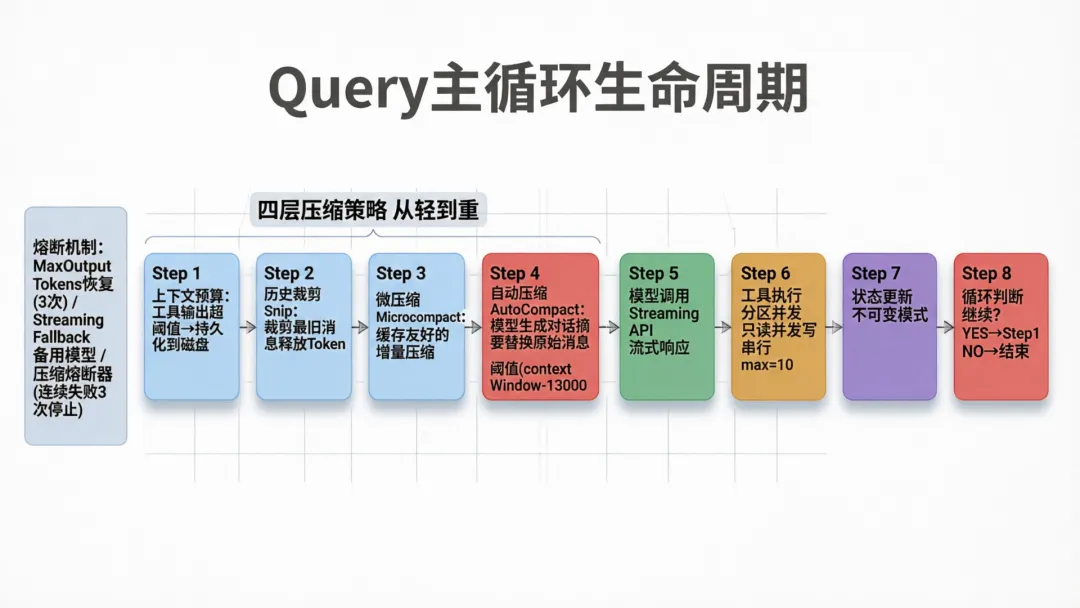
3.1 为什么需要四层?
Claude Code的上下文管理可能是所有Agent系统中最复杂的——因为它必须支持无限长对话。一个开发者可能连续和Claude Code工作几小时,产生数百条消息和工具调用。不做上下文管理,系统会在几十轮后崩溃。
四层策略从轻到重:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.2 Tool Result Budget
工具的输出可能非常大(比如读取一个大文件、执行一个复杂的grep)。Claude Code的策略是:
messagesForQuery = await applyToolResultBudget( messagesForQuery, toolUseContext.contentReplacementState, persistReplacements ?records => void recordContentReplacement(records) : undefined, // 不持久化的工具(如FileRead)设为Infinity new Set(tools.filter(t => !Number.isFinite(t.maxResultSizeChars)).map(t => t.name)),)当工具输出超过maxResultSizeChars阈值时,内容被保存到磁盘文件,消息中只保留文件路径。这样模型知道结果存在,但不会被巨大的文本占满上下文。
3.3 Auto Compact:用模型压缩自己
当上下文接近模型的窗口上限时,Auto Compact启动——用一个独立的forked agent生成对话摘要:
const { compactionResult } = await deps.autocompact(messagesForQuery, toolUseContext, { systemPrompt, userContext, systemContext, toolUseContext, forkContextMessages: messagesForQuery,}, querySource, tracking)关键设计:压缩本身也是一个Agent调用。系统用一个独立的Agent来阅读完整对话历史,生成精简摘要,然后用摘要替换原始消息。这意味着压缩质量等于模型的理解能力——不是简单的截断,而是真正的语义压缩。
Auto Compact还有智能的触发阈值:
export function getAutoCompactThreshold(model: string): number { const effectiveContextWindow = getEffectiveContextWindowSize(model) return effectiveContextWindow - AUTOCOMPACT_BUFFER_TOKENS // 13,000 buffer}不是等上下文满了才压缩,而是留出13,000个Token的缓冲区。这个值来自生产数据的分析——压缩本身需要消耗Token,缓冲区确保压缩请求不会被拒绝。
3.4 Microcompact与缓存友好
Auto Compact的代价很高(一次完整的Agent调用),Microcompact是一种更轻量的增量压缩。它的关键创新是缓存友好——修改缓存的对话前缀,而不是完全替换。
const microcompactResult = await deps.microcompact( messagesForQuery, toolUseContext, querySource)这意味着在Anthropic API的Prompt Caching机制下,Microcompact可以复用之前的缓存,大幅降低成本。
四、记忆系统:三层架构与自动梦境整合
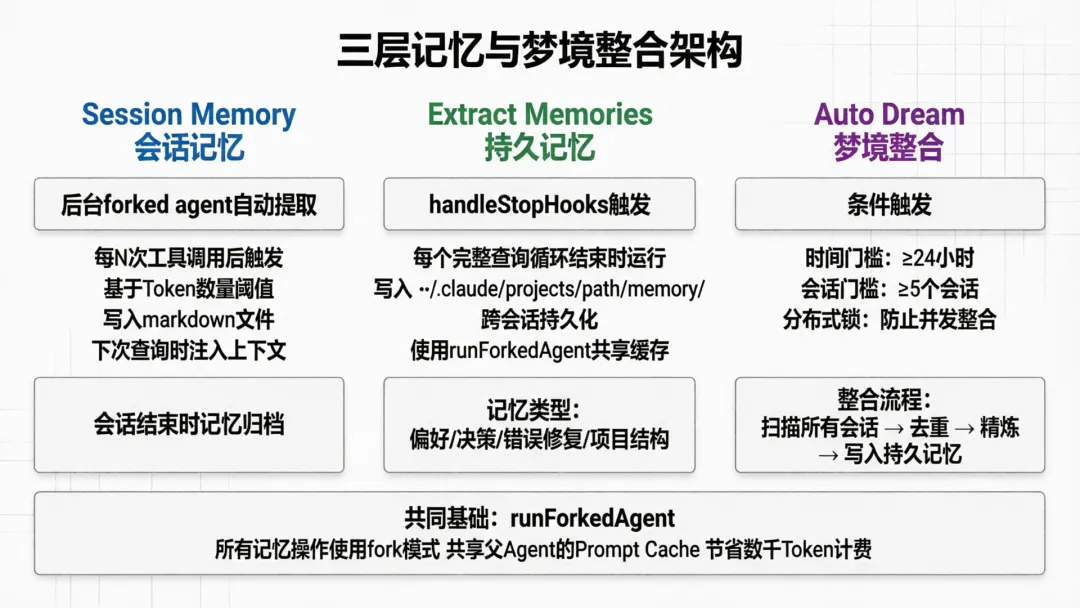
4.1 三层记忆
Claude Code的记忆系统分为三层:
第一层:Session Memory(会话记忆)
// SessionMemory/sessionMemory.ts// 自动维护一个markdown文件,记录当前对话的关键信息// 使用forked subagent后台提取,不阻塞主对话Session Memory在后台自动运行——每次工具调用达到一定阈值后,系统启动一个后台Agent,阅读最近的对话,提取关键信息写入markdown文件。这个文件在下次查询时作为上下文注入。
第二层:Extract Memories(持久记忆)
// extractMemories/extractMemories.ts// 从对话中提取持久记忆,写入 ~/.claude/projects/<path>/memory/// 在每个完整查询循环结束时运行(handleStopHooks)持久记忆存储在~/.claude/projects/<path>/memory/目录下,跨会话持久化。当你下次打开Claude Code时,系统会自动加载这些记忆。
第三层:Auto Dream(梦境整合)
// autoDream/autoDream.ts// 后台记忆整合。当时间门槛和会话数量都满足时触发// 使用 /dream prompt 作为forked subagent运行Auto Dream是最有趣的设计。它模仿人类的睡眠整合机制——当积累了足够多的会话(默认≥5个)且经过足够长的时间(默认≥24小时),系统启动一个后台Agent来整合所有会话的记忆,去除重复、提炼关键信息。
4.2 记忆提取的阈值设计
function shouldExtractMemory(messages: Message[]): boolean { const currentTokenCount = tokenCountWithEstimation(messages) if (!isSessionMemoryInitialized()) { if (!hasMetInitializationThreshold(currentTokenCount)) return false markSessionMemoryInitialized() } const hasMetTokenThreshold = hasMetUpdateThreshold(currentTokenCount) const toolCallsSinceLastUpdate = countToolCallsSince(messages, lastMemoryMessageUuid) // ...}记忆提取不是每条消息都触发,而是有智能的阈值控制——基于Token数量和工具调用次数。只有在积累了足够的新信息后才启动提取,避免频繁的后台Agent调用。
4.3 Forked Agent模式
记忆提取和梦境整合都使用了runForkedAgent——一个关键的基础设施:
// utils/forkedAgent.tsexport async function runForkedAgent(params: { cacheSafeParams: CacheSafeParams messages: Message[] ...}): Promise<{ messages: Message[]; usage: Usage }> { // 创建一个与主对话共享缓存参数的Agent // 确保fork的API请求能命中父对话的Prompt Cache}CacheSafeParams确保fork出来的Agent与父Agent共享完全相同的系统提示、工具列表和消息前缀——这是Prompt Cache命中的关键条件。一次缓存命中可以节省数千个Token的计费。
五、子代理架构:多Agent协作模型
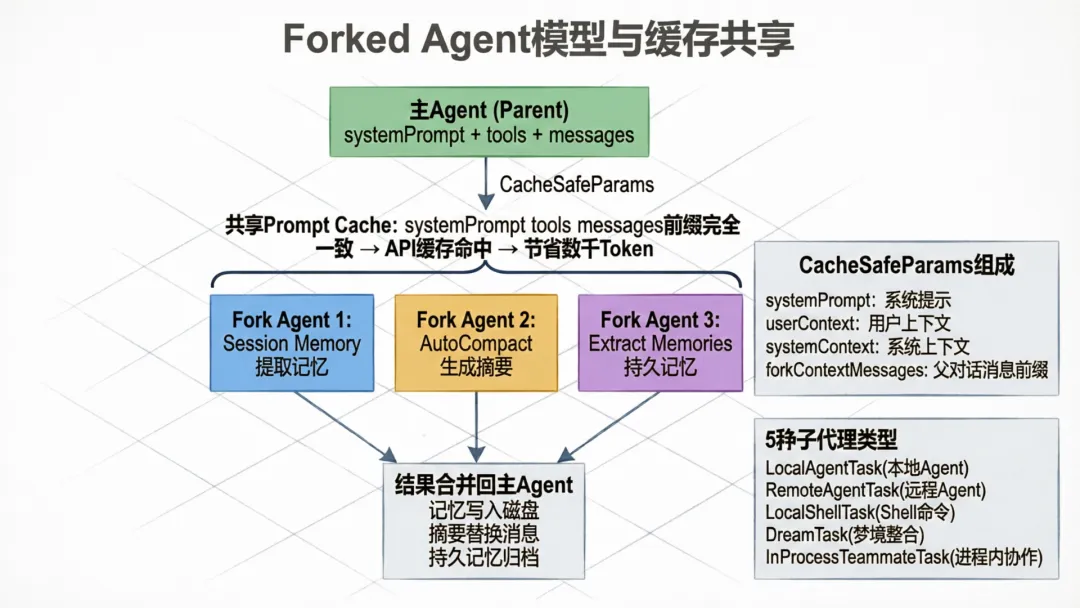
5.1 五种任务类型
Claude Code的子代理系统支持5种任务类型:
|
|
|
|
|---|---|---|
LocalAgentTask |
|
|
RemoteAgentTask |
|
|
LocalShellTask |
|
|
DreamTask |
|
|
InProcessTeammateTask |
|
|
5.2 LocalAgentTask详解
LocalAgentTask是最核心的子代理实现:
type LocalAgentTaskState = { type: 'local_agent' agentId: string prompt: string selectedAgent?: AgentDefinition agentType: string model?: string abortController?: AbortController result?: AgentToolResult progress?: AgentProgress pendingMessages: string[] // 待处理的消息队列 isBackgrounded: boolean // 是否在后台运行 retain: boolean // UI是否正在查看 diskLoaded: boolean // 是否已从磁盘加载 evictAfter?: number // 驱逐时间戳}关键设计点:
-
• pendingMessages:主Agent可以通过 SendMessage工具向子Agent发送消息,这些消息被缓存在队列中,在工具轮次边界时传递给子Agent -
• isBackgrounded:子Agent可以在后台运行,不阻塞主Agent -
• retain:用户可以”进入”子Agent的视图,实时查看它的执行过程 -
• evictAfter:子Agent完成后不会立即销毁,而是在一段时间后被垃圾回收
5.3 进度追踪
type ProgressTracker = { toolUseCount: number latestInputTokens: number cumulativeOutputTokens: number recentActivities: ToolActivity[]}type ToolActivity = { toolName: string input: Record<string, unknown> activityDescription?: string // 如 "Reading src/foo.ts" isSearch?: boolean isRead?: boolean}每个子Agent维护自己的进度追踪器,最近5个活动被保留用于UI展示。Token统计分开追踪输入和输出——因为Anthropic API的输入Token是累积的(包含所有之前的上下文),而输出Token是每次独立的。
5.4 Coordinator Mode
Claude Code还有一个Coordinator模式——一个特殊的Agent可以充当协调者,管理多个子Agent:
// coordinator/coordinatorMode.tsif (isEnvTruthy(process.env.CLAUDE_CODE_COORDINATOR_MODE)) { return asSystemPrompt([getCoordinatorSystemPrompt()])}Coordinator模式使用独立的系统提示,专注于任务分配和结果综合,而不是直接执行任务。
六、权限沙箱:分级信任模型
6.1 权限模式
Claude Code的权限系统支持多种模式:
type PermissionMode = | 'default' // 每次操作都询问 | 'plan' // 只读规划模式 | 'autoEdit' // 自动允许编辑 | 'fullAuto' // 全自动(需配置白名单) // ...6.2 工具级权限控制
每个工具都实现了checkPermissions()方法:
type Tool<Input, Output, P> = { checkPermissions(input: Input, context: ToolUseContext): Promise<PermissionResult> // ...}权限检查分三层:
-
1. validateInput:验证输入是否合法 -
2. checkPermissions:判断是否需要用户确认 -
3. canUseTool:最终的权限决策(考虑白名单/黑名单/自动分类器)
6.3 自动分类器
在fullAuto模式下,Claude Code使用一个安全分类器来评估每个工具调用的风险:
toAutoClassifierInput(input: Input): unknown每个工具都需要实现这个方法,将自己的输入转换为分类器能理解的紧凑表示。例如:
-
• Bash工具返回命令字符串(如 ls -la) -
• FileEdit工具返回文件路径和变更摘要 -
• FileRead工具可以返回空字符串(无安全风险,跳过分类)
6.4 Bash沙箱
Bash工具是安全风险最高的工具,有独立的沙箱机制:
// tools/BashTool/shouldUseSandbox.ts// tools/BashTool/bashSecurity.ts// tools/BashTool/bashPermissions.ts沙箱配置包括:
-
• 命令超时(默认2分钟,最大10分钟) -
• 后台执行支持( run_in_background参数) -
• 破坏性命令检测和警告 -
• 路径验证(防止路径遍历攻击)
6.5 MCP权限管理
MCP(Model Context Protocol)工具的权限管理更加复杂:
// services/mcp/channelAllowlist.ts// services/mcp/channelPermissions.ts// services/mcp/channelNotification.ts每个MCP服务器连接都有独立的权限配置,包括:
-
• 通道白名单:哪些IM通道可以触发哪些MCP工具 -
• OAuth认证:支持MCP服务器的OAuth令牌流程 -
• 用户确认:新MCP工具首次使用时需要用户确认
七、MCP集成:外部工具生态系统
7.1 MCP连接管理
Claude Code实现了完整的MCP客户端:
// services/mcp/├── MCPConnectionManager.tsx // React Context管理MCP连接├── client.ts // MCP客户端├── config.ts // MCP配置├── auth.ts // OAuth认证├── types.ts // MCP类型定义├── normalization.ts // 工具名称规范化├── oauthPort.ts // OAuth端口管理├── officialRegistry.ts // 官方MCP注册表└── xaa.ts // 扩展认证MCP连接通过React Context管理,支持动态连接/断开/重连。每个MCP服务器提供一组工具,这些工具被动态注入到Agent的工具列表中。
7.2 MCP工具的延迟加载
MCP工具支持_meta['anthropic/alwaysLoad']标记——被标记的工具始终加载完整schema,未标记的工具默认延迟加载(通过ToolSearch发现)。
这个设计平衡了功能可见性和上下文效率:核心MCP工具(如代码分析)始终可见,辅助工具(如特定API集成)按需加载。
八、UI层:Ink + React的终端界面
8.1 技术选型
Claude Code使用React + Ink构建终端UI——这是一个不常见但非常聪明的选择:
-
• React:组件化、状态管理、Hooks -
• Ink:React的终端渲染器,支持Flexbox布局
这意味着90+个React Hooks(src/hooks/目录下)都可以在终端UI中使用,包括状态管理、事件处理、副作用管理等。
8.2 关键Hooks
useCanUseTool.tsx // 工具权限决策useBackgroundTaskNavigation // 后台任务导航useMergedTools.ts // 合并内置工具和MCP工具useSessionBackgrounding // 会话后台化useSwarmInitialization // Swarm模式初始化useSwarmPermissionPoller // Swarm权限轮询useMergedTools是特别重要的一个——它将内置的44个工具和动态加载的MCP工具合并成一个统一的工具列表,供给Agent使用。
8.3 Bridge架构
// bridge/ — IDE集成桥接├── bridgeMain.ts // 桥接主入口├── bridgeMessaging.ts // 消息传递├── bridgePermissionCallbacks.ts // 权限回调├── replBridge.tsx // REPL桥接├── createSession.ts // 会话创建└── remoteBridgeCore.ts // 远程桥接核心Bridge架构允许Claude Code与IDE(如VS Code)深度集成——在IDE中直接调用Claude Code,共享工作区、文件状态和终端。
九、系统提示工程
9.1 分层系统提示
Claude Code的系统提示构建是分层的:
function buildEffectiveSystemPrompt({ mainThreadAgentDefinition, toolUseContext, customSystemPrompt, defaultSystemPrompt, appendSystemPrompt, overrideSystemPrompt,}): SystemPrompt { // 优先级:Override > Coordinator > Agent > Custom > Default // appendSystemPrompt 总是追加在最后}系统提示有5层优先级:
-
1. Override:完全替换(如loop模式) -
2. Coordinator:协调者专用 -
3. Agent:自定义Agent定义 -
4. Custom: --system-prompt参数 -
5. Default:标准Claude Code提示
appendSystemPrompt总是追加在最后,不受优先级影响。
9.2 动态提示内容
系统提示不是静态字符串,而是动态构建的:
type Tool = { prompt(options: { getToolPermissionContext: () => Promise<ToolPermissionContext> tools: Tools agents: AgentDefinition[] }): Promise<string>}每个工具都实现了prompt()方法,在运行时动态生成自己的使用说明。这意味着工具的提示内容可以根据当前权限状态、可用Agent等因素动态调整。
十、设计模型总结:Harness的六大原则
从Claude Code的源码中,我们可以提炼出Agent Harness设计的六大核心原则:
原则一:永不信任模型输出
Claude Code的每一层设计都假设模型可能出错:
-
• validateInput验证工具输入 -
• checkPermissions检查操作权限 -
• LoopDetection防止死循环 -
• ToolResultBudget限制输出大小 -
• AutoCompact处理上下文溢出
这不是对模型的不信任,而是防御性工程——任何可能出错的地方,都要有保护机制。
原则二:流式一切
从Query主循环到工具执行到UI渲染,所有操作都是流式的。这意味着:
-
• 用户可以看到实时进度 -
• 可以随时中断任何操作 -
• 内存不会因为等待完整结果而溢出
AsyncGenerator是Claude Code最核心的抽象。
原则三:上下文是最宝贵的资源
四层压缩策略、延迟工具加载、Tool Result Budget、Tool Search——所有这些设计的核心目标都是高效利用有限的上下文窗口。
在Agent系统中,上下文窗口就是内存——它决定了Agent能”记住”多少信息。Claude Code的上下文工程可以总结为一句话:用最少的Token携带最多的信息。
原则四:Fork而不是Spawn
Claude Code的子代理使用runForkedAgent——fork而不是spawn。区别在于:
-
• Spawn:创建全新的Agent,从零开始 -
• Fork:复制当前Agent的状态,共享缓存
Fork的好处是缓存共享——子Agent可以复用父Agent的Prompt Cache,一次API调用可以节省数千Token。这个设计直接降低了运营成本。
原则五:分级信任
不是所有操作都需要同样的安全级别:
-
• 文件读取(只读)→ 自动允许 -
• 文件编辑(写入)→ 需要确认(或autoEdit模式) -
• Bash命令(执行)→ 安全分类器 + 用户确认 -
• 破坏性操作(删除/覆盖)→ 强制确认
这种分级信任模型在安全性和效率之间取得了平衡。
原则六:后台处理不阻塞前台
记忆提取、梦境整合、技能发现——所有这些后台任务都不阻塞主对话流:
// Memory prefetch — runs while the model streams and tools executeusing pendingMemoryPrefetch = startRelevantMemoryPrefetch(messages, toolUseContext)// Skill discovery — runs in parallel with tool executionconst pendingSkillPrefetch = skillPrefetch?.startSkillDiscoveryPrefetch(...)用户永远不会因为系统在后台整理记忆而等待。
结语
Claude Code的源码告诉我们:构建一个Agent很容易,但构建一个可靠的Agent运行时很难。
50万行代码不是过度工程——每一行都在解决一个真实的问题。四层上下文压缩解决了”对话过长”的问题;Forked Agent解决了”子Agent成本过高”的问题;分级权限解决了”安全与效率的矛盾”。
这些不是某个特定模型的限制——它们是Agent系统本身的工程挑战。任何想构建生产级Agent的团队,都需要面对这些问题。
Claude Code给出了它的答案。而理解这些答案背后的设计决策,比记住代码本身更重要。