 夜雨聆风
夜雨聆风





AI半导体产业链分析中篇-利润去哪了?
引言:
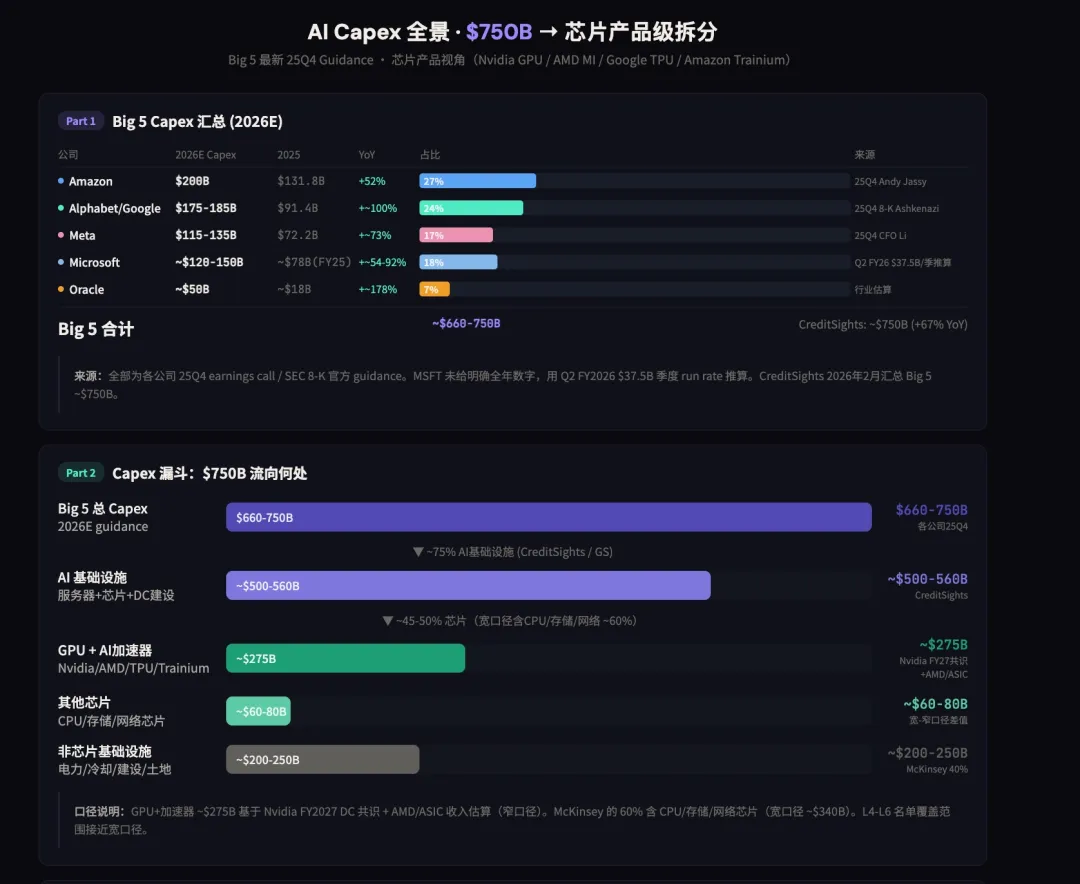
AI加速器市场格局
2026年, 各芯片厂牌的预计市场份额
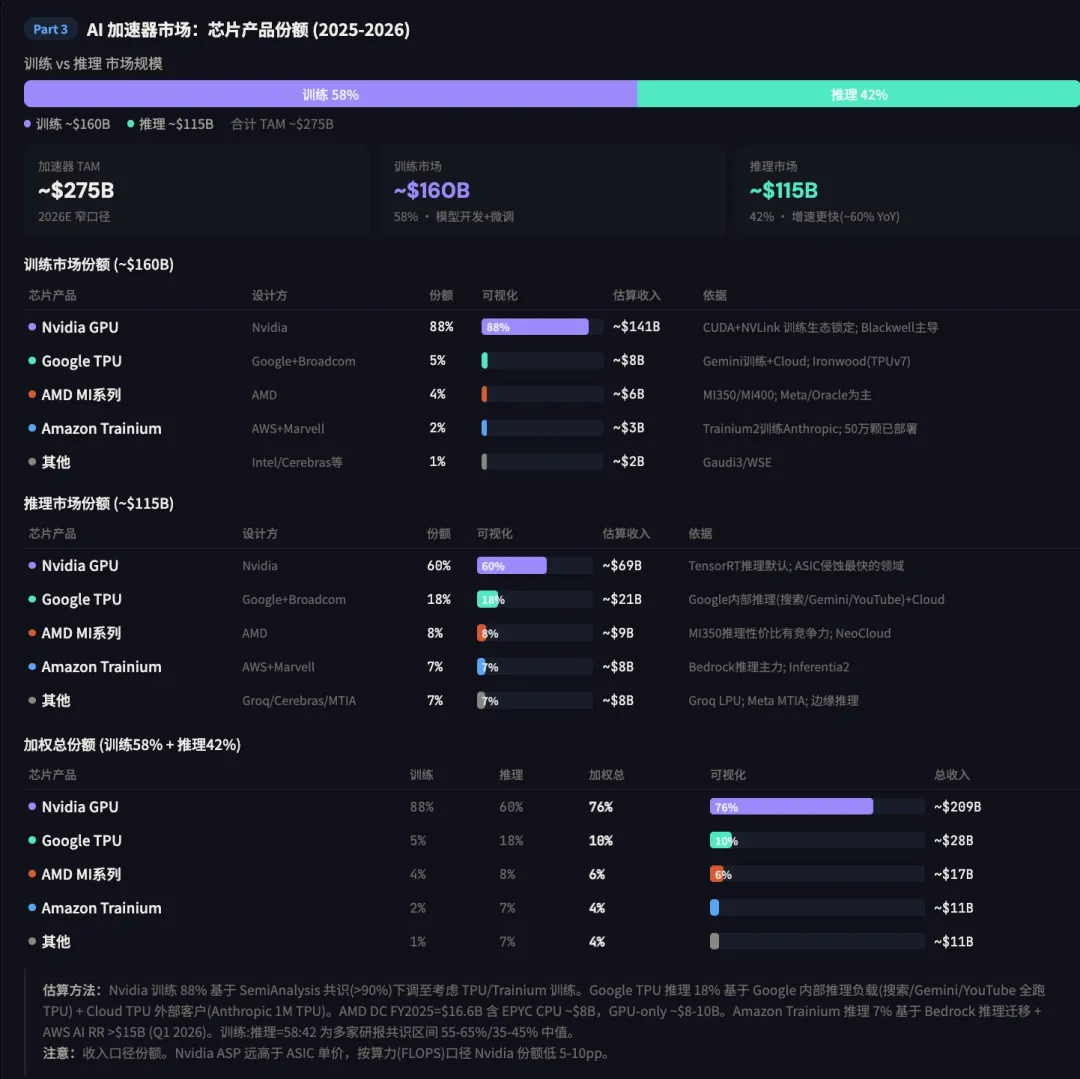
2027-2028年, 各芯片厂牌的市场份额预测
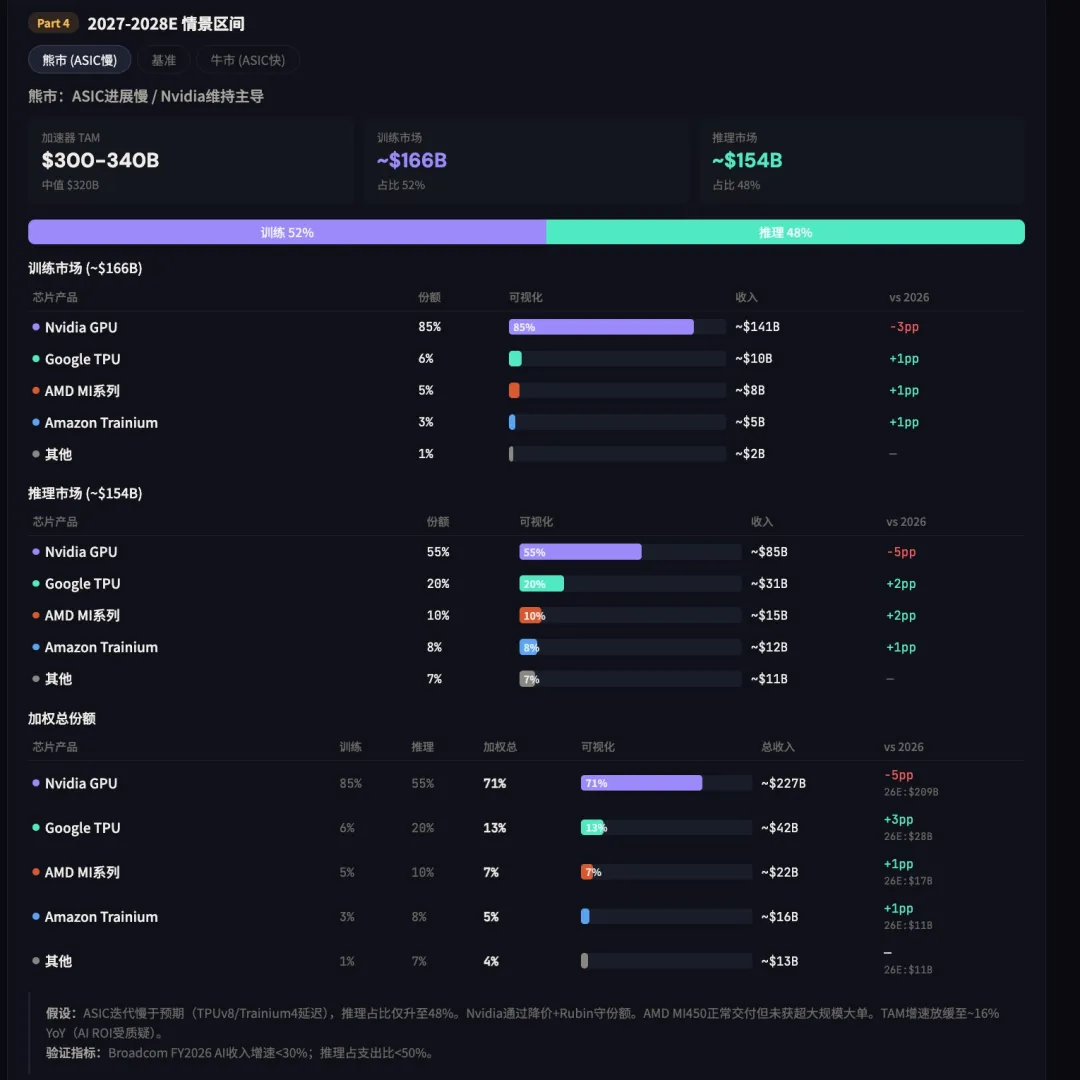
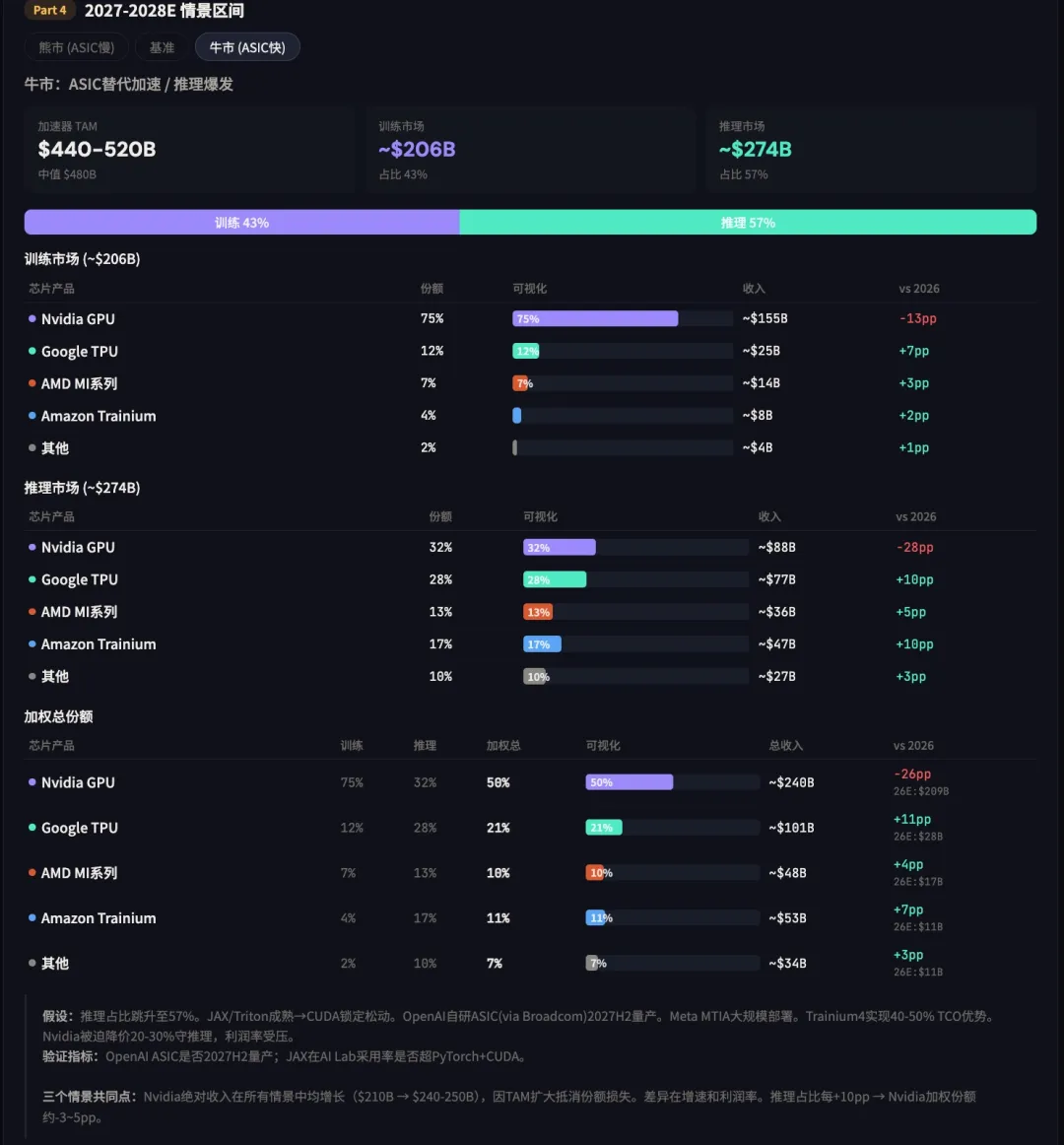
本文主题
本文主旨
Step 1:绘制价值链的利润分布图

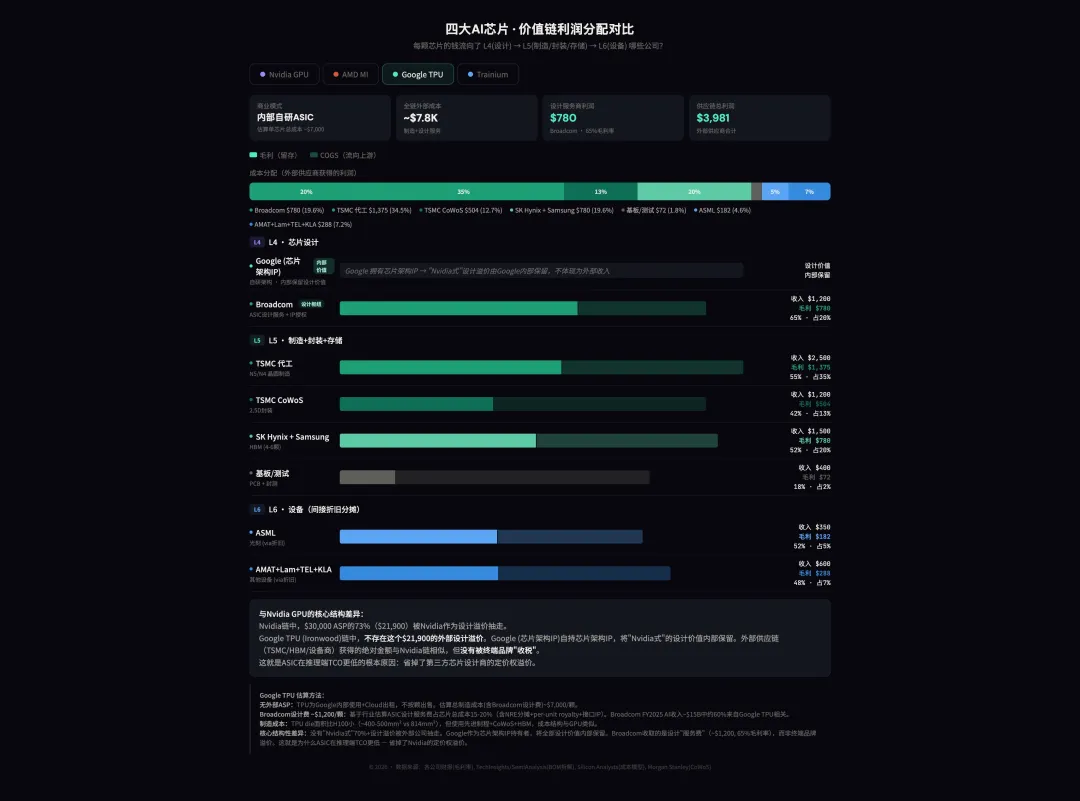

一、两种商业模式下的利润分配结构
|
|
|
|
|
|
|
|---|---|---|---|---|---|
|
|
|
|
84%
|
|
|
|
|
|
|
61%
|
|
|
|
|
|
|
|
40-45%
|
|
二、各环节”收税能力”三档分类
|
|
|
|
|
|
|---|---|---|---|---|
| 第一档:强力收税者 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 第二档:有壁垒但受限 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 第三档:做加工者 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Step 2:分析供给弹性——瓶颈在哪里,能持续多久
第一步:识别供需瓶颈在哪里
第二步:分析需求/产能与超额利润窗口
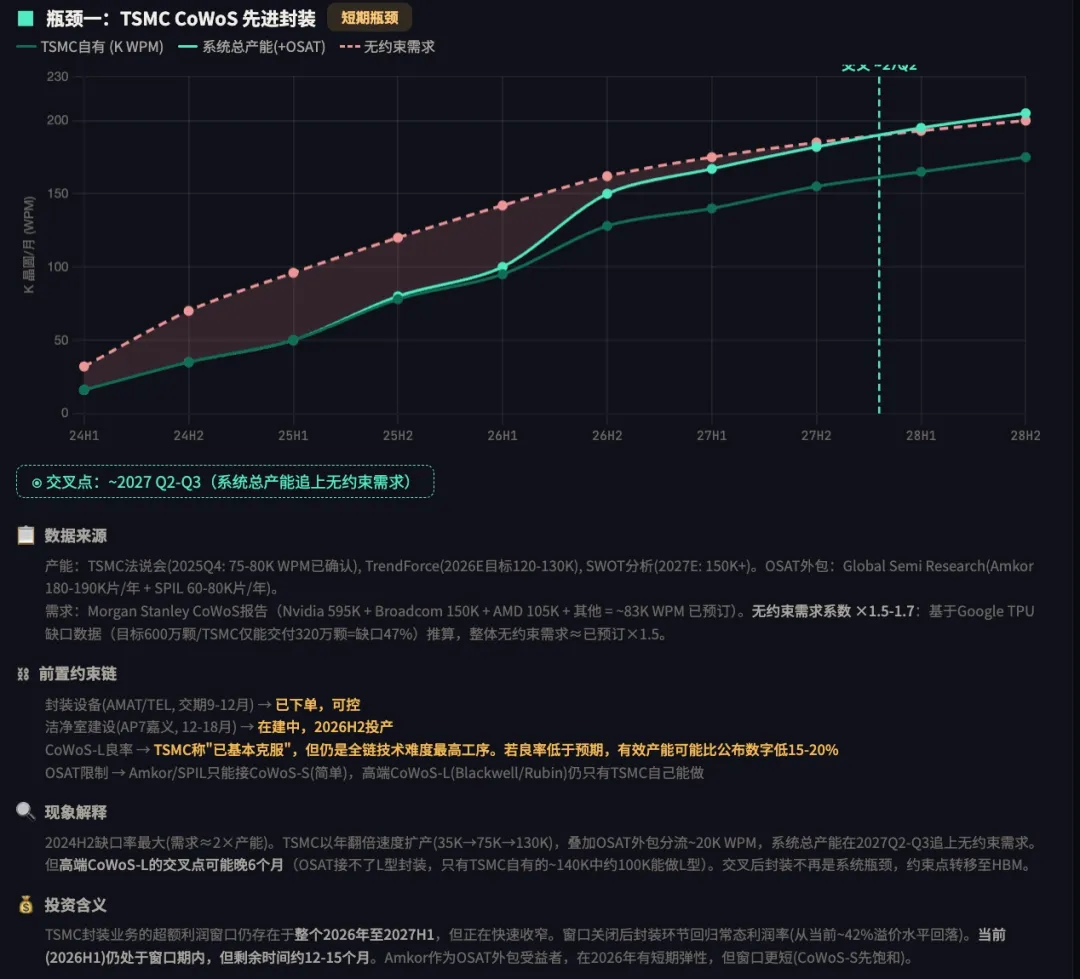
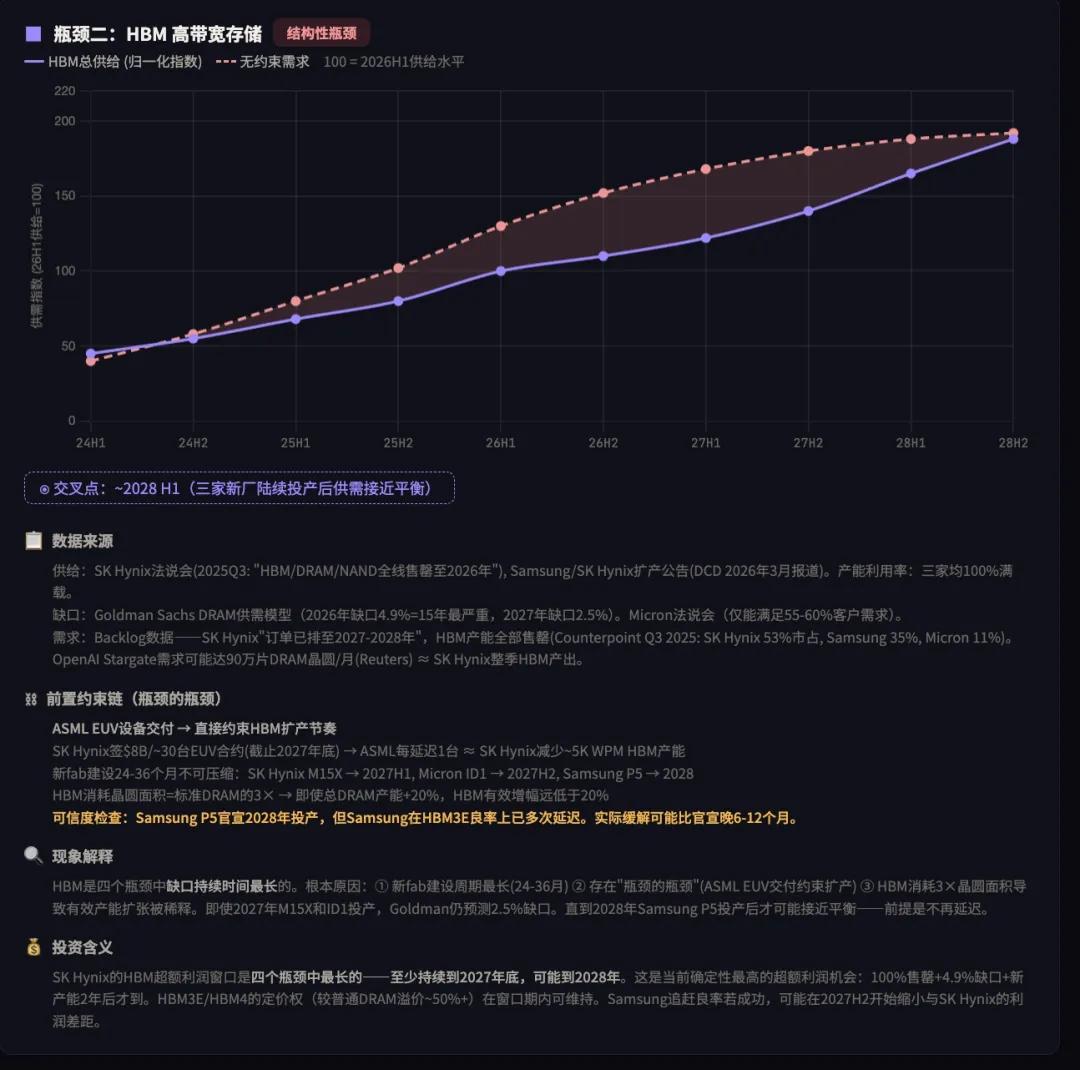
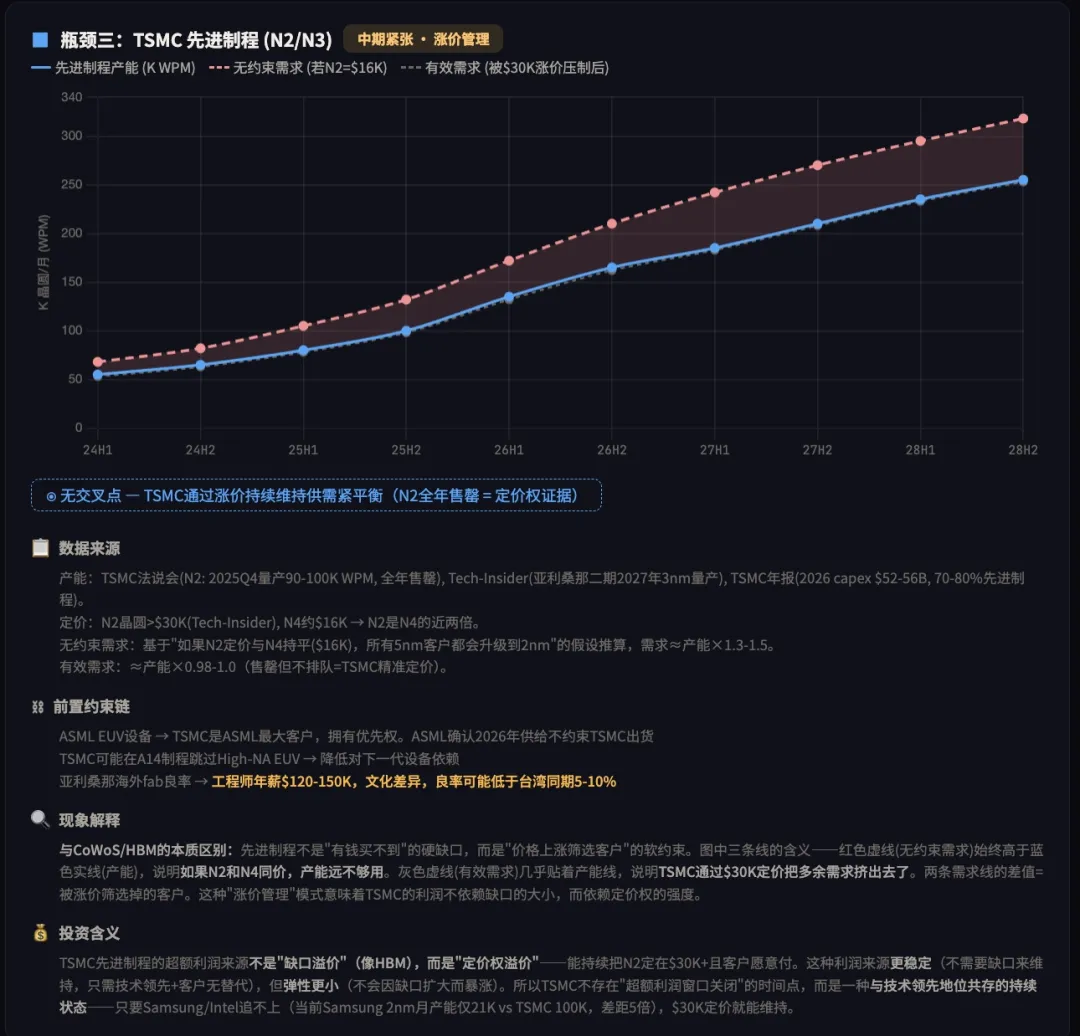
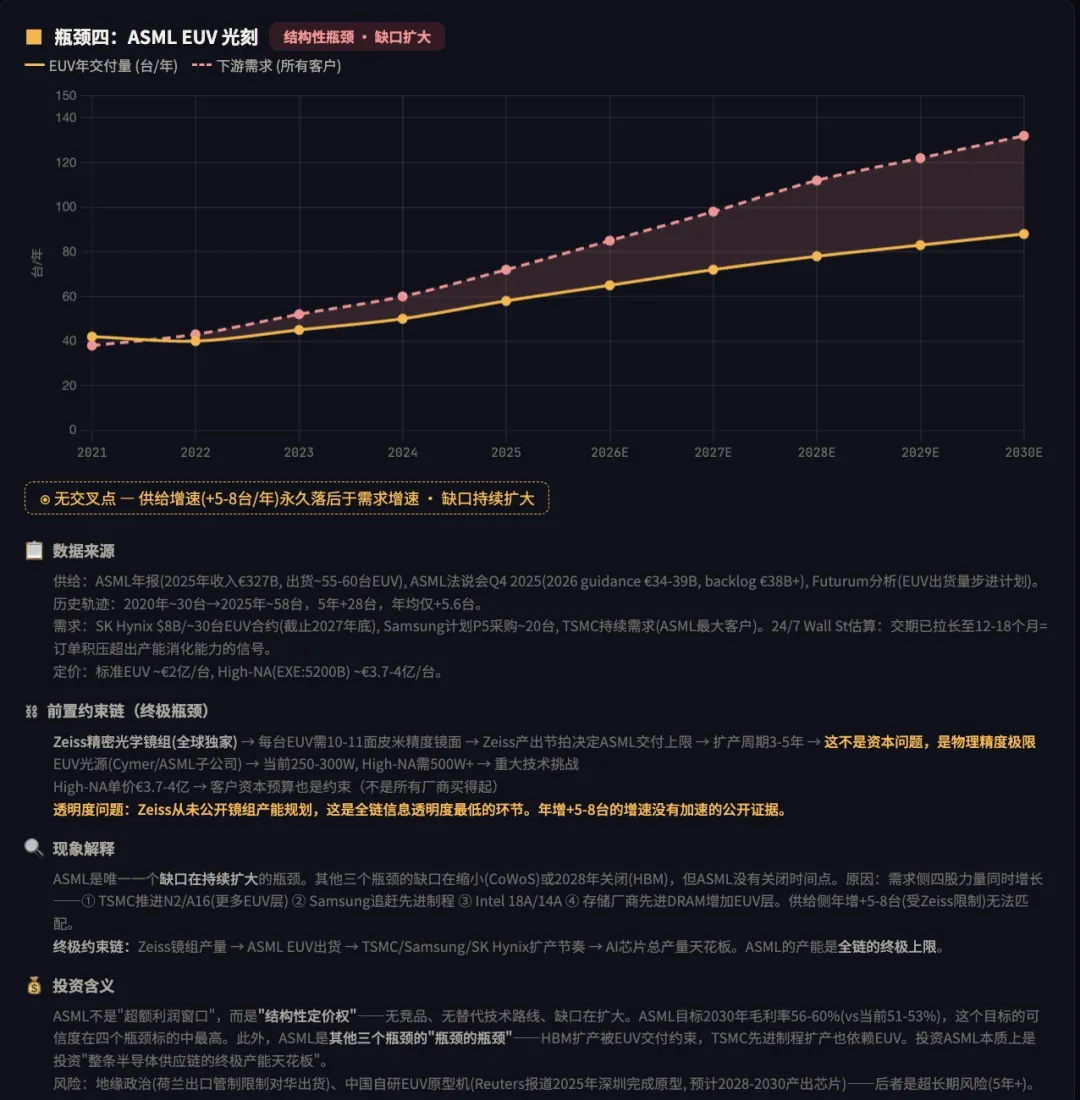
第三步: 瓶颈程度排序(超额利润 = 供需缺口 × 时间):
|
|
|
|
|
|
|
|---|---|---|---|---|---|
| 1 | HBM 存储 |
|
|
2028H1
|
整体瓶颈:~24 个月
|
| 2 | ASML EUV |
|
无竞争者
|
无交叉点
|
永久性定价权
|
| 3 | CoWoS 先进封装 |
|
|
2026Q4-2027Q1
|
整体 CoWoS:~9-12 个月
|
|
|
|
|
|
|
|
Step 3:追踪利润迁移方向——利润在向哪个环节转移?
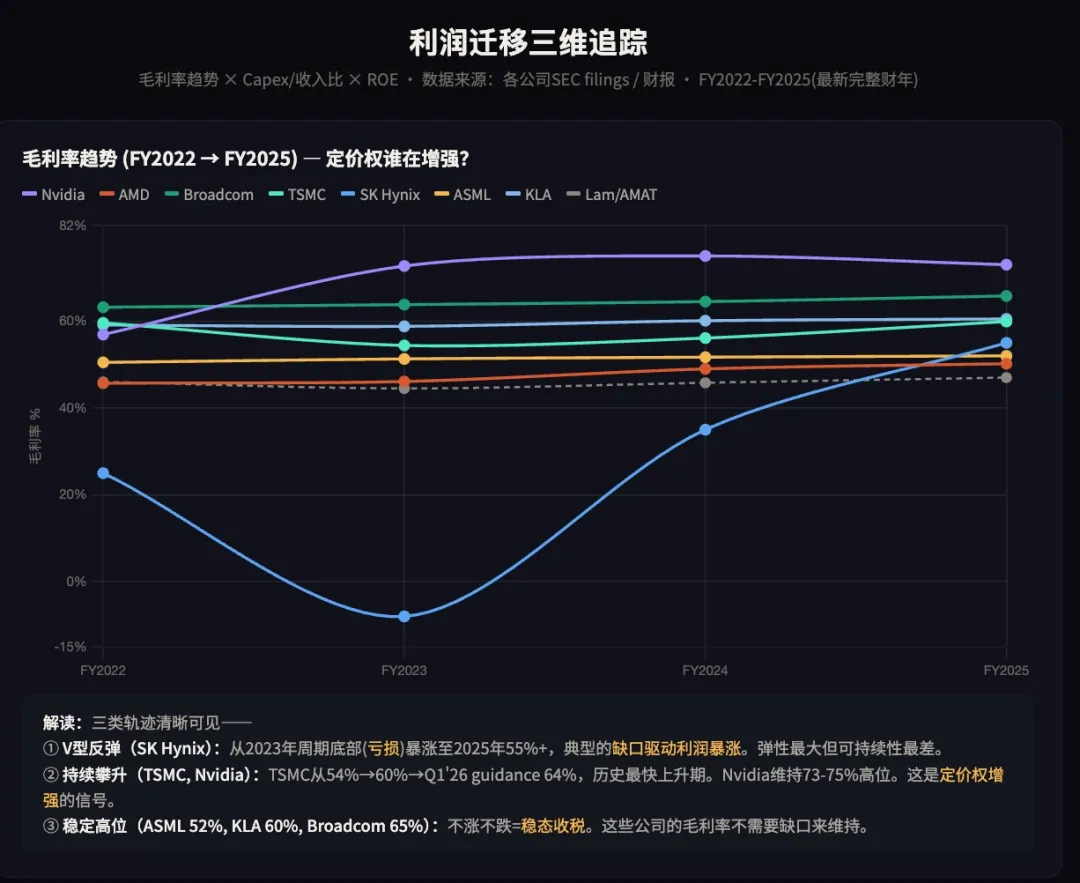
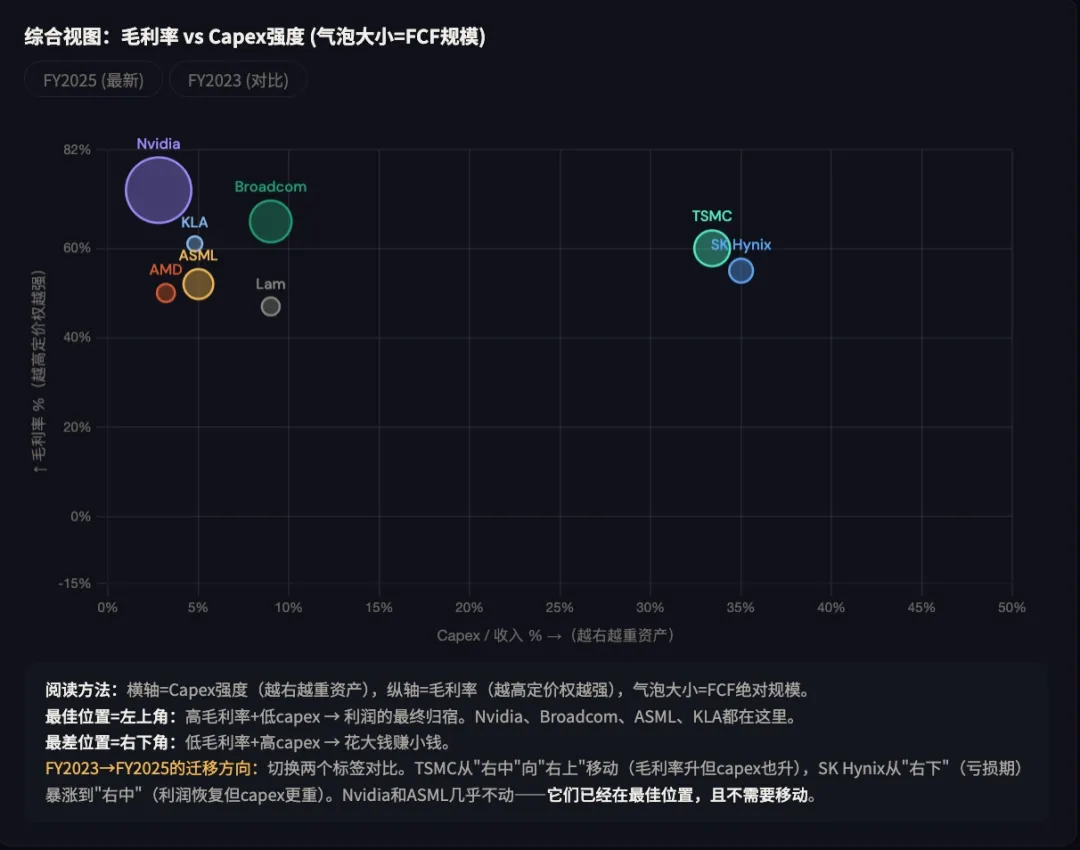
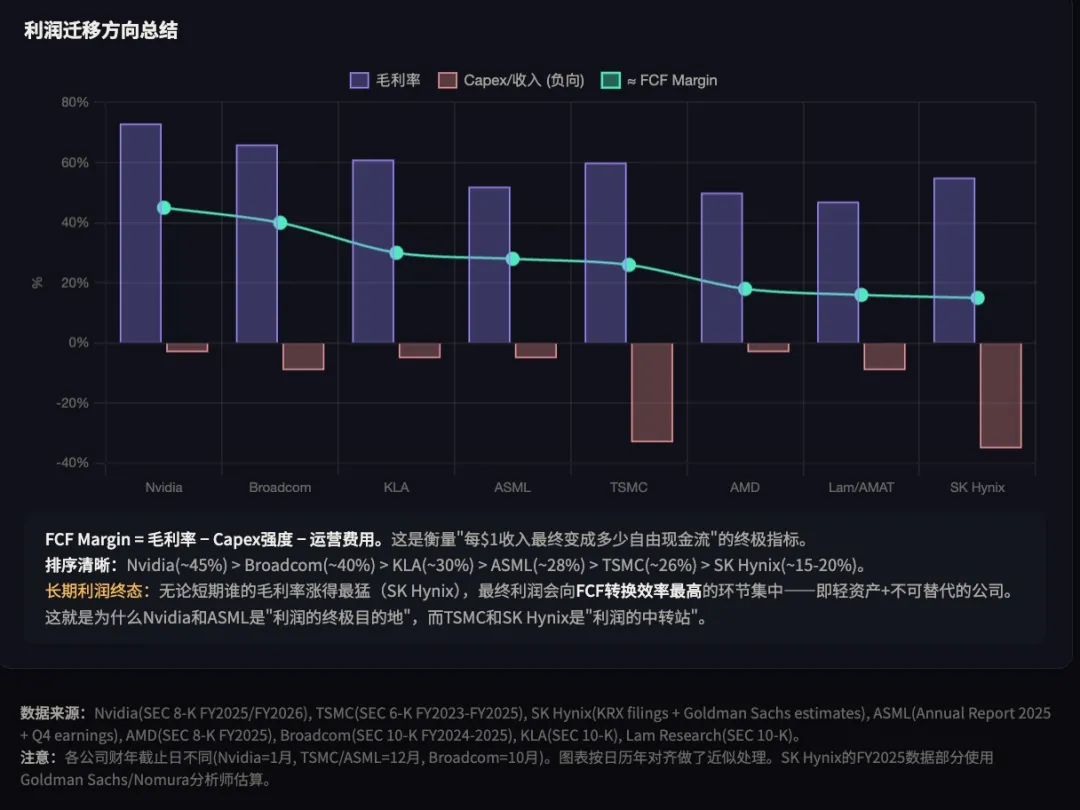
→ 核心观察: Nvidia 的毛利率从 AI 周期前的 60% 左右飙升至 75%+,且领先身位持续扩大;Broadcom、KLA 的毛利率稳步抬升;TSMC 从 50% 左右稳步提升至 55%+,但绝对值仍比设计层低 15-20 个百分点;而设备厂商(Lam/AMAT/TEL)、存储厂商(Samsung/Micron 在 HBM 之外)毛利率几乎没有受益于 AI 周期。
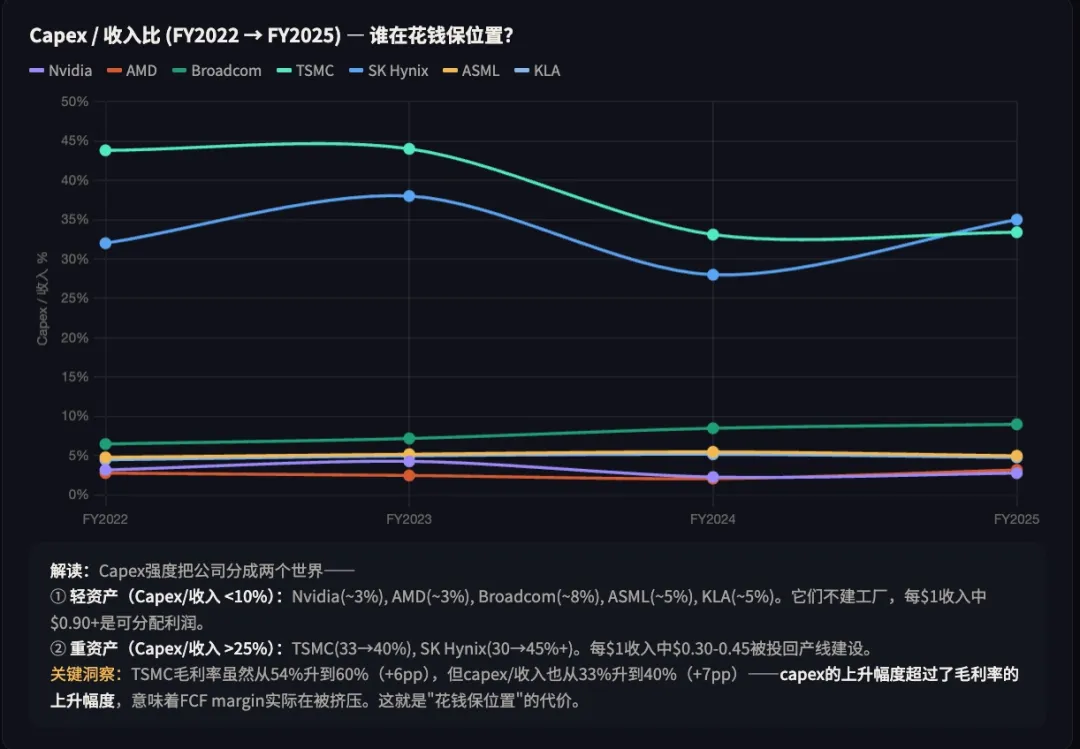
→ 核心观察: Fabless 设计公司(Nvidia、AMD、Broadcom)的 CapEx/收入比常年低于 5%,AI 周期中甚至有所下降(因为收入爆发而 CapEx 没同步增加);TSMC 的 CapEx/收入比长期在 40-45%,SK Hynix 在 30-35%,ASML 在 5-8%(设备厂本身也是相对轻资产)。
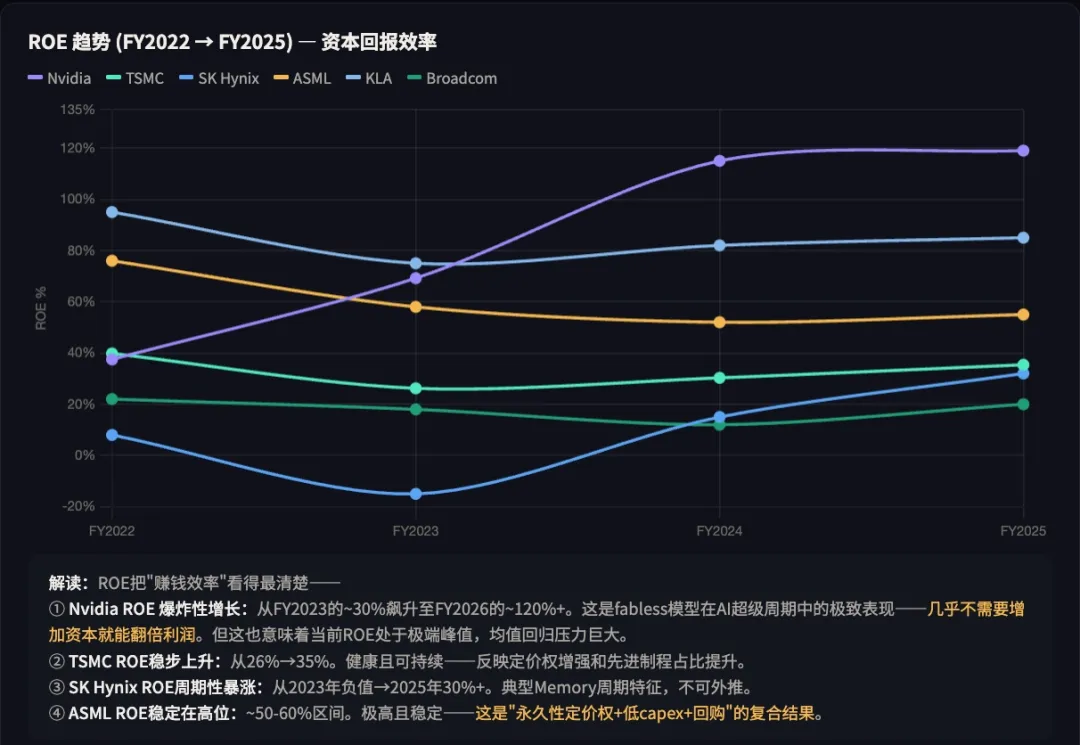
→ 核心观察: Nvidia 的 ROE 在 AI 周期内出现断层式飙升,从 30% 左右跃升到 100%+;Broadcom 的 ROE 也显著抬升;而 TSMC 的 ROE 虽有提升(从 25% 到 30% 左右),幅度远小于设计层公司;SK Hynix 的 ROE 波动较大(受存储周期影响),HBM 只带来了一个阶段性窗口,还没有彻底改写它的周期性特征。
结语:三个框架,找到你的答案
名词解释:
-
HBM(High Bandwidth Memory,高带宽内存,通过将多层 DRAM 芯片垂直堆叠并直连 GPU,大幅提升数据传输速度)
-
CoWoS(Chip on Wafer on Substrate,台积电的旗舰先进封装技术,将 GPU 芯片与 HBM 封装在同一基板上)
-
EMIB(Embedded Multi-die Interconnect Bridge,Intel 的嵌入式多晶圆互连桥接技术,是 CoWoS 的潜在竞争方案)
-
ROIC(Return on Invested Capital,投入资本回报率,衡量企业利用资本产生利润的效率)