 夜雨聆风
夜雨聆风





我用AI写了一篇小说,被告了——2026 AIGC版权避坑指南
来不及解释了,
2026年4月,北京通州法院判了全国首例用AI侵犯著作权的刑案。4个人用AI“洗稿”别人的小说,被判侵犯著作权罪。你以为AI生成的东西就是你的?不一定。更麻烦的是,你以为用AI“抄”别人不算抄——错得离谱。
这篇文章把AIGC版权的司法口径、五大风险点和五步合规方案一次性说清楚。
Here we go!
一、那个被判刑的案子,给所有人上了一课
2025年底到2026年初,“北京”通州法院判了4个人。
罗某某等4人,用AI工具批量生成别人小说的“改写版”。不是自己写的,是让AI把原文重新组织一遍再发出来。法院认定:用AI洗稿,照样构成侵犯著作权罪。

崩不住了。很多人脑子里有两套逻辑——我用AI生成的东西,版权归我;我用AI抄别人的东西,不算抄。
这两套逻辑不能同时成立。
AI是工具,不是挡箭牌。工具不会替人坐牢,人才会。
2026年1月,全国检察长会议专门强调:加强对涉AI前沿司法问题的研究指导。什么意思?这类案子以后只会越来越多,判得越来越细。
你品品,是不是这个理?
二、版权到底归谁?核心就看三个字:“人味”
“我用AI写了一篇小说,版权是我的吗?”
答案是:看你有多少“人的智力投入”。
根据《著作权法》和已有司法实践,AI生成内容受不受保护,分两种情况:
第一种,封闭式生成。你输入“写一篇科幻小说”,AI直接吐出一篇。你没有筛选、没有修改、没有后期加工。这种大概率不受版权保护。因为法院看的是“人类的独创性智力投入”——你啥也没干,凭啥给你版权?
第二种,辅助式创作。你反复调试提示词,从20个候选中挑出3个,再手动改了五六个版本,最后精修成定稿。这种受保护,版权归你——或者归你的雇主/投资人。
“苏州”中院之前有过类似思路。2026年4月17日,“人工智能+”知识产权论坛上,这也是核心议题。业内基本形成共识:AI是笔,不是画家。
那怎么证明你“参与了”?
三大证据必须留好:
-
构思与交互证据:保存提示词迭代记录。从“写一篇科幻小说”到“写一篇关于时间循环的短篇科幻,主角是程序员,第一人称,3000字”——这个演变过程,就是你的智力投入痕迹。
-
参数控制与选择证据:截图保留所有影响输出的关键参数。记录你从多个候选方案中选某一个的理由。“为什么选这个而不是那个”——这是证明“人做了判断”的关键。
-
后期编辑证据:保留PS、剪辑软件的可编辑源文件。这是证明“人参与了创作”的最有力证据,比任何口头声明都管用。
实操技巧:作品发布时附带权利声明——
“本作品系由创作者[姓名]主导,借助[AI工具名]生成初始素材,并经过深度构思、参数控制与后期创作而成。”
没有过程存证,就等于没干过。
三、你正在踩的雷:训练数据、输入内容、数字人直播
很多人以为AI合规就是“输出内容别侵权”。太天真了。雷埋在三个地方。
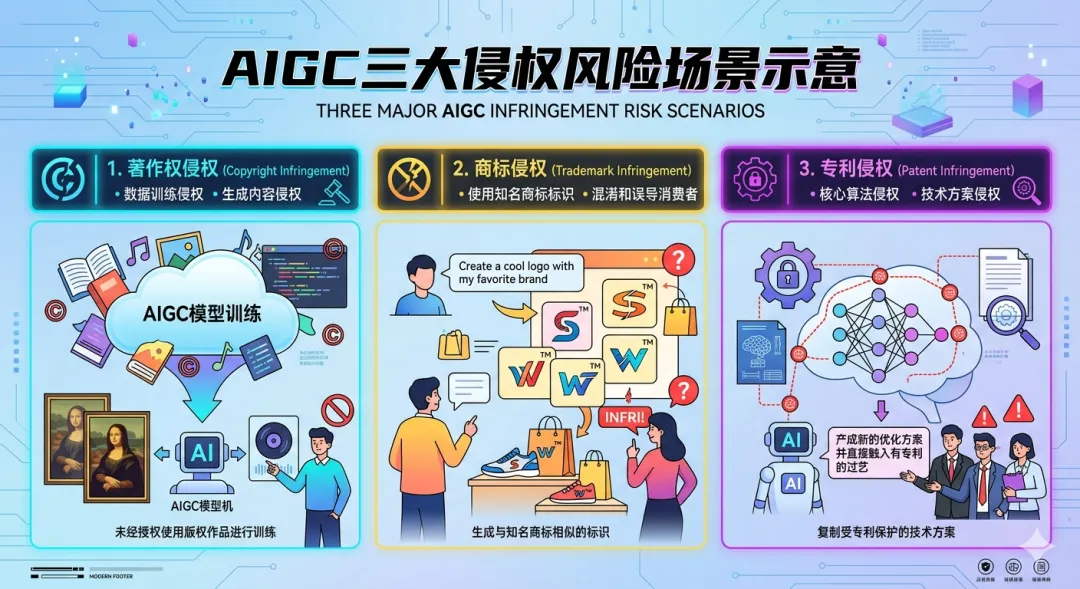
雷区一:训练数据。开源不等于“随便用”
常见误区两连击:
-
❌ “模型开源了,训练数据就能随便用” -
❌ “网上公开的内容,可以随意抓来训练”
全错。
开源是基于许可证的有条件授权。违反许可证,就是侵权。“公开可访问”不等于“可合法用于训练”——你发在公众号上的文章受著作权法保护,别人不能随便抓去训练模型。
2025年9月,有个叫“MixtureVitae”的数据集火了。为什么?因为它用的是公有领域和宽松许可(CC-BY/Apache)的文本,来源可追溯、授权链条清晰。性能还不输传统爬取的数据集。
企业采购训练数据时,记住两件事:
-
要求供应商提供完整的数据来源证明与授权链路文件 -
合同里加权利瑕疵担保条款——数据来源违规引发的索赔,供应商承担
雷区二:输入端。提示词就能让你吃官司
有人在提示词里写“按‘刘慈欣’的风格写一篇科幻小说”。大刘没告你,是因为没看见。但如果输入的是“把下面这段文字扩写成5000字”——原文有版权,你就侵权了。
还有更离谱的:有人输入“绘制一张‘漫威’风格的超级英雄海报”。“迪士尼”的法务部不是吃素的。
内部规范必须定三条红线:
-
禁止输入他人作品全文或核心表达 -
禁止输入未脱敏的个人信息 -
禁止输入商业秘密
所有交互记录自动保存,形成可追溯日志。这不是麻烦,是保命。
雷区三:输出端和数字人。新规已经落地
2026年2月1日起,《直播电商监督管理办法》正式施行。明确规定:
-
使用数字人主播,直播间运营者对内容负全责 -
必须持续、清晰标识“本内容由AI生成”
没标识?罚的就是你。
另外,输出内容本身也可能“记忆”训练数据里的受保护内容。有个简单但有效的办法:发布前用AI检测工具扫一遍,看有没有“撞脸”别人的作品。
没有合规意识,AI就是你的加速器——加速踩雷。
四、五步实操:从灰色地带到合规运营
光知道风险没用,得知道怎么做。这五步,今天就能开始。
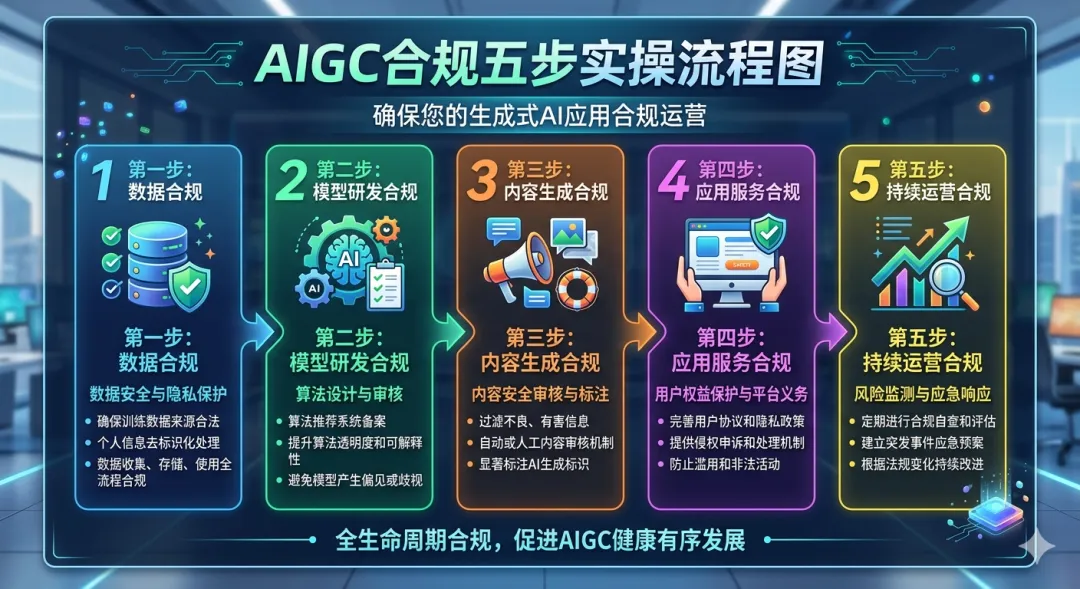
第一步,输入端:提示词合规审查
不是让你每句话都审,而是建规则。定好什么能输、什么不能输。员工用公司AI工具,输入框下面贴一行字:“请勿输入他人版权作品、个人隐私信息或商业秘密。”
就这么简单,但能挡住80%的风险。
第二步,创作端:人机协同过程存证
前面说的三大证据,从今天开始留。
具体做法:
-
提示词迭代:每次修改都保存一个新版本,别覆盖 -
参数设置:截图保存,命名规则是“日期_项目名_参数” -
筛选记录:建一个表格,列出候选方案和选择理由 -
后期编辑:永远保留源文件,不要只导出最终版
养成习惯之后,每件事多花30秒。但打官司的时候,这30秒值几十万。
第三步,输出端:三道防线
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
不复杂。第一道用免费工具就能跑,第二道让编辑看一眼,第三道复制粘贴一段话。
第四步,协议端:用户协议里的权责划分
如果你是AI工具的用户:
-
看用户协议里生成内容的版权归属——归用户还是归平台?归平台的,换一个工具 -
看有没有侵权免责条款——用户输入侵权内容,后果谁承担? -
看有没有退出机制——能不能不让自己的数据用于训练?
如果你是AI工具的平台方:
-
明确约定生成内容的版权归属 -
明确用户输入侵权内容的后果由用户承担 -
设置用户退出训练的选项(这是合规标配了)
第五步,出海:适配全球规则
截至2026年4月,各司法辖区动态:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
你的内容出到哪里,就按哪里的规则来。欧盟要披露训练数据来源,你就得能说清楚。
一句话总结2026年合规原则:人主导、过程存证、来源透明、标识清晰、责任到人。
写在最后
我是真没想到,2026年了,还有人在问“AI生成的东西能不能直接商用”。
能。但有前提。
AI不是法外之地,也不是版权真空。
从今天开始,做三件事:
-
留好提示词记录、参数截图、编辑源文件 -
发布时带权利声明 -
用户协议看仔细
这三件事,比你的“我觉得”管用一百倍。
搞定搞定。
获取方式:
关注我们的公众号,后台回复关键词 【马老师AI】 ,即可免费获取马老师《六款超强大AI软件课程》的下载链接。
关注我们的公众号,后台回复关键词 【AI工具实操】 ,即可免费获取《AI工具实操教程》的下载链接。
@ 作者 / 青畅
最后,感谢你看到这里👏如果喜欢这篇文章,不妨顺手给我们点赞|在看|转发|评论 📣
如果想要第一时间收到推送,不妨给我个星标🌟
如果你有更有趣的玩法,欢迎在评论区聊聊🤝
更多的内容正在不断填坑中……