“人工智能”(artificial intelligence)这一概念最早由计算机科学先驱约翰·麦卡锡(John McCarthy)提出。此后,人工智能被确立为一门学科,旨在通过计算技术模拟人类智能。然而,“智能”(“intelligence)这一概念至今并无明确定义。事实上,关于智能的内涵与影响的探讨,早在哲学作品中早便已存在。例如,亚里士多德(Aristotle)在《论灵魂》(De Anima,1956)中就已探讨灵魂的本质及其机能。他认为理智是灵魂中负责思考、理解和推理的部分,也就是灵魂的理性部分,这正是人类的一项关键能力。逻辑推理通常被视为智能的基本组成部分。
在哲学中,对智能这一概念的探讨由来已久。而在人工智能领域,图灵(Turing)于1950年发表的《计算机器与智能》(Computing Machinery and Intelligence)中提出的“图灵测试”(Turing Test),成为了讨论“智能”的开创性概念。在该论文中,图灵开篇便提出了一个极具启发的问题,“机器能否思考?”。他意识到这个问题充满歧义和哲学复杂性,于是提出了一种可操作的方法:图灵测试。它将焦点从寻求智能的抽象定义转向对可观察行为的实践评估。因此,在此语境下,智能被定义为令人信服地模仿人类反应的能力,正如麦卡锡等人在1956年达特茅斯夏季研究项目提案(The Dartmouth Summer Research Project on Artificial Intelligence)中所言:①
“学习的每一个方面或智能的任何其他特征,原则上都可以被如此精确地描述,以至于可以制造机器来模拟它。“
为此,人们开发了各种计算技术,从基于规则的系统到近期的机器学习(machine learning,ML)模型。本章中,将结合几个案例来阐述这些技术。本文目标有两重。首先,将从逻辑的角度探讨人工智能的基础,因为逻辑在人工智能的发展中发挥了关键作用,理解逻辑将有助于展望人工智能的未来。其次,鉴于人工智能、人类与人类社会之间的内在联系,伦理问题自然随之而生。本文将分享一些观察与担忧,以及应对这些挑战的思路。本文的最终目标是为下一代人工智能提供一个概念框架——该框架能够融合不同方法的优势,同时纳入一套健全的价值体系。
本章其余部分的结构如下。第2.2节介绍四种逻辑推理类型,这有助于后续理解人工智能的机制。第2.3节阐释人工智能的第一种路径,即系统对知识进行表征并据此推演出新的结论。第2.4节介绍当前另一种主流路径,它是机器学习与深度学习的基础;在此,本文将分析归纳与演绎及其蕴含的意义。在第2.5节中,本文对这两种路径进行比较分析,并提出将二者融合以更好地实现真正的智能。在此过程中,本文会讨论伦理问题,这些问题将在第2.6节中进一步探讨,着重强调技术开发者与伦理学家之间合作的重要性。最后,第2.7节给出结论。
在人工智能领域,逻辑推理在问题求解与决策中扮演着基础性角色(参见Russell and Norvig, 2010)。逻辑推理可分为四种主要形式:演绎、归纳、溯因和类比。这些推理形式构成了从已知信息中推断结论的基本机制,每种方法都有其独特的运作方式。本节将介绍这几种推理类型,以及在人工智能语境下,它们的发展与关联。
演绎推理从一般性前提或已知事实出发,将其应用于具体案例,从而得出逻辑上必然成立的结论。若前提为真且推理有效,则结论必然为真。例如:
示例1(演绎) 所有哺乳动物都有脊椎骨。鲸是哺乳动物。因此,鲸有脊椎骨。
在此示例中,一般性规则是哺乳动物都有脊椎骨。鲸是哺乳动物的一个具体实例,因此可以得出鲸有脊椎骨的结论。
演绎推理的根源可追溯至古希腊哲学。亚里士多德因其在《前分析篇》(Prior Analytics,Aristotle, 1938)中对三段论的系统性研究,通常被视为演绎逻辑形成化的奠基人。上述示例便是典型的三段论。本质上,这一理论支持对对象的类别及其属性(或谓词)推理。在19世纪和20世纪,弗雷格(Frege, 1879)、罗素和怀特海(Russell and Whitehead, 1913)等哲学家与逻辑学家构建了一阶逻辑,将其适用范围拓展至可对对象间任意(n元)关系的推理。演绎方法的范围也随之拓宽。在众多技术中,自动定理证明是逻辑研究的重要成果,后来逐渐成为为计算机科学与人工智能的研究课题。一般来说,一旦特定领域的知识被存入数据库,就可从中推导出进一步的结论。事实上,继一阶逻辑发展后,直至今日,仍不断有新的逻辑被提出。本文将在第2.3节讨论这些新的逻辑。
归纳推理始于具体的观察或证据,通过概括形成更普遍的结论或理论。所得结论具有或然性,并非必然为真。例如:
示例2(归纳)迄今为止,太阳每天早晨都从东方升起。今天,太阳从东方升起。因此,明天太阳也将从东方升起。
如示例,基于重复的具体观察,本文归纳出关于太阳升起方位的一般性规律。尽管这一结论极可能成立,但归纳推理并不能以绝对确定性保证结论为真。
弗朗西斯·培根(Francis Bacon)通常被认为是归纳法之父。在其著作《新工具》(Novum Organum)中,他主张将经验观察和系统实验作为科学知识的基础。他强调归纳是从具体实例推导出一般原则的方式。后来,休谟(Hume, 1748)对归纳进行了批判性审视,提出了归纳的问题,即如何基于过去经验为归纳推理辩护。此后,哲学家们致力于回答休谟这一问题,其中一些人提出了概率论方案(参见 Carnap, 1950;de Finetti, 2017)或实用主义解决方案(Popper, 1972),以期为科学中的归纳推理提供依据。将归纳视为一种科学学习方法,例如,形式学习理论研究了从证据中学习能够导向真理的条件(Schulte, 2024)。
通过本文可以看到,演绎推理从一般规则推导出具体实例,而归纳推理则从具体实例或观察中概括出普遍规则。与这两种形式不同,类比推理则是从一个具体实例推断出另一个具体实例的方式。这类推理在科学探究和日常认知中都极为常见。它并不试图建立普遍性命题,而是基于已知案例推断另一案例可能具有某些相似特征。类比推理依赖于对象或情境之间的结构相似性(Gentner, 1983)。通过识别结构对应关系,它根据相似对象的已知属性来推断未知对象的潜在属性。类比推理的结构可以表述如下:
A 和I’q 在属性 P₁, P₂,…, Pₙ 上相似;
这种推理形式不同于演绎的严格有效性,也不同于归纳对统计模式的依赖。它更关注本质与结构的相似性,而非表面的相似性。
示例3(类比)地球是一颗孕育生命、拥有液态水并具备磁场的行星。火星显示出存在液态水的迹象、磁场的残余,且与地球的地质相似。因此,火星也可能存在某种形式的生命。
这种推理是基于地球和火星这两个具体对象间的相似性,形成了一个合理的假说。当然,此类结论并不能保证为真。
类比推理在逻辑学和认知科学中已得到了广泛研究,至今仍然是一个活跃的研究领域。在人工智能中,类比推理扮演着日益重要的角色,尤其是在迁移学习、基于案例的推理(CBR,参见 Voskoglou and Salem, 2014)和结构匹配模型等背景下。例如,基于案例的推理系统在面对新问题时,会检索结构相似的过往案例及其解决方案,并加以调整以适应新情况。这种方法广泛应用于法律推理、医疗诊断和技术支持系统,突显了类比推理的核心特征:将知识从已知案例迁移到新情境中进行推理和决策。
现在,让我们来看最后一种推理类型:溯因推理。皮尔士在其著作(Peirce, 1891)中正式提出了溯因的概念,并将其描述为构建解释性假说的过程。他将溯因定性为在相互竞争的假说中选择最可能或最简单的解释,通常被称为“最佳解释推论”。它常用于诊断过程和日常决策。考虑以下示例:
示例4(溯因)你醒来时注意到街道是湿的。你想找出原因。运用溯因推理,你确定了几个可能的解释:
在诸多可能解释中,下雨是街道湿滑最可能也最简单的解释。你得出结论:昨夜很可能下过雨。
换言之,溯因推理帮助我们在现有证据的基础上选择最有可能的解释,即使存在其他解释。
需要注意的是,溯因推理天然允许进一步的修正。再以该示例为例:一旦观察到新证据,如“屋顶是干的”,这就与之前的结论相矛盾。此时,你可能会得出结论:很可能是有扫地车经过。这种动态性在溯因推理中非常常见。
溯因推理常用于科学研究中,研究者需要不断提出解释,以阐明所观察到的实验证据。而这些解释可能会随着新证据的出现而发生变化。近年来,溯因推理在人工智能领域也日益受到重视,因为从非完备数据中生成具有说服力的解释至关重要。阿利塞达(Aliseda,2006)对溯因推理进行了系统的逻辑研究。
本文在下表中总结了这四种推理类型的基本特征。无论人工智能中发展出何种技术,其背后的推理机制都属于这四种类型之一。在下一节中,本文将通过实例说明每种推理类型在人工智能系统中的应用方式,展示它们在各类问题解决场景中的适用性(表 2.1)。
表 2.1 演绎、归纳、溯因与类比推理总结
在本节结尾,本文提出一个重要观察。尽管上文给出的这些单步推理示例初看可能显得简单甚至微不足道,但其真正的价值在于能够以远超人类能力的程度不断迭代。机器驱动的方法使推理能够达到原本无法企及的深度,从而实现对数据更透彻、更详尽的探索。
知识表示(knowledge representation,简称KR)是人工智能的基础性领域之一,其重点是构建能够以计算机可处理的方式对世界知识进行编码的系统(Brachman and Levesque, 2004),从而支持复杂问题的求解。知识表示的有效性取决于系统在理解、推理以及与所处环境交互方面的能力,从而支持决策、规划与推理等任务。逻辑推理在此过程中起着至关重要的作用。本文将说明逻辑推理如何应用于知识表示,下文将通过一个简单的动物分类示例加以说明。
设想我们要开发一个基础的人工智能系统,根据两个关键特征将动物分类为“哺乳动物”或“爬行动物”:
首先,本文使用形式语言中的事实和规则来表示关于动物的知识。在此案例中,每个动物对应两项事实:是否为恒温动物,以及是否有鳞片。
规则是基于这些事实指导分类过程的逻辑语句。例如,本文定义两条简单的“如果—则”分类规则:
逻辑推理的作用至关重要,它使人工智能系统能够根据事实和规则推断出分类结果。例如,考虑对大象进行分类的具体任务:
示例5(对大象进行分类)我们有以下关于大象的事实:
根据这些事实,系统应用规则1:由于大象是恒温动物且没有鳞片,规则1判定大象属于哺乳动物。
在这个例子中,逻辑的使用,特别是演绎推理,提供了一种基于预定义规则得出结论的直接方式。逻辑使人工智能系统能够高效地利用事实进行推理,确保结论遵循既定前提。这一特性使得逻辑系统对于需要精确、基于规则推理的任务(如分类、验证和演绎)尤为有用。在人工智能的发展历程中,专家系统正是基于领域知识进行推理的典型范例。
然而,虽然包括一阶逻辑在内的传统形式框架至关重要,但它们也存在局限性。尤其是,一阶逻辑假设了一种严格的结构,其中所有事实非真即假,且推理是单调的。这在涉及不确定性、模糊性或例外情况时可能构成限制。现实世界常常呈现信息不完整、不精确或相互矛盾的情形,这些复杂性仅凭经典逻辑难以表示和处理。
因此,过去四十年间,人们发展出新的逻辑来应对这些问题,例如非单调逻辑(nonmonotonic logic)、动态认知逻辑(nonmonotonic logic,简称为DEL)和概率逻辑(probabilistic logic)。这些新逻辑扩展了传统逻辑框架,能够更有效地处理例外情况、知识更新和不确定信息。
非单调推理处理的是此类场景,即当新信息出现,尤其是存在例外时,可能需要修正已有结论。在传统的演绎系统中,增加新事实或前提不会推翻已有结论,但在许多现实情景中,必须考量例外情况。该领域一个著名的框架是缺省逻辑(Reiter, 1980),它允许我们基于典型(缺省)假设得出结论,而当发现矛盾证据时,这些假设可以被撤回。例如,在动物分类系统中,我们可以引入如下规则:
当我们发现一种新动物A,观察到它通过胎生方式繁殖(表明其属于哺乳动物),且没有已知特征与其为恒温动物相矛盾,我们就依据缺省规则得出:A是恒温动物。如果后续发现A存在异常代谢状况,使其体温与环境温度保持一致,这一新事实就会推翻之前缺省假设,我们将修正关于A是恒温动物的结论。然而,对于其他缺乏此类矛盾证据的哺乳动物,该通用缺省规则仍然适用。
为了处理不确定性与动态性,动态认知逻辑已成为一个重要工具,参见巴尔塔格(Baltag et al,1998)等人、范·迪特马什(van Ditmarsch et al,2007)等人以及范·本土姆(van Benthem,2011)。动态认知逻辑扩展了传统逻辑,它不仅关注知识的状态,还聚焦知识如何通过观察和通信随时间演变。
例如,设想一个人工智能野生动物监测系统,用于对新观察到的动物进行分类。最初,系统检测到皮毛的存在,便初步推断该动物是哺乳动物。然而,新的证据(如异常类似爬行动物的体温读数)给这一分类带来了不确定性。在动态认知逻辑框架中,每条新数据都会触发一次认知更新:系统重新审视其知识库,修正其假设,如果新证据与先前的推理相冲突,则可能对动物重新分类。这种基于动态认知逻辑的研究已从纯粹的知识更新扩展到信念修正(Baltag and Smets, 2008)和偏好变更(Liu, 2011),从而实现了能够根据新获取的信息,不断优化其内部模型的自适应人工智能系统。
应对不确定性的另一种方法是构建概率逻辑,旨在表示和处理不确定信息。经典逻辑使用两个真值,而概率逻辑为命题赋予概率,使人工智能系统能够在不确定性下进行推理。在概率推理中,系统不是断定一个陈述为真或假,而是基于已有证据评估一个命题成立的可能性。这在绝对确定性无法实现的情况下尤为有用。
例如,假设一个人工智能系统用于将动物分类为“哺乳动物”或“爬行动物”。如上所示,在典型场景中,系统会使用一组事实进行分类,如动物是否为恒温动物或有鳞片 。然而,在现实情境中,可用信息可能存在不确定性。例如,像蝙蝠这类的动物。蝙蝠是恒温动物,但也具有类似爬行动物的特征,如某些翼部结构。在概率推理框架下,系统可以根据观察到特征为“该动物是哺乳动物”这一命题赋予概率。如果该动物是恒温动物,但翼的存在带来了不确定性,系统可能会为该动物是哺乳动物的可能性赋予一个概率,例如80%,从而体现分类中的不确定性(Pearl, 1988; Jensen, 2001)。
这种概率方法使系统能够有效处理不确定性,即使在可用事实无法得出明确结论时也能进行推理。通过基于概率进行推理,系统可以整合新证据并相应更新其判断,这在动态且充满不确定性的环境中至关重要。
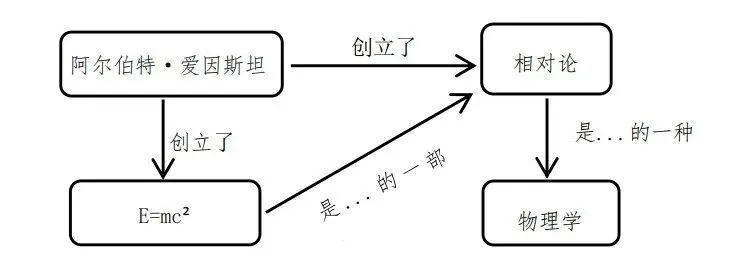
知识图谱(Knowledge graphs,简称KGs)已成为以结构化、语义化形式表示和组织知识的强大工具,关于其全面概述可参见霍根等人的研究(Hogan et al,2022)。知识图谱由节点(代表人、地点、概念或物体等实体)和边(代表这些实体之间的关系)组成。该结构通常以图的形式呈现,其中每个节点通过边相互连接,这些边描述了各种关系,例如“是……的一种类型”、“与……相关”或“位于……”。
许多知识图谱背后的一个关键组成部分,是使用本体来形式化地记录领域概念及其关系。在描述逻辑⁶和语义网技术的背景下,本体通常分为两部分:T-Box(术语盒,Terminological Box)和 A-Box(断言盒,Assertional Box)。T-Box 包含概念模式,其中包括类层次结构(例如,“物理学家”是“科学家”的子类)、属性限制和逻辑约束(例如,“所有理论都必须与某个领域相关”)。相比之下,A-Box存储实例层数据,将具体个体归属于类,并通过属性建立关联(例如,“阿尔伯特·爱因斯坦是一位物理学家”,“相对论与物理学相关”)。这种T-Box与A-Box的区分使得推理机能够在知识图谱中验证并推断新知识。例如,如果T-Box 规定“任何物理学家都专精于某个领域”,而A-Box表明“阿尔伯特·爱因斯坦是一位物理学家”,那么推理机就可以检查(或推断)爱因斯坦专精于哪个领域。通过T-Box定义与A-Box事实的相互配合,知识图谱具备了语义深度,从而支持逻辑一致性检查、分类以及某些推理的自动化。
知识图谱的核心优势之一在于其能够表示不同部分之间复杂的相互关系。通过关联不同的信息片段,知识图谱能够实现更好的上下文理解和推理。例如,下图所示的知识图谱通过“提出”这一关系将“阿尔伯特·爱因斯坦”与“相对论”联系起来,同时页通过另一条“提出”关系将“阿尔伯特·爱因斯坦”与“E=mc²(质能方程)”相连。此外,该图还通过“是……的一种类型”关系将“相对论”与“物理学”相连,并通过“是……的一部分”关系将“E=mc²”与“相对论”相连(图 2.1)。
知识图谱的通用性不仅限于简单的数据组织。它们是人工智能中各种高级应用的基础,包括自然语言处理(natural language processing,简称NPL)、问答系统、推荐引擎,甚至机器学习。知识图谱能够对现实世界的实体及其之间关系进行建模,使得知识图谱在语义搜索等任务中极具价值,语义搜索的目标是基于含义而非单纯的关键词匹配来检索信息。以上述知识图谱的一个可能应用场景为例:
如果研究人员输入“爱因斯坦在物理学领域提出了哪些理论?”查询,知识图谱能够使系统超越关键词匹配来理解查询。它可以利用实体间的关系来检索相关信息,识别出相对论是阿尔伯特·爱因斯坦在物理学领域提出的关键理论,并且 E=mc² 是该理论的一部分。这种对实体间关系的理解能力,使得知识图谱在获得更准确的研究结果上极为宝贵。
知识图谱本质上是动态的,这意味着它们可以随着新数据和关系的出现而持续更新。这种灵活性使其对于捕捉现实世界中各领域的复杂性极具价值。因此,知识图谱已被广泛应用于医疗、金融和技术等众多行业和领域。例如,在医疗保健领域,知识图谱可用于整合不同渠道的患者数据,从而优化诊断、治疗计划和个性化医疗。
数据驱动的人工智能是指主要通过分析大规模数据集来学习模式并进行预测的人工智能系统。与基于规则的人工智能不同,这类人工质能依赖预定义规则工作,数据驱动型人工智能运用统计方法、机器学习和深度学习技术,以发现数据中的模式与关系。系统通常利用相关性来建立不同的数据点之间的联系。这种方法使人工智能系统能够无须针对每种可能场景进行显式编程的情况下,实现自适应、优化并做出预测。
示例6(电子邮件垃圾过滤器) 设想一个旨在自动检测并过滤垃圾邮件(无用邮件)的人工智能系统,确保只有合法邮件才能进入收件箱。
为实现这一目标,通常会构建一个垃圾邮件过滤器。该过滤器通常采用数据驱动的人工智能,特别是机器学习,来分析收到的邮件并将其分类为“垃圾邮件”或“非垃圾邮件”。系统从已标记邮件的模式中学习,例如是否出现某些关键词(如“免费”、“限时优惠”或“快速赚钱”)、发件人地址(如已知的垃圾邮件域名)或邮件结构(如过度使用大写字母、可疑附件)。
例如,如果一封邮件来自陌生发件人,包含异常多的超链接,且主题行中含有“保证”一词,过滤器就可能将其归类为垃圾邮件。该系统会通过新示例学习来持续改进,从而能够适应不断变化的垃圾邮件手段。
在上述示例中,归纳推理体现在系统从过往数据中概括模式,以对从未见过的新邮件进行分类。例如,在利用大量标记为“垃圾邮件”或“非垃圾邮件”的邮件数据集训练后,系统能够识别出垃圾邮件中常见特征。再利用这些概括出的特征对新邮件进行预测,根据已学到的模式对其进行分类。这便是归纳步骤,即过滤器从具体实例中学习,并将所学应用于更广泛的情境。
另一方面,当过滤器面对一封不符合既有模式的模糊邮件时,溯因推理便开始发挥作用。在这种情况下,过滤器可能会根据邮件的特征生成关于其内容的假设,并尝试解释其为何可能是垃圾邮件。例如,如果一封邮件包含一些异常特征,比如怪异的主题但正文内容正常,过滤器可能会假设该主题行是垃圾邮件的标志,并基于上下文推断该邮件极有可能是垃圾邮件。溯因推理使过滤器能够在证据不完整或垃圾邮件发送者采用新手段时做出合理的猜测。需要注意的是,在这种情况下,无论邮件被判定为垃圾邮件与否,我们原则上都能获得相应的解释,因为垃圾邮件过滤器及其运行机制对我们而言仍然相对透明。
回到垃圾邮件过滤器和机器学习的话题,归纳推理帮助系统基于历史数据构建关于垃圾邮件样态的通用模型,而溯因推理则使其能够通过假设邮件特征的最佳解释来处理不确定的情况。当然,演绎推理和类比推理也有应用,但其重要性不及前两者。例如,系统中可能隐含一条规则:“如果发件人域名位于黑名单上,则将该邮件归类为垃圾邮件。”在这种情况下,如果发件人地址与黑名单中的条目匹配,过滤器就会根据该规则演绎推断出该邮件为垃圾邮件。
尽管相关性在数据和学习系统的推理中始终占据主导地位,但因果关系才是研究者的终极目标。理解数据点之间的因果联系至关重要,因为它能实现更精准的预测和更深刻的洞察。该领域已有广泛研究,探索了因果推断(Pearl, 2018)、结构方程模型(Bollen, 1989)和反事实推理(Rubin, 1974; Lewis, 1973)等方法。这些方法旨在超越单纯的相关性,揭示驱动观测数据模式的底层机制。因此,将因果关系融入机器学习与数据分析已成为近期研究进展中的一个关键焦点。
深度学习是机器学习的一个子领域,专注于模仿人脑的算法,即人工神经网络(artificial neural networks,简称ANNS)。这些网络由多层相互连接的神经元构成,以分层方式处理数据。凭借从原始数据中自动学习特征的能力,深度学习彻底改变了计算机视觉、自然语言处理和语音识别等领域(Goodfellow et al., 2016)。与需要手动设计特征工程的传统机器学习方法不同,深度学习系统能够自动发现数据中的模式,因此特别适合处理图像、视频和文本等大量非结构化数据任务。以利用深度学习进行图像分类的任务为例,这是计算机视觉中的常见应用场景。
示例7(图像分类) 在大量带标签图像数据集(例如数百万张动物图片)上训练的深度神经网络,可以根据学到的特征将一张未知动物的图像分类为“猫”或“狗”。
– 处理:网络通过多个层处理图像,每一层识别不同的特征。浅层可能检测边缘,中间层可能检测纹理,而深层可能识别特定物体(如猫或狗)的存在。
神经网络是深度学习的核心。它们由多个层组成,每一层都以更加抽象的方式转换输入的数据。深度学习的关键优势之一在于能够从原始数据中学习分层特征,无需人工干预。例如,在图像分类任务中,深度学习模型可以直接将原始像素值作为输入并直接产生分类结果,而无需依赖人工设计的特征,如颜色直方图或边缘检测滤波器。这就是为什么深度学习在包括图像识别(如卷积神经网络,CNN)、语音识别(如循环神经网络,RNN)和机器翻译(如 Transformer 网络)在内的许多领域都优于传统方法的原因。深度学习模型在训练过程中通过一种称为反向传播算法(backpropagation)来优化网络中的权重。通过将模型的预测与实际输出进行比较并计算误差,反向传播使网络能够调整其权重,从而随着时间推移不断提高其性能。
这类学习模型的快速发展得益于多种因素的共同作用:大规模标注数据集的出现、算力(尤其是图形处理器和张量处理器)的进步,以及借鉴了人类认知理念的精细架构,例如Transformer中的注意力机制(Vaswani et al., 2017)。这些因素共同使得在大规模数据上训练高表达能力的模型成为可能,从而在从图像识别到自然语言理解等任务中取得了显著进步。
但与此同时,深度学习模型的参数量的不断增加也使其内部运作机制愈发难以理解。例如,GPT-3.5 采用了基于Transformer的架构,拥有1750亿参数,而据估计 GPT-4 包含约1.76万亿参数。随着模型复杂性的增加,决策过程变得越不透明,这一挑战常被称为深度学习的“黑箱”(black‑box)特性。因此,尽管可以观察到这些模型中的一般推理模式,但要准确指出其确切理由和底层逻辑仍然充满挑战。这种可解释性的缺乏,让模型决策更加难以解释,尤其是在医疗和金融等关键领域,理解人工智能驱动的预测至关重要。为了解决这个问题,研究人员正在积极探索可解释人工智能领域的技术,参见吉多蒂 (Guidotti et al. 2019)和戈埃尔(Gohel et al,2021)等人。
近年来,尽管大语言模型展现了显著的进步,但它们只是高度依赖数据驱动方法的更广泛人工智能图景的一部分。然而,这些方法也带来了严峻挑战。其中一些问题影响着整个人工智能系统,而另一些问题则在大语言模型中尤为突出。下文将讨论数据驱动人工智能面临的两个主要挑战,随后介绍大语言模型面临的几个具体挑战。
-
数据集可用性与标注:人工智能的归纳方法依赖于从数据中学习模式,但关键挑战在于能否获得用于训练和再训练的高质量标注数据集。在医学诊断和法律推理等专业领域,数据集通常稀缺,而隐私法规(如欧盟《通用数据保护条例》(GDPR)、美国《健康保险流通与责任法案》(HIPAA))进一步限制了数据访问。此外,数据不平衡可能导致模型性能出现偏差。数据标注是另一个主要障碍。高质量的标注需要专业知识,这使得过程成本高昂且耗时。情感分析等主观性任务可能导致标注不一致。并且随着模型的演进,需要持续进行再训练,而人工标注难以规模化。这给长期维持模型性能带来了困难
-
偏见与公平性:数据驱动人工智能模型的另一个关键挑战是偏见问题。由于这些模型从大规模数据集中学习,它们可能会继承并放大社会偏见,导致不公平或歧视性的结果(Bolukbasi et al., 2016)。解决这一问题需要改进数据管理、模型训练和性能评估的方法,以确保结果更加公平(Mehrabi et al., 2019)。人工智能中的公平性对于防止社会不平等的加剧以及促进合乎道德和负责任的部署至关重要。例如,洪肯施罗尔和和鲁特格(Hunkenschroer & Luetge,2022回顾了人工智能驱动的招聘中的伦理风险,并提出了减轻偏见和增强公平性的最佳实践。
具体到大语言模型,以下挑战处于当前人工智能讨论的中心。
逻辑推理:总体而言,大语言模型表现出有限的逻辑推理能力。尽管近年来取得了显著进展,例如在 ChatGPT 中引入了“思维链(chain of thought)”方法(Wei et al., 2023),但这些模型在执行复杂的数学或逻辑推理任务时仍然存在困难。这一差距凸显了进一步提升人工智能以结构化、演绎方式进行推理能力的必要性。关于当前将大语言模型与逻辑推理相结合的努力,近期综述可参见成等人的研究(Cheng et al,2025)。
-
事实依据:事实依据构成了另一项重大挑战。ChatGPT-3 等早期版本的模型曾以生成错误或虚构信息而闻名,包括虚假引文和参考文献(Bender et al., 2021)。尽管在提高事实准确性方面已取得进展,但机器学习的归纳性质限制了模型持续验证其输出真实性的能力,而且这个问题似乎不太可能得到完全解决(Stiennon et al., 2020)。
最后,大语言模型还深受偏见之害,偏见可能以多种形式显现。例如,欧泽基等人(Ozeki et al,2024)通过英语和日语的三段论推理任务表明,这些模型不仅反映了既有的人类偏见,而且在整体推理过程中也面临独特的局限性。大语言模型面临的另一个独特挑战是缺乏针对社会少数群体的代表性数据。例如,原住民群体的文化内容往往代表性不足,因为他们的许多价值观和规范要么没有文字记载,要么通过口述传统传承,这使得大语言模型难以学习并反映他们的视角。
尽管这些挑战十分严峻,但相关问题远不止于此。然而,鉴于本章聚焦于逻辑层面的考量,上述挑战尤为相关。在第2.6节中,我们将继续讨论人工智能应用所引发的更广泛的伦理问题。
在前几节中,我们回顾了运用计算技术模拟人类智能的两条主流路径,并通过典型示例说明了它们的特点,同时从底层逻辑推理的角度分析了各自的优势与不足。具体而言,神经网络在处理如图像识别或语言建模等大规模数据任务方面表现出色,但在需要逻辑推理和抽象思维的任务上往往力不从心。相比之下,符号人工智能系统旨在利用抽象符号和形式逻辑进行推理,具有高度的可解释性,并能够执行结构化推理。然而,符号系统在处理非结构化数据以及从原始复杂输入中学习方面存在局限。
这两种路径可与卡尼曼提出的双系统理论(Kahneman, 2011)进行类比:系统1是快速、自动且直觉性的,类似于数据驱动的学习系统;而系统2则是缓慢、审慎且分析性的,类似于专家系统中的演绎推理。然而,作为人类,我们同时拥有这两个系统,并根据具体情境灵活运用。我们在演绎、归纳和溯因之间自如切换。这种灵活性才是真正的智能——这是当前人工智能系统尚未实现的能力。
神经网络研究可追溯至20世纪40至50年代(如 McCulloch 和 Pitts, 1943),与基于符号逻辑的人工智能浪潮并行发展。随着现代硬件的发展和数据规模的扩大,神经网络方法的性能大幅提升,但人们对符号方法的兴趣依然存在,这催生了“神经符号人工智能(neuro-symbolic AI)”领域富有成效的协同发展(Zhang and Sheng, 2024)。神经符号人工智能旨在通过整合两种路径来弥合它们之间的差距,将深度学习模型的模式识别能力与符号系统的结构化推理能力相结合(Belle, 2020)。
例如,第2.3节介绍的知识图谱提供了一种将外部知识注入神经模型以提升性能的方法,例如基于实体间关系进行预测,或确保跨多个数据源的一致性,参见马里奥提等人(Mariotti et al,2024)。
另一个此类例子是“基于符号推理的少样本学习(few‑shot learning with symbolic reasoning)”(Wang et al., 2020)。少样本学习使模型能够仅通过少量示例学习新任务,而通过整合符号推理,这些系统可以运用结构化知识来提高在新情境下的学习效率。其目标是克服深度学习模型需要海量数据的核心局限,使模型能够更抽象地推理,并从有限数据中获得更好的泛化能力。
目前,人们正致力于应用形式逻辑理论来更好地理解机器学习和深度学习的性质。例如,信息约简已被用于对机器学习系统的庞大状态空间进行分类(Geiger et al., 2021)。此外,当前逻辑与人工智能的交叉领域多涉及概率,这表明逻辑、人工智能与概率论正日益走向融合。
人类智能天然蕴含着逻辑与伦理的交织。我们做出的每一个决定,不仅受事实及发展趋势的影响,这属于逻辑范畴,也受到我们如何评估这些现实或潜在事实的影响,而这属于伦理的范畴。这种深刻的相互联系在人工智能中尤为明显,因为系统必须在处理信息的同时遵循伦理原则。
逻辑与伦理不仅仅是并行的视角,它们从根本上相互交织,这在诸如道义逻辑等将规范推理形式化的领域中可见一斑。在人工智能中,当设计具备自主决策、影响人类行为或影响社会福祉能力的系统时,这种交叉点尤为关键。随着人工智能技术持续发展,解决公平性、透明性和偏见等伦理关切,对于确保负责任的部署至关重要。
继第2.4节中关于数据驱动学习模型中偏见与公平性的讨论基础上,还有许多其他伦理问题亟待关注,这体现在“安全人工智能(safe AI)”“负责任人工智能(responsible AI)”和“可信人工智能(trustworthy AI)”等术语中。一个紧迫的问题是隐私。科辛斯基等人(Kosinski et al,2013)的研究表明,看似无关紧要的数字足迹如何能够泄露敏感的个人特征,这凸显了过度数据收集的伦理风险。尤其值得注意的是,大语言模型因其可能无意中记忆并复现训练过程中接触到的敏感信息而带来独特风险。尽管采用了数据匿名化和聚合方法来缓解部分风险,但近期关于数据泄露和模型透明度的研究(Apicella et al., 2024)表明,这些方法并非万无一失。这埋下了滥用的隐患,即个人、机密或专有数据可能在模型输出中被泄露(Rigaki and Garcia, 2023)。
现有的隐私法律,如欧洲的《通用数据保护条例》及其他地区的法规,试图解决这些问题,但全球范围内的协同治理仍必不可少(Voigt and von dem Bussche, 2017)。另一个问题是,制定新法律需要时间,往往落后于人工智能技术的快速发展,这在不断演化的人工智能应用所带来的挑战中可见一斑(Gerke et al., 2020)。然而问题依然存在:在强大的机器学习模型时代,我们能否真正实现隐私保护?还是说,这需要彻底地重新思考人工智能与个人数据的交互方式?
我们如今生活在一个与各类新形态存在——机器人和各种人工智能系统——它们怀着善意为我们提供帮助。然而,当问题出现时,谁应承担责任?这些系统是否拥有权利?它们应该为自己的行为负责,还是其创造者和使用者应承担这一责任?意图问题尤为棘手——机器能否真正拥有意图,还是仅仅基于预设程序和外部指令行事?(Königs, 2022)。
人类与人工智能系统之间的互动引发了许多新问题。例如,我们的偏好通过网购特定商品等行为体现出来,随后这些数据被收集起来,用于向我们推送更多的相关推荐⁹。事实上,我们不断被投喂“个性化(personalized)”内容,这看似有益,却也限制了我们接触新可能性的机会(Pariser, 2011)。Shartsis(2019)等学者警告说,这种能力可能导致不道德的行为,例如通过动态定价利用心理弱点,或针对有成瘾倾向的个体定向投放(如烟草或高热量食品)。此类做法引发了对企业利用人工智能牟利的道德责任的担忧。尽管如此,我们必须强调,新技术的发展势不可挡。然而,我们应当时刻警惕前方潜在的危险,以便做好相应准备(Choung et al., 2023)。例如,在人工智能系统开发过程中就应纳入伦理考量,确保从一开始就建立正确的价值体系(Borenstein et al., 2021)。
尽管面临挑战,令人鼓舞的是,针对其中一些伦理问题已采取了相应措施。科技行业的自我监管是人工智能伦理治理的一个主要路径。例如,克劳福德和卡洛(Crawford &Calo,2016)主张开发者采用社会系统分析方法来评估人工智能技术的社会影响。谷歌和微软等公司已实施内部伦理准则,强调人工智能开发中的公平性、透明性和问责制等原则。然而,自我监管存在局限性,尤其是在利润动机与伦理考量相冲突时,前述论文的作者也指出了这一点。
一些政府和国际组织已出台立法措施来应对人工智能伦理问题。欧盟一直走在人工智能监管的前沿,推出了《通用数据保护条例》和拟议的《人工智能法案》等举措。这些框架强调数据隐私、风险分级以及对高风险人工智能应用的问责,为伦理治理树立了全球标杆(Taddeo and Floridi, 2018)。另一方面,美国则采取了更为分散的方式,通过行业专项法规和州级倡议来处理医疗保健和金融等领域的人工智能伦理问题。
学术界和机构已制定了指导人工智能实践的伦理框架。电气与电子工程师协会(IEEE)的《人工智能设计的伦理准则(Ethically Aligned Design)》和经济合作与发展组织(OECD)的人工智能原则是突出的例子。这些指南倡导以人为本的设计、公平性、透明性以及负责任的数据使用等原则。虽然这些框架提供了宝贵的指导,但其在不同行业和地区的实施仍参差不齐。
然而,建立全球人工智能伦理标准的努力也面临重大挑战,包括文化差异、各不相同的监管优先事项以及经济差距。例如,拥有严格数据隐私法的国家可能难以与数据收集限制较少的地区保持一致。前路依然漫长,本文需要跨越国界的集体努力来共同解决这些问题。
在此背景下,学术框架可以提供宝贵的见解。道义逻辑框架,尤其是基于优先级的道义逻辑,不仅将规范和伦理体系形式化,还能形式化其背后的理由(参见 van Benthem et al., 2013)。它们可以作为一个统一的平台,用于协调不同利益相关者之间的协议并解决分歧。
本章中,本研究从自身视角出发,对人工智能进行了概述。逻辑与推理在人工智能中始终扮演着奠基性角色。形式逻辑语言用于知识表示,演绎推理则被广泛应用于从数据库中推断新知。相比之下,数据驱动的人工智能高度依赖大规模数据集,统计学规律主导着该领域的多数研究。从逻辑的角度来看,可以清晰地认识到,归纳与溯因推理或许无法从根本上解决准确性问题。尽管算法持续改进,但实现完美准确率的“最后一公里”很可能仍是一项挑战。逻辑视角使我们能够更清楚地理解这些局限性。
此外,本文还探讨了人工智能的新兴发展方向,例如将传统符号推理与数据驱动方法相结合,以更好地模拟人类智能。在此过程中,本文还讨论了人工智能开发与部署中产生的主要伦理问题。本研究认为,技术人员与哲学家之间的协同合作对于实现最优成果至关重要,这能确保技术进步与伦理考量相辅相成。
感谢迪克森·卢迪生(Dickson Lukose)与约翰·范·本特姆(Johan van Benthem)提出的宝贵意见,他们的建议使本文得以精进。刘奋荣的研究得到清华大学自主科研计划与庆应义塾大学客座教授(全球)项目的支持。
注释:
①该提案实际成文于1955年(McCarthy et al. 于1955年8月31日提交给洛克菲勒基金会)。因其规划并促成了1956年夏季召开的标志性“达特茅斯夏季研究项目”,学界通常将1956年视为人工智能学科的诞生元年,故在文献引用中亦普遍以该年份指代本提案。
刘奋荣,清华大学哲学系教授、博士生导师。她拥有中国社会科学院哲学博士学位和荷兰阿姆斯特丹大学理学博士学位,是“动态偏好逻辑”的创始人之一。刘奋荣现任清华大学-阿姆斯特丹大学逻辑学联合研究中心主任,并担任国际科学哲学学院(AIPS)正式院士、国际哲学学院(IIP)院士等学术职务。她长期致力于逻辑学、哲学、人工智能及中国逻辑史的交叉研究,在动态偏好逻辑、社会主体性、社会认知逻辑等领域取得了系统性成果,其专著《Reasoning about Preference Dynamics》曾获第七届高等学校科学研究优秀成果奖(人文社会科学)一等奖。
刘庆红(Ryu Keikoh),美国斯坦福大学国际与跨文化教育中心研究顾问 (Advisory Committee Member for Stanford Program on International and Cross-Cultural Education, Stanford University),日本经营伦理学会常务理事,稻盛和夫经营哲学研究中心教授。主要研究方向为伦理经济学与管理哲学。在教育学、管理学、经济学与哲学等领域曾出版多部关于中国,美国和日本研究的学术著作,并被学术界认为是少有的精通中、日、美三国学术语言与文化语境的跨文化、跨地域、跨学科的学者。
了解更多与AI²、IDEAS相关的学术科研信息,请点击以下链接:
2026年AI²讲座合集
2024年IDEAS讲座合集
 夜雨聆风
夜雨聆风