 夜雨聆风
夜雨聆风





多肽设计,为什么会成为AI制药的下一个爆点?
面对AI for Science的科研浪潮,学术论文、前沿成果是启发思考、开拓视野的有效途径。为帮助科研人员快速理解复杂公式、突破学科壁垒、节约科研时间,星使智算推出「科研聚焦」系列栏目!我们将依托北大科研团队+ADAM智能体的双重优势,筛选Nature、Chem. Sci.、J. Chem. Theory Comput.等顶刊中的标杆论文,用“技术拆解+应用落地”的双视角,为你提炼核心创新点、梳理技术逻辑链、解读科研价值与产业转化潜力。无需逐字啃读长篇原文,10分钟get一篇顶刊的核心精华,让前沿科研成果真正赋能你的实验设计与技术研发,少走弯路、高效突破!
过去几年,AI改写了蛋白结构预测,也把“从头设计生物分子”这件事从高门槛的计算游戏,推到了药物研发前线。尤其是在那些传统小分子很难啃下来的蛋白—蛋白相互作用(PPI)靶点上,多肽正重新被看见:它既比抗体更灵活,又比小分子更容易贴合大而平的结合界面。但问题也同样尖锐——多肽太“软”、太“活”、太难预测,设计成本高,实验成功率也并不稳定。就在这样的背景下,澳门理工大学应用科学学院与浙江大学药学院联合团队,在 Drug Discovery Today期刊发表综述文章 Artificial intelligence in peptide-based drug design,系统梳理了AI驱动多肽药物设计的关键数据基础、结构预测方法、靶向设计路线,以及这一领域正在面临的核心瓶颈与未来方向。
01丨为什么偏偏是多肽?
因为它卡在“小分子够不着、抗体进不去”的中间地带
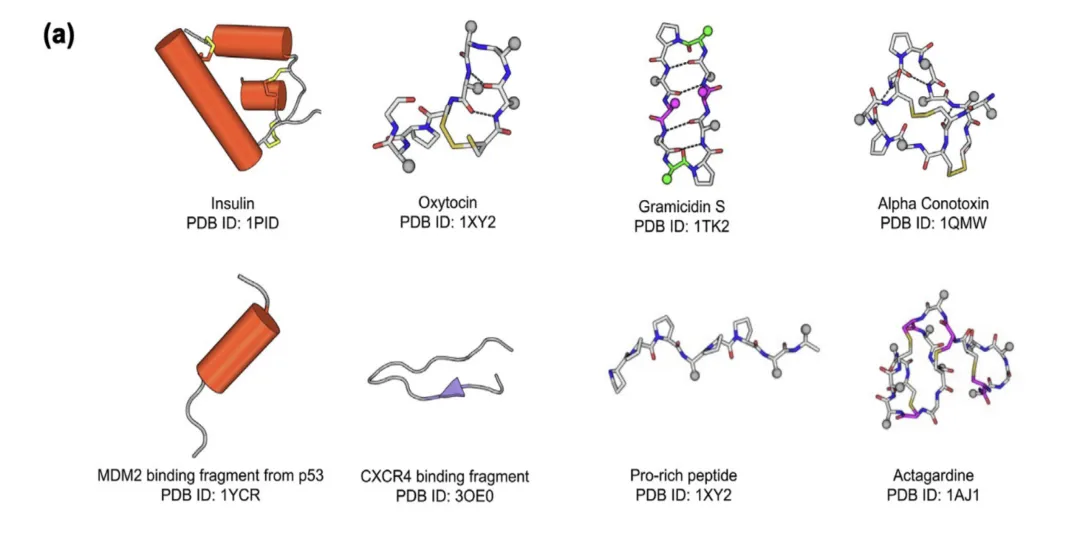
这篇综述一上来就点出了问题本质:PPI是生命活动的核心接口,但这类界面通常面积大、表面浅、缺少小分子喜欢“钻”的深口袋,因此传统小分子药物往往很难做出既强又专一的结合。抗体虽然擅长识别这类表面,却常常受限于膜通透性,难以进入胞内。多肽则恰好处在一个很微妙的位置:它保留了足够的柔性去适配蛋白表面,又具有相对可控的特异性和亲和力,因此被视为很多“不可成药”靶点的重要突破口。文章还提到,肽类药物的发展并不是新故事——从胰岛素开始,到今天FDA已批准超过100种肽类药物,多肽早已走出实验室,只是AI让它重新进入高速发展期。
02丨AI做多肽设计,第一道坎不是模型,而是数据
文章第二部分其实非常关键:在很多人都在谈模型的时候,作者先把视角拉回到了数据。因为多肽设计和蛋白设计最大的不同之一,就是高质量结构数据更少、冗余更高、构象更难覆盖。综述统计了多类蛋白—多肽相互作用数据库,例如 ProPedia、PepBDB、CPSet、PPI-Affinity、PixelDB 等,这些数据集为训练和评测提供了基础,但问题也很明显:多数数据来自PDB,很多是短肽、重复样本,部分数据库更新不足,网站甚至已经不可用。换句话说,多肽AI不是没有模型,而是还缺一个真正成熟、统一、持续更新的数据底座。
更有意思的是,作者指出了一个值得关注的思路:把蛋白 loop 区域当成“类多肽”资源来用。因为这些区域在结构与动态行为上与多肽具有相似性,可能成为补足多肽构象空间的重要参考。此外,随着 AlphaFold Protein Structure Database 这类“虚拟结构数据库”扩展,AI也开始不再只依赖实验结构,而是可以借助高精度预测结构放大训练规模。这个判断很重要:未来多肽设计的竞争力,可能很大程度上取决于谁能更高效地整合“真实结构 + 虚拟结构 + 序列知识”。
03丨从“能不能预测结合”到“能不能直接设计”:AI路线正在快速分叉
在方法层面,这篇综述给出了一个很清晰的故事线:AI做多肽设计,大体经历了三个能力层级。
第一层是相互作用预测。也就是先回答:这个蛋白表面哪里可能结合多肽?哪些残基更关键?文章提到了一系列代表性方法,比如 PepBind、InterPep、CAMP、PepNN、MaSIF 等。这里的趋势很明显:单纯靠序列或者单纯靠结构都不够,越来越多方法开始同时整合蛋白结构、肽序列、表面几何和注意力机制,目的就是把“会不会结合、在哪结合、如何结合”这几个问题一起回答。
第二层是复合物结构预测。也就是不只是知道会结合,而是想知道“结合成什么样”。文章回顾了传统的 template-based 和 template-free docking 方法,也提到分子动力学在热力学和动力学层面的价值;但作者也直言,这些方法面对高柔性多肽时都很吃力,采样成本高、打分也不稳。于是,AlphaFold 系列、AF3、RoseTTAFold All-Atom、Chai-1、Boltz-1、OpenFold 等新一代结构模型开始进入多肽场景。作者认为,这些模型已经展示出明显潜力,尤其AF3在全原子、多组分建模上提供了新机会,但对短肽、非天然修饰肽、宏环肽的系统 benchmark 仍然不足。
第三层才是现在最热的——target-specific peptide binder design,即针对特定靶标,直接生成可结合的多肽分子。这也正是整篇综述最值得传播的一部分:AI不再只是“看图说话”,而是开始真正“下场做分子”。
04丨主战场:多肽从头设计的三条路线,已经开始正面交锋
这一部分是全文最出圈的内容。因为它不再停留在原理,而是在回答一个更直接的问题:AI到底怎么设计一个能打靶的多肽?
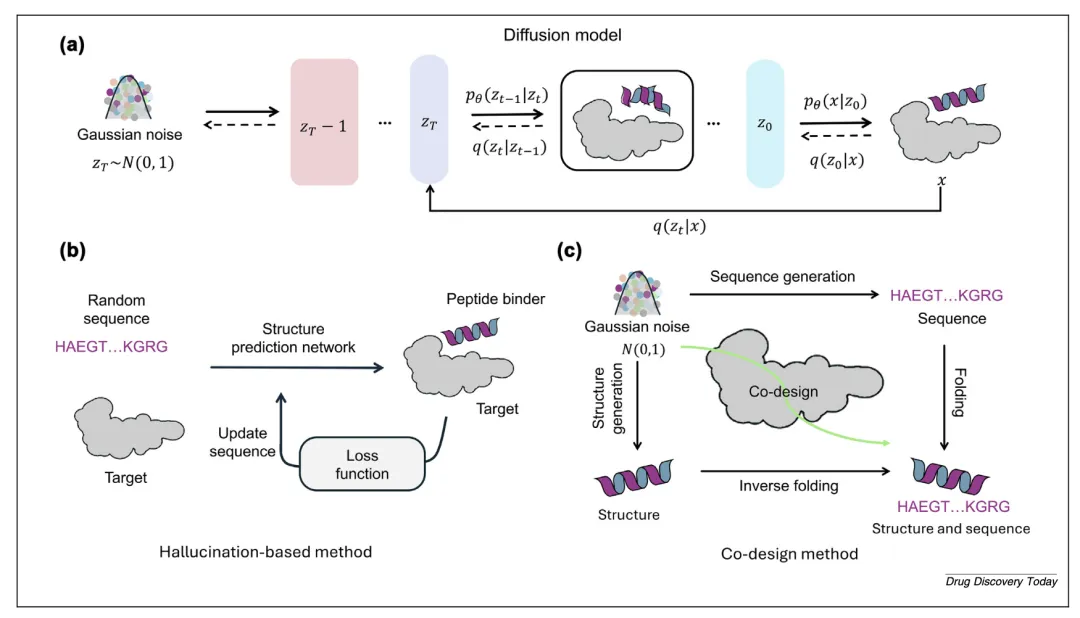
4.1 幻觉式设计:先乱写,再逼它“折”对
第一条路线是 hallucination-based methods。它的逻辑很像“逆向创作”:先给出随机序列,然后一边用结构预测模型判断“它会不会折成目标想要的样子”,一边通过损失函数不断迭代优化。文章把 ColabDesign、EvoBind、EvoBind2、EvoPlay 等放在这一脉络下讨论。
其中 EvoBind 通过 Foldseek 找种子结构、再用 ESM-IF1 做逆折叠设计,最后用 AlphaFold 评估复合物;EvoBind2 更进一步,几乎只需要目标蛋白序列,不依赖预先知道的结合位点、模板或肽长度。更吸引眼球的是,作者引用的结果显示:EvoBind2 设计出的环肽结合亲和力可以覆盖从微摩尔到亚纳摩尔量级,环肽和线性肽的实验成功率分别达到 75% 和 46%。这已经不是“能不能做”的问题,而是“做到什么程度”的问题了。
4.2 共设计:不再先定骨架再补序列,而是结构和序列一起长出来
第二条路线是 sequence–structure co-design。这类方法不满足于“先有结构再配序列”或“只从序列端盲猜”,而是让结构与序列在生成过程中共同演化。文章重点讲了 DiffPepBuilder、PepGLAD 和 PepFlow。
其中 DiffPepBuilder基于 SE(3)-equivariant diffusion,把蛋白语言模型嵌入、位置编码、distogram 等信息都揉进来,不仅生成多肽结构,还同时预测残基类型、旋转平移、扭转角等信息。更重要的是,它还专门加入了一个 SSBuilder 模块去设计二硫键,以提高多肽稳定性。作者总结其表现时提到,DiffPepBuilder 在 recall、界面质量和结构多样性上优于 ColabDesign 和 RFdiffusion+ProteinMPNN 组合。PepGLAD 则强调全原子几何与结合构象多样性;PepFlow 代表的是 flow-matching 路线,在几何、能量和多样性指标上表现强劲。
4.3 序列模型:没有结构也能做,而且更适合“不老实”的靶点
第三条路线是 sequence-based methods。这是这篇综述里非常有前景的一条线。作者指出,很多真正有药物价值的靶标并没有高质量共晶结构,甚至本身就高度无序、构象切换频繁,例如某些转录因子。对于这类目标,结构驱动方法天然吃亏,而蛋白语言模型(pLM)反而可能更有机会。
在这条线上,文章重点提到 ESM2、PepMLM、moPPIt、Cut&CLIP。PepMLM 通过在目标蛋白序列C端放置一个连续 mask,让模型“补出”一个可结合的多肽,报道的 hit rate 超过 38%;moPPIt 则进一步强调 motif-specific 设计,BindEvaluator 在测试集上的 AUC 超过 0.94,微调到蛋白—多肽对后可超过 0.96;Cut&CLIP 更把设计与降解结合起来,用对比学习设计既能结合靶蛋白、又能触发 E3 连接酶介导降解的多肽。换句话说,AI设计多肽的目标,已经不只是“bind”,而是开始走向“bind and act”。
05丨这波热潮离真正成药还有多远?文章把“冷水”也泼得很明白
作者在结尾部分的判断相当克制:虽然AI在多肽设计上已经显示出强大潜力,但截至这篇综述发表时,还没有AI辅助设计的多肽药物获得FDA批准。目前已上市的肽类药物,主体仍来自传统药物发现路线。
作者认为,未来这个方向至少还有几道硬门槛要过。
第一,多肽的药代性质仍然是大问题。高亲和力不等于可成药,热稳定性、蛋白酶降解、半衰期、膜通透性、口服可及性,任何一个维度掉链子,分子都很难真正走到临床。
第二,模型对非天然氨基酸(NCAAs)和非常规环化方式的支持还远远不够。文章特别强调,环肽是药化上极有价值的一类分子,但当前很多结构模型主要围绕常规的首尾环化或二硫键环化,像硫醚环化等非常规方式仍探索不足。作者还点到了RFpeptides 这类新工作,认为其展示了宏环多肽设计的潜力。
第三,未来模型必须从“单目标最优”走向多目标优化。也就是说,不只是追 binding affinity,还要同时考虑 specificity、stability、drug-likeness、甚至可制造性。否则,AI设计出的分子可能在计算上很漂亮,但在真实研发中没有落地空间。
06丨总结:AI在把多肽药物设计从“靠经验碰运气”推向“可编程生成”
这篇综述告诉我们,多肽药物设计正在经历一次范式切换——从“先找到天然模板再修修补补”,转向“围绕靶点,直接生成能结合、能优化、甚至能执行功能的分子”。其最大的价值不只是盘点了模型,更是把这个领域的主线讲清楚了:
先要有数据与结构基础,再解决相互作用预测和复合物建模,接着走向真正的靶向生成设计,最后再回到药代、特异性、实验验证这些成药本质问题。所以,对今天的AI多肽设计来说,最值得关注的并不是“哪个模型又刷榜了”,而是三个更本质的问题:
🔺它能否面对没有结构、甚至高度无序的真实靶标?
🔺它能否支持非天然氨基酸、环肽和更复杂的药化修饰?
🔺它能否把高亲和力、强特异性和成药性同时装进一个设计框架里?
谁先把这三件事真正做通,谁就可能定义下一代多肽药物研发平台。
论文题目:
Artificial intelligence in peptide-based drug design
论文链接:
https://doi.org/10.1016/j.drudis.2025.104300

Sidereus
星使智算
星使智算是一家专注于科研智能体与垂类科学计算解决方案的创新型科技公司,致力于以人工智能赋能科研,重构科学研究范式。公司核心产品 GaliLeo 平台通过自然语言交互驱动科学计算,集成任务解析、工具调用与科研报告自动生成,显著提升科研效率与算力使用效能。
星使智算面向量子化学、生物信息、材料建模等多个高性能计算领域,提供智能体定制与计算平台服务。公司自研 AI Agent “ADAM” 已在多个场景中落地应用,具备高度可扩展性与专业化能力。与此同时,星使智算还提供对 SPONGE 分子动力学引擎的深度适配与计算支持,帮助科研用户高效开展分子模拟、自由能计算等关键任务,推动前沿科研成果的加速落地。
目前,星使智算已与多家一流科研机构与科研服务公司建立战略合作,持续拓展在新药研发、分子设计与基础科学研究中的智能化应用边界。
*点击阅读原文,即可进入GaliLeo平台:https://sidereus-ai.com/