夜雨聆风
夜雨聆风





非技术人员怎么用 Arena 选对 AI 工具#实测指南

Arena.ai(Chatbot Arena、LMArena)最近改名叫 Arena,但核心没变:一个靠全球用户投票决定 AI 模型排名的众包评测平台。
你不需要懂技术,也能从中拿到有用的参考。
Arena 是什么
Arena 由 LMSYS 和 UC Berkeley SkyLab 联合开发,机制很直接:你输入一个 prompt,平台返回两个匿名模型的回复,你选哪个更好,投票后才公开模型身份。投票数据通过 Elo 评分计算排名。
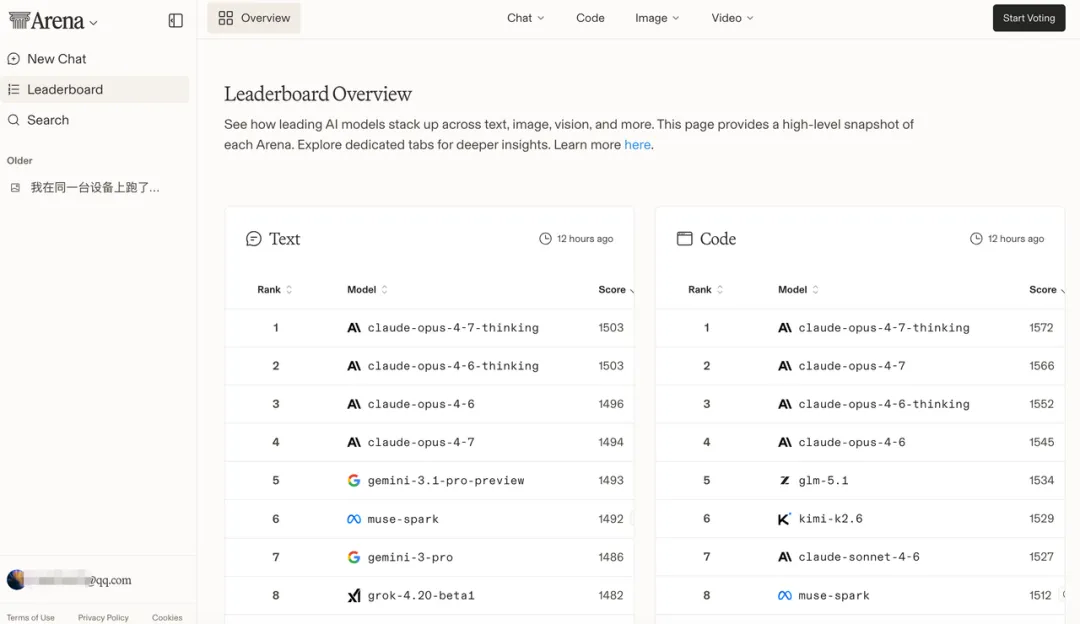
Arena leaderboards
目前有 600 多万次投票,月活 5M,覆盖 150 个国家,每月 60M 次对话。
非技术人员能从中得到什么
直接价值:看模型排名。
Arena 有多个细分类别的排行榜:
-
Overall:综合排名 -
Text:文本对话能力 -
Code:编程能力 -
Vision:多模态视觉理解 -
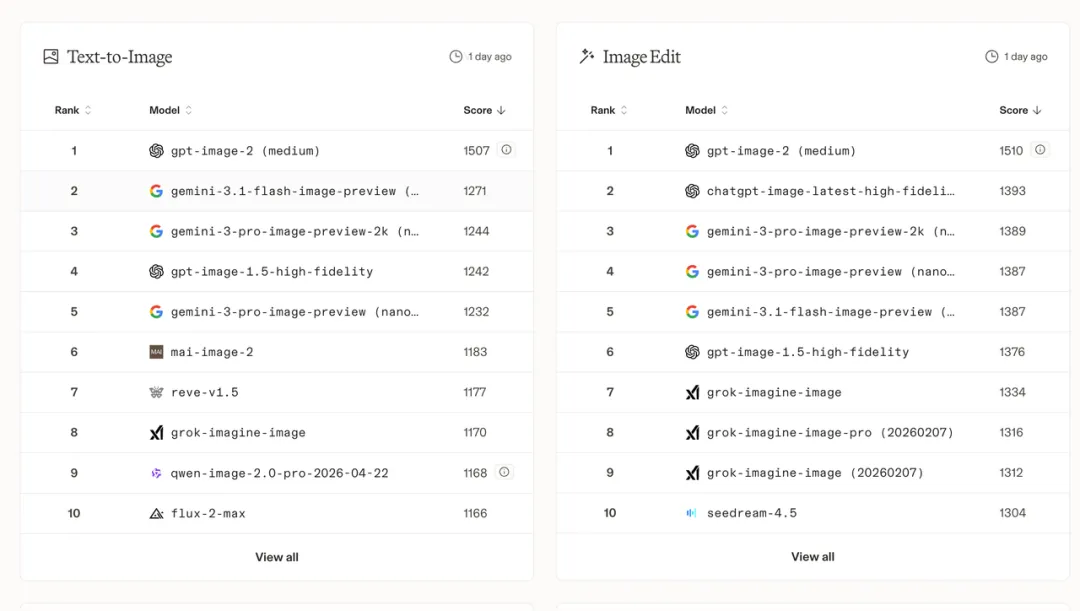
Image to WebDev:根据截图生成网站 -
Document:文档理解
2026 年 4 月的数据:
-
Claude Opus 4.7 Thinking 在 Expert Category 排名第一 -
Kimi K2.6 已上线 Battle Mode,覆盖 Text、Vision、Code 等多个 Arena -
Image to WebDev 排行榜上,Claude 4.6(Sonnet/Opus)占据前 3,Google Gemini 3.1/3 紧随其后
How to evaluate LLMs: the statistics behind Arena’s rankings
选 AI 工具时,这些排名比厂商自己的宣传可靠——几百万人次投票投出来的结果,不是官网首页上写的那几句话。
Arena 排行榜的局限
Arena 不是完美的评测体系。TechCrunch 的深度报道指出几个问题:
- 用户偏技术
:投票者多是程序员,不代表普通用户 - 题目分布偏差
:高赞问题集中在编程、调试,非技术类问题严重不足 - 无法检测幻觉
:流畅的表达可能获得更多票,但不等于信息准确 - 商业利益
:赞助商包括 a16z 等 VC/公司
把它当作”用户满意度调研”会更准确,而不是”客观智能测评”。
怎么用 Arena 做决策
1. 找到对应需求的排行榜类别。
只看 Overall 排名容易误导。主要用 AI 写文案,看 Text;主要做图片相关的事,看 Vision 或 Image to WebDev。不同类别的排名差异很大。
2. 亲自测一下。
Battle Mode 对所有人开放。输入自己真实场景的 prompt,看两个匿名模型哪个回复更好——这个测试结果比任何排名都准确,因为测的是你真正会用到的东西。

How To Try Out AI Models For Free
3. 结合其他维度。
Arena 人类偏好 + 静态基准测试(如 MMLU、HellaSwag)+ 特定任务表现,三者结合才能全面评估。
4. 关注 Expert Category。
这个类别反映的是专业用户提出的最有挑战性的 prompt,最接近前沿能力。
能从中学会什么
即使不用 Arena 做决策,这个平台本身也是个学习资源。
通过大量真实对话,可以了解不同 AI 模型在复杂推理、多模态、代码等任务上的实际表现。追踪同一个模型在不同时间点的排名变化,能看到模型的进化方向。参考全球数百万用户的集体判断,能建立对 AI 能力边界的真实认知——不是看厂商怎么说,是看大家实际怎么用。
提示
Arena 用户以技术背景为主,对非技术类任务(如创意写作、生活建议)的评估参考价值有限。
商业公司可能利用 Arena 排名做营销,排名靠前不等于”最适合你的场景”。
另外,纯 API 调用的模型可以访问所有用户输入,存在”针对 Arena 训练”的潜在不公平优势。
参考
[1] Arena.ai 官方首页 | 2026
[2] Arena 排行榜
[3] LMArena is now Arena
[4] The AI industry is obsessed with Chatbot Arena — TechCrunch